
[2026.02.01] 전체 리뷰조회 필터링 기능 추가
[2026.02.02] 쿼리 최적화
[2026.02.03] README 수정 및 프로필 이미지 관련api 작성
[2026.02.04] 리드미 완성 및 조회api완성
[2026.02.05]
[2026.02.06]
2026.02.01 ✅
전체 리뷰 필터
모델
class Game(models.Model):
name = models.CharField(max_length=255)
intro = models.TextField()
released_at = models.DateField(null=True, blank=True)
developer = models.CharField(max_length=255)
publisher = models.CharField(max_length=255)
created_at = models.DateTimeField(auto_now_add=True)
id_deleted = models.BooleanField(default=False)
avg_score = models.FloatField(default=0)
class Genre(models.Model):
genre = models.CharField(max_length=255, unique=True)
slug = models.SlugField(max_length=255, unique=True)
genre_ko = models.CharField(max_length=255)
class GameGenre(models.Model):
game = models.ForeignKey(Game, on_delete=models.CASCADE, related_name="game_genres")
genre = models.ForeignKey(Genre, on_delete=models.CASCADE, related_name="game_genres")
class Review(TimeStampedModel):
game = models.ForeignKey(Game,on_delete=models.CASCADE,related_name="reviews",)
user = models.ForeignKey(User,on_delete=models.CASCADE,related_name="reviews",)
content = models.TextField(verbose_name="리뷰 내용")
rating = models.PositiveSmallIntegerField(
verbose_name="별점",
validators=[MinValueValidator(1), MaxValueValidator(5)], # 1~5점 제한
help_text="1~5 사이의 정수",
)
view_count = models.BigIntegerField(default=0, verbose_name="조회수")
like_count = models.BigIntegerField(default=0, verbose_name="좋아요 합계")
is_deleted = models.BooleanField(default=False, verbose_name="삭제 여부")목표
-
전체 리뷰를 불러오는 api는 구현이 되어있는데 그 전체 리뷰를 장르별로 필터를 걸고 싶다
시작 모델 (Review) 관계 필드 중간 모델 (Game) 관계 필드 (related_name) 타겟 모델 (Genre) 필터 대상 Review gameGame game_genresGameGenre genre__slug
현상황
- 장르별로 필터를 걸기 위해서는
- Review 모델에서 Game을 거쳐 Genre까지 연결되는 관계(Relationship)를 따라가야 함
- Game과 Genre는 GameGenre라는 중간 모델을 통해 N:M(다대다) 관계를 맺고 있음
- 따라서 Django ORM의 __ (double underscore) 문법을 사용하여 조인을 수행해야 함
코드 수정
service
def get_community_review_all() -> QuerySet[Review]:
"""
커뮤니티용 전체 리뷰 피드를 조회합니다.
모든 게임의 리뷰를 최신순으로 가져오며, 게임 정보도 함께 로딩합니다.
"""
return (
Review.objects.filter(is_deleted=False)
.select_related("user", "game")
.order_by("-created_at")
)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_community_review_all(genre_name: Optional[str] = None) -> QuerySet[Review]:
"""
커뮤니티용 전체 리뷰 피드를 조회합니다.
장르 이름(genre)이 전달되면 해당 장르의 게임 리뷰만 필터링합니다.
"""
# 기본 쿼리셋 (삭제되지 않은 리뷰, User/Game 조인)
queryset = Review.objects.filter(is_deleted=False).select_related("user", "game")
# 장르 이름으로 필터링 적용
if genre_name:
# Review -> Game -> GameGenre -> Genre 순으로 조인
# 마지막 __genre는 Genre 모델의 실제 필드명입니다.
queryset = queryset.filter(game__game_genres__genre__genre=genre_name)
return queryset.order_by("-created_at")views
def get(self, request):
# 1. 커뮤니티 전용 서비스 호출
queryset = get_community_review_all()
# 2. 페이지네이션
paginator = ReviewPageNumberPagination()
page = paginator.paginate_queryset(queryset, request, view=self)
# 3. 커뮤니티 전용 Serializer 사용
if page is not None:
serializer = CommunityReviewListSerializer(page, many=True)
return paginator.get_paginated_response(serializer.data)
serializer = CommunityReviewListSerializer(queryset, many=True)
return Response(serializer.data, status=200)
——————————————————————————————————————[비교]—————————————————————————————————————————
def get(self, request):
# 1. 쿼리 파라미터 추출 (예: ?genre=RPG)
genre_name = request.query_params.get("genre")
# 2. 서비스 호출 (slug 대신 name 전달)
queryset = get_community_review_all(genre_name=genre_name)
# 3. 페이지네이션
paginator = ReviewPageNumberPagination()
page = paginator.paginate_queryset(queryset, request, view=self)
if page is not None:
serializer = CommunityReviewListSerializer(page, many=True)
return paginator.get_paginated_response(serializer.data)
serializer = CommunityReviewListSerializer(queryset, many=True)
return Response(serializer.data, status=200)- 1. if page is not None: (페이지네이션 적용 시)
- paginator.get_paginated_response 메서드는 데이터를
- 메타데이터(개수, 다음 페이지 링크 등)와 함께 감싸서 딕셔너리(Object) 형태로 반환합니다.
{
"count": 100,
"next": "http://api.example.com/reviews/?page=2",
"previous": null,
"results": [ // 실제 데이터는 여기 'results' 안에 들어갑니다.
{ "id": 1, "content": "리뷰 1" },
{ "id": 2, "content": "리뷰 2" }
]
}
- 2. if문 밖 (페이지네이션 미적용 시)
- serializer = CommunityReviewListSerializer(queryset, many=True)의 결과인
- serializer.data는 메타데이터 없이 리스트(Array) 형태 그대로 반환됩니다.
[
{ "id": 1, "content": "리뷰 1" },
{ "id": 2, "content": "리뷰 2" },
...
{ "id": 100, "content": "리뷰 100" } // 모든 데이터가 한 번에 옴
]- paginator.get_paginated_response(serializer.data)
- 이 함수는 단순히 데이터를 내보내는 것이 아니라, 응답 객체(Response)를 새로 생성
- 내부적으로 return Response({'count': ..., 'results': data})와 같은 식으로 구조를 변경
- 따라서 프론트엔드에서는 데이터를 꺼낼 때 response.data.results로 접근필요
- serializer = ...(queryset, many=True)
- QuerySet(DB 데이터)을 JSON으로 변환 가능한 리스트로 바꾼 것
- 보통 이 뒤에 return Response(serializer.data)를 사용하게 되며,
- 프론트엔드에서는 response.data로 바로 배열에 접근
- "페이지네이션이 필요한 상황과 아닌 상황을 모두 처리"하기 위한 방어적인 코드
- URL 파라미터로 ?page=1 등이 들어와서 paginator가 정상적으로 페이지 객체(page)를 만들어냈다면
- 형태 A로 응답을 줍니다.
- 만약 페이지네이션 설정이 꺼져 있거나, 특정 조건에 의해 paginate_queryset이 None을 반환했다면
- 형태 B(전체 데이터 반환)로 응답을 줍니다.
