✅ 무한 스크롤 도입
무한 스크롤이란?
- 아래로 스크롤 하다가 컨텐츠의 마지막 요소를 볼 즈음 다음 컨텐츠가 있으면 불러오는 방식
❓ 무한 스크롤 방식 도입 이유
- 페이스북, 인스타 피드 처럼 아래로 계속 스크롤 하면서 보는 기능을 구현하고 싶어서 도입
✅ 커서 기반 페이징
📌 오프셋 기반 페이지네이션의 문제점
1. UX 저하
-
id가 10~6까지 5개 게시물을 읽고, 다음 페이지 읽기 전 3개의 게시물이 추가 되었을 경우
-
오프셋 기반에서는 다음 페이지 요청 시 id가 8~4 인 게시물을 요청하게 된다 (위에 게시글이 3개 추가되서)
-
이런 경우, id가 8, 7, 6인 게시물은 다음 페이지에서 중복되어 보이게 된다
2. 성능 저하
select *
from post
order by id desc
limit 10
offset 10000000;-
offset 기반 페이징의 경우, 앞에서부터 데이터를 읽어오는 방식이기에 뒤 페이지 요청할 수록 성능이 점점 하락한다.
-
위 예시는 앞에서부터 천만개의 레코드를 읽고, 그 다음 10개의 레코드를 읽어오는 쿼리문이다.
위 단점을 모두 해결한 커서 기반 페이지네이션
- 커서 개념
-
여기서 커서(Cursor)는 마지막으로 읽은 데이터의 식별자 값을 말한다
-
즉, 마지막으로 읽은 게시물의 id 값이 커서이고, 이 값을 기준으로 다음 n개의 레코드를 요청한다
- 오프셋 기반 페이지네이션과 다른 점은?
"id 1000부터 10개의 데이터를 주세요" 요청 시,
-
오프셋 기반 페이지네이션은 앞에서부터 1000개 읽고 거기서부터 10개 데이터 가져옴 -> 1009개의 데이터를 읽음
-
커서 기반 페이지네이션은 id 값이 1000이 데이터를 기준으로 10개 데이터만 읽어서 가져옴
-
⭐ 즉, 필요한 개수만큼만 조회하기 때문에 항상 성능상의 이점이 존재함
⭐ 커서 기반 페이지네이션 적용 시 주의 사항
📌 무조건 항상 같은 정렬 조건으로 데이터를 조회해야함
- 만약 게시물을 id 기준으로 DESC 정렬하면
10, 9, 8, 7, 6, 5, 4, 3, 2, 1이 될 것임- 이 상태에서 커서를
6을 주면 6보다 아래에 있는 데이터를 가져옴 ->5, 4, 3, 2, 1을 가져올 것
- 이 상태에서 커서를
- 처음에는 id DESC 기준으로 5개 가져와 놓고, 다음에 가져올 때는 좋아요 개수로 정렬한 후 커서를
6으로 주면- 좋아요 수로 정렬 시 ->
8, 3, 4, 5, 7, 6, 2, 1, 10, 9이렇게 되고 여기서 6 아래의 데이터 가져오면 ->2, 1, 10, 9을 가져오게 된다.
- 좋아요 수로 정렬 시 ->
📌 커서는 정렬 기준 컬럼의 값 & 유니크해야 함
-
만약 좋아요 순으로 정렬된 데이터에 커서 기반 페이지네이션을 적용하고 싶은 경우
-
정렬 기준이
like DESC이므로 커서로 마지막으로 조회한 게시물의 좋아요 개수를 넘겨야 한다. -
만약 게시물의 좋아요 개수가 아닌 id값을 넘기게 되면 해당 id를 기준으로 짜르고 거기서 좋아요 순으로 정렬한 데이터를 가져옴.
SELECT * FROM POST WHERE id < lastId ORDER BY LIKE DESC; -
쿼리문은 WHERE문 먼저 실행되고 ORDER BY가 실행되기 때문에
lastId값보다 작은 id 값을 먼저 가져오고 거기서like로 DESC를 적용 -
우리가 생각하는 좋아요 순으로 커서 기반 페이지네이션이 적용되지 않음
-
- 또한,
like컬럼의 값은 유니크하지 않기에 정확히 어떤 게시물이 커서인지 파악할 수 없을 수 있다. - 그래서 커서로
like값과 해당 게시물의id값을 같이 넘겨주면 정확히 마지막으로 읽은 게시물을 기준으로 가져올 수 있음
SELECT * FROM POST
WHERE like < lastLike or (like = lastLike AND id > lastId)
ORDER BY like DESC, id ASC;✅ 분산 DB 환경에서 문제점
만약에 post 테이블이 여러 DB에 나눠서 저장되고 있다면 어떤 문제가 발생할까?
