
코딩테스트(10699)
최적화 진행
http://127.0.0.1:8000/silk/
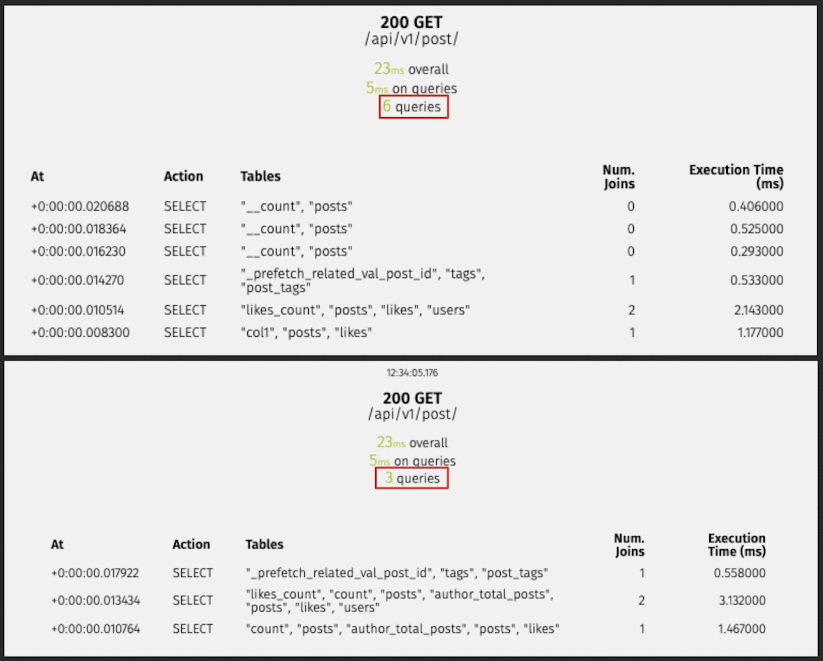
Post(전체 글 조회)
# 수정 전
200 GET
/api/v1/post/
23ms overall
5ms on queries
6 queries
# 수정 후
200 GET
/api/v1/post/
23ms overall
5ms on queries
3 queries쿼리 분석
- 페이지네이션 COUNT 쿼리
- PostAPIView.get() 내부의
paginator.paginate_queryset(posts, request, view=self)에서- 전체 페이지 수를 계산하기 위해
SELECT COUNT(*)쿼리가 1회 발생
- PostAPIView.get() 내부의
- Post 및 User 메인 데이터 조회 쿼리
get_global_posts()서비스 함수에서.select_related("user")와.annotate(likes_count=...)가 결합되어- 실제 포스트 목록과 유저 정보를 가져오는 메인 쿼리가 1회 발생
- Tag Prefetch 쿼리
.prefetch_related("tags")로 인해 게시글과 연결된 태그들을 가져오기 위해- 별도의
SELECT ... IN (...)쿼리가 1회 발생
- 별도의
- 작성자 등급 계산용 COUNT 쿼리
PostListSerializer의get_author_grade_image()내부에서Post.objects.filter(...).count()가 실행됨__init__에서 딕셔너리로 캐싱 처리를 했지만- 첫 번째 게시글의 작성자에 대해서는 무조건 1회의 쿼리가 발생
- Series 참조 (N+1 문제) 쿼리 1
-PostListSerializer에는source="series.name"을 통해 시리즈의 이름을- 참조하는 필드가 있음
- 하지만
get_global_posts()의select_related에는"series"가 빠져있어서Series정보를 가져오기 위해 추가 쿼리가 발생
- Series 참조 (N+1 문제) 쿼리 2
- 한 페이지에 노출된 게시글 중
- 서로 다른 series를 가진 게시글이 2개 이상일 경우 위 5번의 쿼리가 반복되어 발생
- 또는 API 호출 시 Django의 Session/Auth User를 조회하는 쿼리일 수 있으나
- 시리즈 N+1 문제로 인한 누적일 확률이 가장 높습니다.
- 서로 다른 series를 가진 게시글이 2개 이상일 경우 위 5번의 쿼리가 반복되어 발생
- 한 페이지에 노출된 게시글 중
수정
- 시리얼라이저의 작성자 카운트 쿼리를 서브쿼리(Subquery)로 메인 쿼리에 밀어 넣고
- Series에 대한 N+1 문제를 select_related로 해결
...
