
코딩테스트(1463)
문제해결
회원가입
이메일인증은 되는데 회원가입이 안됨
- '회원가입 완료' 버튼을 눌렀을 때 화면의 내용이 모두 비워지고 아무런 진행이 되지 않는 현상
- 프론트엔드 코드의 오타와 폼 제출 방식의 한계
원인
- HTML과 JS의 ID 불일치 (치명적 오타)
- HTML의 폼 태그는
<form id="signupForm"> - 하지만 JavaScript에서는
document.getElementById('signup-form')을 찾음 - 자바스크립트가 폼을 찾지 못해 에러가 발생했고
- 결국 방어 로직(
e.preventDefault())이 아예 작동하지 않았음
- 결국 방어 로직(
- HTML의 폼 태그는
- 기본 폼 제출(Default Submit)로 인한 새로고침
- 자바스크립트가 고장 난 상태에서
<button type="submit">을 누르면- 브라우저는 HTML 기본 동작인 action 주소로 GET 요청을 보냄
- action 속성이 없으므로 현재 페이지로 다시 이동하게 되고
- 이 과정에서 페이지가 새로고침(Refresh)되며 적어두었던 글자들이 전부 날아가게 된 것
- 자바스크립트가 고장 난 상태에서
- HTML과 JS의 ID 불일치 (치명적 오타)
해결
- 더 최선의 방법 (AJAX/Fetch API 도입)
- 폼의 기본 제출 방식을 완전히 막아버리고, 자바스크립트의 fetch를 이용해
- 비동기(AJAX)로 백엔드 API(/api/v1/user/signup/)에 데이터를 쏘아주는 방식 채택
- 이렇게 하면
- 1) 페이지 새로고침 없이 깔끔하게 에러(예: 닉네임 중복 등)를 잡아내어 알림창을 띄움
- 2) 비밀번호 확인(비밀번호와 비밀번호 확인 칸이 일치하는지) 같은 추가 검증도
- 프론트엔드에서 안전하게 수행 가능
- 더 최선의 방법 (AJAX/Fetch API 도입)
<form id="signupForm">
<div class="form-group mb-3">
...
</div>
...
——————————————————————————————————————[기본]—————————————————————————————————————————
document.getElementById('signup-form').addEventListener('submit', function (e) { // 회원가입 폼이 제출(Submit)될 때 실행됩니다.
if (!isEmailVerified) { // 만약 이메일 인증이 완료되지 않은 상태라면
e.preventDefault(); // 폼이 백엔드로 넘어가는 것을 강제로 막아버립니다.
alert("이메일 인증을 먼저 완료해주세요!"); // 경고창을 띄워 사용자에게 알려줍니다.
document.getElementById('email').focus(); // 사용자의 커서를 다시 이메일 칸으로 이동시켜줍니다.
}
// 인증이 완료된 상태(isEmailVerified == true)라면, e.preventDefault()가 실행되지 않아 정상적으로 백엔드(/user/signup/)로 데이터가 전송됩니다.
});
——————————————————————————————————————[비교]—————————————————————————————————————————
document.getElementById('signupForm').addEventListener('submit', async function (e) {
// 브라우저가 멋대로 페이지를 새로고침하는 현상을 무조건 막아줌
e.preventDefault();
// 이메일 인증을 안 했다면 가입을 막고 이메일 칸으로 커서를 이동시킴
if (!isEmailVerified) {
alert("이메일 인증을 먼저 완료해주세요!");
document.getElementById('email').focus();
return; // 함수 실행을 여기서 멈춰서 서버로 데이터를 보내지 않음
}
// 사용자가 입력한 데이터들을 HTML 요소에서 꺼내와 변수에 담음
const email = document.getElementById('email').value;
const nickname = document.getElementById('nickname').value;
const password = document.getElementById('password').value;
const passwordConfirm = document.getElementById('passwordConfirm').value;
// 비밀번호와 비밀번호 확인 칸에 적은 내용이 똑같은지 검사하는 '프론트엔드 방어 로직'을 추가
if (password !== passwordConfirm) {
alert("비밀번호가 일치하지 않습니다. 다시 확인해주세요.");
document.getElementById('passwordConfirm').focus();
return;
}
// 가입 버튼을 누른 후, 사용자가 버튼을 여러 번 눌러 중복 가입되는 것을 막기 위해 버튼을 잠금
const submitBtn = this.querySelector('button[type="submit"]');
