논문 리뷰 - Tourism recommendation system based on semantic clustering and sentiment analysis
틀린 내용이 있을 수 있습니다. 지적해주시면 반영하도록 하겠습니다.
Abstract
관광 명소를 추천하는 추천 시스템은 여행자에게 개인 맞춤형 서비스를 제공하는 것이 도전과제다.
이 논문에서는 개인 맞춤형 추천을 위해 사용자의 선호를 추출하는 추천 시스템을 소개한다.
사용자의 선호를 감지하기 위해 사용자의 리뷰를 전처리하고, semantic clustering과 감정 분석을 수행한다.
비슷하게 관심 지점(points of interest)의 특징을 추출하기 위해 관광 명소에 대한 사용자 리뷰들이 이용됐다.
최종적으로 고안된 추천 시스템은 사용자의 선호와 명소의 특징을 의미론적으로 비교하여 가장 매칭이 높은 지점을 사용자에게 추천하게 된다.
추가로 현재 상황에 맞는 추천을 위해 시간, 장소 그리고 날씨와 같은 contextual 정보가 활용되었다.
파이썬으로 개발된 이 시스템은 기존의 추천 시스템과 비교하여 f1 스코어에서 개선이 있음을 확인했다.
Introduction
관광 사이트나 소셜 네트워크 등 관광에 대한 데이터는 많아졌지만, 그것을 처리하는 것은 쉬운 일이 아니다. 그리하여 사용자들에게 맞춤 추천을 위한 관광 추천 시스템이 제안됐다.
방문 기록을 바탕으로 유사한 사용자끼리 묶은 클러스터에 동일한 추천을 하는 방식이 나오기도 했지만, 방문 기록으로만 판단하는 것은 불충분하다.
사용자의 리뷰 또한 중요하기에 코멘트를 분석하는 추천 시스템이 나온다. 하지만 어떤 단어를 부정적인 뜻으로 썼으나 많이 등장하면 선호와 관련된 단어로 인식될 수 있다는 문제를 가지고 있다.
즉, 코멘트에서 어떤 감정을 가졌는지 감정 분석이 필요하지만, 대부분은 이를 간과한다.
관광을 위한 추천 시스템은 다음 기능을 포함해야 한다.
- 특정 단어만 보는 것이 아니라 전체적인 concept를 보고 선호를 파악해야 한다.
- 긍정/부정 선호를 파악하기 위해 사용자의 코멘트를 감정 분석해야 한다.
- 사용자의 현재 상황에 적응하여 알맞은(context-aware) 추천해야 한다.
2. Related work
이 섹션에서는 관광 추천 시스템과 관련한 연구를 보여준다.
경로가 비슷한 유저를 군집화하는 방법, 장소나 시간, 속도, 방향과 날씨 정보를 이용한 방법이 제안되었음이 보인다.
그 외에도 딥러닝으로 명소의 카테고리를 추출하는 방법, 필요 없는 단어를 고려하지 않고 단순히 코멘트를 분석하는 방법 등 여러 연구를 나열하고 있다.
최종적으로 논문에서는 감정 분석을 통해 기존의 결과물보다 성능이 좋음을 알리고 있다.
3. Proposed System
논문에 제시된 추천 시스템은 3단계로 이루어져 있다.
- 코멘트와 리뷰에서 사용자의 선호 추출
- 여행객들이 관광 명소에 남긴 리뷰에서 명소의 특징 추출
- 사용자와 관광 명소의 유사도 비교와 더불어 현재 상황 정보(contextual infomation)를 고려한 적절한 관광 명소 제안
다음은 추천 시스템을 의사 코드로 설명한 그림이다.

여기서 등장하는 PoI가 Point of Interest, 관심 지점이다.
3.1. Extracting preferences
선호를 추출할 때는 다시 4가지 단계로 나뉜다.
- 전처리
- Semantic Graph 생성
- 군집화
- 선호 추출
전처리할 때는 다음과 같은 과정을 거친다.

PoS(Part of Speech) tagging: 문장의 각 단어의 품사를 식별하여 태그를 붙이는 과정이다.
Eliminating stop words: stop words는 불용어라는 의미로 문장에서 의미가 없는 단어를 제거하는 과정이다.