- URL 파라미터로 ?page=1 등이 들어와서 paginator가 정상적으로 페이지 객체(page)를 만들어냈다면
serializers
class CommunityReviewListSerializer(ReviewListSerializer):
"""
기존 리뷰 리스트 정보 + 게임 정보 추가
"""
game_title = serializers.CharField(source="game.name", read_only=True)
class Meta(ReviewListSerializer.Meta):
model = Review
fields = ReviewListSerializer.Meta.fields + ["game_title"]
——————————————————————————————————————[비교]—————————————————————————————————————————
class CommunityReviewListSerializer(ReviewListSerializer):
"""
기존 리뷰 리스트 정보 + 게임 정보 + 장르 정보 추가
"""
game_title = serializers.CharField(source="game.name", read_only=True)
game_genres = serializers.SerializerMethodField()
class Meta(ReviewListSerializer.Meta):
model = Review
# 기존 필드들에 game_title, game_genres 추가
fields = ReviewListSerializer.Meta.fields + ["game_title", "game_genres"]
def get_game_genres(self, obj):
"""
해당 리뷰가 달린 게임의 모든 장르 명칭을 리스트로 반환
예: ["RPG", "Action"]
"""
# obj.game -> Game 객체
# obj.game.game_genres -> GameGenre 역참조 매니저
# gg.genre.genre -> Genre 모델의 genre 필드 (이름)
return [gg.genre.genre for gg in obj.game.game_genres.all()]욕설필터 방식 변경
현재
# utils.py
# 1. 욕설 필터 패턴(정규표현식)
BAD_PATTERNS = [
# 1. "시발" 계열
r"시[^가-힣]*?발",
r"씨[^가-힣]*?발",
# 2. "개새끼" 계열
r"개[^가-힣]*?새[^가-힣]*?끼",
r"새[^가-힣]*?끼",
# 3. "병신" 계열
r"병[^가-힣]*?신",
r"븅[^가-힣]*?신",
# 4. "ㅈ" 계열
r"좆",
r"좇",
r"좃",
# 5. 패드립 계열
r"느[^가-힣]*?금[^가-힣]*?마",
r"느[^가-힣]*?금",
r"니[^가-힣]*?애[^가-힣]*?미",
r"니[^가-힣]*?미",
# 6. "미친" 계열
r"미[^가-힣]*?친",
# 7. "지랄/염병" 계열
r"지[^가-힣]*?랄",
r"염[^가-힣]*?병",
# 8. "호로" 계열
r"호[^가-힣]*?로",
]
# service
def _generate_and_save(self, game: Game, summary_obj) -> dict:
"""
AI 요약 생성 및 DB 저장
"""
# 글자 수 필터링 및 유효 리뷰 개수 확인
bring_reviews = (
game.reviews.annotate(text_len=Length("content")) # type: ignore
.filter(is_deleted=False, text_len__gte=self.min_review_length)
.order_by("-created_at")[:20]
)
clean_reviews = []
for review in bring_reviews:
if self.profanity_pattern.search(review.content):
continue # 욕설 발견 시 건너뜀
clean_reviews.append(review)
if len(clean_reviews) >= self.summary_review_count:
break
# 유효한 리뷰가 설정된 개수(예: 3개) 미만이면 중단
if len(clean_reviews) < self.min_valid_reviews:
logger.warning(
f"Game({game.id}) has enough raw reviews but VALID reviews({len(clean_reviews)}) "
f"are less than {self.min_valid_reviews}."
)
raise NotEnoughValidReviews()
# 리뷰 내용들을 줄바꿈 문자로 연결하여 하나의 문자열로 만듬
reviews_text = "\n".join([f"- {r.content}" for r in clean_reviews])해결
# utils.py
from korcen import korcen
def is_valid_review_for_ai(text: str) -> bool:
"""
AI 요약에 사용할 리뷰인지 판단합니다.
- 욕설이 없으면: 무조건 통과
- 욕설이 있으면: 정보량이 충분한지(길이) 확인하여 통과 여부 결정
- 사용 가능하면 True, 버려야 하면 False
"""
# 1. 욕설 여부 확인
if korcen.check(text):
# 2. 욕설이 있는데 길이가 짧다면 (ex. "개망겜", "ㅈ노잼") -> 정보 가치 없음, 토큰 낭비
if len(text) < 10:
return False
# 3. 욕설이 있지만 길이가 길다면 (ex. "재미는 있는데 운영이 쓰레기임") -> 정보 가치 있음
return True
# 4. 욕설이 없으면 통과
return True
# service
def _generate_and_save(self, game: Game, summary_obj) -> dict:
"""
AI 요약 생성 및 DB 저장
"""
# 글자 수 필터링 및 유효 리뷰 개수 확인
bring_reviews = (
game.reviews.annotate(text_len=Length("content")) # type: ignore
.filter(is_deleted=False, text_len__gte=self.min_review_length)
.order_by("-created_at")[:20]
)
clean_reviews = []
for review in bring_reviews:
# 욕설 포함여부만 판단
if not is_valid_review_for_ai(review.content):
continue # 유효하지 않은(짧은 욕설 등) 리뷰는 건너뜀
clean_reviews.append(review)
if len(clean_reviews) >= self.summary_review_count:
break코드 구조 수정
"메서드화해서 위에서 관리하라"
- 문제점
- 비즈니스 로직(데이터 조회, 저장 등)과 데이터(프롬프트 텍스트)가 섞여 있어
- 코드가 길어지고 가독성이 떨어짐
- 프롬프트만 수정하고 싶을 때도 로직 코드를 뒤져야 함
- 해결책 ("위에서 관리")
- 프롬프트 템플릿을 클래스 상단(속성)이나
__init__메서드에서 정의하여 설정값처럼 관리
- 해결책 ("메서드화")
- 프롬프트를 생성하는 역할만 전담하는 별도의 메서드(
_build_prompt등) 로 분리하여 호출
- 프롬프트를 생성하는 역할만 전담하는 별도의 메서드(
# AI에게 보낼 사용자 프롬프트를 구성
user_prompt = f"""
게임명: {game.name}
아래 유저 리뷰들을 분석해서 지정된 JSON 스키마에 맞춰 요약해줘.
[Review Data]
{reviews_text}
"""class ReviewSummaryService:
def __init__(self):
"""
서비스 초기화: Client 생성 및 공통 설정 정의
"""
...
# AI에게 보낼 사용자 프롬프트
self.user_prompt_template = (
"게임명: {game_name}\n"
"아래 유저 리뷰들을 분석해서 지정된 JSON 스키마에 맞춰 요약해줘.\n\n"
"[Review Data]\n"
"{reviews_text}"
)
...
def _build_user_prompt(self, game_name: str, reviews_text: str) -> str:
return self.user_prompt_template.format(
game_name=game_name, reviews_text=reviews_text
)
...
def _generate_and_save(self, game: Game, summary_obj) -> dict:
"""
AI 요약 생성 및 DB 저장
"""
# 글자 수 필터링 및 유효 리뷰 개수 확인
bring_reviews = (
game.reviews.annotate(text_len=Length("content")) # type: ignore
.filter(is_deleted=False, text_len__gte=self.min_review_length)
.order_by("-created_at")[:20]
)
clean_reviews = []
for review in bring_reviews:
# 욕설 포함여부만 판단
if not is_valid_review_for_ai(review.content):
continue캐시 처리 수정
타임아웃이 아닌 진행 중에 완료가 되면 캐시를 지우는 코드 필요
현재
- cache.set(cache_key, "processing", timeout=10)
- timeout=10으로 설정하여 10초가 지나면 무조건 캐시가 사라집니다.
