2026/03/01 ~
2026/03/01
2609
최대공약수(GCD)와 최소공배수(LCM)
유클리드 호재법
- 두 수 a, b의 최대공약수는 b와 a%b (a를 b로 나눈 나머지)의 최대공약수와 같다는 원리
- 즉, 두 수 a, b의 곱은 두 수의 최대공약수와 최소공배수의 곱과 같다.
- a X B = GCD X LCM
import sys
N, M = map(int, sys.stdin.readline().split())
a, b = N, M
# 최대 공약수 계산
while b != 0:
a, b = b, a % b
GCD = a
LCM = (N * M) // GCD
print(GCD)
print(LCM)2026/03/02
11050
- 입력: 5 2 / 출력: 10
이해
- 5명의 친구() 중에서 대표 2명을 뽑는 상황
- 첫 번째 사람을 뽑는 경우의 수: 5명 중 아무나 한 명 (A, B, C, D, E 중 1명) -> 5가지
- 두 번째 사람을 뽑는 경우의 수: 남은 4명 중 한 명 -> 4가지
- 단순하게 곱하면 20이 됨 하지만, A를 먼저뽑고 B를 뽑는것과 그 반대의 결과는 동일한(A,B)
- 즉, 순서가 상관없음 -> 20/2 -> 10
- 5명의 친구() 중에서 대표 2명을 뽑는 상황
수식으로 계산하기 (팩토리얼 공식)
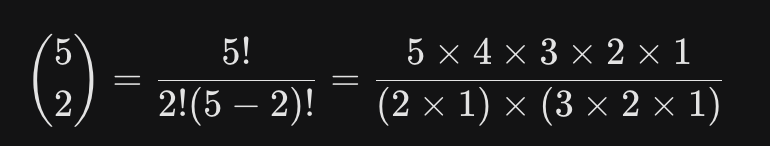
import sys
def factorial(n):
ans = 1
for i in range(2, n + 1):
ans *= i
return ans
n, k = map(int, sys.stdin.readline().split())
# 공식 적용: n! / (k! * (n-k)!)
result = factorial(n) // (factorial(k) * factorial(n - k))
print(result)DP(파스칼의 삼각형)로 이해하기
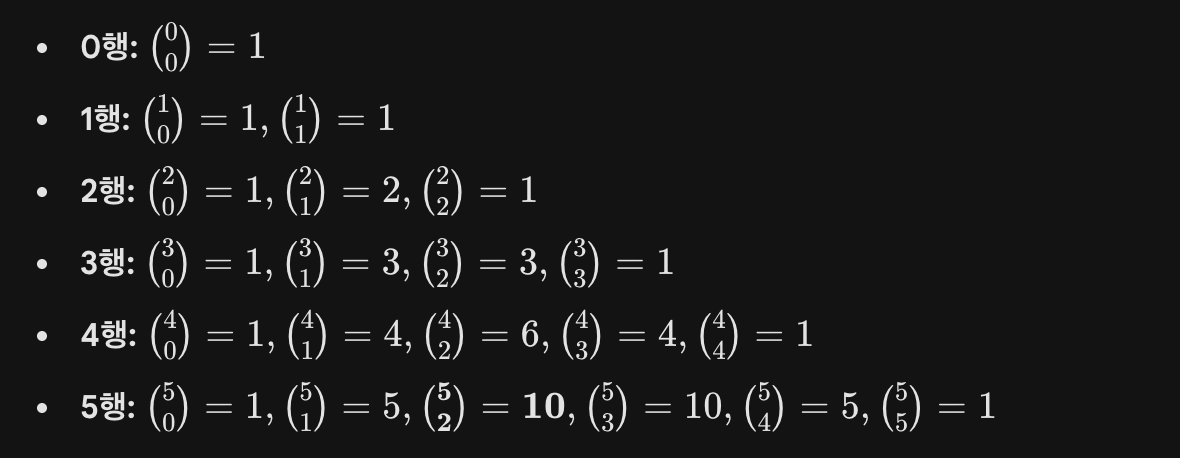
2026/03/03
30802

# 입력
23
3 1 4 1 5 9
5 7
# 출력
7
3 2
# 이해
펜을 7개씩 3묶음을 주무하고나면 2명의 인원은 펜을 받지 못하기 때문에 2명은 따로 1개씩 주문한다.시간 초과
- 반복문 기반의 뺄셈을 적용하여 느렸음
- 만약 특정 사이즈의 신청자 수가 10억 명이고, 묶음 단위 T가 1이라면
- while 루프는 한 사이즈당 10억 번을 돌아야 함
- 반복문 기반의 뺄셈을 적용하여 느렸음
N = int(input())
# S,M,L,XL,XXL,XXXL
M = list(map(int,input().split()))
T,P = map(int,input().split())
num1 = 0
for i in M:
while True:
if i > 0:
num1 += 1
i -= T
else:
break
print(num1)
print(f"{int(N/P)} {int(N%P)}")해결
import sys
N = int(sys.stdin.readline())
# S,M,L,XL,XXL,XXXL
M = list(map(int, sys.stdin.readline().split()))
T,P = map(int, sys.stdin.readline().split())
num1 = 0
for i in M:
if i == 0:
continue
num1 += (i // T)
if i % T > 0:
num1 += 1
print(num1)
print(f"{int(N//P)} {int(N%P)}")2026/03/04
10989
메모리 초과
- 리스트에 요소를 append() 할 때마다 메모리가 동적으로 할당
- 파이썬의 정수(int) 객체 하나는 보통 28바이트의 메모리를 차지
- 1000만 개의 정수를 리스트에 모두 저장한다면 최소 80MB 이상의 메모리가 필요
- 문제의 메모리 제한인 8MB를 아득히 초과하게 되어, 정렬을 시작하기도 전에 MemoryError
- 리스트에 요소를 append() 할 때마다 메모리가 동적으로 할당
N = int(input())
num_li = []
for i in range(N):
A = int(input())
num_li.append(A)
num_li.sort()
for j in num_li:
print(j)해결
import sys
# 데이터의 최댓값이 10000이므로, 10001개의 칸을 가진 리스트를 0으로 초기화(메모리차지 최소화)
count = [0] * 10001
# 빠른 입력을 위해 sys.stdin.readline 사용
N = int(sys.stdin.readline())
for _ in range(N):
# 입력받은 숫자를 리스트에 저장하지 않고, 해당 인덱스의 카운트만 1 증가시킴
num = int(sys.stdin.readline())
count[num] += 1
# 결과 출력
for i in range(10001):
# count[i]에 기록된 횟수만큼 인덱스 i를 반복 출력
if count[i] != 0:
for _ in range(count[i]):
print(i)2026/03/05
4949(스택문제)
-
요구사항
소괄호 ()와대괄호 []가 올바르게 짝을 지어야 함- 마지막에 열린 괄호가 가장 먼저 닫혀야 함
- 영문 알파벳이나 공백 등 괄호가 아닌 문자는 무시
-
예시 해석
So when I die (the [first] I will see in (heaven) is a score list).- 괄호 순서:
(, [, ], ), (, ), ) - 진행:
( 열림➔[ 열림➔]가 가장 최근에 열린 [를 닫음➔)가 (를 닫음➔( 열림➔)가 (를 닫음➔마지막 )가 맨 처음 열린 (를 닫음. - 결과: 모든 짝이 완벽히 맞으므로 yes
- 괄호 순서:
-
중요 로직
line = "A ( )"char = 'A''A'는"()[]"안에 없으므로 무시 (아무 일도 안 일어남)
char = ' ' (공백)공백은"()[]"안에 없으므로 무시
char = '(''('는"()[]"안에 있으므로 통과! ➔ brackets에 추가- 현재 brackets =
"("
char = ' ' (공백)- 무시
char = ')'')'는"()[]"안에 있으므로 통과! ➔ brackets에 추가- 최종 brackets =
"()"
if char in "()[]"- 방금 가져온 글자(char)가
(,),[,]네 개의 문자 중 하나인지 검사
- 방금 가져온 글자(char)가
brackets = "" # 1. 빈 바구니 준비
for char in line: # 2. 문자열에서 글자를 하나씩 꺼냄
if char in "()[]": # 3. 꺼낸 글자가 괄호인지 검사
brackets += char # 4. 괄호가 맞다면 바구니에 추가해결
import sys
while True:
N = sys.stdin.readline().rstrip()
if N == ".":
break
# 알파벳과 공백을 모두 제거하고 괄호만 남김
result = ""
for char in N:
if char in "()[]":
result += char
# "()" 나 "[]" 가 문자열 안에 존재하는 동안 계속 지워나감
while "()" in result or "[]" in result:
result = result.replace("()", "")
result = result.replace("[]", "")
# 다 지웠는데 괄호가 남아있으면 짝이 안 맞는 것
if len(result) == 0:
print("yes")
else:
print("no")출력 예시
# 맞는 경우
import sys
while True:
line = sys.stdin.readline().rstrip()
# 현재 line = "[ first in ] ( first out )."
if line == ".":
break
# 알파벳과 공백을 모두 제거하고 괄호만 남김
brackets = ""
for char in line:
if char in "()[]":
brackets += char
# [for문 종료 후 결과]
# 괄호만 순서대로 추출되었으므로, brackets = "[]()" 가 됩니다.
# "()" 나 "[]" 가 문자열 안에 존재하는 동안 계속 지워나감
while "()" in brackets or "[]" in brackets:
# [while문 1번째 반복 시작] 현재 brackets = "[]()"
brackets = brackets.replace("()", "")
# "()"가 지워짐 -> brackets = "[]"
brackets = brackets.replace("[]", "")
# "[]"가 지워짐 -> brackets = "" (빈 문자열)
# [while문 2번째 반복 조건 검사]
# brackets가 "" 이므로 "()", "[]" 둘 다 없습니다. -> while문 종료!
# 다 지웠는데 괄호가 남아있으면 짝이 안 맞는 것
if len(brackets) == 0:
# 현재 len(brackets)는 0입니다. (빈 문자열이므로)
print("yes") # 결과: "yes" 출력!
else:
print("no")
# 틀린 경우
import sys
while True:
line = sys.stdin.readline().rstrip()
# 현재 line = "Help( I[m being held prisoner in a fortune cookie factory)]."
if line == ".":
break
# 알파벳과 공백을 모두 제거하고 괄호만 남김
brackets = ""
for char in line:
if char in "()[]":
brackets += char
# [for문 종료 후 결과]
# 괄호만 순서대로 추출되었으므로, brackets = "([)]" 가 됩니다.
# "()" 나 "[]" 가 문자열 안에 존재하는 동안 계속 지워나감
while "()" in brackets or "[]" in brackets:
# [while문 조건 검사] 현재 brackets = "([)]"
# 문자열 안에 완전히 붙어있는 "()" 나 "[]" 가 없습니다!
# 따라서 while문 안으로 들어가지 못하고 바로 종료됩니다.
brackets = brackets.replace("()", "")
brackets = brackets.replace("[]", "")
# 다 지웠는데 괄호가 남아있으면 짝이 안 맞는 것
if len(brackets) == 0:
print("yes")
else:
# 현재 len(brackets)는 4입니다. ("([)]"가 그대로 남아있으므로)
print("no") # 결과: "no" 출력!참고(스택 활용)
import sys
while True:
line = sys.stdin.readline().rstrip()
if line == ".": # 마침표만 들어오면 종료
break
stack = []
is_balanced = True
for char in line:
if char == '(' or char == '[': # 여는 괄호는 스택에 추가
stack.append(char)
elif char == ')': # 소괄호 닫기
# 스택이 비어있거나, 짝이 맞지 않으면 불균형
if not stack or stack[-1] != '(':
is_balanced = False
break
stack.pop() # 짝이 맞으면 스택에서 제거
elif char == ']': # 대괄호 닫기
if not stack or stack[-1] != '[':
is_balanced = False
break
stack.pop()
# 문자열을 다 돌았는데 스택에 여는 괄호가 남아있다면 불균형
if is_balanced and not stack:
print("yes")
else:
print("no")2026/03/06
2775
- a층의 b호에 살려면 자신의 아래(a-1)층의 1호부터 b호까지 사람들의 수의 합만큼 사람들을 데려와 살아야 한다
예제
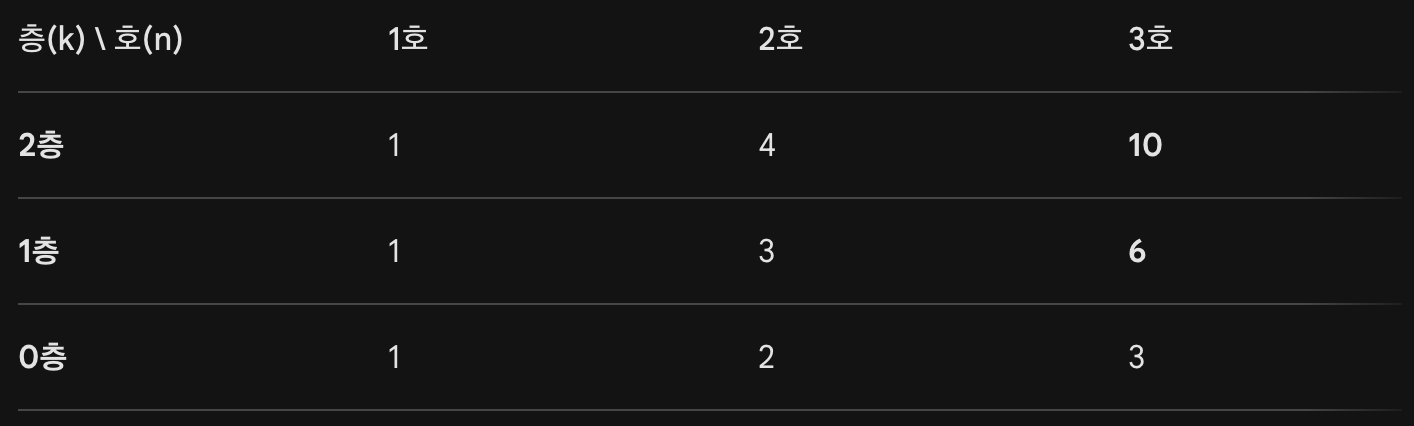
# 입력
2
1
3
2
3
# 출력
6
10입력 방법 (
sys.stdin.read())
import sys
# 사용자가 여러 줄로 2 1 3 2 3 을 입력
data = sys.stdin.read().split()
print(data)
# 출력: ['2', '1', '3', '2', '3'] (작은따옴표가 붙은 문자열)정수 변환
import sys
# 읽어온 문자열 리스트를 정수로 모두 변환한 뒤 다시 리스트로 묶음
data = list(map(int, sys.stdin.read().split()))
print(data)
# 출력: [2, 1, 3, 2, 3] (계산 가능한 진짜 숫자!)풀이
import sys
input = sys.stdin.read
def solve_apart():
data = input().split()
if not data:
return
N = int(data[0])
num = 1
for _ in range(N):
k = int(data[num]) # 층
n = int(data[num+1]) # 호
num += 2
# 0층의 거주민 리스트 (1호부터 n호까지: 1, 2, 3... n)
people = [i for i in range(1, n + 1)]
for floor in range(k):
# 2호(인덱스 1)부터 n호까지 계산
for room in range(1, n):
# 이전 호수의 사람 수 + 아래층 현재 호수의 사람 수
people[room] += people[room - 1]
# 리스트의 가장 마지막 요소(n호) 출력
print(people[-1])
solve_apart()파스칼 삼각형 풀이
import sys
import math
input = sys.stdin.read
def solve_math():
data = input().split()
if not data:
return
T = int(data[0])
idx = 1
for _ in range(T):
k = int(data[idx])
n = int(data[idx+1])
idx += 2
# math.comb를 사용하여 (k+n) C (k+1) 계산
result = math.comb(k + n, k + 1)
print(result)
if __name__ == '__main__':
solve_math()2026/03/07
1929
1은 소수가 아님
출력초과
if n % 2 != 0 and n % 3 != 0 and n % n == 0:- 소수가 아닌 합성수들도 소수로 잘못 판별하여 너무 많은 숫자를 출력하고 있기 때문
- n이 25 / 35 / 49 일때 오류발생
import sys
input = sys.stdin.read
def solve_decimal(n):
if n != 1:
if n == 2 or n == 3:
print(n)
else:
if n % 2 != 0 and n % 3 != 0 and n % n == 0:
print(n)
else:
pass
M, N = map(int,input().split())
for i in range(M,N+1):
solve_decimal(i)최적화
import sys
import math
input = sys.stdin.read
def solve_decimal(n):
if n == 1:
return False
# 2부터 n의 제곱근까지만 나누어 떨어지는지 확인
for i in range(2, int(math.sqrt(n)) + 1):