# 5. N+1 문제 해결 및 좋아요 수 계산 후 생성일 기준 내림차순 정렬 반환
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 0. 서브쿼리: 각 사용자(OuterRef)의 삭제되지 않은 총 게시글 수를 구하는 쿼리를 미리 정의
author_posts_count = (
Post.objects.filter(
# OuterRef를 통해 나중에 메인 쿼리에 결합될 때, 메인 쿼리의 user_id와 동일한 작성자의 글만 필터링
user_id=OuterRef("user_id"),
deleted_at__isnull=True
)
# user_id를 기준으로 데이터를 그룹화(GROUP BY)할 준비
.values("user_id")
# 그룹화된 데이터(각 유저)를 기준으로 게시글의 개수(id)를 세어 'count'라는 가상 필드를 만듬
.annotate(count=Count("id"))
# 메인 쿼리에 서브쿼리로 들어갈 때는 단일 값만 반환해야 하므로, 위에서 만든 'count' 필드만 결과로 추출
.values("count")
)
...
# 5. N+1 문제 해결 및 좋아요 수 계산 후 생성일 기준 내림차순 정렬 반환
return (
qs.select_related("user", "series")
.prefetch_related("tags")
.annotate(
# 중복되지 않은 좋아요(likes)의 개수를 세어 likes_count에 저장
likes_count=Count("likes", distinct=True),
# 서브쿼리를 실행하여 작성자의 총 글 수를 author_total_posts에 저장 (Serializer N+1 제거)
author_total_posts=Subquery(author_posts_count, output_field=IntegerField())
)
.order_by("-created_at")
) # 1. 시리얼라이저가 실행될 때 유저별 글 개수를 기억할 딕셔너리 준비
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._author_counts = {}
# 2. 등급 이미지 URL을 계산하는 메서드 최적화
def get_author_grade_image(self, obj):
user_id = obj.user_id
# 만약 이 유저의 글 개수를 아직 계산한 적이 없다면? -> 딱 1번만 DB에서 카운트 쿼리 실행
if user_id not in self._author_counts:
self._author_counts[user_id] = Post.objects.filter(
user_id=user_id,
deleted_at__isnull=True
).count()
# 이미 계산된 유저라면 쿼리 없이 딕셔너리에서 바로 꺼내옴 (N+1 방어)
total_count = self._author_counts[user_id]
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade["imgUrl"]
return GRADE_SETTINGS[-1]["imgUrl"]
——————————————————————————————————————[비교]—————————————————————————————————————————
# 등급 이미지 URL을 계산하는 메서드 최적화
def get_author_grade_image(self, obj):
# 1. 쿼리셋의 annotate(Subquery)를 통해 미리 계산되어 넘어온 author_total_posts 값을 가져옴
total_count = getattr(obj, "author_total_posts", 0)
# 2. 미리 정의된 GRADE_SETTINGS 리스트를 순회하며 적절한 등급을 찾음
for grade in GRADE_SETTINGS:
# 유저의 총 게시글 수가 특정 등급의 최소 기준치(min) 이상인지 확인
if total_count >= grade["min"]:
# 조건을 가장 먼저 만족하는(가장 높은 등급의) 이미지를 반환
return grade["imgUrl"]
# 3. 모든 조건을 만족하지 못할 경우 안전 장치(Fallback)로 가장 낮은 등급의 이미지를 반환
return GRADE_SETTINGS[-1]["imgUrl"]결과
코드 수정에 따른 이점
- 응답 속도(Latency) 대폭 개선
- 웹 서버(Django)와 데이터베이스(DB)가 통신하는 횟수 자체가 6번에서 3번으로 줄어듬
- 네트워크 통신은 비용이 매우 큰 작업이므로
- 쿼리 횟수를 줄이는 것만으로도 API 응답 속도가 비약적으로 빨라짐
- 메모리 및 CPU 절약
- 파이썬 코드(시리얼라이저) 내부에서 루프를 돌며 데이터를 계산하고 조립하는 것보다
- 데이터베이스 엔진 자체에서 데이터를 다듬어서 보내주는 것이 훨씬 빠르고 효율적
- 책임의 분리 (Thin Serializer)