- 만약 분석이 2초 만에 끝나도 캐시는 8초간 남아있어 "진행 중"으로 뜰 수 있고,
- 반대로 20초가 걸리면 중간에 캐시가 풀려 중복 실행될 위험이 있습니다.
수정
- API에서는 캐시를 설정하기만 하고(Lock),
- Celery Task(백그라운드 작업)가 작업을 완료한 직후 스스로 캐시를 삭제(Unlock)해야
- 가장 정확
AI 태스크를 돌리기 위한 밸리데이션도 Celery로 넘기기
현재
- (코드에는 안 보이지만) 만약 AI 분석 전 "데이터가 충분한가?" 등을 검사하는 로직이
- 이 함수 안에 있다면, 그 계산 시간만큼 사용자는 기다려야 함
- (코드에는 안 보이지만) 만약 AI 분석 전 "데이터가 충분한가?" 등을 검사하는 로직이
수정
- API는 "요청 접수"만 하고 즉시 응답합니다.
- 데이터가 충분한지, 분석이 가능한지는 백그라운드 워커(Celery)가 나중에 판단하여
- 불가능하면 '실패' 상태를 DB에 남기는 방식이 더 효율적임
캐시를 지워야 하는 이유
| 구분 | 캐시 삭제 안 함 (Timeout만 의존) | 캐시 직접 삭제 (Task 완료 시) |
|---|---|---|
| 비유 | 화장실 쓰고 문 잠근 채로 창문으로 탈출함 (문은 5분 뒤에 자동으로 열림) | 화장실 다 쓰고 나오면서 문을 열어둠 |
| 작업 성공 시 | 작업은 3초에 끝났지만, 5분간 재요청 불가 | 작업 끝나자마자 즉시 재요청/결과 확인 가능 |
| 작업 실패 시 | 실패했는데도 계속 "처리 중"이라고 거짓말 함 | 즉시 "처리 중" 해제 -> 유저가 바로 재시도 가능 |
| 사용자 경험 | 답답함 (왜 안 되지?) | 쾌적함 (빠릿빠릿함) |
-
"작업이 끝났는데도 사용자가 하염없이 기다리는 상황을 막기 위해서"
상황 1: 캐시를 안 지울 때 (기존 방식)
- 상황: 손님이 탈의실에 들어가며 "사용 중" 팻말을 겁니다. (캐시 설정, 타임아웃 5분)
- 작업: 손님이 옷을 갈아입는 데 3초밖에 안 걸렸습니다.
- 문제: 손님은 이미 나갔는데, "사용 중" 팻말은 5분 동안 문에 그대로 걸려있습니다.
- 결과
- 다음 손님(혹은 본인이 다시 들어가려 할 때)은 탈의실이 비어있는데도
- 4분 57초 동안 문 밖에서 기다려야 합니다.
상황 2: 캐시를 지울 때 (수정 방식)
- 상황: 손님이 들어갈 때 "사용 중" 팻말을 겁니다.
- 작업: 옷을 3초 만에 갈아입었습니다.
- 해결: 나오면서 직접 "사용 중" 팻말을 뗍니다(Cache Delete).
- 결과: 팻말이 사라지자마자 다음 손님이 바로 들어갈 수 있습니다.
-
기술적 이유
즉각적인 상태 동기화 (UX 향상)
- AI 분석이 예상보다 빨리 끝나서 5초 만에 성공했다면,
- 시스템은 즉시 "처리 중" 상태를 해제해야 합니다.
- 그래야 프론트엔드에서 새로고침을 하거나 재요청을 했을 때 막히지 않고 결과를 볼 수 있음
- AI 분석이 예상보다 빨리 끝나서 5초 만에 성공했다면,
재시도 기회 부여 (Error Handling)
- 만약 AI 서버가 잠깐 오류가 나서 작업이 1초 만에 실패했다고 가정해 봅시다.
- 캐시를 안 지우면, 유저는 실패했음에도 불구하고 타임아웃(5분)이 끝날 때까지
- "분석 중입니다..." 메시지만 보게 됩니다.
- 작업이 실패하자마자 캐시를 지워주면, 유저는 바로 "다시 시도" 버튼을 눌러볼 수 있습니다.
수정방향
| 구분 | AS-IS (기존) | TO-BE (수정 방향) | 이점 |
|---|---|---|---|
| 캐시 해제 시점 | timeout=10 (10초 후 자동 만료) | Celery Task 완료(finally) 시점에 cache.delete() 호출 | 작업 시간이 10초를 넘거나 1초 만에 끝나도, 정확한 작업 종료 시점에 상태 동기화 가능 |
| 타임아웃 역할 | 작업 종료 예상 시간 (불확실) | 비상 안전 장치 (Zombie Lock 방지용, 5분 등 넉넉히 설정) | 서버 장애 등으로 Task가 비정상 종료되어도 영원히 락이 걸리는 것 방지 |
| 데이터 검증 | API 뷰/서비스(메인 스레드)에서 수행 | Celery Task 내부로 이동 | 검증 로직이 복잡해져도 API 응답 속도(Response Time)는 항상 빠름 |
| 역할 분담 | API가 상태 추측 및 검증 혼합 | API는 트리거(Trigger), Task가 실제 처리/상태관리 | 관심사의 분리(SoC)를 통해 코드가 간결해지고 유지보수성 향상 |
현재
# service
def get_or_create_tendency(self, user) -> dict:
"""
API View에서 호출: DB 데이터를 우선 반환하고, 없으면 분석 요청
"""
from apps.ai.tasks.user_tendency import run_user_tendency_analysis
if hasattr(user, "ai_tendency"):
return {"status": "completed", "tendency": user.ai_tendency.tendency}
# 2. 캐시 확인 (이미 분석 중인지 체크)
cache_key = f"debounce_tendency_analysis_{user.id}"
if cache.get(cache_key):
# 이미 Task가 돌고 있다면 그냥 "처리 중" 메시지만 반환하고 Task는 실행 X
return {
"status": "processing",
"message": "성향 분석이 진행 중입니다. 잠시만 기다려주세요.",
"tendency": None,
}
# 3. 데이터도 없고, 분석 중도 아니라면 -> 분석 요청 (비동기)
# 캐시 설정 (분석 중임을 표시, 10초 쿨타임)
cache.set(cache_key, "processing", timeout=10)
run_user_tendency_analysis.delay(user.id)
return {
"status": "processing",
"message": "성향 분석이 시작되었습니다.",
"tendency": None,
}
# tasks
@shared_task
def run_user_tendency_analysis(user_id: int):
"""
유저 ID를 받아 성향 분석을 비동기로 수행
"""
from apps.ai.services.user_tendency_service import UserTendencyService
User = get_user_model()
try:
user = User.objects.get(id=user_id)
logger.info(f"Start User Tendency Analysis for User ID: {user_id}")
# 서비스의 분석 로직 호출
service = UserTendencyService()
service.analyze_and_save(user)
logger.info(f"Successfully finished analysis for User ID: {user_id}")
except User.DoesNotExist:
logger.error(f"User not found during tendency analysis: {user_id}")
except Exception as e:
logger.error(f"Error in User Tendency Task: {e}", exc_info=True)수정
# service
def get_or_create_tendency(self, user) -> dict:
"""
API View에서 호출: DB 데이터를 우선 반환하고, 없으면 분석 요청
"""
from apps.ai.tasks.user_tendency import run_user_tendency_analysis
# 1. DB 데이터가 이미 있다면 바로 반환
if hasattr(user, "ai_tendency"):
return {"status": "completed", "tendency": user.ai_tendency.tendency}
# 2. 캐시 확인 (분석 진행 중 여부 체크)
# 기존 'debounce'는 단순 중복 방지 용어라 'lock'으로 변경하여 상태 관리 의미 강화
cache_key = f"tendency_analysis_lock_{user.id}"
if cache.get(cache_key):