const originalBtnText = submitBtn.innerText;
submitBtn.disabled = true;
submitBtn.innerText = "회원가입 처리 중...";
try {
// 새로고침 없이 백엔드 회원가입 API로 데이터를 몰래 쏴주는 fetch 비동기 통신을 시작
const response = await fetch('/api/v1/user/signup/', {
method: 'POST', // 데이터를 생성하므로 POST 방식을 사용
headers: {
'Content-Type': 'application/json', // 데이터를 JSON 형태로 보낸다고 알림
'X-CSRFToken': csrftoken // Django의 보안 검사를 통과하기 위한 토큰
},
// 이메일, 닉네임, 비밀번호를 JSON 문자열로 예쁘게 포장해서 보냄
body: JSON.stringify({
email: email,
nickname: nickname,
password: password
})
});
// 백엔드에서 돌아온 대답(성공/실패 등)을 JSON 형태로 해독
const data = await response.json();
if (response.ok) {
// 백엔드 응답이 201 Created 등 성공적이라면, 축하 알림을 띄움
alert("회원가입이 성공적으로 완료되었습니다! 로그인 페이지로 이동합니다.");
// 가입이 완료되었으므로 깔끔하게 로그인 페이지로 사용자를 이동
window.location.href = "/api/v1/user/login-page/";
} else {
// 이메일 중복, 닉네임 중복 등 백엔드에서 빠꾸를 먹였다면 에러를 보여줌
let errorMsg = "회원가입에 실패했습니다.";
// DRF 특성상 배열 형태로 에러가 올 수 있으므로 이를 안전하게 꺼내옴
if (data.email) errorMsg = data.email[0];
else if (data.nickname) errorMsg = data.nickname[0];
else if (data.password) errorMsg = data.password[0];
else if (data.message) errorMsg = data.message;
alert(errorMsg);
}
} catch (error) {
// 서버가 꺼져있거나 인터넷이 끊기는 등 아예 통신이 안 된 경우의 예외 처리
alert("서버 통신 중 오류가 발생했습니다.");
} finally {
// 가입에 실패했거나 통신이 끝났다면, 사용자가 다시 시도할 수 있도록 버튼의 잠금을 풀어줌
submitBtn.disabled = false;
submitBtn.innerText = originalBtnText;
}
});회원가입에 실패했습니다 반복
- 백엔드가 보내는 모든 종류의 메시지를 알림창으로 띄우도록 자바스크립트의 에러 캐치 부분을 수정
// 백엔드에서 돌아온 대답(성공/실패 등)을 JSON 형태로 해독
const data = await response.json();
if (response.ok) {
// 백엔드 응답이 201 Created 등 성공적이라면, 축하 알림을 띄움
alert("회원가입이 성공적으로 완료되었습니다! 로그인 페이지로 이동합니다.");
// 가입이 완료되었으므로 깔끔하게 로그인 페이지로 사용자를 이동
window.location.href = "/api/v1/user/login-page/";
} else {
// 이메일 중복, 닉네임 중복 등 백엔드에서 빠꾸를 먹였다면 에러를 보여줌
let errorMsg = "회원가입에 실패했습니다.";
// DRF 특성상 배열 형태로 에러가 올 수 있으므로 이를 안전하게 꺼내옴
if (data.email) errorMsg = data.email[0];
else if (data.nickname) errorMsg = data.nickname[0];
else if (data.password) errorMsg = data.password[0];
else if (data.message) errorMsg = data.message;
alert(errorMsg);
}
}
——————————————————————————————————————[비교]—————————————————————————————————————————
const data = await response.json();
if (response.ok) {
// [리뷰] 백엔드 응답이 201 Created 등 성공적이라면, 축하 알림을 띄웁니다.
alert("회원가입이 성공적으로 완료되었습니다! 로그인 페이지로 이동합니다.");
// [리뷰] 가입이 완료되었으므로 깔끔하게 로그인 페이지로 사용자를 이동시킵니다.
window.location.href = "/api/v1/user/login-page/";
} else {
// [리뷰] 실패했을 때, 사용자에게 보여줄 기본 에러 메시지 뼈대를 준비합니다.
let errorMsg = "회원가입에 실패했습니다.";
// [리뷰/개선] DRF는 폼 검증 에러 시 {"필드명": ["에러내용"]} 처럼 배열 형태로 에러를 반환합니다.