- 데이터를 '조회'하는 책임은 Service(또는 QuerySet) 계층이
- 데이터를 화면에 맞게 '포장(직렬화)'하는 책임은 Serializer가 가지도록 역할을 명확화
- 따라서, 유지보수가 훨씬 쉬워짐
- 진짜 N+1 문제의 근본적인 해결 (압도적인 성능 향상)
- 이전 방식의 한계
- 시리얼라이저의
__init__에 딕셔너리를 둬서 '동일 유저'의 중복 쿼리만 막았을 뿐 - 피드에 10명의 각기 다른 유저가 쓴 글이 있다면 결국 총 글 개수를 알기 위해
- DB에 10번의 추가 쿼리를 날려야 했음
- 시리얼라이저의
- 수정된 방식의 이점
author_total_posts=Subquery(...)를 통해 DB에 "메인 쿼리를 실행할 때- 하위 작업 지시서(author_posts_count)를 통해 각 작성자의 총 글 개수도
- 한방에 계산해서 가져와!"라고 지시하게 되었음
- 따라서 유저가 10명이든 100명이든 단 1번의 쿼리로 모든 데이터를 가져오게 되어
- 조회 속도가 비약적으로 향상
- 이전 방식의 한계
- 서버 메모리 절약 (캐싱 불필요)
- 이전에는 시리얼라이저가 동작할 때마다 파이썬 메모리에
self._author_counts = {}라는 임시 저장소(딕셔너리)를 만들고- 일일이 데이터를 넣고 빼는 작업이 필요했음
- 하지만 이제는 DB 자체에서 계산이 완료된 결과(
author_total_posts)를- 객체에 붙여서 반환해 주기 때문에, 시리얼라이저가 무거운 딕셔너리 캐시를
- 들고 있을 필요가 없어 메모리 사용량이 크게 절약됨
- 이전에는 시리얼라이저가 동작할 때마다 파이썬 메모리에
__init__사용 이유
# 1. 시리얼라이저가 실행될 때 유저별 글 개수를 기억할 딕셔너리 준비
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._author_counts = {}
# 2. 등급 이미지 URL을 계산하는 메서드 최적화
def get_author_grade_image(self, obj):
user_id = obj.user_id
# 만약 이 유저의 글 개수를 아직 계산한 적이 없다면? -> 딱 1번만 DB에서 카운트 쿼리 실행
if user_id not in self._author_counts:
self._author_counts[user_id] = Post.objects.filter(
user_id=user_id,
deleted_at__isnull=True
).count()
# 이미 계산된 유저라면 쿼리 없이 딕셔너리에서 바로 꺼내옴 (N+1 방어)
total_count = self._author_counts[user_id]
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade["imgUrl"]
return GRADE_SETTINGS[-1]["imgUrl"]def __init__가 하는 핵심 역할: "기억 저장소(캐시) 준비하기"__init__은 생성자(Constructor)라고 부르며- 클래스가 객체로 생성될 때(즉, 시리얼라이저가 작동을 시작할 때)
- 가장 먼저 딱 한 번 실행되는 초기화 메서드
- 클래스가 객체로 생성될 때(즉, 시리얼라이저가 작동을 시작할 때)
- 이 코드에서
__init__이 하는 가장 중요한 역할은self._author_counts = {}라는 빈 딕셔너리를 만드는 것
- 한 번 DB에서 계산해 온 유저의 글 개수는 이 딕셔너리에 적어두고
- 다음번에는 DB에 가지 말고 여기서 바로 꺼내 쓰려는 목적으로 만들었음
- 이 코드는 같은 유저의 글이 여러 개일 때 발생하는 중복 쿼리를 막을 수 있음
- 하지만, N+1 문제가 발생할 수 있음
가장 큰 문제
- 만약 게시판 목록에 10명 각기 다른 유저가 쓴 글 10개가 있다면
- 이 시리얼라이저는
self._author_counts에 저장된 정보가 없기 때문에 - 10명의 유저 글 개수를 알기 위해 결국 DB에 10번의 쿼리를 날리게 됨
- 동일 유저 중복만 막을 뿐, 다른 유저라면 매번 쿼리가 발생함
- 이 시리얼라이저는
- 만약 게시판 목록에 10명 각기 다른 유저가 쓴 글 10개가 있다면
Post(내 글 조회)
# 수정 전
/api/v1/post/my/
28ms overall
6ms on queries
14 queries
# 수정 후(2026/03/21)
/api/v1/post/my/
17ms overall
4ms on queries
5 queries
# 수정 후(2026/03/22)
200 GET
/api/v1/post/my/
31ms overall
4ms on queries
4 queries서비스 수정
- 어제 쿼리최적화를 진행하면서 캐싱방법을 사용했는데 전체글 조회 쿼리 최적화를 진행하면서
- 캐싱방식을 삭제했더니 오류 발생
- 내 글 목록에서는 무조건 총 게시글 수가 0개로 인식되어 가장 낮은 등급의 이미지만 노출
...
