[Paper review] ViTA : An Efficient Video-to-Text Algorithm using VLM for RAG-based Video Analysis System
Paper Review

ViTA : An Efficient Video-to-Text Algorithm using VLM for RAG-based Video Analysis System
[ 해당 논문은 CVPR workshop papar 로 2024에 발행되었습니다. ]
LLM(Large-Language model)은 학습되지 않은 데이터를 제대로 이해하지 못한다는 한계를 지닌다. 특히 학습 이후에 등장하는 새로운 데이터나 기업 내부 데이터처럼, 모델이 한 번도 본 적 없는 정보에 대해서는 답변이 부정확해지기 쉽다.
이 문제를 해결하기 위해 많이 쓰이는 방법이 RAG(Retrieval-Augmented Generation)다.
RAG의 작동 과정을 간단히 설명하면 다음과 같다.
- 질문(Query)이 들어오면
- Vector DB(= Knowledge Base)에서 쿼리와 유사한 문서를 검색(Retrieval)한 뒤
<유사한 문서 검색은 코사인 유사도 같은 방법을 이용한다. >- 이 문서들을 LLM에게 맥락(Context)으로 제공하고
- LLM은 그 정보를 활용해 최종 답변(Generation)을 만든다.
이 방식을 통해서 LLM 이 알지 못했던 데이터도 RAG를 통해 보완해서 답변할 수 있다. 이 때문에 LLM과 RAG를 결합하여 쓰이는 방식이 널리 사용되고 있다.
하지만 RAG는 textual data만 저장할 수 있다. 따라서 기업 내부 데이터가 비디오나 이미지 같은 형태라면, 먼저 텍스트로 변환해야 한다. 특히 비디오 데이터는 양이 방대하므로 빠르게 텍스트로 변환하는 것이 중요하다.
이 논문에서 제안하는 ViTA는, 비디오 데이터를 RAG에 빨리 저장해 LLM이 활용할 수 있도록 돕는 알고리즘이다. 텍스트가 아닌 데이터를 텍스트로 변환하는 과정이 핵심이며, 이때 VLM (Vision-Language Model)이 사용된다. VLM은 이미지나 비디오를 보고 이에 대한 설명 text 를 출력으로 얻을 수 있다. VLM은 파라미터 수에 따라서 lightweight와 heavyweight로 나눌 수 있다.
- lightweight VLM : 속도가 빠르지만 세부 정보가 부족할 수 있다.
- heavyweight VLM : 풍부한 정보를 뽑아낼 수 있지만 시간이 오래 걸리는 단점이 있다.
ViTA는 두 가지 VLM을 섞어서 사용하는 하이브리드 접근을 제안한다.
lightweight VLM으로 먼저 대략적인 정보를 얻은 뒤, heavyweight VLM에게 추가 세부 정보를 토큰 수 제한 등으로 최소한만 생성하도록 함으로써, 비디오-텍스트 변환 시간을 크게 줄이면서도 필요한 정보는 놓치지 않도록 한다.
Motivation - StreetAware dataset experiment
StreetAware dataset의 sample image
lightweight, heavyweight VLM 의 속도와 출력을 비교하기 위해서 StreetAware 데이터셋으로부터 실험을 진행하였다. 해당 데이터는 뉴욕 시의 거리를 찍은 데이터로 위 사진은 데이터셋의 sample 이미지이다.
비교를 위해 사용된 모델은 아래와 같다.
- lightweight VLM : BLIP (247.4M)
- heavyweight VLM : InternLM-XComposer2 (7B) , LLAVA-1.5-7B: 7B
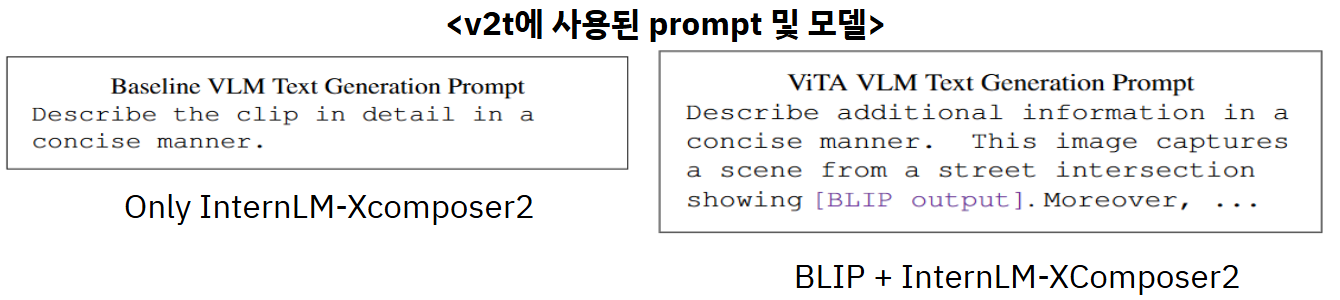
해당 이미지에 대한 세 가지 모델의 출력 값은 아래와 같다.

