
[2026.01.12] IsAuthenticated / 권한 / EMS / 인증
[2026.01.13] read_only_fields / 핸들러 동작 원리
[2026.01.14] 에러메세지 분리 / fields
[2026.01.15] Django ORM에서 빈번하게 사용되는 메서드 / 수정 메서드
[2026.01.16] DRY원칙 / 테스트코드 / delete이론(soft/hard)
2026.01.12 ✅
데코레이터 vs with
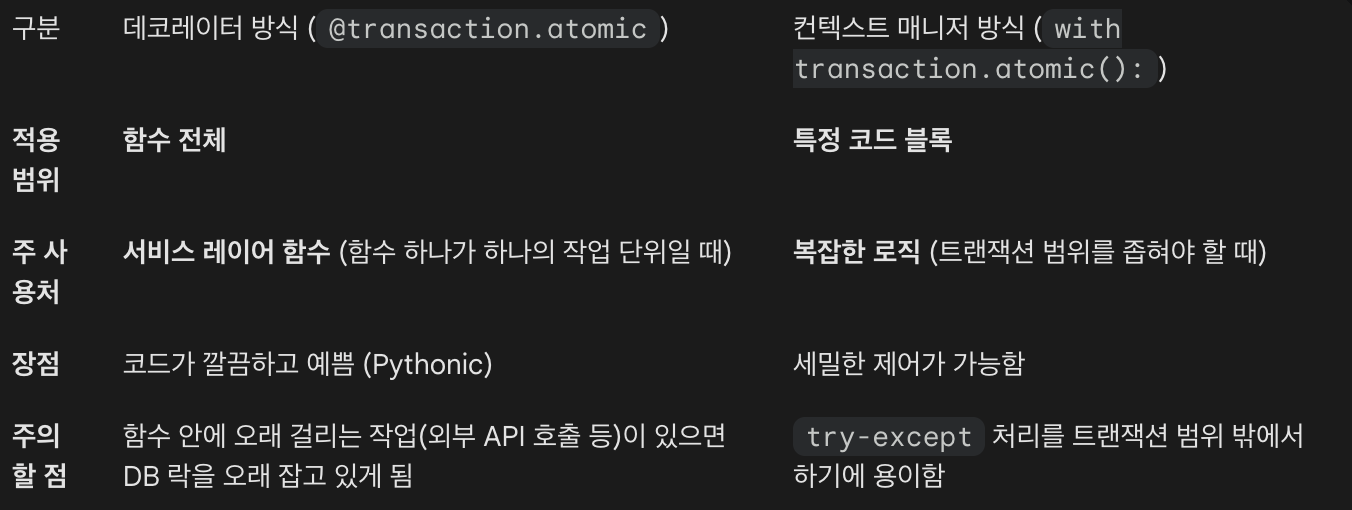
- @transaction.atomic
- 함수 실행 시점에 트랜잭션을 시작
- 함수가 정상적으로 return하면 Commit, 중간에 예외(Error)가 발생하면 Rollback
권한
IsAuthenticated
permission_classes = [IsAuthenticated]- 로그인된 사용자(인증 성공)만 접근할 수 있고, 비로그인 사용자(익명)는 차단한다
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.IsAuthenticated',
],
# 기타 DRF 설정...
}
# views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAuthenticated
class View(APIView):
# 1. 클래스 전역 설정: 이 View의 모든 메서드에 대해 인증을 요구함
permission_classes = [IsAuthenticated]
def get(self, request):
...
def post(self, request):
...메서드마다 권한을 다르게 주고 싶다면
- permission_classes변수 대신 get_permissions 메서드를 오버라이딩(재정의)해서 사용
인증과 권한 부여를 구현
인증 클래스 구성하기
TokenAuthentication은 클라이언트가 토큰을 사용하여 인증하는 데 사용되고,SessionAuthentication은 전통적인 세션 기반 인증을 가능하게 합니다.
# settings.py
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [
'rest_framework.authentication.TokenAuthentication',
'rest_framework.authentication.SessionAuthentication',
],
...
}EMS / Exception 고민
Exception
- DRF는 설계상 Global Exception Handling (전역 예외 처리) 메커니즘을 강력하게 지원
- 비즈니스 로직(View/Serializer)은 "무엇이 잘못되었는지(Exception)"만 알리고,
- "어떻게 응답할지(HTTP Status, JSON Format)"는 예외 처리기(exception_handler)가 담당
DRF의 내장 인증 클래스
SessionAuthentication- Django의 세션 프레임워크를 사용하여 인증합니다.
- 이것은 API가 일반적인 웹 클라이언트에서 사용될 때 유용합니다.
BasicAuthentication- HTTP 기본 인증(Basic Authentication)을 사용합니다.
- 이는 HTTP 프로토콜에 내장된 간단한 인증 방식입니다.
TokenAuthentication- 토큰 기반 시스템을 사용하여 인증합니다.
- 사용자가 인증되면 토큰이 부여되며, 이 토큰은 이후의 요청의 헤더에 포함됩니다.
# 인증 클래스를 사용하려면 DRF 설정의 AUTHENTICATION_CLASSES에 추가해야 함
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication',
'rest_framework.authentication.TokenAuthentication',
],
# 기타 DRF 설정...
}내장 권한 클래스
IsAuthenticated- 인증된 사용자만 접근을 허용합니다.