# 하나라도 나누어 떨어지면 소수가 아님
if n % i == 0:
return False
return True
data = input().split()
if data:
M, N = int(data[0]), int(data[1])
for i in range(M, N + 1):
if solve_decimal(i):
print(i)추천방식(에라토스테네스의 체)
import sys
input = sys.stdin.read
data = input().split()
if data:
M, N = int(data[0]), int(data[1])
# 1. 0부터 N까지 모든 숫자를 소수(True)라고 가정한 리스트 생성
sieve = [True] * (N + 1)
sieve[0] = sieve[1] = False # 0과 1은 소수가 아님
# 2. 에라토스테네스의 체 로직 적용
for i in range(2, int(N**0.5) + 1):
if sieve[i]: # i가 소수라면
# i의 배수들을 모두 지운다(False)
for j in range(i * i, N + 1, i):
sieve[j] = False
# 3. M부터 N까지 True인 인덱스만 출력
for i in range(M, N + 1):
if sieve[i]:
print(i)2026/03/08
1874(stack)
예제
# 입력
8
4
3
6
8
7
5
2
1
# 출력
+
+
+
+
-
-
+
+
-
+
+
-
-
-
-
-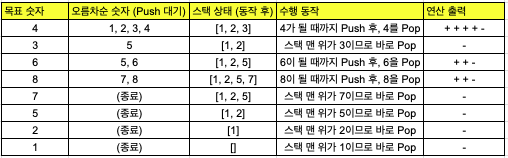
- 만약 스택의 맨 위(Top)에 있는 숫자가 목표 숫자와 다르고
- 더 이상 Push할 숫자도 없다면 그 수열은 스택으로 만들 수 없는 수열이 되어 NO를 출력
solve
import sys
def solve_stack():
data = sys.stdin.read().split()
if not data:
return
n = int(data[0])
targets = [int(i) for i in data[1:]]
stack = []
result = []
current = 1 # 스택에 Push할 오름차순 숫자
for target in targets:
# 1. 목표 숫자에 도달할 때까지 스택에 push
while current <= target:
stack.append(current)
result.append('+')
current += 1
# 2. 스택의 맨 위(top)가 목표 숫자와 같다면 pop
if stack[-1] == target:
stack.pop()
result.append('-')
else:
# 3. 스택의 맨 위가 목표 숫자와 다르다면 수열 생성 불가
print("NO")
return
for op in result:
print(op)
solve_stack()2026/03/09
1966(큐)
# 입력
3
1 0
5
4 2
1 2 3 4
6 0
1 1 9 1 1 1
# 해석
1 0: 문서가 1개 있고, 궁금한 문서는 0번째(첫 번째)에 있음
4 2: 문서가 4개 있고, 궁금한 문서는 2번째(인덱스 0부터 시작)에 있음
6 0: 문서가 6개 있고, 궁금한 문서는 0번째에 있음
# 출력
1
2
5
-
해석
- 1 0 (중요도: 5)
- 상태: 큐에 (중요도: 5, 인덱스: 0) 하나만 있음
- 과정: 현재 문서(5)보다 중요도가 높은 문서가 큐에 없으므로 바로 인쇄
- 결과: 0번째 문서는 1번째로 인쇄됩니다. → 출력: 1
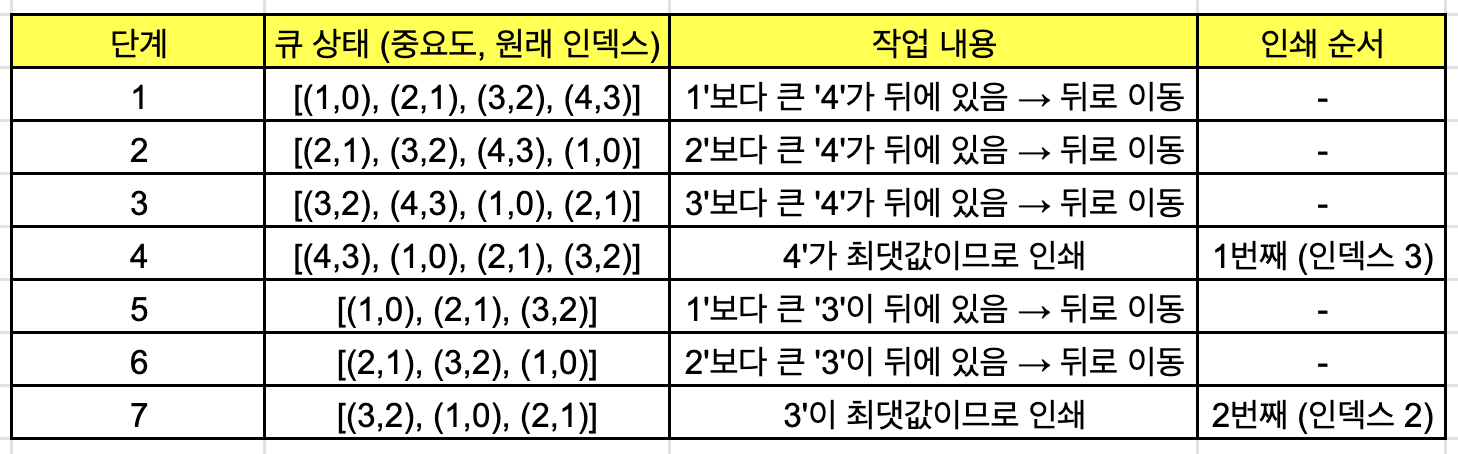
- 4 2 (중요도: 1 2 3 4)
- 궁금한 대상: 인덱스 2인 문서 (중요도 3)
- 초기 큐:
[(1, 0), (2, 1), (3, 2), (4, 3)] (값, 원래 위치)
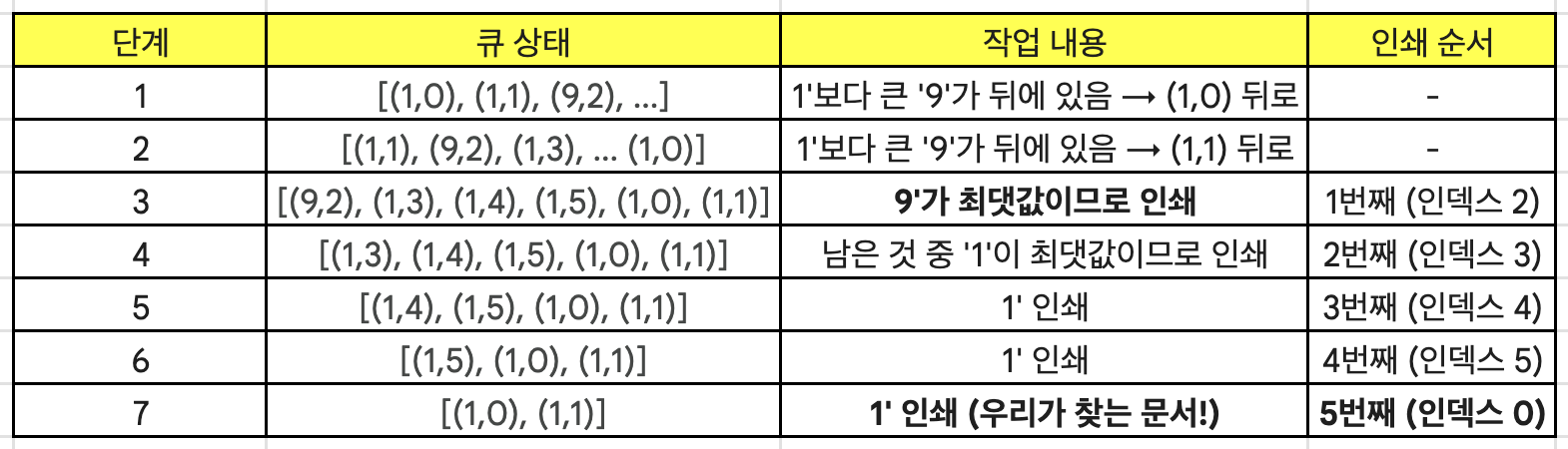
- 6 0 (중요도: 1 1 9 1 1 1)
- 궁금한 대상: 인덱스 0인 문서 (중요도 1)
- 초기 큐:
[(1,0), (1,1), (9,2), (1,3), (1,4), (1,5)]
- 1 0 (중요도: 5)
-
필요 로직
for i, fruit in enumerate([1,2,3]):
print(i, fruit)
# 출력
0 1
1 2
2 3풀이
from collections import deque
import sys
def solve_queue():
# 테스트 케이스 수
N = int(sys.stdin.readline())
for _ in range(N):
# A: 문서 개수, B: 궁금한 문서의 위치
A, B = map(int, sys.stdin.readline().split())
# (중요도, 초기 인덱스)
importance = list(map(int, sys.stdin.readline().split()))
queue = deque([(p, i) for i, p in enumerate(importance)])
count = 0 # 인쇄 순서
while queue:
# 1. 가장 앞에 있는 문서 꺼내기
current = queue.popleft()
# 2. 큐에 현재 문서보다 중요도가 높은 문서가 있는지 확인
if any(current[0] < i[0] for i in queue):
# 더 높은 게 있다면 가장 뒤로 보냄
queue.append(current)
else:
# 3. 현재 문서가 가장 중요하다면 인쇄
count += 1
# 만약 이 문서가 찾던 인덱스라면 종료
if current[1] == B:
print(count)
break