# 5. N+1 문제 해결 및 좋아요 수 계산 후 반환
return (
qs.select_related("user")
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 0. 서브쿼리 정의: "작성자의 총 게시글 수를 세어라" 라는 하위 작업 지시서를 만듬
author_posts_count = (
Post.objects.filter(
# OuterRef("user_id"): 이 하위 작업 지시서가 '메인 쿼리'의 데이터와 연결되는 고리
# "메인 쿼리에서 현재 보고 있는 그 게시글의 작성자(user_id)와 같은 사람의 글만 찾아라"
user_id=OuterRef("user_id"),
deleted_at__isnull=True
)
# user_id를 기준으로 데이터를 그룹화(GROUP BY)할 준비
.values("user_id")
# 그룹화된 데이터(각 유저)를 기준으로 게시글의 개수(id)를 세어 'count'라는 가상 필드를 만듬
.annotate(count=Count("id"))
# 메인 쿼리에 서브쿼리로 들어갈 때는 단일 값만 반환해야 하므로, 위에서 만든 'count' 필드만 결과로 추출
.values("count")
)
...
# 5. N+1 문제 해결 및 좋아요 수 계산 후 반환
return (
# 메인 쿼리 실행
qs.select_related("user", "series")
.prefetch_related("tags")
.annotate(
# 중복되지 않은 좋아요(likes)의 개수를 세어 likes_count에 저장
likes_count=Count("likes", distinct=True),
# 3. 서브쿼리 결합: "게시글을 가져올 때, 위에서 만든 하위 작업 지시서(author_posts_count)도
# 데이터베이스 안에서 같이 실행해서, 그 결과를 author_total_posts 라는 이름으로 붙여서 줘!"
author_total_posts=Subquery(author_posts_count, output_field=IntegerField())
)
.order_by("-created_at")
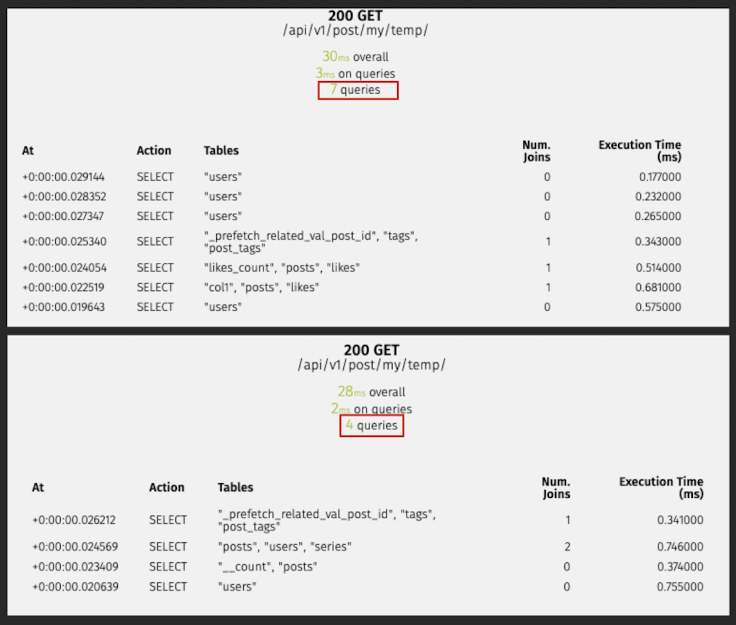
)Post(임시글 목록)
# 수정 전
/api/v1/post/my/temp/
30ms overall
3ms on queries
7 queries
# 수정 후
/api/v1/post/my/temp/
28ms overall
2ms on queries
4 queries불필요한 로직 제거 및 N+1방지
- 좋아요 집계(Count("likes")) 연산 제거 및 series 추가
return (
Post.objects.filter(
user=user,
is_temp=True,
deleted_at__isnull=True,
)
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 1. 쿼리셋 생성: 로그인한 유저의 임시글 중 삭제되지 않은 글만 명확하게 필터링
qs = Post.objects.filter(
user=user,
is_temp=True,
deleted_at__isnull=True,
)
# 2. N+1 방지(JOIN 및 Prefetch) 적용 후 반환
return (
# 작성자(user)와 시리즈(series) 정보를 JOIN으로 한 번에 가져와 시리얼라이저 N+1 방지
qs.select_related("user", "series")