Stemming: Stemming은 어간 추출이라는 뜻인데 여기서 어간(stem)은 단어가 변하지 않는 부분을 의미한다. 예를 들어 밥을 먹다의 먹다는 먹어, 먹자와 같이 끝이 변할 수 있지만 '먹'은 변하지 않으므로 어간이라고 할 수 있다.
Extracting nouns: 명사가 가장 중요한 정보를 나타내므로 명사만 따로 추출하면 연산을 효율적으로 할 수 있다.
이 과정을 통해 명사로 분류된 단어들을 추출할 수 있다.
다음은 명사 유사도 행렬을 구성한다.
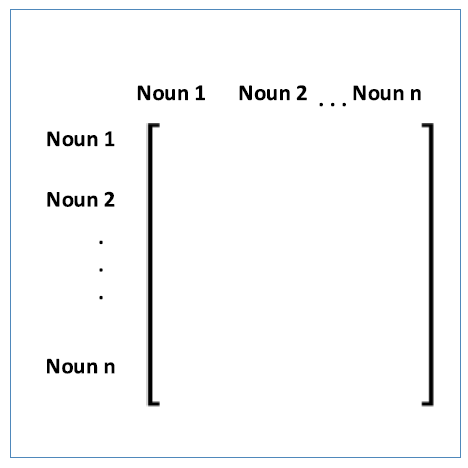
그림에서 알 수 있듯이 대칭 행렬의 형태로 각 단어 쌍의 유사도를 표현한다.
명사 유사도 행렬을 만들기 위해서 Wu-Palmer semantic similarity와 Extended gloss overlaps를 섞은 hybrid semantic similarity measure가 사용된다.
유사도를 계산했으면 평가를 할 수 있도록 정규화가 필요하고 정규화를 위해 모든 원소를 원소의 최댓값으로 나눈다.
그러면 각 단어 쌍의 유사도는 가중치 있는 간선으로 간주할 수 있고 임계치를 넘는 가중치만 연결되도록 하여 그래프의 집합으로 표현할 수 있다.
이때 각각의 연결 컴포넌트가 바로 클러스터가 된다. 동일한 클러스터에 속한 단어들은 서로 의미상으로 유사한 것으로 간주한다.
마지막으로 각 문장은 클러스터로 전달되는데 한 문장에 여러 단어가 있는 만큼 여러 클러스터에 할당될 수 있다.
그리고 이 클러스터들은 명사의 빈도와 감정 분석에 의해 점수가 매겨진다.
감정 분석의 목적?
감정 분석은 사용자의 코멘트에 담긴 기분을 감지하고 대상에 대해 어떻게 생각하는지 이해하기 위함이다.
감정 분석은 Sentiwordnet의 도움을 받아 수행된다. 이때 한 단어가 서로 다른 의미와 감정적 부하(load)를 내포할 수 있으므로 그 단어가 속한 synset의 긍정/부정 부하가 해당 단어의 긍정/부정 부하로 사용된다.
Synset
위키피디아에서 Synset은 동의어 집합이라는 의미를 가지고 있다.
각 문장의 점수는 긍정 점수 - 부정 점수로 계산된다. 이모티콘 역시 계산 대상(-1과 1)에 포함된다.
각 클러스터의 감정 분석 점수는 다음과 같은 식으로 표현된다. (한 문장에 여러 클러스터가 할당될 수 있음을 상기하고 보면 더 잘 이해할 수 있다.)
클러스터 i에 속한 문장의 감정 분석 점수가 높을수록 클러스터 i의 감정 분석 점수가 높아진다는 의미이다.
이렇게 구한 클러스터의 감정 분석 점수와 출현 빈도인 TF를 곱하여 클러스터의 최종 점수를 구할 수 있다.
여기서 점수가 가장 높은 클러스터가 선택되며 최대와의 점수 차이가 10 미만인 것도 포함할 수 있다. 이렇게 선택된 클러스터의 명사 집합이 사용자의 선호가 된다.