solve_queue()2026/03/10
28702(FizzBuzz)
해석
- 3의 배수이면서 5의 배수이면
- FizzBuzz
- 3의 배수이면: Fizz
- 5의 배수이면: Buzz
- 모두 아니면: 숫자
- FizzBuzz를 구현하는 것을 넘어, 연속된 세 개의 문자열을 보고 다음에 올 숫자를 유추
- 핵심: "입력값 중 적어도 하나는 반드시 숫자다"
- 연속된 3개의 값 중 숫자를 하나라도 찾으면
- 그 숫자의 위치를 통해 4번째에 올 숫자가 무엇인지 정확히 계산가능
- 3의 배수이면서 5의 배수이면
예시 분석
- 세 번째 값이 11이라는 숫자
- 구해야 할 값은 네 번째 위치(i+3)
- 세 번째 값이 11이기 때문에 네 번째 값은 당연히 12 = Fizz
# 입력
Fizz # (어떤 숫자의 위치 i)
Buzz # (위치 i + 1)
11 # (위치 i + 2)
# 출력
Fizz
필요 메서드
.isdigit()- 문자열이 '0~9'로만 이루어져 있는지 검사 (True/False)
풀이
# 28702
import sys
# strip 습관적으로 붙이기 연습
words = [sys.stdin.readline().strip() for _ in range(3)]
num = 0
for i in range(3):
# 입력값이 숫자인지 확인
if words[i].isdigit():
# 해당 위치의 숫자를 기준으로 4번째에 올 숫자 계산
num = int(words[i]) + (3 - i)
break
# FizzBuzz 판별
if num % 3 == 0 and num % 5 == 0:
print("FizzBuzz")
elif num % 3 == 0:
print("Fizz")
elif num % 5 == 0:
print("Buzz")
else:
print(num)2026/03/11
2292(벌집)
문제 해석
- 중앙의 1번 방에서 출발하여 특정 방 번호 까지 최소 몇 개의 방을 지나야 하는지 구함
- 1겹 (거리 1): 1 (1개)
- 2겹 (거리 2): 2 ~ 7 (6개)
- 3겹 (거리 3): 8 ~ 19 (12개)
- 4겹 (거리 4): 20 ~ 37 (18개)
- 6의 배수로 늘어나고 있음
- 중앙의 1번 방에서 출발하여 특정 방 번호 까지 최소 몇 개의 방을 지나야 하는지 구함
풀이
def solve_bee_house(N):
if N == 1:
return 1
layer = 1 # 현재 겹
max_num = 1 # 현재 겹의 마지막 방 번호
while N > max_num:
max_num += 6 * layer # 다음 겹의 마지막 번호로 갱신 (6의 배수씩 증가)
layer += 1 # 거리 증가
return layer
N = int(input())
print(solve_bee_house(N))2026/03/12
15829(hashing)
- 이 문제는 문자열을 특정한 정수 값으로 변환하는
다항식 롤링 해시(Polynomial Rolling Hash)함수의 구현을 요구

- 컴퓨터는 문자열 자체를 비교하는 것보다 숫자를 비교하는 것이 훨씬 빠르기 때문에
- 문자열을 고유한 숫자(해시값)로 변환하여 저장하거나 탐색할 때 해시 함수를 주로 사용함
예시 해석
# 입력
5 # 길이
abcde # 입력된 문자열
# 출력
4739715
# 해석
a = 1, b = 2, c = 3, d = 4, e = 5 # 각 알파벳에 부여된 고유 번호
1 × 310 + 2 × 311 + 3 × 312 + 4 × 313 + 5 × 314 = 1 + 62 + 2883 + 119164 + 4617605 = 4739715이다.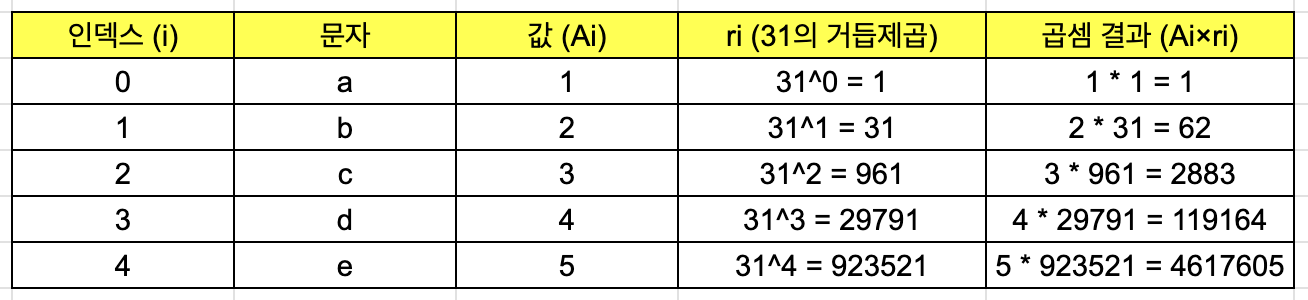
필요한 기능
ord()- 하나의 문자를 인자로 받아 그 문자에 해당하는 유니코드 정수(ASCII 코드 값)를 반환하는 함수
- 반대 기능을 하는 함수는
chr()(chr(97)을 입력하면 문자 'a'를 반환)
# 알파벳 소문자 'a'부터 'z'까지는 97부터 122까지 순서대로 1씩 증가하는 숫자가 배정되어 있음
print(ord('a')) # 출력: 97
print(ord('b')) # 출력: 98
print(ord('A')) # 출력: 65
print(ord('0')) # 출력: 48내 풀이에 적용
ascii_num = ord(s[i]) - ord('a') + 1
# 만약 문자열 s[i]가 'a'라면
ord('a') - ord('a') + 1
= 97 - 97 + 1
= 1
# 만약 문자열 s[i]가 'b'라면:
ord('b') - ord('a') + 1
= 98 - 97 + 1
= 2
# 만약 문자열 s[i]가 'z'라면
ord('z') - ord('a') + 1
= 122 - 97 + 1
= 26풀이
import sys
def solve_hashing():
# 입력 받기
L = int(sys.stdin.readline())
s = sys.stdin.readline().strip()
answer = 0
r = 31
# 문제의 조건
M = 1234567891
for i in range(L):
# 'a'=1, 'b'=2... 로 변환
ascii_num = ord(s[i]) - ord('a') + 1
# 공식 그대로 적용하여 더하기
answer += ascii_num * (r ** i)
# 문제에 주어진 조건으로 나눔
print(answer % M)
solve_hashing()2026/03/13
14626(ISBN)
문제 이해(ISBN-13 바코드의 체크 기호(검사 숫자) 원리)