IsAdminUser- 관리자 사용자만 접근을 허용합니다.
IsAuthenticatedOrReadOnly- 인증되지 않은 사용자에게는 읽기 전용 접근을 허용하고, 인증된 사용자에게는 전체 접근을 허용합니다.
REST_FRAMEWORK = {
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.IsAuthenticated',
],
# 기타 DRF 설정...
}사용자 정의 인증 / 권한 부여 체계
- 사용자 정의 인증(Authentication) 클래스를 생성
rest_framework.authentication.BaseAuthentication를 상속하고.authenticate(self, request)메서드를 구현해야 합니다.
- 사용자 정의 권한(Permission) 클래스를 생성
rest_framework.permissions.BasePermission를 상속하고.has_permission(self, request, view)및/- 또는
.has_object_permission(self, request, view, obj)메서드를 구현해야 합니다.
2026.01.13 ✅
read_only_fields
Serializer
- "조회할 때는 보여주되, 수정은 못 하게 막고 싶을 때" 사용함
- Serializer를 통해 데이터를 응답(Response)으로 내려줄 때 유용
- 지금 리뷰등록 api는 review 객체 전체를 다시 JSON으로 변환해서 내려주는 게 아니기 때문에
- read_only_fields를 설정해서 ID나 작성일 같은 정보를 보여줄 필요가 없는 상황
등록 api
- user와 game은 서버가 인증 정보(request.user)와 URL 파라미터(game_id)로 직접 할당
- 이 필드들은 클라이언트가 body에 담아 보내는게 아님
- view_count, like_count, is_deleted
- 기본값이 선언되어 있기 때문에 자동으로 들어감 시리얼라이저에 추가하지 않아서 데이터 조작을 막음
- user와 game은 서버가 인증 정보(request.user)와 URL 파라미터(game_id)로 직접 할당
핸들러 동작 원리
- 역할: DRF의 기본 예외 처리를 감싸서, 에러 응답 포맷을 통일
- 400 ValidationError 처리 로직
- 예외가 발생하면 custom_exception_handler가 호출
- ValidationError인 경우, View(GameReviewView)에 정의된
- validation_error_message 속성 값을 가져와 error_detail 필드에 넣음
- 상세 에러 내용(딕셔너리)은 errors 필드에 담김
- 예외가 발생하면 custom_exception_handler가 호출
- 401 Unauthorized (인증 실패)
- DRF가 던지는 NotAuthenticated나 AuthenticationFailed 예외를 잡아서
- 무조건 지정된 메시지를 내보냄
- 최종 응답:
"error_detail": "로그인이 필요한 서비스입니다."
- DRF가 던지는 NotAuthenticated나 AuthenticationFailed 예외를 잡아서
- 403 Forbidden (권한 없음) & 404 Not Found
- apps/community/exceptions/review_exceptions.py에 정의한 커스텀예외 발생 시
- 핸들러 로직에서
- detail 키를 error_detail로 변경
- 예외 클래스에 default_code가 있으면 code 필드 추가