3.2. Extracting attractions features
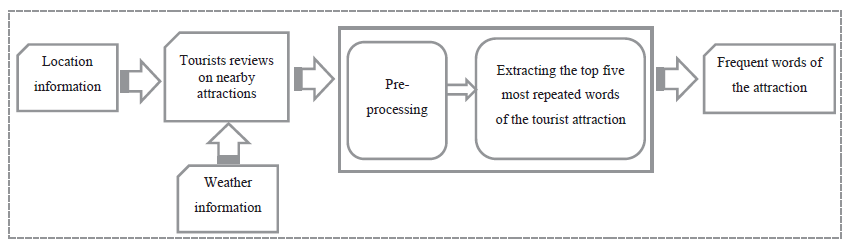
이제 관광 명소의 특징을 추출하자. (그래야 관광객과 유사도를 계산할 수 있으니까)
해당 연구에서는 관광 명소마다 3성 미만의 평점을 제외한 리뷰를 수집한다. 또한 관광 명소는 계절마다 다른 특성을 가질 수 있으므로 5개의 계절(눈, 비, 화창, 폭풍, 흐림)로 전처리한다.
그런 다음 날씨마다 자주 등장하는 5개의 단어를 추출하여 이를 명소의 특징으로 사용한다.
3.3. Recommendation system
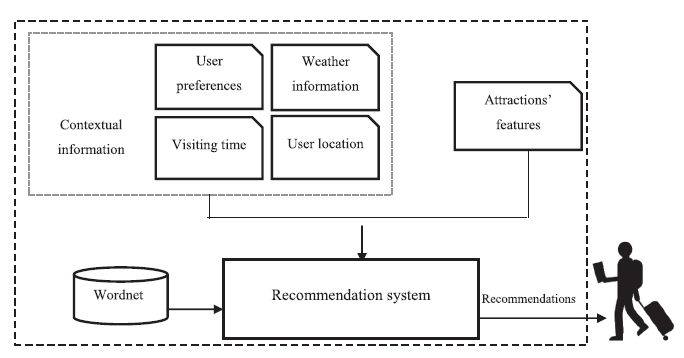
해당 논문에서 제안된 추천 시스템의 메인 아이디어는 관광객의 선호와 가까운 명소의 특징을 비교하여 가장 유사한 명소를 리턴하는 것이다.
사용자의 선호 집합 와 관광 명소의 특징 집합 의 유사도를 계산하기 위해 다음과 같은 식이 사용된다.
와 가장 유사도가 높은 를 찾아 이들의 유사도를 합산한 뒤 의 개수에 따라 평균을 내는 방식이다.
마지막으로 날씨에 따라 우선순위를 조정한다. 가령 비가 오는 날씨의 경우 야외보다는 실내 장소에 더 우선한다.
4. Evaluation
논문에서 제안된 추천 시스템은 파이썬 아나콘다로 개발되었다. (코드는 찾아볼 수 없었다)
데이터셋은 트립어드바이저에서 추출했는데 서로 다른 배경을 가진 여행자 100명의 리뷰와 명소 방문 기록이 데이터로 사용되었다. (2018년 1월부터 6월까지)
그리고 2018년 7월부터 기록된 데이터를 테스트 데이터로 사용했다.
감정 분석은 Sentiwordnet 3.0으로 수행했다.
사용자의 리뷰를 긍정과 부정으로 분류하도록 하고 이를 사용자의 평점(1~2점은 부정, 4~5점은 긍정)과 SVM, 그리고 베이지안 네트워크와 비교한 결과 다음 결과를 얻을 수 있었다.
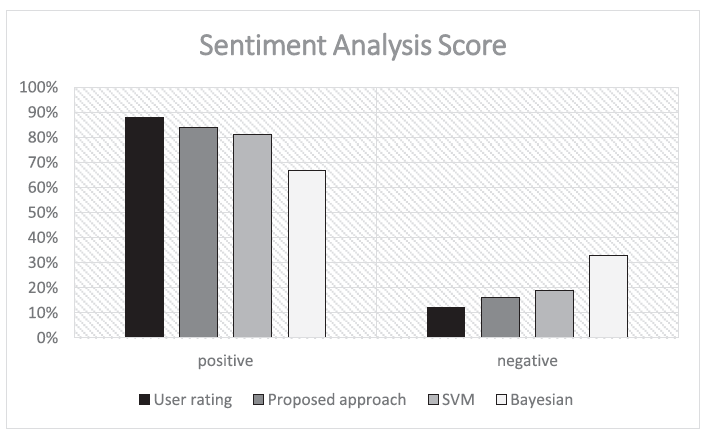
평점 기반 분류를 정답이라고 할 때, 논문에 제안된 방식이 다른 두 모델보다 뛰어남을 보여준다.