- ISBN-13은 총 13개의 숫자로 구성
- 홀수 번째(1, 3, 5...) 자리 숫자는 1을 곱하고
- 짝수 번째(2, 4, 6...) 자리 숫자는 3을 곱함
- 이렇게 곱해서 나온 13개 숫자의 총합이 10의 배수(즉, mod 10 = 0)가 되어야
- 정상적인 ISBN 번호
결과 예시
# 입력
9788968322*73
# 출력
2
-
예시 해석

-
틀림
- 원인
- 가중치가 3일 때의 나눗셈 논리 틀림
*의 가중치가 3이라면- 찾는 숫자
x에 3을 곱한 값의 일의 자리가 8이 되어야 함 - 즉,
3 X *의 끝자리가 8로 끝나는 수(x=6,3 X 6 = 18)를 찾아야 함
- 찾는 숫자
- result_sum이 132일 경우 int(8/3)을 계산하여 2를 출력함(6이어야 함)
- 원인
N = list(str(input()))
odd_num=0
even_num=0
r_li=[]
# 홀수
for i in list(range(0,13,2)):
if N[i] != '*':
odd_num += int(N[i])*1
else:
r_li.append('*')
# 짝수
for j in list(range(1,12,2)):
if N[j] != '*':
even_num += int(N[j])*3
else:
r_li.append('***')
result_sum = odd_num + even_num
if result_sum % 10 == 0:
print(0)
else:
for k in range(1,10):
if (result_sum + k) % 10 == 0:
if len(r_li[0]) == 1:
print(int(k/1))
else:
print(int(k/3))수정
N = list(str(input()))
odd_num=0
even_num=0
r_li=[]
# 홀수
for i in list(range(0,13,2)):
if N[i] != '*':
odd_num += int(N[i])*1
else:
r_li.append('*')
# 짝수
for j in list(range(1,12,2)):
if N[j] != '*':
even_num += int(N[j])*3
else:
r_li.append('***')
result_sum = odd_num + even_num
# '*' 길이에 따라 1 또는 3
weight = 1 if len(r_li[0]) == 1 else 3
for k in range(10):
if (result_sum + k * weight) % 10 == 0:
print(k)
break완전 탐색 (Brute Force)
def solve_brute_force(isbn):
total_sum = 0
star_weight = 0
# 1. '*'를 제외한 나머지 수의 합과 '*'의 가중치(1 또는 3)를 구합니다.
for i in range(13):
# 파이썬 인덱스는 0부터 시작하므로, 짝수 인덱스가 홀수 번째 자리가 됩니다.
weight = 1 if i % 2 == 0 else 3
if isbn[i] == '*':
star_weight = weight
else:
total_sum += int(isbn[i]) * weight
# 2. 0부터 9까지 직접 대입하며 10의 배수인지 확인합니다.
for x in range(10):
if (total_sum + x * star_weight) % 10 == 0:
return x
# 입력 처리
isbn_input = input().strip()
print(solve_brute_force(isbn_input))수학적 연산 (Modular Arithmetic)
def solve_math(isbn):
total_sum = 0
star_weight = 0
for i in range(13):
weight = 1 if i % 2 == 0 else 3
if isbn[i] == '*':
star_weight = weight
else:
total_sum += int(isbn[i]) * weight
# 현재 합에서 10의 배수를 만들기 위해 부족한 값을 구합니다.
remainder_needed = (10 - (total_sum % 10)) % 10
# 가중치가 1인 경우, 부족한 값 자체가 정답입니다.
if star_weight == 1:
return remainder_needed
# 가중치가 3인 경우, 3x ≡ remainder_needed (mod 10)을 만족하는 x를 찾습니다.
# 양변에 3의 모듈러 역원인 7을 곱해주면 x를 바로 구할 수 있습니다.
else:
return (remainder_needed * 7) % 10
# 입력 처리
isbn_input = input().strip()
print(solve_math(isbn_input))2026/03/14
반올림
내장 함수
round()사용- 장점
- 별도의 임포트 없이 즉시 사용 가능하며 속도가 빠릅니다.
- 단점
- 우리가 흔히 아는 '사사오입'이 아니기 때문에
- 정확히 .5인 경우 코딩 테스트 문제 의도와 다를 수 있습니다.
- 장점
# 기본 사용법: round(숫자, 정밀도)
print(round(2.5)) # 결과: 2 (짝수인 2로 내림)
print(round(3.5)) # 결과: 4 (짝수인 4로 올림)
print(round(4.5)) # 결과: 4 (짝수인 4로 내림)
# 소수점 자리수 지정
print(round(3.14159, 2)) # 결과: 3.14decimal모듈 사용 (정밀한 사사오입)- 코딩 테스트에서 정확한 '사사오입' 반올림이 요구될 때 가장 안전한 방법입니다.