BLIP은 데이터셋에 대한 간단한 설명을 output으로 도출하고, heavyweight VLM인 InternLM-Xcomposer2와 LLAVA는 좀 더 풍부한 설명을 생성한다. 또한, heavyweight VLM은 최대 출력 토큰 제한(max token limit)이라는 매개변수를 제공하여, 생성할 텍스트 양을 조절해 추론 속도를 제어할 수 있다. 예를 들어, 16·32·64·128·256처럼 최대 출력 토큰을 다르게 설정하여 결과를 조절한다.
아래 표는 각 모델의 출력 속도를 비교한 것이다.
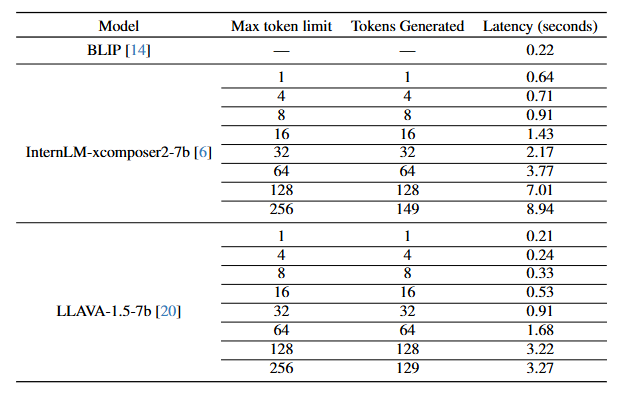
- BLIP은 0.22초 만에 출력을 생성한다.
- InternLM-Xcomposer2는 최대 256 토큰 생성 시 8.94초가 소요되지만, 64 토큰으로 줄이면 3.77초 만에 결과가 나온다. 이를 통해 토큰 수를 줄이면 처리 속도가 빨라진다는 것을 알 수 있다.
- LLAVA의 경우 256 토큰 생성 시 3.27초로, InternLM-Xcomposer2보다 빠르지만 BLIP보다는 느리다.
ViTA
ViTA 의 동작에 대해서 자세히 알아보자
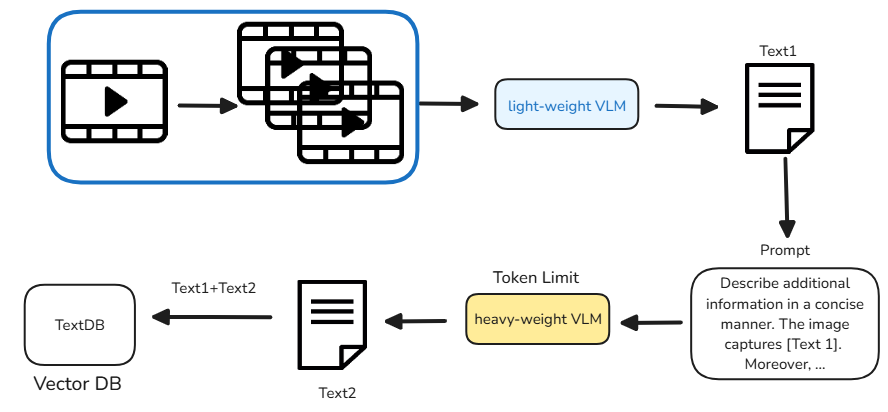
비디오는 PySceneDataset을 통해 프레임 단위로 분할된다.
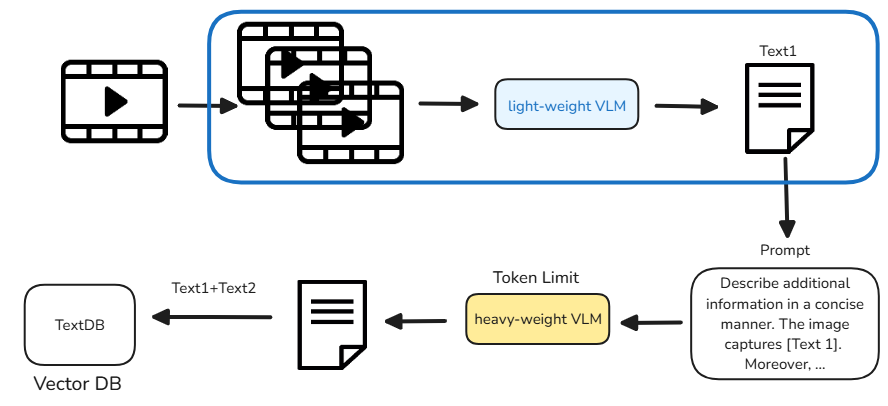
분할된 클립들은 BLIP 같은 lightweight VLM으로부터 텍스트 설명을 뽑아낸다.
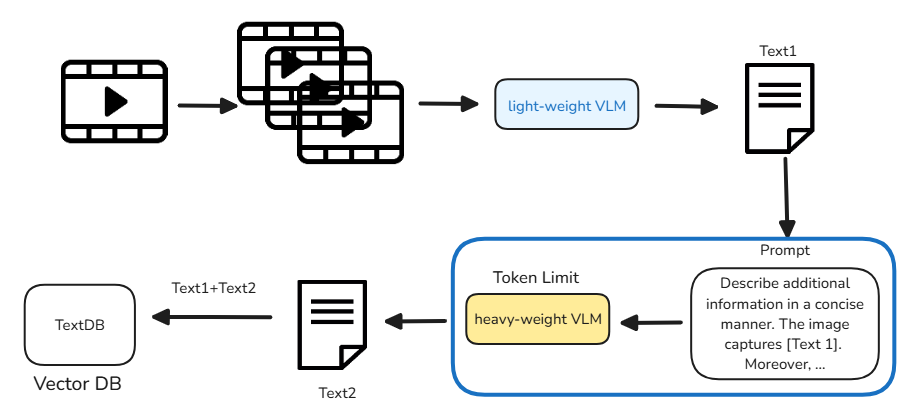