// [리뷰] 닉네임 에러가 배열 형태로 왔다면 최우선적으로 해당 메시지를 꺼내옵니다.
if (data.nickname && Array.isArray(data.nickname)) {
errorMsg = `닉네임 오류: ${data.nickname[0]}`;
}
// [리뷰] 이메일이 이미 존재하거나 형식이 틀렸을 때의 메시지를 꺼내옵니다.
else if (data.email && Array.isArray(data.email)) {
errorMsg = `이메일 오류: ${data.email[0]}`;
}
// [리뷰] 비밀번호 길이가 짧거나 형식이 틀렸을 때의 메시지를 꺼내옵니다.
else if (data.password && Array.isArray(data.password)) {
errorMsg = `비밀번호 오류: ${data.password[0]}`;
}
// [리뷰] 특정 필드 에러가 아닌 인증/권한 에러(예: "이메일 인증이 완료되지 않았습니다.")를 잡아냅니다.
else if (data.detail) {
errorMsg = data.detail;
}
// [리뷰] 백엔드에서 커스텀하게 {"message": "에러내용"} 형태로 보낸 응답을 잡아냅니다.
else if (data.message) {
errorMsg = data.message;
}
// [리뷰/개선] 위 조건에 아무것도 안 걸리는 예상치 못한 에러 구조일 경우를 대비한 최후의 방어막입니다.
else if (typeof data === 'object' && Object.keys(data).length > 0) {
const firstKey = Object.keys(data)[0]; // 첫 번째 키값을 찾아냄
errorMsg = `입력값 오류 (${firstKey}): ${data[firstKey]}`;
}
// [리뷰] 최종적으로 걸러진 진짜 실패 원인을 사용자에게 알림창으로 친절하게 띄워줍니다.
alert(errorMsg);
// [개선] 닉네임 중복 에러였다면 사용자가 바로 수정할 수 있도록 닉네임 입력칸에 커서를 깜빡이게 해줍니다.
if (data.nickname) {
document.getElementById('nickname').focus();
}
}
} catch (error) {
// [리뷰] 서버가 꺼져있거나 인터넷이 끊기는 등 아예 통신이 안 된 경우의 예외 처리입니다.
alert("서버 통신 중 오류가 발생했습니다.");
} finally {
// [리뷰] 가입에 실패했거나 통신이 끝났다면, 사용자가 다시 시도할 수 있도록 버튼의 잠금을 풀어줍니다.
submitBtn.disabled = false;
submitBtn.innerText = originalBtnText;
}
});원인찾기
- 크롬(Chrome)에서 F12를 눌러 개발자 도구를 엽니다.
- 네트워크(Network) 탭을 클릭합니다.
- 그 상태에서 회원가입 완료 버튼을 누릅니다.
- 네트워크 목록에 signup/ 이라는 빨간색 요청이 뜨면 그것을 클릭합니다.
{
"error_detail": "유효하지 않은 요청입니다.",
"code": "invalid",
"errors": {
"nickname": [
"사용자의 nickname은/는 이미 존재합니다."
]
}
}
프폴 수정
- 강점 (Strengths)
- 아키텍처에 대한 고민
- 단순히 프레임워크가 제공하는 MVC(MVT) 구조에 갇히지 않고
- 비즈니스 로직을 Service Layer로 분리한 점은 시니어 면접관들이 매우 좋아하는 포인트
- 구체적인 해결책 명시
- X-Accel-Buffering: no, update_fields, select_related 등 실제로
- 부딪혀보지 않으면 모를 디테일한 기술명과 해결책이 포함되어 있어 훌륭
- 아키텍처에 대한 고민
- 개선 사항 (Weaknesses to fix)
- 수치화된 성과 부족
- N+1 문제를 해결했다면 "쿼리 호출 횟수를 N회에서 1회로 줄였다"라거나
- 쿼리 응답 시간이 "OOmms에서 Oms로 개선되었다"라는 구체적인 지표(숫자) 필요
- 동시성 고민의 부재
- 이전 이력서에는 비관적 락(select_for_update) 경험이 있었는데
- 이번 블로그 시스템의 '좋아요'나 '조회수', '경험치(게시글 작성에 따른 등급제)' 처리 시
- 동시성 이슈를 어떻게 제어했는지 명시하기
- 수치화된 성과 부족
면접 시뮬
[네트워크/비동기]- AI 텍스트 생성을 위해 SSE(StreamingHttpResponse)를 사용했음
- 그런데 Django는 기본적으로 동기(Synchronous) 워커 모델을 사용
- 다수의 사용자가 동시에 AI 글쓰기를 요청하여 장기 연결(Long-lived connection)이
- 유지된다면, 가용 워커가 고갈되어 다른 일반 API 요청까지 블로킹될 위험 존재
- 이 문제는 서버 인프라 혹은 코드 레벨에서 어떻게 해결하셨나요?