- 장점
- 수학적으로 기대하는 반올림(사사오입)을 정확하게 수행합니다.
- 단점
- decimal 모듈을 불러와야 하며, 코드가 약간 더 복잡해집니다.
- 장점
- 코딩 테스트에서 정확한 '사사오입' 반올림이 요구될 때 가장 안전한 방법입니다.
from decimal import Decimal, ROUND_HALF_UP
def traditional_round(number):
# 숫자를 Decimal 객체로 변환 후, ROUND_HALF_UP 방식으로 정수화
return int(Decimal(str(number)).quantize(Decimal('1'), rounding=ROUND_HALF_UP))
print(traditional_round(2.5)) # 결과: 3
print(traditional_round(3.5)) # 결과: 4수학적 트릭 사용 (간단한 구현)
- 모듈을 쓰기 번거로울 때 사용하는 고전적인 방법입니다. (양수 기준)
- 장점
- 매우 직관적이고 빠릅니다.
- 단점
- 음수일 때는 int(n - 0.5)를 사용하는 등 처리가 별도로 필요하여 실수의 여지 존재
- 장점
- 모듈을 쓰기 번거로울 때 사용하는 고전적인 방법입니다. (양수 기준)
def manual_round(n):
return int(n + 0.5)
print(manual_round(2.5)) # 결과: 3
print(manual_round(3.4)) # 결과: 3최빈값
- Counter는 파이썬의 collections 모듈에 포함된 강력한 클래스로
- 말 그대로 데이터 안의 각 원소가 몇 번씩 등장하는지 개수를 세어주는 역할
- 기본 원리: 리스트를 딕셔너리로 변환
from collections import Counter
# 과일 바구니 (리스트)
arr = ['apple', 'banana', 'apple', 'cherry', 'apple', 'banana']
# Counter에게 개수를 세어달라고 부탁
count_result = Counter(arr)
print(count_result)
# 출력: Counter({'apple': 3, 'banana': 2, 'cherry': 1})
# 특정 원소의 개수만 따로 확인할 수도 있습니다.
print(count_result['apple']) # 출력: 3most_common()- most_common()이라는 전용 메서드
- (숫자, 빈도수) 형태의 튜플 리스트를 빈도수가 높은 순서대로 내림차순 정렬하여 반환
- 빈도수가 같으면 원래 배열에서 먼저 등장한 숫자 순, 즉 오름차순으로 유지됨
# 가장 많이 등장한 상위 2개의 데이터를 추출
top_2 = count_result.most_common(2)
print(top_2)
# 출력: [('apple', 3), ('banana', 2)]2108(통계학)
- 산술평균 : N개의 수들의 합을 N으로 나눈 값
- 첫째 줄에는 산술평균을 출력한다. 소수점 이하 첫째 자리에서 반올림한 값을 출력한다.
- 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
- 둘째 줄에는 중앙값을 출력한다.
- 최빈값 : N개의 수들 중 가장 많이 나타나는 값
- 셋째 줄에는 최빈값을 출력한다. 여러 개 있을 때에는 최빈값 중 두 번째로 작은 값을 출력
- 범위 : N개의 수들 중 최댓값과 최솟값의 차이
- 넷째 줄에는 범위를 출력
풀이
# 2108
from decimal import Decimal, ROUND_HALF_UP
import math
from collections import Counter
import sys
input = sys.stdin.readline
# 반올림
def traditional_round(number):
return int(Decimal(str(number)).quantize(Decimal('1'), rounding=ROUND_HALF_UP))
# 최빈값
def solve_counter(arr):
# 1. 오름차순 정렬
arr.sort()
# 2. Counter를 사용해 빈도수를 계산
counter = Counter(arr)
# 3. most_common()이라는 전용 메서드 사용
result = counter.most_common()
# 4. 최빈값이 2개 이상이고, 1위와 2위의 빈도수가 같다면 두 번째로 작은 값 반환
if len(result) > 1 and result[0][1] == result[1][1]:
return result[1][0]
else:
return result[0][0]
N = int(input())
M = [int(input()) for _ in range(N)]
# 1. 산술평균
print(traditional_round(sum(M)/N))
# 2. 중앙값
M.sort()
print(M[math.floor(N/2)])
# 3. 최빈값
print(solve_counter(M))
# 4. 범위
print(max(M)-min(M))
다른 풀이 (불필요한 연산 줄이기)
내장 딕셔너리(dict) 활용 (Counter 모듈 없이 구현)
import sys
input = sys.stdin.readline
N = int(input())
M = [int(input()) for _ in range(N)]
# 🌟 처음에 한 번만 정렬합니다. (중앙값, 최빈값, 범위 모두에 재사용)
M.sort()
# 1. 산술평균
# (작성해주신 decimal 방식이 가장 안전하지만, 여기서는 내장 round를 사용해 봅니다)
print(int(round(sum(M) / N, 0)))
# 2. 중앙값 (몫 연산자 '//' 사용)
print(M[N // 2])
# 3. 최빈값 (기본 딕셔너리 사용)
freq_dict = {}
for num in M:
freq_dict[num] = freq_dict.get(num, 0) + 1 # 없으면 0, 있으면 +1
max_freq = max(freq_dict.values()) # 가장 높은 빈도수 찾기
modes = []
# M이 이미 오름차순 정렬되어 있으므로, 딕셔너리에도 작은 숫자부터 차례대로 쌓여 있습니다.
# (참고: Python 3.7 이상부터는 딕셔너리가 데이터 삽입 순서를 보장합니다)
for num, freq in freq_dict.items():
if freq == max_freq:
modes.append(num)
if len(modes) > 1:
print(modes[1]) # 두 번째로 작은 값
else:
print(modes[0])
# 4. 범위 (정렬된 배열의 맨 끝 값 - 맨 앞 값)
print(M[-1] - M[0])빈도수 배열 (계수 정렬 / Counting Sort 개념)
- 이 문제는 숫자의 범위가 -4000 ~ 4000으로 매우 작습니다.
- 이를 이용해 크기가 8001인 배열을 만들면
- 단 한 번의 정렬(sort())도 없이 O(N)의 속도로 4가지 통계값을 모두 구할 수 있습니다.