# 이미 Task가 돌고 있다면 API는 기다리라는 메시지만 반환
return {
"status": "processing",
"message": "성향 분석이 진행 중입니다. 잠시만 기다려주세요.",
"tendency": None,
}
# 3. 데이터도 없고, 분석 중도 아니라면 -> 분석 요청 (비동기)
# [수정 포인트] 타임아웃을 10초 -> 5분으로 변경
# 작업이 10초보다 길어질 경우 락이 풀려 중복 실행되는 것을 방지합니다.
# 실제 락 해제는 Celery Task가 끝날 때 수행하므로, 이 시간은 '비상용 안전 장치'입니다.
cache.set(cache_key, "processing", timeout=60 * 5)
# [수정 포인트] 밸리데이션 로직 이동
# 만약 "분석 가능한지 검사"하는 로직이 있다면 여기(API)가 아닌 Task 내부에서 수행합니다.
run_user_tendency_analysis.delay(user.id)
return {
"status": "processing",
"message": "성향 분석 요청이 접수되었습니다.",
"tendency": None,
}
# task
@shared_task
def run_user_tendency_analysis(user_id: int):
"""
유저 ID를 받아 성향 분석을 비동기로 수행
"""
from apps.ai.services.user_tendency_service import UserTendencyService
from django.core.cache import cache
User = get_user_model()
cache_key = f"tendency_analysis_lock_{user_id}"
try:
user = User.objects.get(id=user_id)
logger.info(f"Start User Tendency Analysis for User ID: {user_id}")
# 서비스의 분석 로직 호출
service = UserTendencyService()
service.analyze_and_save(user)
logger.info(f"Successfully finished analysis for User ID: {user_id}")
except User.DoesNotExist:
logger.error(f"User not found during tendency analysis: {user_id}")
except Exception as e:
logger.error(f"Error in User Tendency Task: {e}", exc_info=True)
finally:
# 성공하든 실패하든 작업끝나면 무조건 락 해제
cache.delete(cache_key)결과
- 락(Lock)이 중복 실행을 막아줌 (6번 호출 → 1번 실행)
- 사용자가 태그 6개를 다다닥 누르면 API 요청은 6번 날아옴
- 첫 번째 요청
- "어? 락(Lock)이 없네? 내가 Task 실행 시키고 문 잠글게(Lock 설정)!" -> Task 시작
- 두 번째 ~ 여섯 번째 요청
- "어? 문 잠겨있네(Processing)? 이미 누가 하고 있구나. 난 그냥 갈게." -> Task 실행X
2026.02.02 ✅
쿼리 확인
db.connection.queries
- API가 호출될 때마다 실행된 SQL 개수와 쿼리 문을 터미널에 출력해주는 데코레이터
# utils.py
import functools
import time
from django.db import connection, reset_queries
def query_debugger(func):
"""
함수 실행 시 발생한 SQL 쿼리 개수와 실행 시간을 출력하는 데코레이터
"""
@functools.wraps(func)
def wrapper(*args, **kwargs):
reset_queries() # 쿼리 로그 초기화
start_time = time.time()
start_queries = len(connection.queries)
result = func(*args, **kwargs)
end_queries = len(connection.queries)
end_time = time.time()
print(f"\n[Query Debugger] '{func.__name__}'")
print(f" - Execution Time: {(end_time - start_time):.4f}s")
print(f" - Number of Queries: {end_queries - start_queries}")
# 실제 발생한 쿼리문 출력 (필요 시 주석 해제)
# for i, query in enumerate(connection.queries[start_queries:], 1):
# print(f" {i}. {query['sql']}")
print("=" * 30 + "\n")
return result
return wrapper사용 방법
- View의 메서드(get, post 등)나 Service의 메서드 위에
@query_debugger를 붙이기
- View의 메서드(get, post 등)나 Service의 메서드 위에
from apps.ai.utils import query_debugger
class GameReviewSummaryAPIView(APIView):
# ... (생략)
@query_debugger # <-- 여기에 붙이세요
def get(self, request, game_id):
# ... 원래 코드실행
- 방법 1. API를 통해 실행하기 (가장 간편)
- get_summary 위에 @query_debugger를 붙입니다.
- 서버를 켭니다 (python manage.py runserver).
- API를 요청합니다. (예: /api/ai/summary/1/ 접속)
- 서버가 실행 중인 터미널(콘솔)을 확인하면 쿼리 개수 로그가 찍혀 있습니다.
- 방법 2. 함수만 따로 실행하기
- 터미널에서 쉘 진입
- python manage.py shell
- 쉘 안에서 서비스 클래스를 import 하고 실행
- 터미널에서 쉘 진입
- 방법 1. API를 통해 실행하기 (가장 간편)
# 1. 서비스 임포트 (경로는 실제 프로젝트 구조에 맞게 수정)
from apps.ai.services.review_summary_service import ReviewSummaryService
# 2. 서비스 인스턴스 생성
service = ReviewSummaryService()
# 3. 함수 실행 (게임 ID는 테스트하고 싶은 ID로)
# 이때 터미널에 [Query Debugger] 로그가 출력됩니다.
service.get_summary(game_id=1)service - 1
캐시가 있어도 항상 리뷰 개수를 셈 (count 쿼리 발생)
- Game 조회 (DB 호출)
- game.reviews.count() (DB 호출 - 무조건 실행)
- 리뷰 개수 부족하면 에러
- 그 다음에 summary 캐시 확인
- 이미 요약본이 생성되어 있다면(summary 존재), 굳이 리뷰 개수를 다시 셀 필요가 없음
비교
def get_summary(self, game_id: int) -> dict:
"""
외부에서 호출하는 요약 조회 메서드
"""
try:
game = Game.objects.select_related("summary").get(id=game_id)
except Game.DoesNotExist:
raise GameNotFound()
review_count = game.reviews.filter(is_deleted=False).count() # type: ignore
if review_count < self.min_review_count:
raise NotEnoughReviews()
summary_obj = getattr(game, "summary", None)
# 갱신이 필요한지 확인(필요OX)
if self._update_and_parse(summary_obj):
# 갱신이 필요하면 AI 생성 및 저장을 수행하고 결과를 반환
return self._generate_and_save(game, summary_obj)
# 갱신이 필요 없으면 DB에 저장된 JSON 텍스트를 파싱하여 반환
return json.loads(summary_obj.text) # type: ignore
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_summary(self, game_id: int) -> dict:
try:
game = Game.objects.get(id=game_id)
except Game.DoesNotExist:
raise GameNotFound()