- 핸들러 로직에서
- apps/community/exceptions/review_exceptions.py에 정의한 커스텀예외 발생 시
- 400 ValidationError 처리 로직
{
"error_detail": "작성자가 일치하지 않습니다.",
"code": "not_review_author"
}- 404 Not Found (데이터 없음)
- get_object_or_404 실패 또는 존재하지 않는 URL 접근
"error_detail": "찾을 수 없습니다."
get_user_model()
- 현재 프로젝트에서 사용 중인 유저 모델 클래스"를 동적으로 가져오는 함수
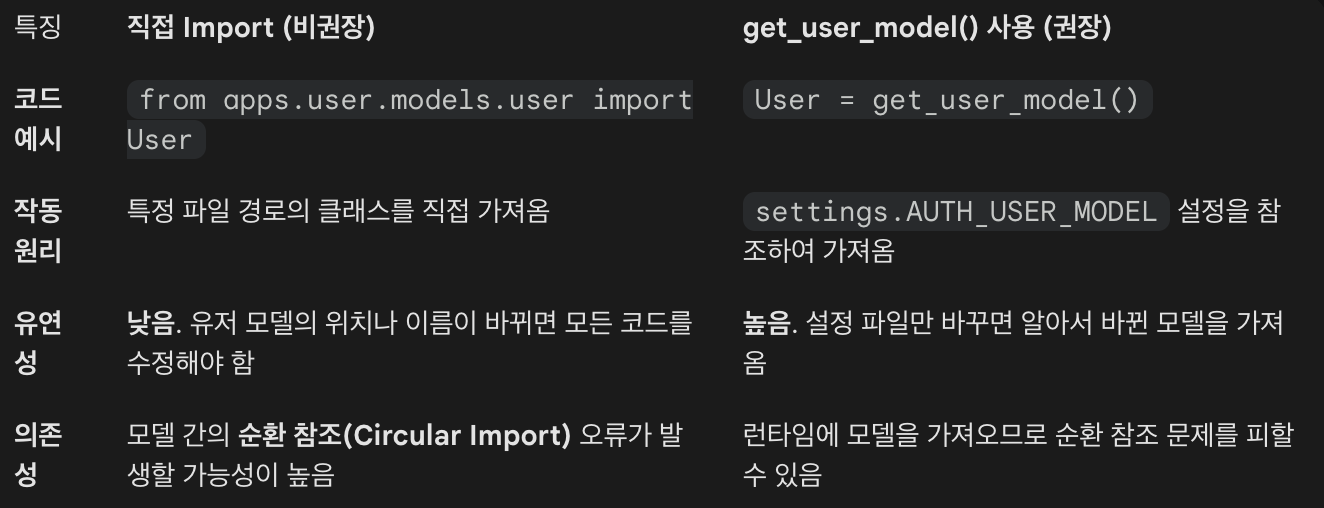
AbstractBaseUser
- 보안 기능 자동 적용
- 비밀번호 암호화(set_password), 검증(check_password) 메서드를 무료로 제공
- 직접 구현할 필요 X
- 호환성
- DRF의 IsAuthenticated, Django Admin, 로그인 기능 등이 아무런 설정 없이 즉시 작동
- 표준 준수
- 개발자가 바뀌어도 "아, 표준 장고 유저 모델이네" 하고 바로 이해 가능
- 비밀번호 암호화(set_password), 검증(check_password) 메서드를 무료로 제공
2026.01.14 ✅
권한 분리
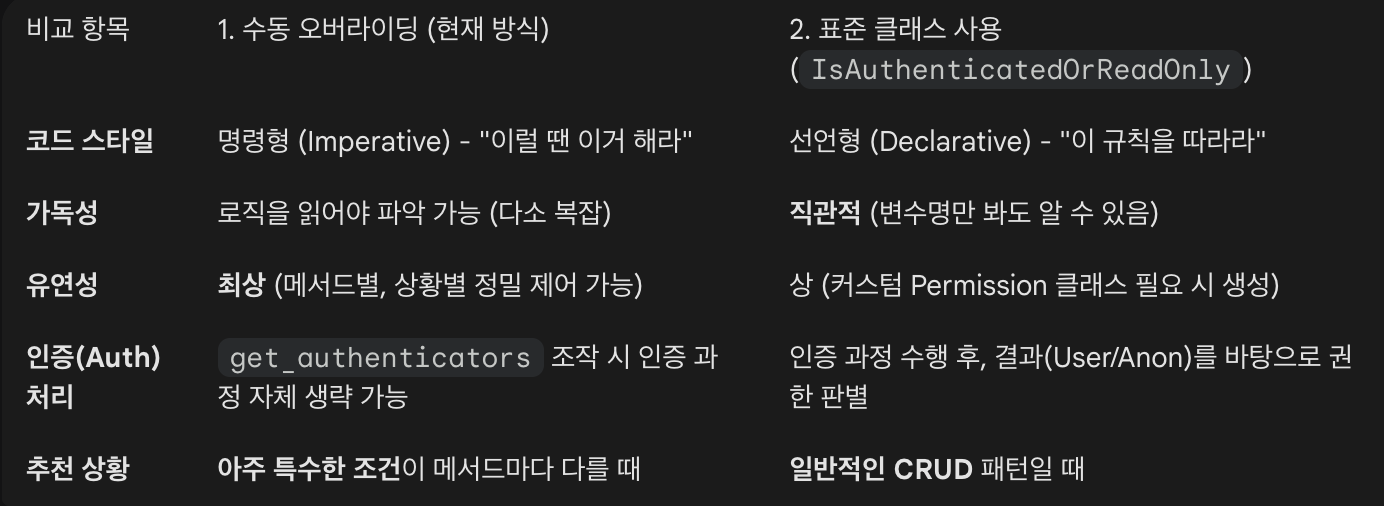

메서드 오버라이딩
이전 프로젝트에서 사용한 방식
- 메서드 오버라이딩(Method Overriding) 방식
- 장점: 제어권이 확실
- 하지만 DRF가 이미 제공하는 표준 권한 클래스 사용이 더 권장됨
- 메서드 오버라이딩(Method Overriding) 방식
class QuestionAPIView(APIView):
def get_authenticators(self) -> list[BaseAuthentication]:
request = getattr(self, "request", None)
if request and request.method == "GET":
return []
return super().get_authenticators()
def get_permissions(self) -> list[BasePermission]:
if self.request.method == "POST":
return [QuestionCreatePermission()]
return []IsAuthenticatedOrReadOnly
- "조회는 누구나, 등록은 회원만"을 구현하는데에 DRF가 제공하는 기본 클래스
- 이전 코드에서는 GET 요청이라도 "토큰을 보냈는데 그게 가짜라도" 비회원으로 쳐서 조회했지만
- 지금 코드는 GET 요청이라도 "토큰을 보냈는데 그게 가짜라면" 401에러를 뱉음
permission_classes = [IsAuthenticatedOrReadOnly]
- GET, HEAD, OPTIONS (Safe Methods) 요청은 누구나 허용
- POST, PUT, DELETE 등은 인증된 사용자만 허용에러메세지 분리
get / post
- 각각 400에러메세지 다르게 주기
class ReviewAPIView(APIView):
permission_classes = [IsAuthenticatedOrReadOnly]
validation_error_message = "이 필드는 필수 항목입니다."
def get(self, request, game_id):
self.validation_error_message = "유효하지 않은 조회 요청입니다."
