
프로젝트의 모델 학습을 위한 사진 수집을 위한 방법을 알아보던 중 Unplash라는 사이트를 알게 되었다. 오늘은 Unplash API를 이용해 1000장의 사진을 수집해보겠다.
1. Unplash
Unsplash는 무료로 사용할 수 있는 고품질의 사진을 제공하는 사이트이다. API도 제공하기 때문에 개발자가 애플리케이션에서 사용할 이미지들을 편리하게 이용할 수 있다.
회원가입
API Access 키 발급
제품 -> 개발자/API
Your apps
New Application
일련의 과정을 마치고 나면 애플리케이션이 등록되고 access 키를 확인할 수 있다.
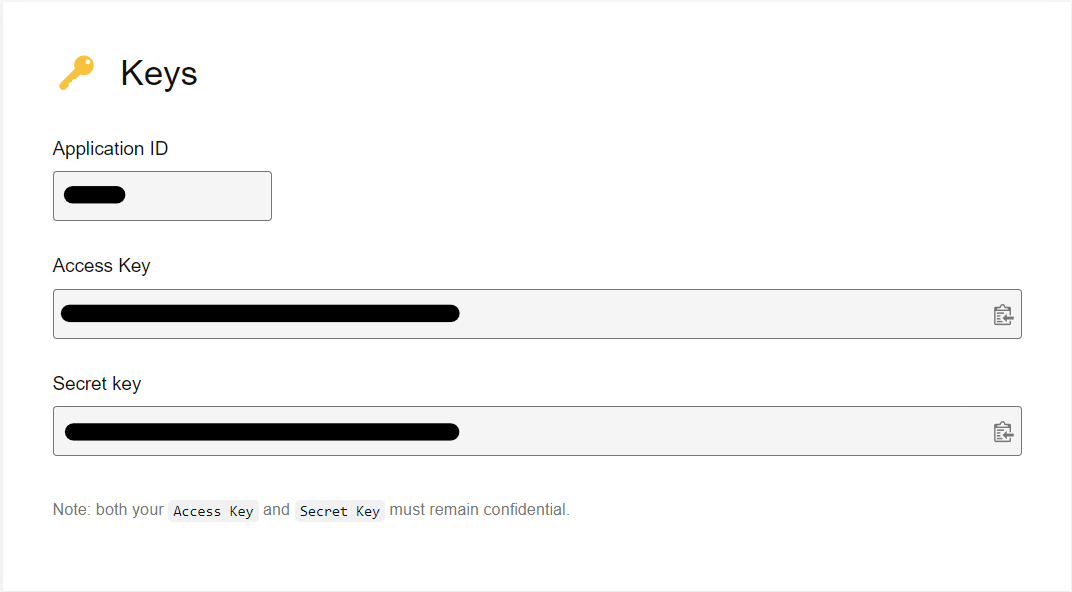
2. 이미지 URL 저장
이제 발급받은 access key로 api 호출을 통해 이미지 URL을 받아와 보자.
Jupyter Notebook
키워드 room으로 검색하여 API 호출로 사진 URL을 받아올 것이다. Unplash API로 한번에 받아올 수 있는 사진은 30장이므로 반복을 통해 1000장을 채워주자.
import requests
import json
# 액세스 키 설정
access_key = '{your access key}'
# API 호출 및 검색
query = 'room' # 검색할 키워드 설정
per_page = 30 # 한 번에 검색할 사진 수 설정
total_photos = 1000 # 얻고자 하는 총 사진 수 설정
# 사진 URL 저장을 위한 리스트
photo_urls = []
# 여러 번의 API 호출을 통해 사진 URL 얻기
page = 1
while len(photo_urls) < total_photos:
url = f'https://api.unsplash.com/search/photos?query={query}&per_page={per_page}&page={page}'
headers = {'Authorization': f'Client-ID {access_key}'}
response = requests.get(url, headers=headers)
data = json.loads(response.text)
# 검색 결과에서 사진 URL 추출하여 저장
for photo in data['results']:
photo_url = photo['urls']['regular']
photo_urls.append(photo_url)
if len(photo_urls) == total_photos:
break
page += 1이미지 URL 확인
받아온 URL은 CSV 파일로 저장하여 관리할 것이다.
import csv
# CSV 파일 경로 설정
csv_file = 'photo_urls.csv'
# CSV 파일에 사진 URL 저장
with open(csv_file, 'w', newline='') as file:
writer = csv.writer(file)
for photo_url in photo_urls:
writer.writerow([photo_url])만들어진 CSV 파일을 확인해보자.