# 게시글에 달린 태그(tags) 정보도 IN 쿼리를 통해 한 번에 묶어서 가져옴
.prefetch_related("tags")
# 임시글은 최근에 작성/수정한 순서대로 보는 것이 편하므로 생성일 역순(최신순) 정렬 적용
.order_by("-created_at")
)결과
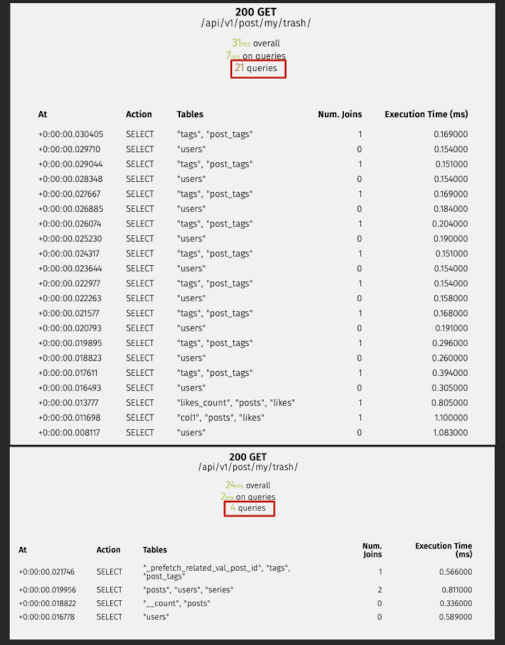
Post(휴지통 목록)
# 수정 전
/api/v1/post/my/trash/
31ms overall
7ms on queries
21 queries
# 수정 후
/api/v1/post/my/trash/
17ms overall
3ms on queries
4 queries수정
return (
Post.objects.filter(user=user, deleted_at__isnull=False)
.annotate(likes_count=Count("likes", distinct=True))
.order_by("-deleted_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 1. 쿼리셋 생성: 로그인한 유저의 글 중 '삭제된(휴지통)' 글만 필터링
qs = Post.objects.filter(
user=user,
deleted_at__isnull=False,
)
# 2. N+1 문제 방지 및 정렬 후 최종 반환
return (
# 휴지통 목록에서도 작성자나 시리즈 이름이 노출될 수 있으므로 JOIN으로 N+1 방지
qs.select_related("user", "series")
# 태그 정보 노출 시 발생하는 추가 쿼리 방지
.prefetch_related("tags")
.order_by("-deleted_at")
)원인
- 수정 전의 코드는 게시글 목록만 먼저 가져온 뒤
- 시리얼라이저(Serializer)가 JSON 데이터를 만들면서 필요한 추가 정보를
- 그때그때 DB에 물어보는 구조
- ex. 휴지통에 10개의 글이 있었다고 가정
- 메인 쿼리 (1개): "휴지통에 있는 게시글 10개 다 가져와!"
- 시리즈 조회 (최대 10개)
- 1번 글 시리얼라이징 중... "어? 1번 글의 시리즈 이름(series.name)이 필요하네?
- DB야, 1번 글 시리즈 정보 줘!" ➡️ 2번 글... 3번 글... (반복)
- 태그 조회 (최대 10개)
- 1번 글 시리얼라이징 중... "어? 1번 글의 태그 목록(tags)도 필요하네?
- DB야, 1번 글 태그 줘!" ➡️ (반복)
수정 후
- select_related와 prefetch_related는
- "이따가 시리얼라이저가 분명히 물어볼 테니까, 미리 한 번에 다 챙겨와!"
- 라고 DB에 미리 지시하는 역할
- 사용자/세션 확인 쿼리 (1개)
- Django가 API 요청을 보낸 사람이 누군지(현재 로그인한 유저 정보) 확인하기 위해 발생
- 페이지네이션 COUNT 쿼리 (1개)
- 전체 휴지통 게시글이 몇 개인지
- 몇 페이지까지 있는지 계산하기 위한
SELECT COUNT(*)쿼리
- 메인 데이터 조회 쿼리 (1개)
- select_related("user", "series")가 작동한 쿼리
- "게시글 가져올 때, 작성자(user) 정보랑 시리즈(series) 정보도
- JOIN(결합)해서 하나의 표로 한 번에 가져와!"
