Kafka와 RabbitMQ의 비교: 메시지 브로커의 차이점과 사용 사례
-
Kafka와 RabbitMQ는 모두 메시지 브로커로서, 분산 시스템에서 메시지를 교환하고 비동기 통신을 가능하게 한다.
-
두 시스템 모두 스트림 처리에 사용될 수 있으며, 특히 실시간 데이터 스트리밍에 적합하다.
-
예를 들어, 온도나 기압의 실시간 변화를 관찰하기 위해 센서 데이터를 지속적으로 수집하고 처리해야 하는 환경에서는 Kafka와 RabbitMQ 모두 활용할 수 있다.
하지만 이 두 메시지 브로커는 설계 철학, 아키텍처, 성능, 메시지 처리 방식 등에서 차이가 있다. 이를 자세히 살펴보자.
RabbitMQ와 Apache Kafka의 정의
-
RabbitMQ : 여러 소스에서 스트리밍 데이터를 수집하고 처리를 위해 다른 대상으로 라우팅하는 분산 메시지 브로커이다. RabbitMQ는 실시간 메시징, 작업 대기열, 마이크로서비스 간의 통신 등에서 주로 사용된다.
-
Apache Kafka : 실시간 데이터 파이프라인과 스트리밍 애플리케이션을 구축하는 데 사용되는 스트리밍 플랫폼이다. Kafka는 뛰어난 확장성, 내결함성, 내구성을 제공하며, 복잡한 데이터 스트리밍 및 로그 수집에 적합하다.
Kafka vs RabbitMQ 비교 시작
아키텍처
공통점
- 두 시스템 모두 소비자(Consumer)에게 메시지를 보낼 수 있으며, 생산자(Producer)가 정보를 게시하고, 소비자가 이를 구독하고 처리하는 구조를 가짐
차이점
-
RabbitMQ
-
교환소(Exchange) : 메시지를 수신하고 어디로 라우팅할지 결정
-
대기열(Queue) : 교환소에서 받은 메시지를 소비자에게 전달하기 위해 저장
-
바인딩(Binding) : 교환소와 대기열을 연결하는 경로로, 라우팅 키를 사용해 메시지를 특정 대기열로 라우팅
-
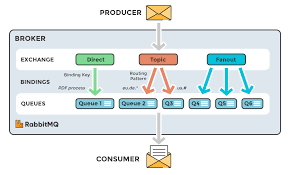
-
Kafka
-
브로커 : 생산자가 소비자에게 데이터를 스트리밍할 수 있도록 하는 Kafka 서버. 브로커는 토픽과 파티션을 포함하며, 각 파티션은 독립적으로 관리된다.
-
토픽(Topic) : 유사한 데이터를 그룹화하는 데이터 스토리지. 토픽은 하나 이상의 파티션을 가질 수 있음
-
파티션(Partition) : 토픽 내의 더 작은 데이터 스토리지 단위로, 소비자가 구독한다.
-
KRaft 프로토콜 : 파티션 관리를 통해 내결함성 스트리밍을 제공한다.
