Paper Review
1.[Paper review] ViTA : An Efficient Video-to-Text Algorithm using VLM for RAG-based Video Analysis System

ViTA는 light·heavy-weight VLM을 결합해 비디오→텍스트 변환을 대폭 가속화한다. RAG 시스템에 빠르게 비디오 정보를 저장해 LLM이 활용하도록 돕는다.
2024년 12월 29일
2.[Paper Review] QLoRA: Efficient Finetuning of Quantized LLMs
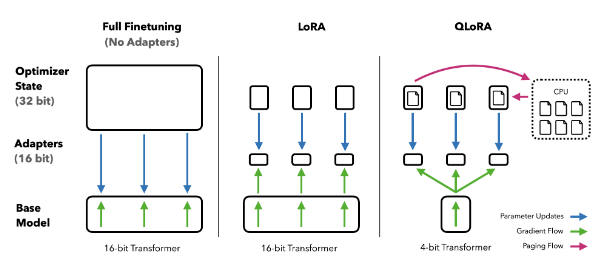
🔗 https://arxiv.org/abs/2305.14314 LoRA 와 nf4로 양자화 한 pretrained language model 을 사용하는 방식
2025년 1월 17일
3.[Paper review] Robust Speech Recognition via Large-Scale Weak Supervision

* Robust Speech Recognition via Large-Scale Weak Supervision [Paper] [[Github]] (https://github.com/openai/whisper)* Alec Radford, Jong Wook Kim, Tao
2025년 4월 15일