- (혹은 어떻게 해결할 계획이신가요?)
문제의 본질
기존의 Django는 기본적으로 동기식(Synchronous)인 WSGI(Gunicorn 등) 기반으로 동작합니다. 이 환경에서는 요청 하나당 하나의 워커(프로세스/스레드)를 점유합니다. AI 응답을 기다리며 SSE(Server-Sent Events) 연결이 수십 초간 유지되면, 가용 워커가 모두 고갈되어 다른 사용자들의 단순한 게시글 조회 요청조차 처리하지 못하고 서버가 뻗어버리는 현상(Worker Starvation)이 발생합니다.답변
"동기식 WSGI 환경에서는 워커 고갈 문제가 발생할 수 있음을 인지하고 있습니다. 이를 해결하기 위해 서버 아키텍처를 ASGI(Asynchronous Server Gateway Interface) 기반(예: Uvicorn, Daphne)으로 전환하고, 스트리밍을 처리하는 뷰와 서비스 로직을 async def를 활용한 비동기(Asynchronous) 코드로 리팩토링하겠습니다. 이를 통해 하나의 워커가 I/O 대기 시간 동안 블로킹되지 않고 다른 요청들을 비동기적으로 처리할 수 있도록(Non-blocking) 구성하여 서버의 가용성을 높이겠습니다."[DB 최적화]- 태그 통계를 집계할 때 annotate와 Count를 사용해 DB 단에서 처리한 것은 좋음
- 그런데 블로그 규모가 커져서 게시글이 천만 개 단위가 넘어간다면
- 매번 Group By 연산을 수행하는 현재 쿼리는 데이터베이스에 큰 부하를 줄 수 있음
- 이럴 경우 읽기 성능을 최적화하기 위해 아키텍처를 어떻게 변경하시겠습니까?
문제의 본질
데이터가 적을 때는 annotate와 Count를 통한 DB 집계가 메모리 처리보다 효율적입니다. 하지만 데이터가 수백만, 수천만 건으로 늘어나면 매번 요청이 들어올 때마다 무거운 Group By 연산이 수행되어 DB의 CPU가 버티지 못합니다. (Read-heavy 시스템의 병목)답변
"트래픽과 데이터가 대규모로 증가한다면, 실시간 집계 쿼리 대신 역정규화(Denormalization)와 캐싱(Caching) 전략을 도입하겠습니다.
첫째, Tag 모델 자체에 post_count라는 정수형 필드를 추가하고, 게시글이 작성되거나 삭제될 때만 카운트를 증감(+1/-1)시키겠습니다.
둘째, 빈번하게 조회되는 태그 통계 데이터는 Redis에 캐싱해두고 읽기 요청은 전적으로 Redis에서 처리하게 하여 RDB로 향하는 부하를 원천 차단하겠습니다. 데이터 정합성을 위해 Celery 비동기 워커를 활용하여 주기적으로 RDB와 Redis 데이터를 동기화하는 배치를 구성하겠습니다."[트랜잭션/무결성]- 댓글 수정/삭제 서비스 로직에 @transaction.atomic을 적용 했음
- 만약 댓글이 작성될 때 유저의 '활동 점수'를 올려주는
- 외부 API 연동 로직이나 Redis 업데이트 로직이 해당 트랜잭션 블록 안에
- 포함되어 있다면 어떤 문제가 발생할 수 있으며, 이를 어떻게 분리해야 할까요?
