[논문 리뷰] Data Augmentation of Wearable Sensor Data for Parkinson’s Disease Monitoring using Convolutional Neural Networks
Arxiv link
https://arxiv.org/pdf/1706.00527
Github link
https://github.com/terryum/Data-Augmentation-For-Wearable-Sensor-Data
이미지 데이터의 경우 Flipping, Brightness control, RGB channel change, Rotation, Centor crop 등 여러 Augmentation 방법들이 있다. Time series에 적용 가능한 Augmentation 방법이 무엇이 있을까 찾아보다가 이 논문을 찾게 되었다.
INTRODUCTION
CNN을 통해 Parkinson’s disease(PD)를 판별함. 다만 대규모의 의료 데이터는 개인 정보 등의 이유로 인해 모으기 어렵고, 소규모의 데이터에 대해 CNN에 적용하는 것은 굉장히 어려운 작업임. 따라서 Data augmentation을 이용해 이러한 문제를 해결하고자 함.
RELATED WORK
PD 환자들은 bradykinesia(underscaled, slow movement)와 dyskinesia(overflowing spontaneous movement) 이 2가지 상태의 상반된 증상을 경험한다. 도파민 투여를 통해 완화될수는 있으나, 과도하게 투여할 경우 dyskinesia가 바로 bradykinesia 상태로 전환될 수 있음. 따라서 환자의 현재 상태에 대한 정확한 진단이 중요함.
현재 wearable sensor data에 대해 평가를 자동화하려는 시도가 있었으나, 이는 임상 환경에 특화되어 있어 일상생활에 적용하기에는 무리가 있는 상황임. 따라서 data augmentation을 통해 noisy한 데이터 혹은 window를 변경하는 등 일상생활에 가까운 데이터를 얻는다.
PD MOTOR STATE CLASSIFICATION
- Challenges in PD Data
bradykinesia : decreased movement speed, tremor(떨림)가 동반될 수 있음.
dyskinesia : involuntary extremity movements (비자발적인 움직임)
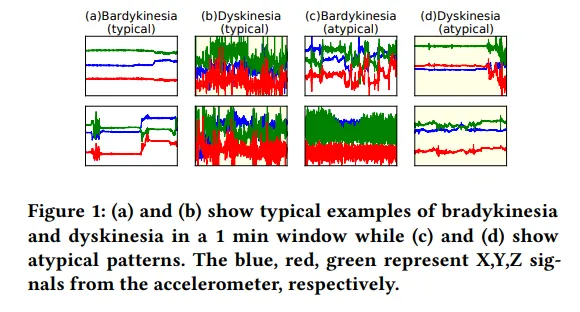
가속도 센서를 이용하여 환자의 운동 상태를 측정한다.
(a), (b)에서 보이듯, bradykinesia 는 정적, dyskinesia 는 변동이 굉장히 큼. 그러나 (c), (d)에서 보이듯 tremor이 동반된 bradykinesia는 dyskinesia 처럼 보일 수 있고 의도적으로 움직임을 억제하는 (센서를 부착한 손은 환자가 의자를 잡고 있어 움직이지 않는 경우) dyskinesia 는 bradykinesia처럼 보일 수 있음. 이러한 데이터 패턴의 불일치는 Ground Truth의 라벨과 일치하지 않을 수 있다. 또한 전문가는 고정된 길이의 window로 증상을 평가하는데, 임의의 시점에서 고정된 window로 나누면 그 안에 여러 상태의 신호가 포함될 수 있다. 데이터 양이 적을 경우 이러한 요인들은 운동 상태의 분류를 굉장히 어렵게 만들 수 있다.
- Data Augmentation Methods for Wearable Sensor Data
Data augmentation은 특정 데이터의 invariante properties에 Prior - knowledge를 주입하는 것으로 생각할 수 있다. 이는 unexplored input space의 데이터를 커버하고, overfitting을 방지하며, general ability를 높인다.
- Rotation (Rot)
Sensor을 거꾸로 부착하면 부호가 뒤집힐 수 있지만, label은 변경되지 않는다. (가속도 센서라서 가능한 듯. PPG에 적용하기는 어려워 보인다.)