# 1. 서비스 레이어를 통해 QuerySet 가져오기
queryset = get_review_list(game_id=game_id)
# 2. 페이지네이션 객체 생성(APIView는 수동 호출 필요)
paginator = ReviewPageNumberPagination()
# 3. 쿼리셋을 현재 페이지에 맞게 자르기
page = paginator.paginate_queryset(queryset, request, view=self)
# 4. 직렬화 (Serializer)
if page is not None:
serializer = ReviewListSerializer(page, many=True)
# 5. 페이지네이션된 최종 응답 반환
return paginator.get_paginated_response(serializer.data)
# 만약 페이지네이션 설정이 꼬여서 page가 None이면 일반 리스트 반환 (예비책)
serializer = ReviewListSerializer(queryset, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)fields
models.ManyToManyField
- 데이터베이스에서 다대다(Many-to-Many, N:N) 관계를 정의할 때 사용하는 필드
- 하나의 데이터가 여러 개의 데이터와 연결될 수 있고, 그 반대도 가능한 경우에 사용
# ex. 블로그 게시글(Post)과 태그(Tag)의 관계
- 하나의 글은 여러 개의 태그를 가질 수 있다. (예: 'Python', 'Django', 'Coding')
- 반대로, 하나의 태그('Django')는 여러 개의 글에 달릴 수 있다.
# models.py
from django.db import models
class Tag(models.Model):
name = models.CharField(max_length=50)
def __str__(self):
return self.name
class Post(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
# Post 모델 안에 ManyToManyField를 선언합니다.
tags = models.ManyToManyField(Tag)
def __str__(self):
return self.titleManyToManyField
- 중간 테이블(Intermediate Table) 자동 생성
- Post 테이블과 Tag 테이블 외에
- 이 둘을 연결해주는 제3의 테이블(예: appname_post_tags)을 자동으로 만듬
- 편리한 데이터 추가/조회 메서드 제공
- Python 코드 상에서 직관적으로 데이터를 연결하거나 가져올 수 있음
# 1. 새로운 글과 태그 생성
my_post = Post.objects.create(title="Django 공부", content="재밌다")
tag_python = Tag.objects.create(name="Python")
tag_django = Tag.objects.create(name="Django")
# 2. 관계 맺기 (.add)
# my_post 글에 태그들을 추가합니다.
my_post.tags.add(tag_python, tag_django)
# 3. 조회하기 (.all)
# 이 글에 달린 모든 태그 가져오기
my_post.tags.all()
# 결과: <QuerySet [<Tag: Python>, <Tag: Django>]>
# 반대로, 'Python' 태그가 달린 모든 글 가져오기 (역참조)
tag_python.post_set.all()2026.01.15 ✅
Django ORM 핵심 메서드
filter()와 exclude()
- 데이터를 조회할 때 가장 기본이 되는 메서드 / 조건에 맞는 여러 개의 객체(QuerySet)를 가져옴
기능 비교

예시
# 30세 이상이면서, 스태프가 아닌 유저 찾기
users = User.objects.filter(age__gte=30).exclude(is_staff=True)
# ---------------------------------------------------------
# [코드 분석 설명]
# ---------------------------------------------------------
# 1. User.objects.filter(age__gte=30)
# -> age 필드가 30 이상(Greater Than or Equal)인 유저들을 1차로 걸러냅니다.
# -> 결과는 리스트와 유사한 QuerySet 형태로 반환됩니다.
#
# 2. .exclude(is_staff=True)
# -> 앞서 필터링된 결과 중에서, is_staff가 True인(운영자인) 사람을 명단에서 제외합니다.
#
# 3. 체이닝 (Chaining)
# -> 이처럼 메서드를 점(.)으로 계속 연결하여 쿼리를 구체화할 수 있습니다.
# -> 실제 데이터베이스 조회(SQL 실행)는 이 users 변수가 실제로 사용될 때(예: for문) 발생합니다(Lazy Evaluation).bulk_create()
- 대량의 데이터를 한 번에 생성해야 할 때 사용합니다. save()를 여러 번 호출하는 것보다 압도적으로 빠름
특징 요약
- 속도
- 수천 개의 데이터를 1번의 쿼리로 저장
- 주의사항
- save() 메서드가 호출되지 않으므로, pre_save나 post_save 같은 시그널(Signal)이 발생X
- 속도
예시
# 1000개의 로그 데이터를 한 번에 저장하기
log_list = [Log(message=f"Log {i}") for i in range(1000)]
Log.objects.bulk_create(log_list)
# ---------------------------------------------------------
# [코드 분석 설명]
# ---------------------------------------------------------
# 1. log_list = [...]
# -> Log 객체들을 메모리 상에서 생성하여 리스트에 담습니다.
# -> 이때는 아직 DB에 저장되지 않은 상태입니다 (ID 값 없음).
#
# 2. Log.objects.bulk_create(log_list)
# -> 리스트에 있는 모든 객체를 단 한 번의 SQL 쿼리로 DB에 INSERT 합니다.
# -> for문을 돌며 하나씩 .save() 하는 것보다 수십 배 이상 빠릅니다.exists()
- 데이터가 존재하는지 여부만 True/False로 알고 싶을 때 사용합니다.
성능 비교
- if queryset:
- 데이터를 모두 가져와서 파이썬 메모리에 올린 후 확인
- 데이터가 많으면 느림
- if queryset.count():
- 전체 개수를 셈
- 전체를 세야 하므로 불필요한 연산 발생
- if queryset.exists():
- 데이터가 1개라도 있는지 확인하면 즉시 멈춤
- 가장 빠름
- if queryset:
예시
# VIP 회원이 한 명이라도 있는지 확인
if User.objects.filter(is_vip=True).exists():
print("VIP 회원이 존재합니다.")