- 만약 댓글이 작성될 때 유저의 '활동 점수'를 올려주는
문제의 본질
- 댓글 수정/삭제 서비스 로직에 @transaction.atomic을 적용 했음
@transaction.atomic으로 묶인 블록 내부에서 외부 API(예: 알림 발송)나 Redis 통신을 하게 되면 두 가지 치명적인 문제가 생깁니다.
외부 API 응답이 3초간 지연되면 DB 트랜잭션도 3초간 물고 있게 되어 DB 커넥션 풀이 고갈되고 데드락 확률이 높아집니다.
외부 API 호출은 성공했는데 그 직후 DB 저장 단계에서 에러가 발생하면, DB는 롤백되지만 이미 발송된 외부 API(알림 등)는 롤백할 수 없는 데이터 불일치가 발생합니다.답변
"트랜잭션 내부에는 철저히 DB 연산만 포함시켜 락(Lock) 유지 시간을 최소화해야 합니다. 외부 시스템과의 연동은 트랜잭션이 안전하게 데이터베이스에 완전히 반영(Commit)된 이후에 실행되도록 분리해야 합니다. 이를 위해 Django의 transaction.on_commit() 훅을 사용하겠습니다. 즉, DB 커밋이 성공적으로 완료된 것이 보장될 때만 Celery Task를 호출하여 외부 API 연동이나 Redis 업데이트를 비동기로 안전하게 처리하겠습니다."최적화
기본 방식
최적화 utils.py
import functools
import time
from django.db import connection, reset_queries
def query_debugger(func):
"""
함수 실행 시 발생한 SQL 쿼리 개수와 실행 시간을 출력하는 데코레이터
"""
@functools.wraps(func)
def wrapper(*args, **kwargs):
reset_queries() # 쿼리 로그 초기화
start_time = time.time()
start_queries = len(connection.queries)
result = func(*args, **kwargs)
end_queries = len(connection.queries)
end_time = time.time()
print(f"\n[Query Debugger] '{func.__name__}'")
print(f" - Execution Time: {(end_time - start_time):.4f}s")
print(f" - Number of Queries: {end_queries - start_queries}")
# 실제 발생한 쿼리문 출력 (필요 시 주석 해제)
# for i, query in enumerate(connection.queries[start_queries:], 1):
# print(f" {i}. {query['sql']}")
print("=" * 30 + "\n")
return result
return wrapper
사용방법
- View의 메서드(get, post 등)나 Service의 메서드 위에
@query_debugger를 붙이기
- View의 메서드(get, post 등)나 Service의 메서드 위에
from apps.ai.utils import query_debugger
class ~APIView(APIView):
# ... (생략)
@query_debugger # <-- 여기에 붙이기
def get(self, request):
# ... 원래 코드기본 방식 특징
DEBUG = True에서만 동작
- Django는 메모리 누수를 막기 위해 settings.DEBUG = True일 때만
- connection.queries에 쿼리를 기록
- 즉, 실제 운영(Production) 환경에서는 쿼리 개수가 카운트되지 않으므로
- 철저히 로컬 개발 및 테스트 환경 전용으로 사용해야 함
- Django는 메모리 누수를 막기 위해 settings.DEBUG = True일 때만