- Permutation (perm)
크기가 fixed된 window의 분할이 임의로 이루어지기 때문에, window 내에서 symptom의 위치는 중요한 정보를 가지지 않는다. 따라서 이 event 혹은 window 분할의 위치를 임의로 변경하여 데이터를 늘린다. Permutation(Perm)은 event의 위치를 임의로 교란하는 방법 중 하나인데, N개의 같은 길이의 segment로 자른 후 이를 무작위로 조합하여 new window를 얻는다.
- Time-Warping (TimeW)
sample간의 time interval을 왜곡함으로서 temporal location이 달라진다.
- Scaling (Scale)
magnitude의 small change는 label을 변화시키지 않을 수 있음. random scaler을 data에 곱해줌으로 데이터를 증강함
- magnitude-warping (MagW)
data window에 임의의 curve를 합성하여 magnitude를 변경
- jittering (Jitter)
임의의 noise를 추가 (ex : gaussian noise)
- cropping (crop)
image crop 또는 window slicing과 비슷하게 적용되어 event간의 location 의존도를 줄인다. 다만 이는 event가 없는 영역을 포착할 수 있으며 이는 label에 영향을 줄 수 있다.
Experiment
25명의 PD 환자의 운동 데이터가 수집되었고, 1분 간격의 window는 전문가에 의해 label됨.
초당 62.5회의 빈도로 sampling, 이후 120Hz로 resampling됨. 60초 길이의 window에서 처음 58초 동안의 데이터가 (58 * 120 = 6960) 같은 길이의 window를 만드는 데 사용됨.
증상이 없는 일반적인 데이터는 제외하고, normalization 혹은 smoothing과 같은 전처리는 하지 않음.
총 3530min(58.8H)의 데이터를 만들었고, 25명의 group을 5개씩 나누어 5-fold validation을 진행. LSTM, ResNet등 깊이가 깊은 데이터보다는 비교적 작은 모델인 CNN을 사용.
모든 실험은 400에폭동안 수행되며, 마지막 10 epoch동안의 결과의 중앙값을 사용하여 5-fold 검증 결과를 평균화함.
jittering의 경우 : 0.03의 std를 가진 gaussian noise
scaling : mean - 1, std - 0.1에서 gaussian distribution에서 random한 scaler이 샘플링됨
Permutation : std - 5의 gaussian distribution에서 sampling된 값에 따라 무작위 정수 N이 생성됨.
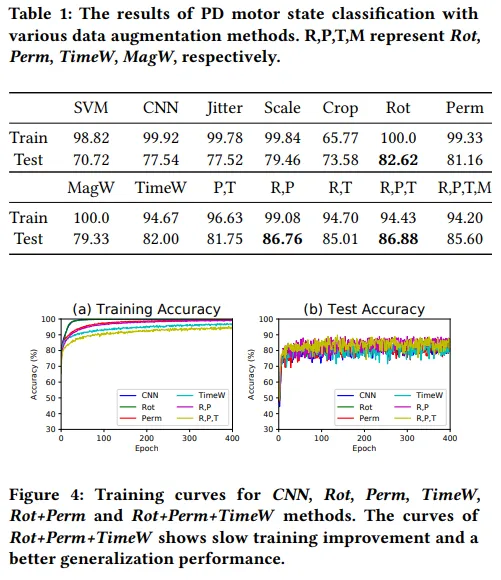
jittering은 급격한 변화를 포함하기 때문에 성능의 개선에 영향이 없었음.
croping 또한 정보량을 2/3가량 줄였는데, 이는 small dataset에 치명적인 결과.
Scaling and magnitude warping 또한 실패 → signal의 intensity를 바꿨을 때 label이 바뀌는 경우가 있었기 때문.
반면 Permutation, rotation, Time warping은 perfirmance를 개선시키는 효과를 보임.
Rotation, Permutation, Time warping을 모두 적용한 결과 baseline보다 약 9%의 성능 개선이 이루어짐. data augmentation이 regularization효과를 얻을 수도 있음 → training curve가 느리게 포화됨