# ---------------------------------------------------------
# [코드 분석 설명]
# ---------------------------------------------------------
# 1. .filter(is_vip=True)
# -> VIP 회원 조건을 설정하지만, 아직 데이터를 가져오진 않습니다.
#
# 2. .exists()
# -> DB에 "SELECT 1 ... LIMIT 1" 같은 최적화된 쿼리를 날립니다.
# -> 데이터 전체를 가져오지 않고, 조건에 맞는 데이터가 발견되는 즉시 True를 반환하고 종료합니다.
# -> 단순히 존재 여부만 체크할 때는 가장 성능이 좋은 방법입니다.get_or_create
- 데이터베이스에서 특정 조건의 객체를 조회(Get)하고
- 만약 그 객체가 없다면 새로 생성(Create)하는 과정을 한 번에 처리해 주는 메서드
- 중복 데이터 생성을 방지하고 코드를 간결하게 만들기 위함
주요 반환 값 (Return Values)
- 이 메서드는 항상 튜플(Tuple) 형태의 결과값을 반환
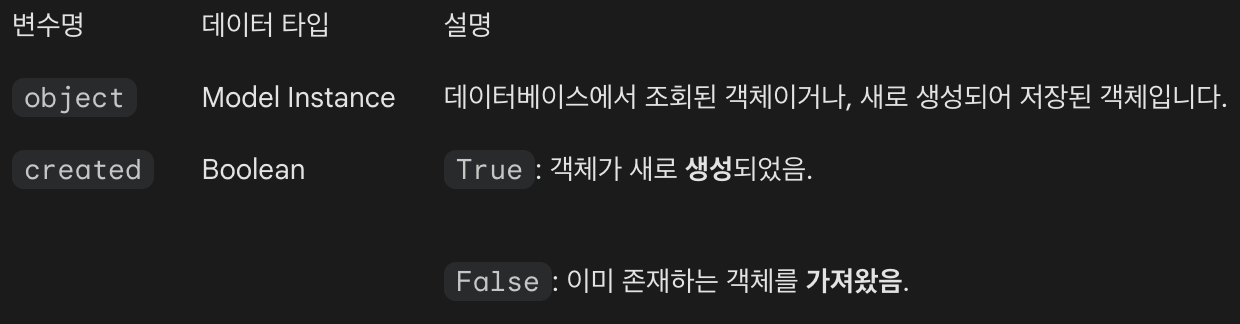
- 이 메서드는 항상 튜플(Tuple) 형태의 결과값을 반환
예시
# Tag 모델을 사용한다고 가정
# name: 태그 이름 (검색 기준)
# slug: URL에 사용될 별칭 (생성 시에만 필요한 추가 정보)
tag_obj, is_new = Tag.objects.get_or_create(
name='Python',
defaults={'slug': 'python-lang'}
)
if is_new:
print("새로운 태그가 등록되었습니다.")
else:
print("기존 태그를 불러왔습니다.")
# ---------------------------------------------------------
# [코드 분석 설명]
# ---------------------------------------------------------
# 1. Tag.objects.get_or_create(...)
# -> DB에서 name이 'Python'인 객체가 있는지 먼저 찾습니다(SELECT).
#
# 2. name='Python' (Lookup Parameter)
# -> 검색의 기준이 되는 필드입니다. 이 조건으로 데이터 존재 여부를 판단합니다.
#
# 3. defaults={'slug': 'python-lang'}
# -> 만약 'Python'이라는 이름의 태그가 '없을 때만' 사용되는 값입니다.
# -> 객체를 새로 생성(INSERT)할 때, name='Python'과 함께 slug='python-lang'으로 저장됩니다.
# -> 이미 객체가 있다면 이 defaults 값은 완전히 무시됩니다.
#
# 4. tag_obj, is_new
# -> tag_obj: 찾아낸 혹은 만든 태그 객체 그 자체입니다.
# -> is_new: DB에 없어서 새로 만들었다면 True, 원래 있었다면 False가 담깁니다.defaults의 역할
- 검색 조건에는 포함되지 않고, 오직 생성될 때만 반영하고 싶은 필드는
- 반드시 defaults 딕셔너리에 넣어야 함
- 만약 defaults 밖에 둔다면 그 필드까지 포함해서 검색 조건으로 사용하게 됨
- 검색 조건에는 포함되지 않고, 오직 생성될 때만 반영하고 싶은 필드는
원자성(Atomicity)
- 기본적으로 트랜잭션 처리가 되지만,
- 데이터베이스 레벨에서의 고유성 제약(Unique Constraint)이 설정되어 있지 않다면,
- 동시 접속 환경에서 아주 드물게 중복 생성 문제가 발생할 수도 있음
- 기본적으로 트랜잭션 처리가 되지만,
update_or_create()
- get_or_create의 확장판
- 객체가 있으면 내용을 수정(Update)하고,
- 없으면 생성(Create), 설정값을 덮어씌워야 할 때 유용함
반환 값 구조

예시
# 사용자 프로필을 업데이트하거나, 없으면 새로 만드는 상황
# user: 식별자 (Lookup)
# bio: 변경할 내용 (Defaults)
profile, created = Profile.objects.update_or_create(
user=request.user,
defaults={'bio': '안녕하세요, 반가워요!', 'is_public': True}
)