# 1. 캐시(요약본)가 있는지 먼저 확인 (DB 접근 최소화)
# OneToOneField는 game.summary 접근 시 DB 조회가 발생할 수 있으니
# try-except나 hasattr로 처리합니다.
summary_obj = getattr(game, "summary", None)
# 2. 갱신이 필요한지 체크
if not self._update_and_parse(summary_obj):
# 갱신 필요 없으면 바로 리턴! (여기서 리뷰 카운트 쿼리 생략됨 -> 최적화)
return json.loads(summary_obj.text)
# 3. 요약본이 없거나 갱신이 필요할 때만 리뷰 개수 체크 (쿼리 발생)
review_count = game.reviews.filter(is_deleted=False).count()
if review_count < self.min_review_count:
raise NotEnoughReviews()
# 4. 생성 및 저장
return self._generate_and_save(game, summary_obj)
- 쿼리 개수 동일
# [쿼리 1] 게임을 가져옵니다. (여기서 summary는 안 가져옴)
game = Game.objects.get(id=game_id)
# [쿼리 2] 여기서 DB를 한 번 더 다녀옵니다!
# game.summary에 접근하는 순간, Django는 summary 정보를 가져오기 위해
# "SELECT * FROM game_review_summary ..." 쿼리를 날립니다.
summary_obj = getattr(game, "summary", None)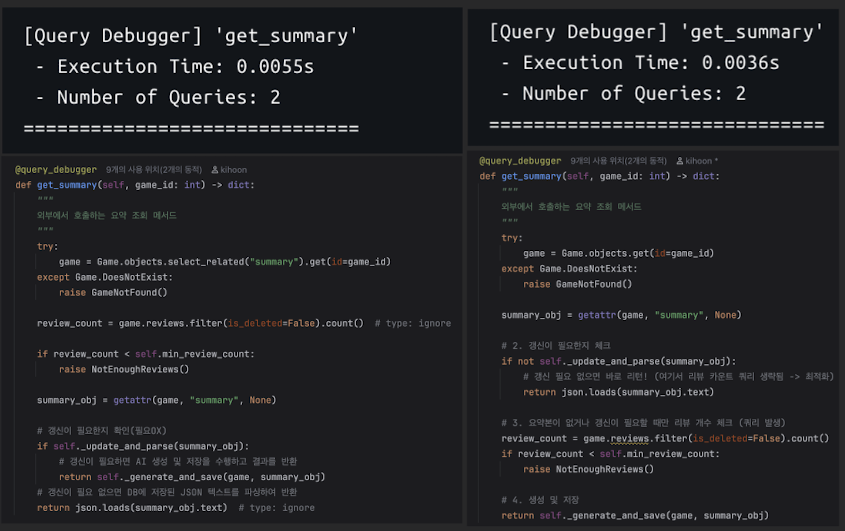
최종
def get_summary(self, game_id: int) -> dict:
try:
# [수정] select_related를 추가하여 Query를 1개로 줄임 (JOIN)
game = Game.objects.select_related("summary").get(id=game_id)
except Game.DoesNotExist:
raise GameNotFound()
# [메모리 접근] 이미 위에서 가져왔으므로 여기서는 쿼리가 발생하지 않음
summary_obj = getattr(game, "summary", None)
# 2. 갱신이 필요한지 체크
if not self._update_and_parse(summary_obj):
# 여기까지 쿼리 총 1개 발생 (Game + Summary JOIN)
return json.loads(summary_obj.text)
# 3. 갱신이 필요할 때만 카운트 쿼리 발생
review_count = game.reviews.filter(is_deleted=False).count()
if review_count < self.min_review_count:
raise NotEnoughReviews()
return self._generate_and_save(game, summary_obj)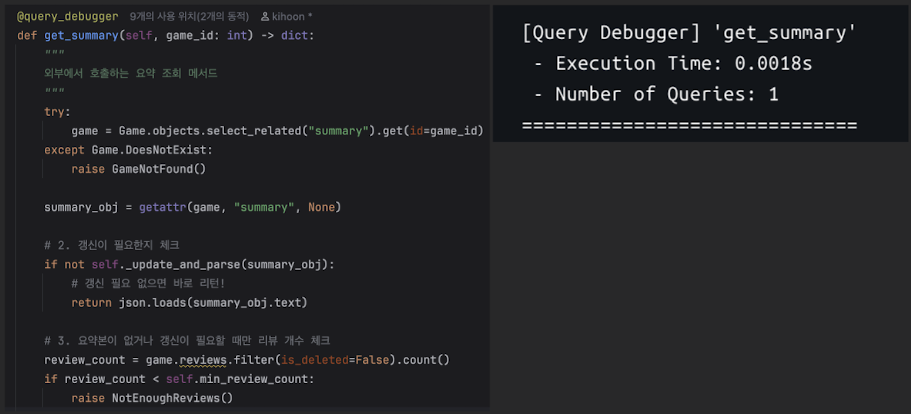
service - 2
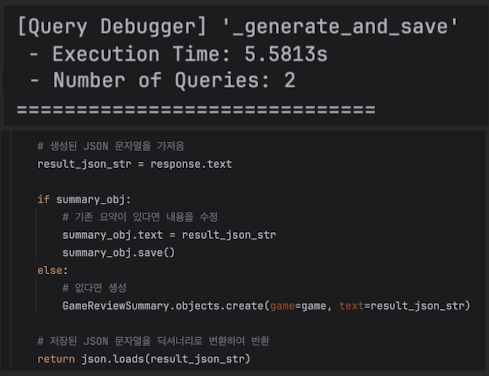
transaction.atomic()의 불필요한 오버헤드
- transaction.atomic()은 DB에 BEGIN; ... COMMIT; (또는 SAVEPOINT) 명령을 보냅니다.
- 하지만 내부 코드를 보면 save() 혹은 create() 단 하나의 쿼리만 실행됩니다.
- Django의 save()와 create()는 그 자체로 이미 원자성(Atomic)을 가집니다.
- 즉, 여러 테이블을 동시에 수정하는 게 아니라면 굳이 트랜잭션 블록을 열 필요가 없습니다.
- with transaction.atomic(): 라인을 지우고 들여쓰기만 정리하면 쿼리(커맨드) 2개를 아낌
# 현재 코드
with transaction.atomic(): # 오버헤드
if summary_obj:
summary_obj.text = result_json_str
summary_obj.save()
else:
GameReviewSummary.objects.create(game=game, text=result_json_str)
——————————————————————————————————————[비교]—————————————————————————————————————————
- Django에서 transaction.atomic()을 사용하면
- DB 내부적으로 트랜잭션을 관리하기 위해 앞뒤로 쿼리를 날림
- 진입할 때: SAVEPOINT ... (쿼리 1개)
- 나올 때: RELEASE SAVEPOINT ... (쿼리 1개)
- 즉, atomic()을 쓰면 아무것도 안 해도 쿼리 카운트가 +2
- DB 내부적으로 트랜잭션을 관리하기 위해 앞뒤로 쿼리를 날림
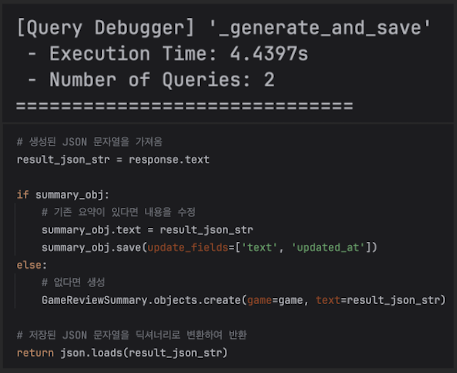
save() 시 전체 필드 업데이트 (Update 쿼리 최적화)
- Django의 save()는 기본적으로 모델의 모든 필드를 UPDATE 문에 포함시킵니다.