시각적/상세 분석의 한계
- 터미널에서 쿼리 횟수와 실행 시간을 보는 데는 최고
- 하지만 "어느 파일 몇 번째 줄에서 이 쿼리가 발생했는지"
- "인덱스는 제대로 탔는지(EXPLAIN)" 등을 더 깊게 눈으로 보고 싶다면
- Django Debug Toolbar(DDT) / Django Silk 같은
- 서드파티 라이브러리를 설치하는 것이 UI 측면에서는 더 '최선'일 수 있음
- 터미널에서 쿼리 횟수와 실행 시간을 보는 데는 최고
동기(Sync) 함수 전용
- 현재 데코레이터는 일반적인 동기 함수용
- 만약 Django 3.1 이상에서 async def로 정의된 비동기 뷰나 함수에 적용하면
- 에러가 발생 (비동기 함수용 래퍼가 따로 필요함)
라이브러리
Django Debug Toolbar (DDT)
- 웹 브라우저 화면 우측에 숨겨진 패널 형태로 나타나며, 시각적인 분석에 매우 탁월
- 정확한 발생 위치 추적 (Stack Trace)
- 단순히 "쿼리가 100번 돌았다"가 아닌
- "어느 파일, 몇 번째 줄의 코드(혹은 템플릿)에서 이 쿼리가 발생했는지"를 클릭 한 번으로
- 보여줌, N+1 문제의 진짜 범인을 찾는 데 시간을 엄청나게 단축해 줌
- 실행 계획 (EXPLAIN) 시각화
- 발생한 쿼리문 옆에 EXPLAIN 버튼이 제공
- 이걸 누르면 데이터베이스가 이 쿼리를 처리할 때
- 인덱스를 잘 탔는지, 아니면 테이블 전체를 다 뒤졌는지(Full Scan)를
- 그래픽이나 표로 보여줌
- '데이터 양'에 따른 성능 저하를 눈으로 직접 확인 가능
- 다양한 병목 현상 분석
- DB 쿼리뿐만 아니라, 캐시(Cache) 히트율, 템플릿 렌더링에 걸린 시간
- HTTP 헤더 정보 등 뷰(View)가 실행되면서 거친 모든 과정의 소요 시간을
- 부위별로 쪼개서 보여줌
- 정확한 발생 위치 추적 (Stack Trace)
Django Silk
- DDT가 브라우저의 HTML 화면에 의존한다면
- Silk는 아예 별도의 성능 분석용 대시보드 페이지를 제공함
- API 위주로 개발할 때 압도적으로 편리
- API(JSON) 응답 분석에 최적화
- DDT는 브라우저 화면에 HTML을 주입하는 방식이라
- 내가 작성한 ToneConverterAPIView처럼 JSON(또는 Event-Stream)을 반환하는
- API 엔드포인트를 테스트할 때는 화면에 툴바가 뜨지 않아 보기가 까다로움
- 반면 Silk는 모든 요청(HTML이든 JSON이든)을 백그라운드에서 가로채어
- 별도의 대시보드에 기록하므로 DRF API 성능 최적화에 훨씬 유리함
- 내가 작성한 ToneConverterAPIView처럼 JSON(또는 Event-Stream)을 반환하는
- DDT는 브라우저 화면에 HTML을 주입하는 방식이라
- 요청/응답 데이터 풀 로그 기록
- 어떤 URL로, 어떤 파라미터(Body, Headers)를 담아서 요청했는지
- 그리고 서버가 어떤 응답을 내렸는지를 쿼리 내역과 함께 통째로 기록
- 어떤 URL로, 어떤 파라미터(Body, Headers)를 담아서 요청했는지
- 동적 프로파일링 (Live Profiling)
- 특정 파이썬 코드 블록이나 함수에만 데코레이터를 씌워
- 해당 부분만 집중적으로 메모리나 CPU를 얼마나 잡아먹는지
- 정밀하게 프로파일링(Profiling)할 수 있는 기능이 있음
- 특정 파이썬 코드 블록이나 함수에만 데코레이터를 씌워
Django Silk
설치
- pip install django-silk
- poetry add django-silk
settings.py 설정 추가
- INSTALLED_APPS 추가
- MIDDLEWARE 추가
INSTALLED_APPS = [
# ... 기존 앱들 ...
'silk', # 가장 아래쪽에 추가해 줌
]
...