Lightweight VLM을 통해 얻은 텍스트 값은 Prompt와 결합되어 Heavyweight VLM의 입력으로 들어간다. 이때 Heavyweight VLM은 토큰 수를 제한해 응답을 생성하도록 하여, 비디오 내용을 깊이 파악하면서도 불필요하게 긴 출력을 방지한다. 이렇게 하면 적은 토큰으로도 풍부한 정보를 뽑아낼 수 있어 전체 변환 시간을 크게 단축할 수 있다.
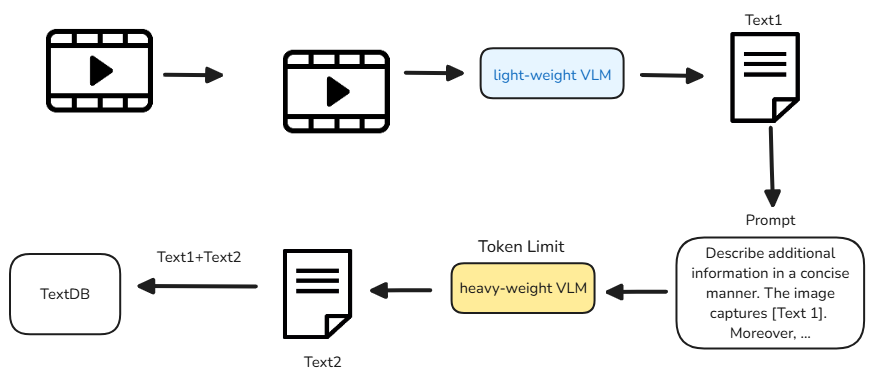
lightweight VLM을 통해 나온 text1과 heavyweight VLM을 통해 나온 text2가 concat 되어서 vectorDB에 저장된다.
Evaluation
비디오에 대한 설명이 생성되는 속도를 비교하기 위해 실험을 진행했다.
Baseline은 InternLM-XComposer2 단일 모델만 사용하고,
ViTA는 BLIP + InternLM-XComposer2를 함께 사용한다.
StreetAware와 Tokyo MODI 데이터셋을 대상으로 두 방식을 비교 실험했다.
v2t(video-to-text)에 사용된 Prompt는 아래와 같다.
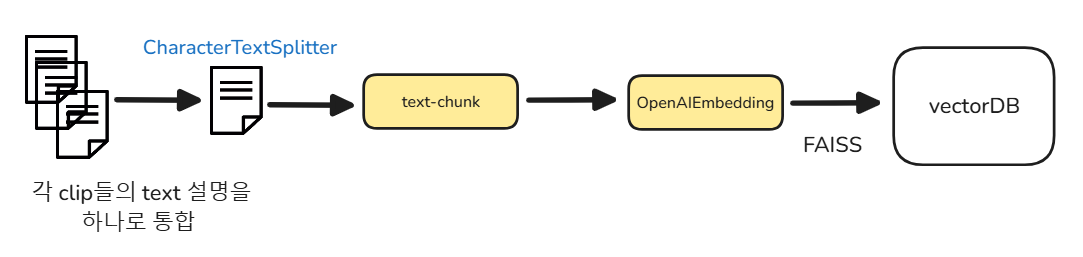
해당 프롬포트를 통해서 얻은 각 클립별 텍스트 설명은 하나로 합쳐지고, 그 문서는 CharacterTextSplitter를 통해 여러 text-chunk로 쪼개진다. 이후 OpenAIEmbedding으로 임베딩 값을 만들고, FAISS를 통해 vector DB에 저장된다.
Video-to-Text Conversion Time Reduction