- summary_obj는 created_at 같은 다른 필드도 가지고 있는데,
- 내용(text)만 바뀌었음에도 DB에는 모든 컬럼을 덮어쓰는 무거운 쿼리가 날아갑니다.
- 해결: update_fields 옵션을 사용하여 변경된 컬럼만 콕 집어서 업데이트하기
- Django의 save()는 기본적으로 모델의 모든 필드를 UPDATE 문에 포함시킵니다.
# 현재 코드
summary_obj.text = result_json_str
summary_obj.save()
——————————————————————————————————————[비교]—————————————————————————————————————————
summary_obj.text = result_json_str
summary_obj.save(update_fields=['text', 'updated_at'])리뷰 데이터 가져올 때 불필요한 컬럼 조회 (.only() 미사용)
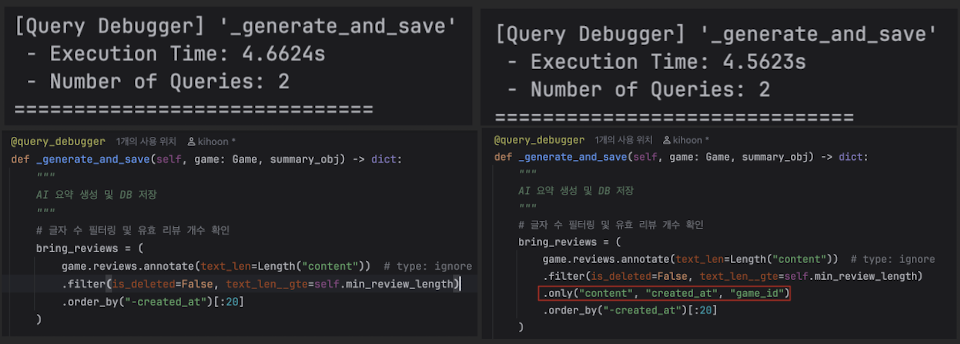
# 현재 코드
bring_reviews = (
game.reviews.annotate(text_len=Length("content"))
.filter(...)
.order_by("-created_at")[:20]
)
——————————————————————————————————————[비교]—————————————————————————————————————————
# 수정 코드
bring_reviews = (
game.reviews.annotate(text_len=Length("content"))
.filter(is_deleted=False, text_len__gte=self.min_review_length)
.only('content', 'created_at', 'game_id') # <--- 필요한 것만 조회
.order_by("-created_at")[:20]
)- 더 느려지기는 했지만 ai호출 때문인것 같음
- 리뷰 데이터(content)가 엄청나게 길지 않다면(수천 자 이상), 효과는 미미
- 오히려 코드가 복잡해지거나 실수할 여지가 생긴다면 과감히 빼기로 결정
.only()를 쓰면 Django는 내부적으로 "이 필드는 가져왔고, 저 필드는 나중에 가져와야지"라고- 관리하는 추가적인 연산(오버헤드)을 수행
- 리뷰 본문(content)이 엄청나게 긴 글(수 KB 이상)이 아니라면,
- 그냥 다 가져오는 속도나 골라서 가져오는 속도나 DB 입장에서는 비슷
- 오히려 Python 레벨에서 필드 관리하느라 시간이 더 걸림
from apps.ai.services.review_summary_service import ReviewSummaryService
from apps.game.models.game import Game
# 1. 서비스 준비
service = ReviewSummaryService()
# 2. 테스트할 게임 가져오기
game = Game.objects.get(id=97) # 테스트할 게임 ID
# 3. _generate_and_save 직접 호출 (summary_obj는 None으로 줘서 생성 유도)
# 이때 터미널에 쿼리 개수가 바로 찍힙니다!
service._generate_and_save(game, None)helper review
삭제된 리뷰/댓글도 수정·삭제 가능
- is_deleted=False 조건 없이 수정/삭제 허용
def get_review(self, request, review_id) -> Review:
"""
리뷰 조회 및 권한 검증을 수행
"""
try:
review = Review.objects.get(id=review_id)
except Review.DoesNotExist:
raise ReviewNotFound()
——————————————————————————————————————[비교]—————————————————————————————————————————
def get_review(self, request, review_id) -> Review:
"""
리뷰 조회 및 권한 검증을 수행
"""
try:
review = Review.objects.get(id=review_id, is_deleted=False)
except Review.DoesNotExist:
raise ReviewNotFound()삭제된 리뷰에도 좋아요 가능
- 좋아요 로직에 is_deleted 체크 없음
def _get_review_with_lock(review_id: int) -> Review:
"""
리뷰를 Lock과 함께 조회하고, 없으면 예외를 발생시킴
"""
try:
return Review.objects.select_for_update().get(id=review_id)
except Review.DoesNotExist:
raise ReviewNotFound()
——————————————————————————————————————[비교]—————————————————————————————————————————
def _get_review_with_lock(review_id: int) -> Review:
try:
return Review.objects.select_for_update().get(id=review_id, is_deleted=False)
except Review.DoesNotExist:
raise ReviewNotFound()DELETE 204 응답에 바디 포함 제거
def delete(self, request, review_id):
# 1. 조회 & 검증
review = self.get_review(request, review_id)
# 2. 서비스 호출
delete_review(review=review)
return Response(
{"message": "리뷰가 삭제되었습니다."}, status=status.HTTP_204_NO_CONTENT
)
def delete(self, request, comment_id):
# 1. 조회 & 검증
comment = self.get_comment(request, comment_id)
# 2. 서비스 레이어 호출
delete_comment(comment=comment)
return Response(
{"message": "댓글이 삭제되었습니다."}, status=status.HTTP_204_NO_CONTENT
)
——————————————————————————————————————[비교]—————————————————————————————————————————
def delete(self, request, comment_id):
# 1. 조회 & 검증
comment = self.get_comment(request, comment_id)
# 2. 서비스 레이어 호출
delete_comment(comment=comment)
return Response(
status=status.HTTP_204_NO_CONTENT
)
def delete(self, request, review_id):
# 1. 조회 & 검증
review = self.get_review(request, review_id)
# 2. 서비스 호출
delete_review(review=review)
return Response(
status=status.HTTP_204_NO_CONTENT
)2026.02.03 ✅
프로필 이미지 api
views
class ProfileImageView(APIView):
permission_classes = [IsAuthenticated]
parser_classes = [MultiPartParser, FormParser]
"""
- 1. parser_classes
- 일반적인 JSON 요청과 달리, 이미지 업로드는 'multipart/form-data' 형식을 사용함
- Django REST Framework가 이 형식을 이해하고
- 파일 데이터를 request.FILES (request.data)에 매핑하기 위해서는 MultiPartParser가 반드시 필요합니다.