Semantic similarity를 계산하기 위해서 Wu-palmer similarity와 Extended Gloss Overlaps를 결합한 하이브리드 방식을 선택했다.
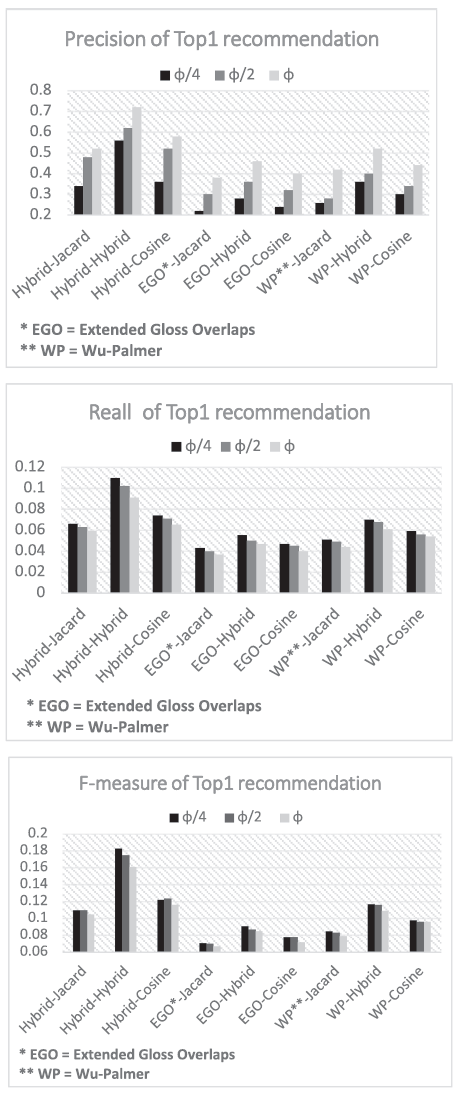
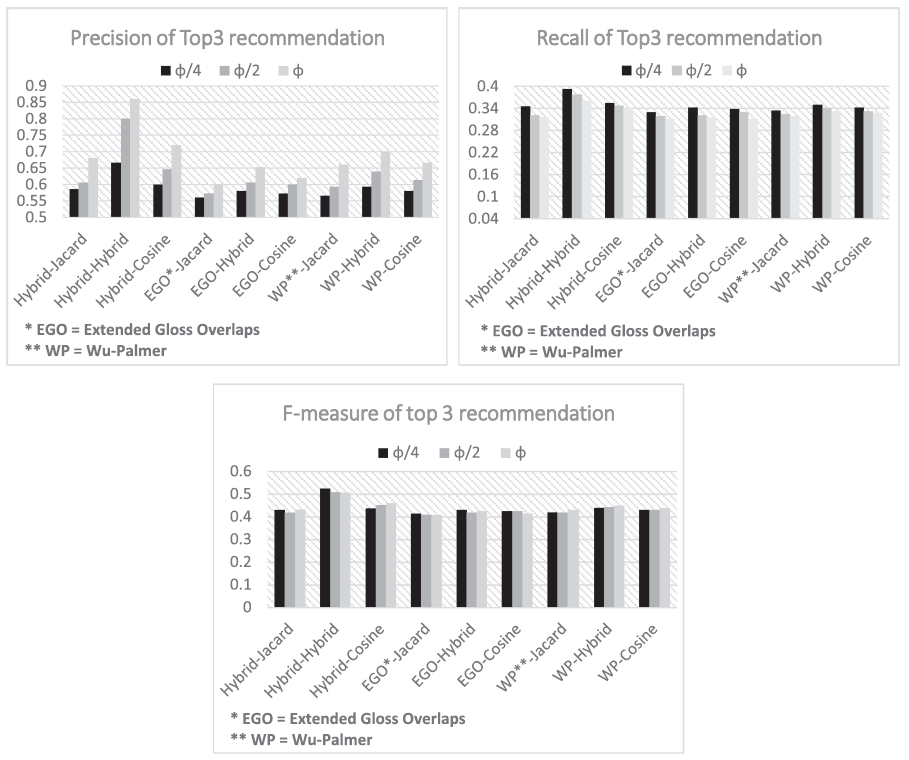
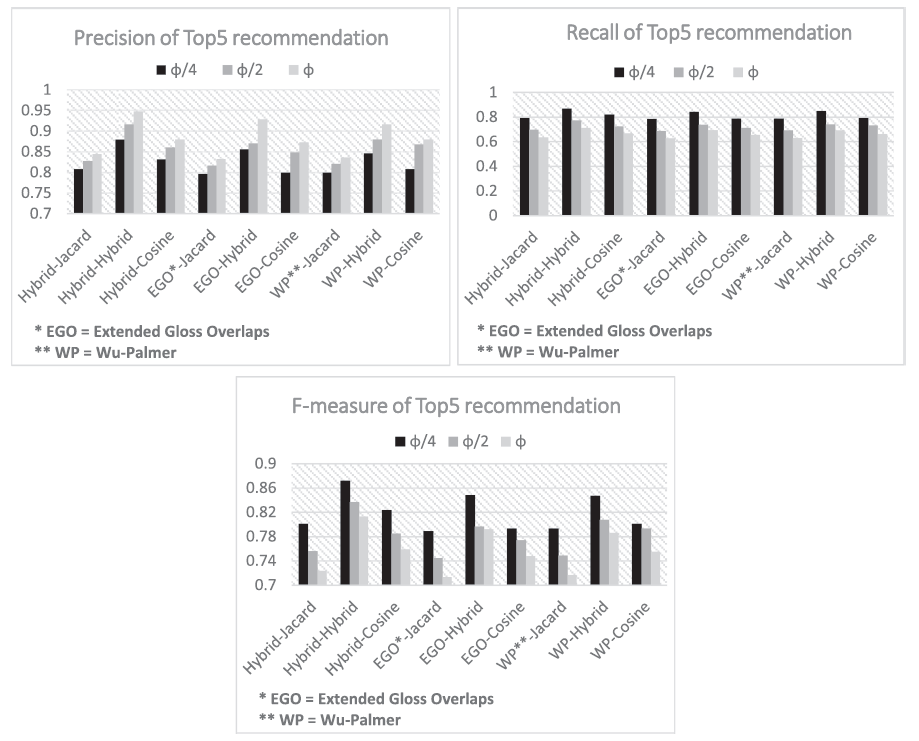
제시된 표에서 각 항목이 A-B 형태로 표현되어있는데 여기서 A는 semantic clustering을 위해 사용된 방법, B는 사용자의 선호와 명소의 유사성 계산을 위해 사용된 방법을 의미한다. 또한 는 여행자의 현재 위치에서 명소를 추천받을 최대 거리를 나타낸다.