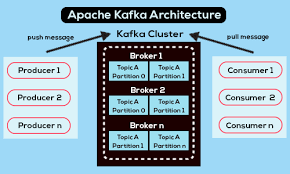
-
성능
-
RabbitMQ : 초당 수만 개의 메시지를 처리할 수 있으며, 대기열이 혼잡해지면 처리 속도가 느려질 수 있음
-
Kafka : 높은 확장성을 갖추고 있어 초당 수백만 개의 메시지를 처리할 수 있음
메시지 처리 방식 차이
-
RabbitMQ : 브로커가 소비자에게 메시지를 Push 하는 방식으로, 소비자는 수동적인 역할을 함
-
Kafka : 소비자가 마지막으로 읽은 메시지를 추적하며, 이를 기반으로 오프셋을 업데이트함. 즉, 소비자가 메시지를 Pull 하는 방식. Kafka에서는 생산자가 소비자가 메시지를 읽었는지 인식하지 못함
메시지 우선 순위 및 정렬
-
RabbitMQ
-
우선 순위 대기열을 사용하여 특정 메시지를 에스컬레이션할 수 있음
-
메시지는 전송된 순서대로 소비
-
-
Kafka
-
모든 메시지를 동등하게 취급하며, 메시지를 특정 순서로 정렬하지 않음
-
소비자는 파티션에서 메시지를 끌어오므로 순서가 달라질 수 있음
-
메시지 삭제 및 보존
-
RabbitMQ : 소비자가 메시지를 읽고 확인 응답(ACK)을 보내면, 메시지가 대기열에서 삭제
-
Kafka : 메시지는 로그 파일에 추가되어 보존 기간이 만료될 때까지 유지. 이 기간 내에 메시지를 여러 번 처리할 수 있음
기타 주요 차이점
-
보안
-
Kafka는 TLS와 JAAS를 통해 안전한 이벤트 스트림을 제공함
-
RabbitMQ는 사용자 권한 및 브로커 보안을 관리하는 도구를 제공함
-
-
프로토콜
-
Kafka는 TCP를 통한 바이너리 프로토콜을 사용함
-
RabbitMQ는 기본적으로 AMQP를 지원하며, STOMP와 MQTT와 같은 레거시 프로토콜도 지원함
-
표 정리
| 항목 | RabbitMQ | Kafka |
|---|---|---|
| 작성 언어 | Erlang | Scala, Java |
| 프로토콜 | AMQP | TCP 상의 바이너리 프로토콜 |
| 클라이언트 API | Java, Ruby, JavaScript, Go, C, Swift, Spring, Elixir, PHP, .NET | Java, Ruby, Python, Node.js |
| 유연한 라우팅 규칙 | Exchange 컴포넌트에서 지원 | 없음 |
| 메시지 소비 | push | pull |
| 메시지 우선순위 | 지원 | 지원 안 함 |
| 메시지 순서 | 큐에서 순서대로 처리 | 토픽에서 순서대로 처리 |
| 메시지 삭제 | ACK 시 삭제 | 보존 기간 만료 시 삭제 |
| 보안 | 관리자 도구를 통한 접근 관리 | TLS, JAAS |
| 확장성 | RabbitMQ 일관된 해시 교환 지원 | 토픽에 파티션 추가 |
| 내결함성 | 지원 | 지원 |
| 메시지 누적 압력 | 잘 처리하지 못함 | 메시지 처리를 위해 설계됨 |
| 성능 | 초당 수만 건 처리 가능 | 초당 수백만 건 처리 가능 |
| 생태계 | Kafka만큼 좋지 않음 | 빅 데이터 및 스트림 컴퓨팅에서 잘 지원됨 |
Kafka와 RabbitMQ 사용 시기
두 메시지 브로커는 서로 경쟁하는 것이 아니라, 유스 케이스에 따라 더 적합한 상황이 있음
-
Case 1: 수신된 데이터를 다시 분석해야 하는 애플리케이션
- Kafka는 메시지를 보존 기간 동안 유지하므로, 데이터를 다시 처리하거나 로그 파일을 분석하기에 적합함
- 반면, RabbitMQ는 사용된 메시지를 삭제하므로 로그 집계에 적합하지 않음
-
Case 2: 알림과 같은 실시간 데이터 처리
- Kafka는 낮은 지연 시간으로 실시간 데이터를 스트리밍하고 분석하는 데 이상적임
- 예를 들어, 분산 모니터링 서비스를 통해 온라인 트랜잭션 처리 알림을 실시간으로 생성할 수 있음
-
Case 3: 수신 확인 및 메시지의 특정 순서 및 전달 보장이 필요한 경우
- RabbitMQ는 메시지의 수신 확인과 우선 순위 대기열을 제공하여 메시지 전달 순서를 보장함
- Kafka는 이러한 기능이 없으므로, 특정 순서와 전달 보장이 필요하다면 RabbitMQ가 더 적합함
Kafka와 RabbitMQ는 각기 다른 강점을 지닌 메시지 브로커다. 애플리케이션의 요구 사항에 따라 적절한 브로커를 선택하는 것이 중요하다. Kafka는 대규모 데이터 스트리밍과 로그 수집에, RabbitMQ는 실시간 메시징과 작업 큐에 최적화되어 있다.