"""
@extend_schema(tags=["프로필"], summary="프로필이미지 업로드", request=ProfileImageSerializer)
def post(self, request):
# 1. 입력 데이터 검증
serializer = ProfileImageSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
# 2. 서비스 호출
service = ProfileImageService()
image_url = service.update_profile_image(
user=request.user, image_file=serializer.validated_data["profile_image"]
)
return Response(
{"message": "프로필 사진이 등록되었습니다.", "profile_img_url": image_url},
status=status.HTTP_200_OK,
)
@extend_schema(tags=["프로필"], summary="프로필 이미지 삭제")
def delete(self, request):
# 1. 서비스 호출
service = ProfileImageService()
service.delete_profile_image(request.user)
return Response(status=status.HTTP_204_NO_CONTENT)
service
class ProfileImageService:
def delete_existing_image(self, user):
"""
기존 프로필 이미지가 존재한다면 삭제
"""
if user.profile_img_url:
try:
media_url = settings.MEDIA_URL
# URL이 MEDIA_URL로 시작하는 경우에만 경로 추출 시도
if user.profile_img_url.startswith(media_url):
path = user.profile_img_url.replace(media_url, "", 1)
"""
- 2. 분석: URL vs 파일 경로
- DB에는 'http://.../media/profile/img.jpg' 같은 URL이 저장되어 있지만,
- 파일을 삭제하려면 물리적 경로(또는 상대 경로)인 'profile/img.jpg'가 필요
- 따라서 MEDIA_URL 접두사를 제거하여 스토리지 시스템이 이해할 수 있는 경로로 변환하는 과정
"""
if default_storage.exists(path):
default_storage.delete(path)
"""
- 3. default_storage 사용 이유
- os.remove() 대신 default_storage.delete()를 사용하는 것이 좋음
- 나중에 로컬이 아닌 AWS S3 등으로 저장소를 변경할 때 코드를 수정할 필요가 없어짐
"""
except Exception:
pass
def update_profile_image(self, user, image_file):
"""
프로필 이미지를 등록합니다.
"""
# 1. 기존 이미지가 있다면 삭제
self.delete_existing_image(user)
# 2. 파일명 난수화
ext = os.path.splitext(image_file.name)[1] # .jpg, .png 등 확장자 추출
new_filename = f"{uuid.uuid4()}{ext}"
file_path = f"profile_images/{new_filename}"
"""
- 4. UUID 사용 이유
- 사용자가 올린 파일명(예: 'image.jpg')을 그대로 쓰면, 다른 사용자의 'image.jpg'를 덮어쓰거나
- 한글/특수문자 파일명 때문에 오류가 날 수 있음
- UUID로 고유한 랜덤 이름을 생성하여 이를 방지하는 필수적인 패턴
"""
# 3. 파일 저장
saved_path = default_storage.save(file_path, image_file)
image_url = default_storage.url(saved_path)
"""
- 5. 저장 및 URL 획득
- default_storage.save(): 실제 물리적(혹은 클라우드) 공간에 파일을 사용
- default_storage.url(): 저장된 파일에 접근할 수 있는 웹 URL을 반환
"""
# 4. DB 업데이트
user.profile_img_url = image_url
user.save(update_fields=["profile_img_url"])
return image_url
def delete_profile_image(self, user):
"""
프로필 이미지를 삭제하여 기본이미지로 전환
"""
# 1. 이미지 삭제
self.delete_existing_image(user)
# 2. DB 필드 초기화
user.profile_img_url = None
user.save(update_fields=["profile_img_url"])
2026.02.05 ✅
2026.02.06 ✅
구글 스크립트
# 파이썬 터미널에서 실행
client_id = "~"
# View 코드에 적은 주소와 토씨 하나 틀리지 않고 똑같아야 함
redirect_uri = "http://localhost:8000/api/v1/user/google/login"
url = f"https://accounts.google.com/o/oauth2/v2/auth?client_id={client_id}&redirect_uri={redirect_uri}&response_type=code&scope=email profile"
print(url)2026.02.07 ✅
구글 소셜 리뷰
View
code = request.GET.get("code")
redirect_uri = (
"http://localhost:8000/api/v1/user/google/login"
if settings.DEBUG
else "https://swbak.cloud/api/v1/user/google/login"
)
# [리뷰 1] 하드코딩된 URL 관리
# 현재 settings.DEBUG에 따라 URL을 분기하고 있는데, 이는 배포 환경이 늘어나거나 도메인이 변경될 때마다 코드를 수정해야 합니다.
# 개선 제안: .env 파일이나 settings.py에 'GOOGLE_CALLBACK_URI' 등의 변수로 관리하는 것이 좋습니다.
# 주의: 이 redirect_uri는 프론트엔드에서 구글 로그인 버튼을 누를 때 사용한 redirect_uri와 '정확히' 일치해야 구글이 승인합니다.
front_url = (
"http://localhost:3000"
if settings.DEBUG
else "https://oz-union-fe-14-team1.vercel.app"
)
# [리뷰 2] 프론트엔드 URL 분리
# 위와 마찬가지로 프론트엔드 주소도 환경변수(예: FRONTEND_BASE_URL)로 관리하는 것이 안전합니다.서비스
try:
# 2. 구글 서버 통신 (토큰 & 유저정보 가져오기)
service = GoogleLoginService(redirect_uri=redirect_uri)
access_token = service.get_access_token(code)
google_user_info = service.get_user_info(access_token)
email = google_user_info.get("email")
email_verified = google_user_info.get("email_verified")
social_id = google_user_info.get("sub")
if not email_verified:
return redirect(f"{front_url}/login/fail?error=email_not_verified")
# [리뷰 3] 이메일 검증
# 구글 계정이지만 이메일 인증이 안 된 경우를 거르는 로직은 보안상 매우 좋습니다.
# 추가로 google_user_info에서 'sub'(social_id)가 없는 경우에 대한 예외 처리도 고려해볼 만합니다.핵심 로직
# 3. 회원가입/로그인 로직 (기존과 동일)
with transaction.atomic():
# [리뷰 4] 트랜잭션 범위
# 외부 API 호출(구글 통신)은 트랜잭션 밖에서 수행하고, DB 작업만 묶은 것은 성능상 아주 훌륭한 선택입니다.
social_account = SocialAccount.objects.filter(
provider="google", social_id=social_id
).first()
if social_account:
user = social_account.user
else:
user = User.objects.filter(email=email).first()
if not user:
user = User.objects.create_user(email=email, password=None)