- 이 단 1번의 쿼리로 시리얼라이저가 유저와 시리즈를 찾기 위해 쏘던
- 수십 개의 추가 쿼리가 완벽히 사라짐
- 태그 정보 조회 쿼리 (1개)
- prefetch_related("tags")가 작동한 쿼리
- 다대다(M:N) 관계인 태그는 JOIN으로 가져오기 어렵기 때문에
- Django가 조회된 게시글들의 ID를 모아서
- "이 게시글들(IN (...))에 달린 태그 다 가져와!" 라며
- 딱 1번의 추가 쿼리만 날려 태그들을 미리 싹 쓸어옴
- select_related와 prefetch_related는
결과
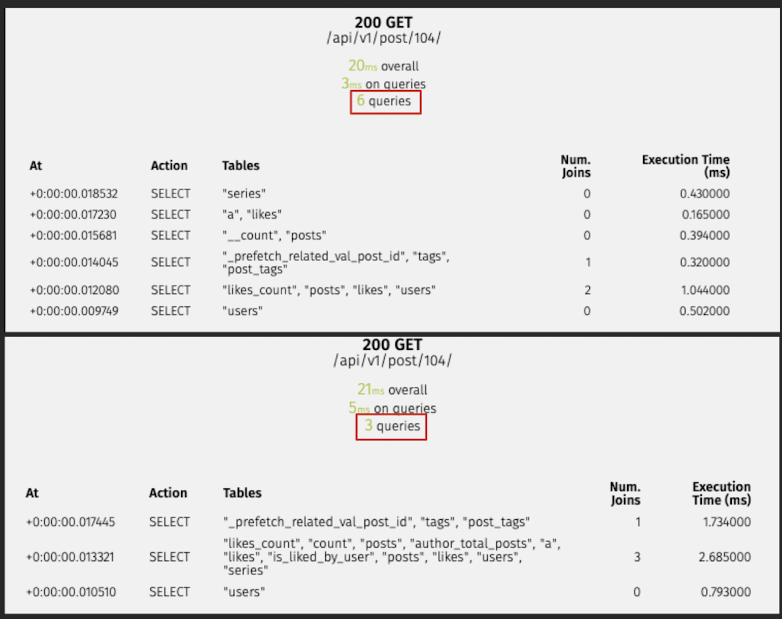
Post(상세조회)
# 수정 전
/api/v1/post/104/
20ms overall
3ms on queries
6 queries
# 수정 후
/api/v1/post/104/
21ms overall
5ms on queries
3 queries원인
- 현재 로그인한 유저(Auth) 조회 쿼리 (1개)
- API 요청 시 Django가 Token/Session을 확인하여 사용자 정보를 가져오는 필수 쿼리
- 게시글 메인 데이터 조회 쿼리 (1개)
- get_post_detail의
- .select_related("user")와 .annotate(likes_count=...)가 실행되는 쿼리
- 태그(Tag) Prefetch 쿼리 (1개)
- prefetch_related("tags")로 인해 태그 데이터를 가져오는 쿼리
[낭비 1]시리즈(Series) N+1 조회 쿼리 (1개)- PostDetailSerializer에 series.name을 요구하는 필드가 있지만
- get_post_detail의 select_related에는 "series"가 빠져있어 DB에 다시 요청을 보냄
[낭비 2]작성자의 총 게시글 수 계산 쿼리 (1개)- 시리얼라이저의 get_author_grade_image 내부에서
- Post.objects.filter(...).count()가 실행되어 추가 쿼리가 발생
[낭비 3]좋아요 여부(is_liked) 확인 쿼리 (1개)- 시리얼라이저의 get_is_liked 내부에서
- obj.likes.filter(...).exists()가 실행되면서 또다시 DB와 통신
해결
service(get_post_detail)
- 서비스 함수가 현재 접속한 user 객체도 받도록 수정하여 is_liked 여부를 DB단에서 미리 확인
return (
Post.objects.select_related("user") # type: ignore
.filter(id=post_id, deleted_at__isnull=True)
.prefetch_related("tags")
.annotate(likes_count=Count("likes", distinct=True))
.first()
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 1. 서브쿼리: 작성자의 총 게시글 수 계산 (등급 이미지용)
author_posts_count = (
Post.objects.filter(
user_id=OuterRef("user_id"),
deleted_at__isnull=True
)
.values("user_id")
.annotate(count=Count("id"))
.values("count")
)
# 2. 메인 쿼리셋 생성 및 최적화 (N+1 방지 및 Annotation)
qs = (
Post.objects.filter(id=post_id, deleted_at__isnull=True)
# [낭비 1 해결] 시리얼라이저의 N+1 쿼리 방지를 위해 "series" 조인 추가
.select_related("user", "series")
.prefetch_related("tags")
.annotate(
# 좋아요 개수 카운트
likes_count=Count("likes", distinct=True),
# [낭비 2 해결] 작성자의 총 게시글 수를 서브쿼리로 가져와 시리얼라이저 N+1 방지
author_total_posts=Subquery(author_posts_count, output_field=IntegerField())
)
)
# 3. [낭비 3 해결] 좋아요 여부(is_liked) 서브쿼리 처리
if user and user.is_authenticated:
# 현재 게시글(OuterRef("id"))에 현재 접속한 유저(user)가 좋아요를 눌렀는지 확인하는 서브쿼리
is_liked_subquery = Like.objects.filter(
post_id=OuterRef("id"),
user=user
)
# Exists를 사용하면 조건에 맞는 데이터가 존재하면 True, 없으면 False를 'is_liked_by_user' 필드로 반환
qs = qs.annotate(is_liked_by_user=Exists(is_liked_subquery))
return qs.first()view
- get_post_detail을 호출할 때 request.user를 같이 넘겨주기
class PostDetailAPIView(APIView):
permission_classes = [IsAuthenticatedOrReadOnly]
@extend_schema(tags=["포스트"], summary="게시글 상세 조회")
def get(self, request: Request, post_id: int):
# 1. 서비스 레이어를 호출
post = get_post_detail(post_id)
# 2. 게시글이 없는 경우(None), 커스텀 예외를 발생
if not post:
raise BaseCustomException(ErrorMessage.POST_NOT_FOUND)