가정
-
ID 생성 전략은 AUTO-INCREMENT로
-
여러 DB에서 post 테이블 데이터를 가져와서 페이징을 위해 Id로 정렬한 상황
문제점
-
각 DB에서 게시물의 Id 값은 1, 2, 3, ... 이런 정수형 값임.
-
이걸 모아서 정렬하게 되면 Id 값이 중복되기에 사실 제대로된 정렬을 할 수 없음
해결 방안
- id 생성 전략을 정수형 AUTO-INCREMENT로 하지 않고 시간 의미가 포함된 id 생성 전략을 도입하자 = Snowflake Id 생성 전략
✅ Snowflake Id 도입
Snowflake Id란?
-
분산 DB 환경에서 각 DB에서 Id 생성 시, 고유한 Id를 생성하는 전략
-
64bit id 생성
-
64bit 안에 시간의 의미가 들어 있기에 이 id를 기준으로 정렬하는게 곧 시간 순으로 정렬하는 것이라고 볼 수 있음
생성 규칙
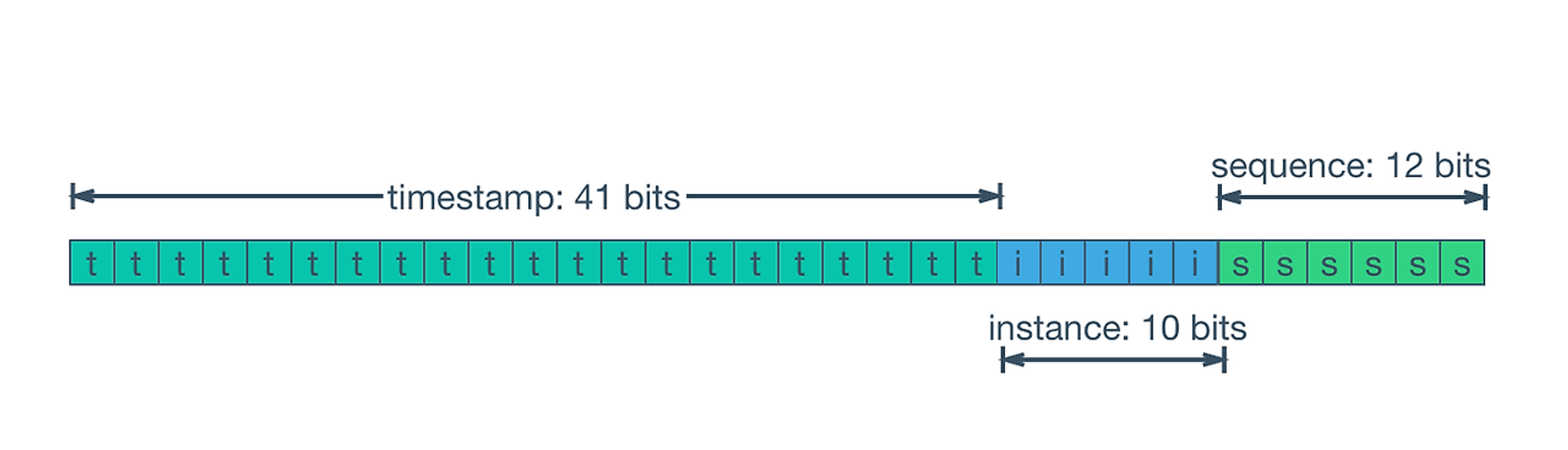
1. MSB는 sign bit
- 양의 정수가 되도록 항상 0 bit로 세팅
2. 다음 상위 41bit는 timestamp
-
현재 timestamp(ms) - 기준 timestamp
-
기준 timestamp 값은 개발자가 세팅 (만약
2024-05-29 00:00:00 UTC를 기준으로 삼으면 Unix timestamp 값은1717027201000 ms) -
41 bits로는 2의 41 제곱 -> 2조 2천언 ms 표현 가능함 -> 1년이 300억ms ->
69~70년 후에2조 ms를 오버플로우할 수 있음 = 넉넉하다~
3. 다음 상위 10bit는 instance
- 애플리케이션이나 DB의 고유 번호를 넣는다
4. 마지막 12bit는 sequence
-
동일한 장비에서 같은 밀리초 내에서 동시에 id 생성할 수 있도록 장비별 시퀀스 번호
-
같은 밀리초(같은 41bit timestamp 값), 같은 DB(같은 10bit instance)일 때, 동시에 4096개의 id를 생성할 수 있음
결론
-
무한 스크롤 도입하려니 오프셋 기반이 아닌 커서 기반 페이지네이션 도입해야 함
-
DB가 한 대인 경우에는 아무 문제 없지만, 분산 DB 환경이라면 기본 id 생성 전략으로는 분산 데이터 모아서 id 정렬 시, id가 중복되기에 정렬되지 않음
-
Snowflake id 생성 전략 도입해 분산 DB 환경에서도 id가 고유하게 생성되고, 시간의 의미도 들어 있기에 이 id로 정렬하면 시간순으로 정렬하는 것과 동일함