MIDDLEWARE = [
# 가급적 최상단(또는 SecurityMiddleware 바로 밑)에 두는 것이 좋음
'silk.middleware.SilkyMiddleware',
# ... 기존 미들웨어들 ...
]프로젝트 라우팅(urls.py) 설정
- 프로젝트 최상위 라우팅 파일(보통 config/urls.py 또는 프로젝트명/urls.py)을 열고
- Silk 대시보드 주소를 연결
- 프로젝트 최상위 라우팅 파일(보통 config/urls.py 또는 프로젝트명/urls.py)을 열고
from django.urls import path, include
urlpatterns = [
# ... 기존 url 패턴들 ...
path('silk/', include('silk.urls', namespace='silk')), # Silk 대시보드 URL 추가
]-
마이그레이션 진행
- Silk는 API 요청 내역, 응답 시간, 발생한 SQL 쿼리문들을 자신의 데이터베이스 테이블에 저장함
- 따라서 마이그레이션을 반드시 실행해야 함
python manage.py migrate

-
실행 및 대시보드 확인
python manage.py runserver- Postman이나 클라이언트 웹을 통해 개발 중인
- API(ToneConverterAPIView 등)를 몇 번 호출 보기
- 웹 브라우저를 열고 http://127.0.0.1:8000/silk/ 로 접속해 보기
- Postman이나 클라이언트 웹을 통해 개발 중인
- API의 총 소요 시간, 데이터베이스 쿼리 개수, 쿼리 실행 시간, 실제 날아간 SQL 문 등을
- 아주 상세하게 클릭해서 확인 가능
-
선택
- Silk를 더 똑똑하게 쓰는 추가 설정 (settings.py)
# [Silk 추가 옵션]
# 1. 특정 요청만 기록할지 비율 설정 (기본값 100% - 로컬에서는 100으로 두는게 좋습니다)
SILKY_INTERCEPT_PERCENT = 100
# 2. 쿼리가 너무 많을 때 화면에 다 보여줄지 제한 (기본값 제한없음)
SILKY_MAX_RECORDED_REQUESTS = 10**4
# 3. 파이썬 코드 레벨의 프로파일링 기능 활성화 (병목 구간 찾을 때 유용)
SILKY_PYTHON_PROFILER = True주의 ⚠️
- Silk는 모든 요청과 쿼리를 DB에 기록하기 때문에 서버의 속도를 꽤 늦춤
- 따라서 완벽하게 최적화를 마친 후 실제 서비스(Production) 환경에 배포할 때는
- 반드시 Silk를 제거하거나 settings.py에서 비활성화 해야 함
이상적인 최적화 및 배포 워크플로우
- 로컬 환경에서 Silk 켜고 테스트하기
- 로컬 환경에 Silk를 설치
- 프론트엔드나 Postman으로 API를 여러 번 쏴보면서 대시보드를 확인
- N+1 문제가 발생하거나 너무 느린 쿼리(빨간색으로 표시됨)를 찾아냅니다.
- 코드 최적화 (문제 해결)
- select_related, prefetch_related를 적용 / DB 인덱스를 추가하는 등 코드를 수정
- 수정한 뒤 Silk 대시보드에서 쿼리 개수와 응답 시간이 줄어든 것을 확인
- Silk 처리하기 (비활성화 또는 제거)
- 최적화가 다 끝났다면, 배포(Push)하기 전에 Silk 관련 코드를 걷어내기
- Silk는 모든 요청과 쿼리를 DB에 일일이 기록하기 때문에
- 실제 배포 서버에 그대로 켜두면 서버가 엄청나게 느려지고 DB 용량도 순식간에 꽉 차버림
- 운영 서버에 Push 및 배포
- Silk가 제거된, "순수하게 쿼리 최적화만 완료된 깔끔한 코드"를 커밋하고 푸시하여 운영 서버에 배포
개발 환경(DEBUG = True)
에서만 Silk가 켜지도록 코드를 분기 처리
settings.py 맨 밑에 추가
# DEBUG가 True일 때(즉, 로컬 개발 환경일 때)만 Silk를 활성화
if DEBUG:
INSTALLED_APPS.append('silk')
MIDDLEWARE.insert(0, 'silk.middleware.SilkyMiddleware')urls.py
from django.conf import settings
from django.urls import path, include
urlpatterns = [
# 기존 URL들...
]
# 로컬 개발 환경에서만 Silk 라우팅 추가
if settings.DEBUG:
urlpatterns += [path('silk/', include('silk.urls', namespace='silk'))]확인
http://127.0.0.1:8000/silk/- 들어가서 확인하기
최적화 진행
AI
19ms overall
1ms on queries
1 queries- 사용자가 보낸 JSON에서 text와 tone을 읽어옵니다. (메모리 작업)
- TONE_MAPPING 딕셔너리에서 프롬프트를 찾습니다. (메모리 작업)
- Google Gemini API 서버로 HTTP 통신을 보내서 결과를 받아옵니다.
- 받아온 결과를 조각내어(Streaming) 바로 클라이언트에게 던져줍니다.