# [리뷰 5] 비밀번호 처리
# 소셜 로그인 사용자는 비밀번호가 필요 없으므로 None이나 사용할 수 없는 문자열로 설정하는 것이 맞습니다.
# 다만, 추후 이메일/비번 찾기 시 혼동이 없도록 'is_social_user' 같은 플래그나 로직이 필요할 수 있습니다.
SocialAccount.objects.create(
user=user, provider="google", social_id=social_id
)
# [리뷰 6] 계정 연동 로직
# 기존에 일반 이메일로 가입한 유저가 같은 이메일로 구글 로그인을 시도할 때,
# 자동으로 계정을 연동(Link)시켜주는 로직입니다. 사용자 경험(UX) 측면에서 좋은 흐름입니다.토큰 발급 및 응답
# 4. 우리 서비스 토큰 발급
token_service = TokenService()
refresh_token, new_access_token = token_service.create_token_pair(user=user)
response = redirect(f"{front_url}/login/success?token={new_access_token}")
# [리뷰 7] 토큰 전달 방식
# Access Token을 URL 쿼리 파라미터로 전달하고 있습니다.
# 리다이렉트 방식에서는 흔히 사용되지만, 브라우저 히스토리나 로그에 토큰이 남을 수 있는 보안 약점이 있습니다.
# 보안을 더 강화하려면 프론트엔드와 핸드셰이크 과정을 거치거나, 짧은 수명의 임시 토큰을 발급하는 방법을 고려할 수 있습니다.
# 5. Refresh Token은 안전하게 쿠키에 굽기
set_refresh_cookie(response, refresh_token)
# [리뷰 8] 리프레시 토큰 보안
# 리프레시 토큰을 쿠키(HttpOnly)로 설정하는 것은 XSS 공격 방어에 매우 권장되는 방식입니다. 잘 구현되었습니다.
return responseService
class GoogleLoginService:
TOKEN_URI = "https://oauth2.googleapis.com/token"
USER_INFO_URI = "https://www.googleapis.com/oauth2/v3/userinfo"
def __init__(self, redirect_uri):
self.client_id = settings.GOOGLE_CLIENT_ID
self.client_secret = settings.GOOGLE_CLIENT_SECRET
self.redirect_uri = redirect_uri
# [리뷰 9] 설정값 의존성
# settings에서 CLIENT_ID와 SECRET을 가져오는 방식은 표준적입니다.
# redirect_uri를 __init__에서 받는 것은 View에서 동적으로 URI를 결정할 수 있게 하므로 유연한 구조입니다.
def get_access_token(self, code):
payload = {
"code": code,
"client_id": self.client_id,
"client_secret": self.client_secret,
"redirect_uri": self.redirect_uri,
"grant_type": "authorization_code",
}
response = requests.post(self.TOKEN_URI, data=payload)
if not response.ok:
raise ValidationError(f"구글 토큰 발급 실패: {response.text}")
# [리뷰 10] 예외 처리
# 구글 측 에러 메시지(response.text)를 포함하여 예외를 발생시키는 것은 디버깅에 큰 도움이 됩니다.
return response.json().get("access_token")Model
class SocialAccount(models.Model):
provider = models.CharField(max_length=20, default="google")
social_id = models.CharField(max_length=255)
user = models.ForeignKey(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
related_name="social_accounts",
)
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = "social_accounts"
unique_together = ("provider", "social_id")
# [리뷰 11] 데이터 무결성
# (provider, social_id) 쌍을 유니크하게 설정한 것은 매우 중요합니다.
# 동일한 소셜 계정이 중복 저장되는 것을 DB 레벨에서 막아줍니다.디스코드
요약
| 단계 | 파일 경로 | 작업 내용 |
|---|---|---|
| 1. 서비스 | user/services/discord_service.py | 디스코드 토큰 발급 및 유저 정보 조회 로직 구현 |
| 2. 뷰 | user/views/social_login_view.py | DiscordLoginView 추가 (콜백 처리 및 회원가입/로그인) |
| 3. URL | user/urls.py | 디스코드 로그인 콜백 URL 연결 |
| 4. 설정 | settings.py / .env | 디스코드 Client ID, Secret, Redirect URI 등록 |
테스트
import urllib.parse
# 1. 디스코드 개발자 포털의 CLIENT ID
client_id = "~"
# 2. 백엔드 코드와 '완벽히' 일치해야 하는 리다이렉트 주소
redirect_uri = "http://localhost:8000/api/v1/user/discord/login"
# 3. 디스코드 스코프 (구글의 'profile email'과 다름)
# identify: 유저 아이디/닉네임 등 기본 정보
# email: 이메일 정보
scope = "identify email"
# 4. URL 인코딩 (주소에 들어가는 특수문자 변환)
# 구글은 대충 넣어도 받아주지만, 디스코드는 인코딩 안 하면 에러 날 때가 많습니다.
encoded_redirect_uri = urllib.parse.quote(redirect_uri)
# 5. 최종 URL 생성
url = f"https://discord.com/api/oauth2/authorize?client_id={client_id}&redirect_uri={encoded_redirect_uri}&response_type=code&scope={scope}"
print("-" * 20)
print("아래 주소를 복사해서 브라우저에 붙여넣으세요:")
print(url)
print("-" * 20)import urllib.parse
client_id = "~"
redirect_uri = "http://localhost:8000/api/v1/user/discord/login"
# [핵심] 여기에 'email'이 꼭 있어야 합니다!
scope = "identify email"
encoded_redirect_uri = urllib.parse.quote(redirect_uri)
url = f"https://discord.com/api/oauth2/authorize?client_id={client_id}&redirect_uri={encoded_redirect_uri}&response_type=code&scope={scope}"
print(url)프론트 예시
// 현재 페이지의 URL 쿼리 파라미터를 가져옵니다.
const urlParams = new URLSearchParams(window.location.search);
// URL에서 'token' 값을 추출합니다.
const accessToken = urlParams.get('token');
if (accessToken) {
// 1. 토큰을 브라우저 로컬 스토리지에 저장합니다 (나중에 API 요청할 때 쓰려고)
localStorage.setItem('access_token', accessToken);
// 2. 토큰이 잘 저장되었는지 콘솔에 찍어봅니다.
console.log("로그인 성공! 토큰 저장 완료:", accessToken);
// 3. 메인 페이지나 대시보드로 이동합니다.
window.location.href = '/';
} else {
// 토큰이 없다면 에러 처리를 합니다.
console.error("토큰이 없습니다. 로그인 실패");
}닉네임 생성 로직
# user/views/social_login_view.py
temp_nickname = f"s_{str(uuid4())[:8]}"
# 분석:
# "s_" (2글자) + UUID 앞 8글자 = 총 10글자
# User 모델의 nickname max_length=10 제한을 정확히 준수합니다.
# 충돌 확률은 매우 낮지만, 0은 아니므로(약 43억 분의 1 수준) 서비스 규모가 커지면 재시도 로직이 필요할 수 있습니다.공통함수 분리 예정
def social_user_login(provider, social_id, email, nickname_prefix="s"):
"""
소셜 유저 로그인/회원가입 공통 로직
"""
with transaction.atomic():
# 1. 소셜 계정 찾기
social_account = SocialAccount.objects.filter(
provider=provider, social_id=social_id
).first()
if social_account:
user = social_account.user
else:
# 2. 이메일 연동 또는 신규 가입
user = User.objects.filter(email=email).first()
if not user:
temp_nickname = f"{nickname_prefix}_{str(uuid4())[:8]}"
user = User.objects.create_user(
email=email, password=None, nickname=temp_nickname
)
SocialAccount.objects.create(
user=user, provider=provider, social_id=social_id
)
return user2026.02.08 ✅
2026.02.09 ✅

안녕하세요.