# ---------------------------------------------------------
# [코드 분석 설명]
# ---------------------------------------------------------
# 1. Profile.objects.update_or_create(...)
# -> 먼저 user=request.user인 프로필이 있는지 찾습니다.
#
# 2. defaults={'bio': ..., 'is_public': ...}
# -> [객체가 있을 경우]: 찾은 객체의 bio와 is_public 필드를 이 값으로 '수정'하고 저장(save)합니다.
# -> [객체가 없을 경우]: user=request.user와 defaults의 값들을 합쳐서 새 객체를 '생성'합니다.
#
# 3. 차이점 (vs get_or_create)
# -> get_or_create는 객체가 이미 있다면 defaults 값을 무시하고 그대로 가져오지만,
# -> update_or_create는 객체가 이미 있다면 defaults 값으로 내용을 갱신합니다.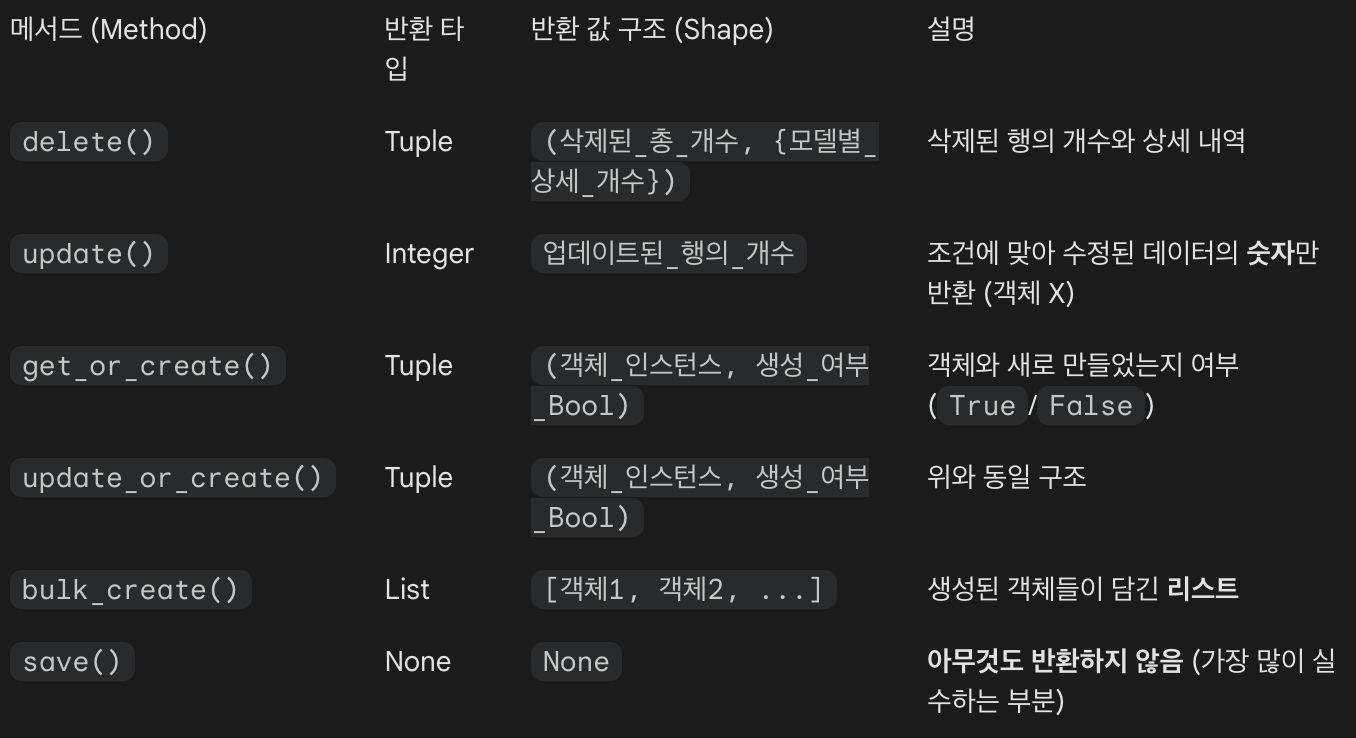
select_for_update
- 데이터베이스의 "행 잠금(Row Lock)" 기능을 사용하는 Django의 메서드
- ex. "좋아요"수가 10개인 게시글에 A와B가 완전히 동일한 시간에 "좋아요"를 누름
- select_for_update 존재X
- A: DB에서 10개를 읽어옴
- B: DB에서 10개를 읽어옴 (A 아직 저장 안함)
- A: 10 + 1 = 11로 저장
- B: 10 + 1 = 11로 저장
- 결과적으로 두명이 "좋아요"를 눌렀지만 결과적으로 1개가 없어짐
- select_for_update 존재
- A: DB에서 10개를 읽으면서 줄(Row) 잠금 (select_for_update)
- B: DB를 읽으려는데 잠겨 있음, A가 끝날 때까지 대기(Wait)함
- A: 10 + 1 = 11로 저장하고 트랜잭션 종료
- B: (이제 잠금 풀림) 방금 갱신된 11개를 읽어옴
- B: 11 + 1 = 12로 저장
- select_for_update 존재X
동작 시점
- get()이나 filter()를 호출하는 순간이 아니라
- 데이터베이스가 해당 쿼리를 실행할 때 해당 데이터 행(Row)에 Lock을 검
해제 시점
- 이 코드가 포함된 transaction이 끝날 때(commit 혹은 rollback) 자동으로 풀림
- 그래서 반드시 @transaction.atomic 블록 안에서 사용해야 함
- 트랜잭션 밖에서 쓰면 효과가 없거나 에러가 발생함
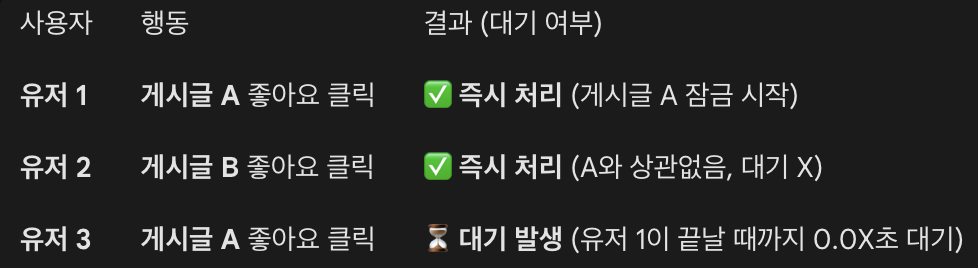
- "대기"로 표현하기는 했지만 실제로 찰나의 순간에 처리가 되기 때문에 사용자는 멈춤을 느끼지 못함
- 동시성 제어(Concurrency Control)를 위해 사용함
- select_for_update 없이 데이터를 조회하고 수정하면
- "경쟁 상태(Race Condition)"가 발생 가능
- select_for_update 없이 데이터를 조회하고 수정하면
select_for_update 기능 사용 X
- 원래는 12가 되어야 하지만 서로의 작업을 모른 채 덮어쓰게되어 11이 되어버림

- 원래는 12가 되어야 하지만 서로의 작업을 모른 채 덮어쓰게되어 11이 되어버림
select_for_update 기능 사용

.save(update_fields)
- Django의
save()는 기본적으로 모든 필드를 UPDATE- update_fields를 지정하면 딱 필요한 컬럼만 건드림
- ex.
review.save(update_fields=["like_count"])
수정
put / patch
- PUT은 전체 수정, PATCH는 부분 수정이라는 의미(Semantics)를 가지지만
- Django REST Framework(DRF)에서는
- 이 차이를 주로 Serializer의 유효성 검사(Validation) 단계에서 구분함
PUT 요청의 핵심
- 리소스를 대체한다(전체 필드를 보낸다)
- 이를 강제하는 것은 Serializer
serializer = ReviewUpdateSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
- PUT 요청을 처리할 때는 partial=True 옵션을 주지 않기 때문에,
- 클라이언트가 content나 rating 중 하나라도 빼먹으면 에러가 발생partial=True