- 이 API의 비즈니스 로직 내부에서는
- 데이터베이스(PostgreSQL)를 단 한 번도 조회하거나 저장하지 않음
- 인증(Authentication) 쿼리
- settings.py에 DRF 전역 설정으로 JWT 인증(IsAuthenticated)이 걸려있음
- 사용자가 보낸 토큰이 유효한지 확인하고
- 해당 토큰의 주인이 누구인지 알기 위해 User 테이블을 조회하는 쿼리가 딱 1번 발생했을 것
POST
내 작성글 조회
# 수정 전
/api/v1/post/my/
28ms overall
6ms on queries
14 queries
# 수정 후
/api/v1/post/my/
17ms overall
4ms on queries
5 queries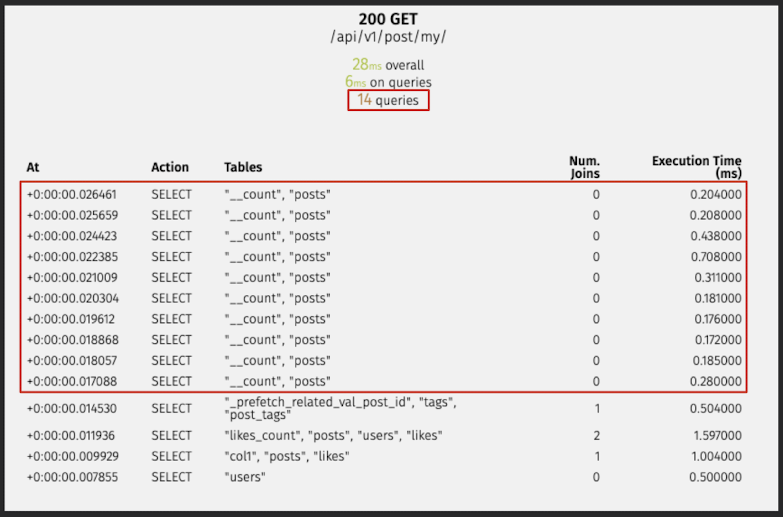
원인
- 1개: 유저 로그인 확인 (JWT 인증)
- 1개: 페이지네이션을 위한 전체 게시글 수 계산 (COUNT)
- 1개: 내 게시글 10개 가져오기 (SELECT)
- 1개: 태그 정보 한 번에 가져오기 (prefetch_related)
- 10개 (N+1 문제)
- PostListSerializer가 응답을 만들면서 10개의 게시글 각각에 대해
- "이 작성자 글 몇 개 썼지?" 하고
- Post.objects.filter(user=obj.user).count() 쿼리를 10번 반복해서 날리고 있음
해결
- 지금 /api/v1/post/my/ API는 "내 게시글"만 10개 가져오기 때문에
- 사실 작성자는 1명(나 자신)으로 똑같음
- 따라서 작성자 글 개수 카운트는 처음 한 번만 계산해서 메모리에 기억(Cache)해 두고
- 나머지 9개 글을 처리할 때는 쿼리를 날리지 않고 재사용

- 나머지 9개 글을 처리할 때는 쿼리를 날리지 않고 재사용
- 지금 /api/v1/post/my/ API는 "내 게시글"만 10개 가져오기 때문에
코드 비교
def get_author_grade_image(self, obj):
total_count = Post.objects.filter(user=obj.user).count()
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade["imgUrl"]
return GRADE_SETTINGS[-1]["imgUrl"]
——————————————————————————————————————[비교]—————————————————————————————————————————
# 1. 시리얼라이저가 실행될 때 유저별 글 개수를 기억할 딕셔너리 준비
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._author_counts = {}
# 2. 등급 이미지 URL을 계산하는 메서드 최적화
def get_author_grade_image(self, obj):
user_id = obj.user_id
# 만약 이 유저의 글 개수를 아직 계산한 적이 없다면? -> 딱 1번만 DB에서 카운트 쿼리 실행
if user_id not in self._author_counts:
self._author_counts[user_id] = Post.objects.filter(
user_id=user_id,
deleted_at__isnull=True # (꿀팁) 기존 코드에 휴지통에 간 글을 제외하는 로직이 빠져있어서 추가했습니다!
).count()
# 이미 계산된 유저라면 쿼리 없이 딕셔너리에서 바로 꺼내옴 (N+1 방어)
total_count = self._author_counts[user_id]
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade["imgUrl"]
return GRADE_SETTINGS[-1]["imgUrl"]배포환경
배포환경에서 도커 재빌드 해야함
docker-compose down
docker-compose up -d --build
안녕하세요.