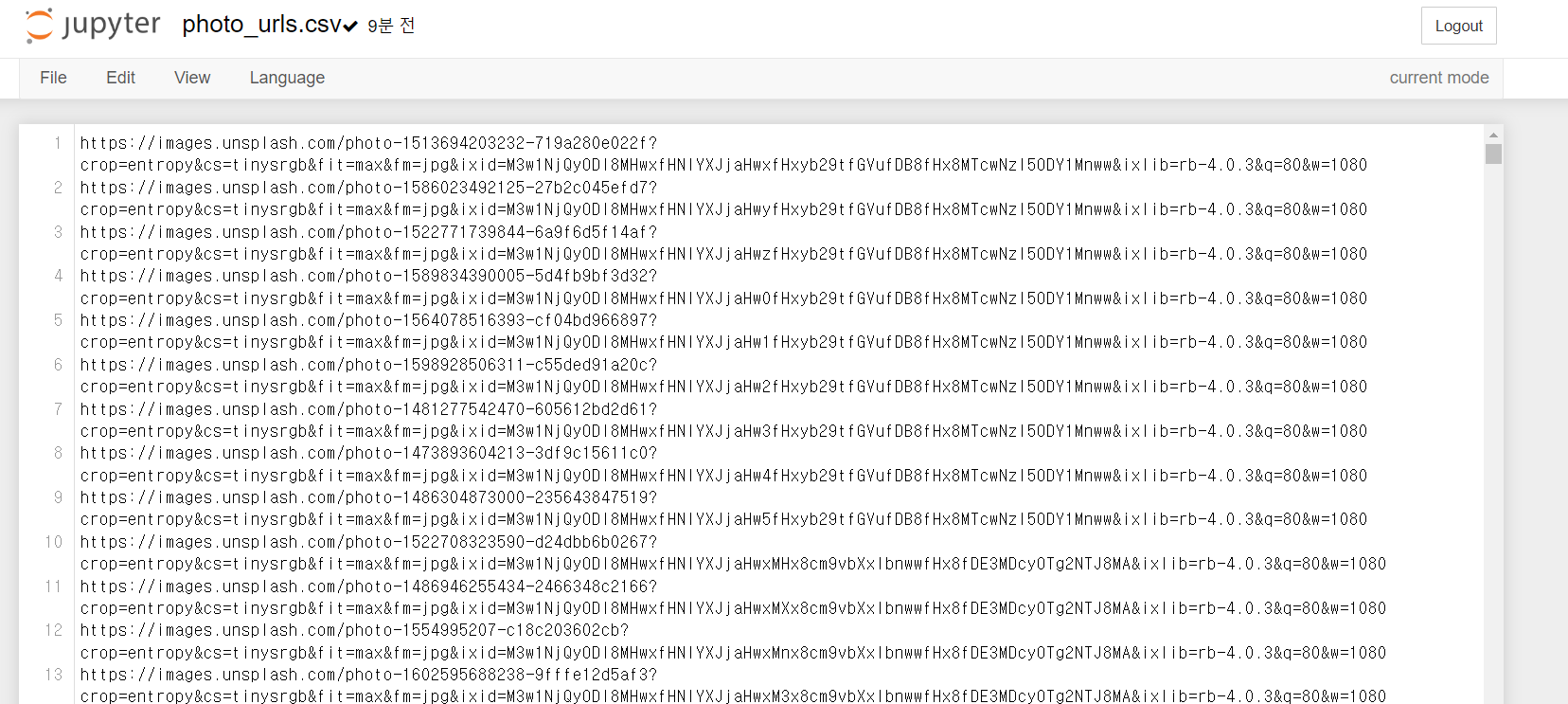
3. 이미지 다운로드
Jupyter Notebook
import csv
import requests
import os
from urllib.parse import urlparse
# CSV 파일 경로 설정
csv_file = 'photo_urls.csv'
# 다운로드할 사진을 저장할 폴더 생성
if not os.path.exists('photos'):
os.makedirs('photos')
# CSV 파일에서 사진 URL 읽어와 다운로드
with open(csv_file, 'r') as file:
reader = csv.reader(file)
next(reader) # 헤더 라인 스킵
for row in reader:
photo_url = row[0]
filename = os.path.basename(urlparse(photo_url).path)
filepath = os.path.join('photos', filename)
# 사진 다운로드
response = requests.get(photo_url)
with open(filepath, 'wb') as image_file:
image_file.write(response.content)
# 파일 확장자를 png로 변경
new_filepath = os.path.splitext(filepath)[0] + '.png'
os.rename(filepath, new_filepath)이제 다운로드한 사진들을 확인해보자.
다양한 사진들이 저장되어 있는데, 몇 번의 과정을 거쳐 데이터셋을 완성시킬 계획이다.


코딩 연구소