- 아래와 같이 수정하면 put도 patch처럼 부분수정 가능
- RESTful API 설계 원칙상 추천하는 방식은 아님
serializer = ReviewUpdateSerializer(
data=request.data,
partial=True
)
serializer.is_valid(raise_exception=True)2026.01.16 ✅
DRY 원칙
- 'Don't Repeat Yourself'
- 로직이 동일한 코드는 하나로 관리하는 것이 유지보수에 유리
partial=True
- 생성(Create) 시에는 모든 필수 필드가 필요하지만
- 수정(Update/Patch) 시에는 일부 필드만 들어올 수 있음
partial=True를 넣어주었기 때문에,- 생성 전용 시리얼라이저를 사용하더라도 필수 필드 누락 에러가 발생하지 않고 부분 수정이 가능
def patch(self, request, review_id):
serializer = ReviewCreateSerializer(data=request.data, partial=True)
serializer.is_valid(raise_exception=True)extend_schema 주요 파라미터

테스트코드
- Given When Then 을 사용하여 분리하기
- 테스트 코드를 명확하고 읽기 쉽게 작성하기 위한 구조적 접근 방식
Given
- 준비 (주어진 상황)
- 테스트를 실행하기 위해 필요한 전제 조건이나 데이터를 설정하는 단계
- 예: 사용자 생성, 게임 데이터 생성, 입력 데이터 준비
When
- 실행 (언제)
- 실제로 테스트하고자 하는 기능(함수, API)을 실행하는 단계
Then
- 검증 (그러면)
- 실행 결과가 기대하는 결과와 일치하는지 확인(Assert)하는 단계
- 예: 반환값이 맞는지, DB에 저장되었는지 확인
Django delete
이론
- APIView의 DELETE 메서드는 서버에서 기존 리소스를 제거하는 데 사용됨
- 일반적으로 삭제할 항목을 식별하기 위해 리소스 ID가 필요
- DELETE 요청이 성공적으로 완료되면
- 일반적으로 응답 본문 없이 삭제가 성공했음을 나타내는 204 No Content 응답이 반환
serializer
요청(Request) 처리 시
- DELETE 요청은 보통 URL 경로(Path Parameter)에 포함된 id(PK)만으로
- 어떤 데이터를 삭제할지 식별함 (예: DELETE /reviews/10)
- 따라서 request.data(Body)를 받아 검증할 필요가 없으므로
- 요청용 시리얼라이저는 만들지 않는 것이 일반적
- DELETE 요청은 보통 URL 경로(Path Parameter)에 포함된 id(PK)만으로
응답(Response) 처리 시
- 내용 없음 (204 No Content)
- 삭제가 성공했다는 사실만 중요하므로 본문(Body)에 아무것도 담지 않음
- 시리얼라이저 필요 없음
- return Response(status=status.HTTP_204_NO_CONTENT)
- 삭제된 객체 정보 반환 (200 OK)
- 삭제된 객체의 정보를 마지막으로 보여줘야 한다면 시리얼라이저가 필요
- class Meta의 fields에는 클라이언트가 확인해야 할 최소한의 정보만 넣음
- FK 미포함 / 보안상 민감한 정보는 오히려 제거

논리적 삭제(Soft Delete)
- 사용자 입장에서는 삭제가 맞지만, 데이터베이스 입장에서는 수정(Update)
- 폴더(목록)에서는 사라져서 안 보임 (사용자는 삭제됐다고 느낌)
- 하지만 하드디스크에는 파일이 남아 있어서 언제든 복구할 수 있음
물리적 삭제(Hard Delete)
- 휴지통 비우기를 하거나 Shift + Delete를 누른 상태
- 데이터가 실제로 사라져서 복구할 수 없음
2026.01.18 ✅
exception
import logging
from typing import Any, Optional
from rest_framework import status
from rest_framework.exceptions import (
ValidationError,
NotAuthenticated,
AuthenticationFailed,
)
from rest_framework.response import Response
from rest_framework.views import exception_handler
logger = logging.getLogger("django")
def custom_exception_handler(