# 이렇게 해야 Serializer 내부에서 현재 접속한 유저가 누구인지 알 수 있음
return Response(PostDetailSerializer(post, context={"request": request}).data)
——————————————————————————————————————[비교]—————————————————————————————————————————
class PostDetailAPIView(APIView):
permission_classes = [IsAuthenticatedOrReadOnly]
@extend_schema(tags=["포스트"], summary="게시글 상세 조회")
def get(self, request: Request, post_id: int):
# 1. 서비스 레이어를 호출할 때 request.user도 함께 넘겨줌
post = get_post_detail(post_id, user=request.user)
# 2. 게시글이 없는 경우 예외 발생
if not post:
raise BaseCustomException(ErrorMessage.POST_NOT_FOUND)
# 3. 데이터 반환
return Response(PostDetailSerializer(post, context={"request": request}).data)serializer
- 시리얼라이저 내부의 연산을 서브쿼리 결과값 매핑으로 교체
def get_author_grade_image(self, obj):
# 1. 작성자(obj.user)가 지금까지 작성한 글 중에서 삭제되지 않은(deleted_at__isnull=True) 전체 글의 개수를 카운트
total_count = Post.objects.filter(
user=obj.user, deleted_at__isnull=True
).count()
# 2. GRADE_SETTINGS를 위에서부터 순회하며 개수(min) 조건을 충족하는 등급 이미지를 찾음
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade[
"imgUrl"
] # 조건을 만족하면 바로 해당 이미지 URL을 반환하고 종료
# 3. 만약 매칭되는게 없다면 (혹시 모를 에러 방지용) 제일 기본 씨앗 이미지를 반환
return GRADE_SETTINGS[-1]["imgUrl"]
def get_is_liked(self, obj) -> bool:
# 1. 뷰(View)에서 넘겨준 context 안에서 현재 요청(request) 객체를 가져옴
request = self.context.get("request")
# 2. 요청 객체가 존재하고, 로그인된 사용자(is_authenticated)일 경우에만 검사
if request and request.user.is_authenticated:
# 3. 현재 게시글(obj)의 좋아요(likes) 목록 중에 현재 로그인한 유저가 있는지(exists) 확인하여 True/False를 반환
return obj.likes.filter(user=request.user).exists()
# 4. 로그인하지 않은 사용자라면 무조건 False(좋아요 안 누름)를 반환
return False
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_author_grade_image(self, obj):
# DB에서 미리 계산해준 'author_total_posts' 값을 바로 사용(쿼리 낭비 X)
total_count = getattr(obj, "author_total_posts", 0)
# 미리 정의된 GRADE_SETTINGS를 순회하며 조건 검사
for grade in GRADE_SETTINGS:
if total_count >= grade["min"]:
return grade["imgUrl"]
return GRADE_SETTINGS[-1]["imgUrl"]
def get_is_liked(self, obj) -> bool:
# Service에서 Exists 서브쿼리를 통해 True/False 값을 'is_liked_by_user'로 붙여주기
# DB를 찌르지 않고 해당 값을 가져오기만 함 (비로그인 상태이거나 값이 없으면 기본값 False 반환)
return getattr(obj, "is_liked_by_user", False)결과
공부 요소
서브쿼리(Subquery / OuterRef)
지연 로딩(Lazy Loading)
- Django ORM은 기본적으로 '지연 로딩' 방식을 사용
- 즉, "진짜로 그 데이터를 달라고 하기 전까지는 굳이 DB에서 가져오지 않고 미뤄두는" 특성 존재
- Service (비즈니스 로직)
- Post.objects.all() 처럼 메인 데이터만 가져와서 시리얼라이저에게 넘김
- Serializer
- 데이터를 JSON으로 변환하려고 하나씩 뜯어봅니다.
- "어? series.name을 출력해야 하는데 데이터가 없네?
- DB야, 지금 시리즈 데이터 좀 줘!" (쿼리 발생)
- "어? 이번엔 tags 목록이 필요하네? DB야, 태그 데이터도 줘!" (쿼리 발생)
- "작성자의 총 게시글 수도 계산해야 하네? DB야, 카운트 세서 줘!" (쿼리 발생)
- 시리얼라이저가 JSON 변환을 하던 도중에 필요한 항목이 발견될 때마다 그때그때 DB에 요청을 함
즉시 로딩(Eager Loading)
- select_related, prefetch_related, annotate(Subquery) 등을
- 비즈니스 로직에 추가한 것은 Django에게 '즉시 로딩'을 강제한 것
- Service (비즈니스 로직)
- "이따 시리얼라이저가 시리즈, 태그, 총 게시글 수 다 물어볼 테니까
- 지금 한 번에 다 결합(JOIN)해서 가져와!"