표에서 알 수 있듯이 모두 하이브리드 방식을 사용한 것이 성능이 가장 좋으며, 상위 5개의 아이템을 추천했을 때 가장 좋은 성능을 보여주었다. 그리고 거리가 짧을수록 F1 score와 recall이 높고, 그 반대일수록 presicion이 높은 경향을 나타낸다.
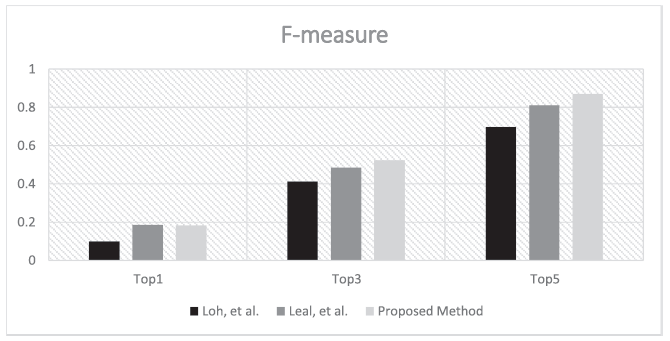
마지막으로 이 추천 시스템을 기존에 제시된 결과물과 비교했을 때는 다음과 같이 논문의 추천 시스템이 가장 성능이 좋음을 보여준다.
Conclusion
이 논문에서 semantic clustering과 감정 분석을 통해 사용자의 선호를 추출한 추천 시스템이 제시되었다.
기존에 있던 추천 시스템과 비교하여 더 나은 성능을 보여줌을 확인했지만, 교통 트래픽이나 여행 인원과 같은 정보는 쓰이지 않았다.
보통 사용자들이 그룹으로 여행을 떠나는 만큼, 미래 연구에서는 그룹으로 여행을 떠나는 경우에도 적용할 수 있도록 하는 것이 중요하다.