- StreetAware(46m):
- Baseline 방식은 36분 15초가 걸렸다.
- ViTA는 20분 25초로 43.7% 빨라졌다. - TokyoMODI(2h):
- ViTA는 2시간짜리 비디오를 46분 22초 만에 변환해, 40.58% 정도 시간을 단축했다.
Query Result
Baseline과 ViTA로 생성된 텍스트 정보를 vectorDB에 저장한 뒤, 질의응답 성능을 확인하기 위해 아래처럼 몇 가지 질문을 GPT-3.5-turbo-1106(temperature=0)에 물어봤다.

2번, 6번 쿼리를 제외하고는 Baseline과 ViTA가 유사한 응답을 했다.2번 쿼리에 대해 ViTA는 총 4개의 context를 활용해 답변했는데, Baseline과 문맥 시간이 완전히 일치하지는 않았지만, 결국 비슷한 이미지 장면을 찾아냈다.

6번 쿼리에서는 Baseline이 “I don’t know”라고 답한 반면, ViTA는 “Yes, at 00:24:28:929, there is a person crossing the street with a child.”라는 구체적인 답을 내놓았다. 즉, 쿼리 의도를 잘 파악해 해당 문맥을 찾은 셈이다.

TokyoMODI 데이터셋에 대한 응답으로는 2번 쿼리에 대해서 baseline rag 기반 llm 과 ViTA rag 기반 llm의 응답이 달랐다. baseline 은 2번 쿼리에 대해서 제대로 대답했지만, ViTA는 뽑아낸 정보가 부족하여서 제대로 대답하지 못하였다.

Conclusion
ViTA는 lightweight VLM과 heavyweight VLM을 결합해 비디오 데이터를 텍스트로 변환하는 과정을 효과적으로 가속화한다.
video-to-text 변환 시간을 최대 43%까지 줄이는 동시에, 질의응답 정확도도 baseline과 비슷하게 유지한다.
다만 lightweight VLM과 heavyweight VLM의 출력이 중복되는 문제가 발생할 수 있다. 앞으로는 프롬프트 최적화를 통해 이러한 중복을 줄이고, 전반적인 성능을 더욱 향상시킬 계획이다.
내용에 대한 오류, 궁금증이 생기신다면 언제든 댓글로 남겨주세요. 감사합니다 😁