- "이따 시리얼라이저가 시리즈, 태그, 총 게시글 수 다 물어볼 테니까
- Serializer
- "우와, 내가 JSON 만들 때 필요한 데이터가 이미 메모리에 다 준비되어 있네?
- 그냥 꺼내서 포장만 해야지!" (DB 통신 0회)
- "우와, 내가 JSON 만들 때 필요한 데이터가 이미 메모리에 다 준비되어 있네?
- Service (비즈니스 로직)
- 비즈니스 로직에 추가한 것은 Django에게 '즉시 로딩'을 강제한 것
서브쿼리(Subquery / OuterRef)
- Subquery (서브쿼리)
- 하나의 메인 SQL 쿼리문 안에 포함된 또 다른 하위 쿼리문
- 데이터베이스에서 복잡한 조건이나 계산을 수행하기 위해 사용
- Django ORM에서는
django.db.models.Subquery클래스로 지원됨
- OuterRef (외부 참조)
- 서브쿼리 내부에서, 자신을 감싸고 있는 메인 쿼리(Outer Query)의
- 필드 값을 참조할 때 사용하는 Django ORM의 클래스
- SQL 이론상으로는 상관 서브쿼리(Correlated Subquery)를 구현할 때 필수적인 역할
- 서브쿼리 내부에서, 자신을 감싸고 있는 메인 쿼리(Outer Query)의
서브쿼리와 상관 서브쿼리의 차이
- 일반 서브쿼리
- 메인 쿼리와 독립적으로 실행될 수 있음
- 서브쿼리가 먼저 한 번 실행되고, 그 결과를 메인 쿼리가 사용
- 상관 서브쿼리 (Correlated Subquery)
- 서브쿼리 내부에서 메인 쿼리의 컬럼을 참조
- 이 경우 메인 쿼리의 각 행(Row)이 평가될 때마다 서브쿼리가 반복적으로 실행되어야 함
- Django의 OuterRef가 바로 이 상관 서브쿼리를 만들기 위해 존재
예시
모델
from django.db import models
class Category(models.Model):
name = models.CharField(max_length=100)
class Post(models.Model):
category = models.ForeignKey(Category, on_delete=models.CASCADE, related_name='posts')
title = models.CharField(max_length=200)
created_at = models.DateTimeField(auto_now_add=True)Subquery와 OuterRef 활용 예제
- 이 데이터를 순회하면서 최신 포스트를 조회할 때, 단순 반복문을 쓰면 N+1 문제가 발생
- 이를 Subquery와 OuterRef로 단일 쿼리로 최적화 가능
from django.db.models import OuterRef, Subquery
from .models import Category, Post
def get_categories_with_newest_post():
# 1. 서브쿼리로 사용할 쿼리셋 정의
"""
OuterRef('pk')는 메인 쿼리(Category)의 Primary Key(id)를 참조
즉, "현재 평가 중인 카테고리의 id와 동일한 카테고리를 가진 포스트"를 찾음
"""
newest_post_subquery = Post.objects.filter(
category=OuterRef('pk')
).order_by('-created_at')
# 2. 메인 쿼리에 서브쿼리 적용 (annotate 활용)
"""
values('title')[:1]을 통해 가장 최신 포스트의 'title' 필드값 1개만 추출하여 반환
Subquery는 반드시 하나의 컬럼, 하나의 로우만 반환해야 에러가 나지 않음
"""
categories = Category.objects.annotate(
newest_post_title=Subquery(newest_post_subquery.values('title')[:1])
)
# 3. 결과 확인
for category in categories:
print(f"카테고리: {category.name}, 최신 글 제목: {category.newest_post_title}")
return categories중요 로직 해석
category=OuterRef('pk')- 서브쿼리인 Post.objects 내부에서 필터링을 할 때
- 부모 쿼리인 Category의 pk 값을 가져와서 비교하겠다는 의미
.values('title')[:1]- 서브쿼리는 테이블(다수의 행과 열)을 반환하면 안 되고 단일 값(Scalar 값)을 반환해야
- 메인 쿼리의 하나의 필드로 매핑될 수 있음
- 따라서 특정 필드(values)를 지정하고 하나만(
[:1]) 잘라냄
- 서브쿼리는 테이블(다수의 행과 열)을 반환하면 안 되고 단일 값(Scalar 값)을 반환해야

안녕하세요.