exc: Exception, context: dict[str, Any]
) -> Optional[Response]:
# 1. 핸들러 호출
response = exception_handler(exc, context)
# 2. 시스템 에러 (500)
if response is None:
logger.error(f"[System Error] {exc}", exc_info=True)
return Response(
{"error_detail": "서버 내부 오류가 발생했습니다.", "code": "server_error"},
status=status.HTTP_500_INTERNAL_SERVER_ERROR,
)
# 3. 에러 메시지 포맷 통일 (Detail -> Error Detail)
# 유효성 검사 실패 (400)
if isinstance(exc, ValidationError):
view = context.get("view")
# 뷰에 설정된 메시지 or 기본 메시지 가져오기
message = getattr(
view, "validation_error_message", "유효하지 않은 데이터입니다."
)
response.data = {"error_detail": message, "errors": response.data}
# 4. 그 외 에러 처리 (데이터가 딕셔너리인 경우)
if isinstance(response.data, dict):
# 401 인증 에러 (로그인 안 함)
if isinstance(exc, (NotAuthenticated, AuthenticationFailed)):
response.data = {"error_detail": "로그인이 필요한 서비스입니다."}
# 그 외 모든 에러 (403, 404, 409 등)
else:
# 'detail' 키가 있으면 'error_detail'로 이름표 바꿔달기
if "detail" in response.data:
response.data = {"error_detail": str(response.data["detail"])}
# 커스텀 예외에 code가 있다면 추가
if hasattr(exc, "default_code"):
response.data["code"] = exc.default_code
return response
app별 사용
from rest_framework.exceptions import APIException
from rest_framework import status
class AIServiceUnavailable(APIException):
status_code = status.HTTP_503_SERVICE_UNAVAILABLE
default_detail = "AI 서비스 연결 상태가 좋지 않습니다. 잠시 후 다시 시도해주세요."
default_code = "ai_service_unavailable"
# 사용 예시
if hasattr(exc, "default_code"):
response.data["code"] = exc.default_code
# [분석] AIServiceUnavailable 클래스에 default_code = "ai_service_unavailable"이 정의되어 있습니다.
# 따라서 response.data 딕셔너리에 'code' 키와 값이 추가됩니다.
# 최종 상태:
# {
# "error_detail": "AI 서비스 연결 상태가 좋지 않습니다. 잠시 후 다시 시도해주세요.",
# "code": "ai_service_unavailable"
# }
# 결과
{
"error_detail": "AI 서비스 연결 상태가 좋지 않습니다. 잠시 후 다시 시도해주세요.",
"code": "ai_service_unavailable"
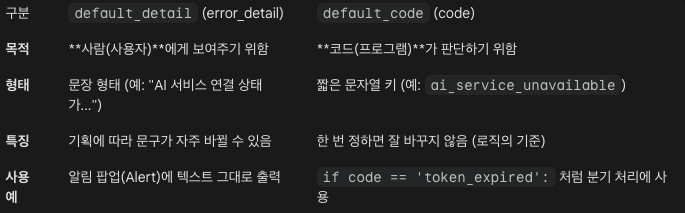
}default_code
- 유지보수성과 안정성을 위해 메시지와 별도로 변하지 않는 code를 함께 내려주는 것
# bad example
- 만약 백엔드 개발자가 메시지 띄어쓰기 하나만 바꿔도 이 코드는 고장
if (error.message === "AI 서비스 연결 상태가 좋지 않습니다. 잠시 후 다시 시도해주세요.") {
showRetryButton(); // '다시 시도' 버튼 노출
}
# good example
- 메시지(default_detail)가 바뀌어도 이 코드는 안전하게 작동
if (error.code === "ai_service_unavailable") {
showRetryButton(); // '다시 시도' 버튼 노출
}

안녕하세요.