import sys
input = sys.stdin.readline
N = int(input())
# -4000 ~ 4000을 인덱스 0 ~ 8000으로 매핑할 빈도수 배열
count_arr = [0] * 8001
total_sum = 0
max_val = -4001
min_val = 4001
# 입력을 받으면서 동시에 합계, 최대/최소, 빈도수를 기록합니다 O(N)
for _ in range(N):
num = int(input())
count_arr[num + 4000] += 1
total_sum += num
if num > max_val: max_val = num
if num < min_val: min_val = num
# 1. 산술평균
print(int(round(total_sum / N, 0)))
# 중앙값과 최빈값을 찾기 위한 변수 초기화
median = 4001
modes = []
max_freq = max(count_arr)
current_count = 0
# 빈도수 배열을 순회하며 중앙값과 최빈값 찾기 O(1) (항상 8001번만 반복)
for i in range(8001):
if count_arr[i] > 0:
# 중앙값: 누적 개수가 N // 2 + 1개째가 되는 순간의 숫자
if current_count < (N // 2 + 1):
current_count += count_arr[i]
if current_count >= (N // 2 + 1):
median = i - 4000
# 최빈값 리스트에 추가
if count_arr[i] == max_freq:
modes.append(i - 4000)
# 2. 중앙값 출력
print(median)
# 3. 최빈값 출력
if len(modes) > 1:
print(modes[1])
else:
print(modes[0])
# 4. 범위 출력
print(max_val - min_val)클래스 2 졸업!
2026/03/15
11723(집합)
문제
add x- S에 x를 추가한다. (1 ≤ x ≤ 20) S에 x가 이미 있는 경우에는 연산을 무시한다.
remove x- S에서 x를 제거한다. (1 ≤ x ≤ 20) S에 x가 없는 경우에는 연산을 무시한다.
check x- S에 x가 있으면 1을, 없으면 0을 출력한다. (1 ≤ x ≤ 20)
toggle x- S에 x가 있으면 x를 제거하고, 없으면 x를 추가한다. (1 ≤ x ≤ 20)
all- S를 {1, 2, ..., 20} 으로 바꾼다.
empty- S를 공집합으로 바꾼다.
예시
# 입력
26
add 1
add 2 [1,2]
check 1 # 1
check 2 # 1
check 3 # 0
remove 2 [1]
check 1 # 1
check 2 # 0
toggle 3 [1,3]
check 1 # 1
check 2 # 0
check 3 # 1
check 4 # 0
all [1,2, ... 20]
check 10 # 1
check 20 # 1
toggle 10 [1,2, ... 9 ... 20]
remove 20 [1,2, ... 9 ... 19]
check 10 # 1
check 20 # 0
empty []
check 1 # 0
toggle 1 [1]
check 1 # 1
toggle 1 []
check 1 # 0
# 출력
1
1
0
1
0
1
0
1
0
1
1
0
0
0
1
0필요한 기능
# add 1 / all 이런식으로 입력받기
command = input().split()풀이
import sys
def solve_set():
input = sys.stdin.readline
M = int(input())
s = set()
for _ in range(M):
command = input().split()
# all / empty 만 1개
if len(command) == 1:
if command[0] == "all":
s = set([i for i in range(1, 21)])
else:
s = set()
else:
op, x = command[0], int(command[1])
if op == "add":
s.add(x)
elif op == "remove":
s.discard(x)
elif op == "check":
print(1 if x in s else 0)
elif op == "toggle":
if x in s:
s.discard(x)
else:
s.add(x)
solve_set()다른 풀이
- 비트마스킹 (Bitmasking) 사용
import sys
def solve_with_bitmask():
input = sys.stdin.readline
M = int(input())
# 0으로 초기화 (공집합)
S = 0
for _ in range(M):
command = input().split()
if len(command) == 1:
if command[0] == "all":
# 1~20번째 비트를 모두 1로 만듦
S = (1 << 21) - 1
else: # "empty"
S = 0
else:
op, x = command[0], int(command[1])
if op == "add":
S |= (1 << x) # x번째 비트를 1로 켬 (OR 연산)
elif op == "remove":
S &= ~(1 << x) # x번째 비트를 0으로 끔 (AND, NOT 연산)
elif op == "check":
if S & (1 << x): # x번째 비트가 1인지 확인 (AND 연산)
print(1)
else:
print(0)
elif op == "toggle":
S ^= (1 << x) # x번째 비트를 반전 (XOR 연산)
solve_with_bitmask()2026/03/16
1620(포켓몬)
요구사항
- N개의 포켓몬 이름이 순서대로 주어집니다. (1번부터 N번까지)
- 이후 M개의 문제가 주어지는데
- 문제가 숫자(번호)면 해당하는 포켓몬의 이름을 출력하고, 이름이면 해당하는 번호를 출력해야 함
- N개의 포켓몬 이름이 순서대로 주어집니다. (1번부터 N번까지)
예시
# 입력
26 5
Bulbasaur
Ivysaur
Venusaur
Charmander
Charmeleon
Charizard
Squirtle
Wartortle
Blastoise
Caterpie
Metapod
Butterfree
Weedle
Kakuna
Beedrill
Pidgey
Pidgeotto
Pidgeot
Rattata
Raticate
Spearow
Fearow
Ekans
Arbok
Pikachu
Raichu # N = 26 끝
25 # M = 5 시작
Raichu
3
Pidgey
Kakuna
# 출력
Pikachu
26
Venusaur
16
14필요 로직
A = [""] * (5) # ['', '', '', '', '']
A[1] = B # ['', 'B', '', '', '']
"""
[입력 예시 시나리오]
3 4 <-- N(포켓몬 수: 3), M(문제 수: 4)
Bulbasaur <-- 1번 포켓몬
Ivysaur <-- 2번 포켓몬
Venusaur <-- 3번 포켓몬
2 <-- 문제 1: 숫자 (2번 포켓몬 이름 출력)
Venusaur <-- 문제 2: 문자 (Venusaur의 번호 출력)
1 <-- 문제 3: 숫자 (1번 포켓몬 이름 출력)
Bulbasaur <-- 문제 4: 문자 (Bulbasaur의 번호 출력)
"""
input = sys.stdin.readline
# n = 3, m = 4 가 저장
n, m = map(int, input().split())
# 두 개의 자료구조를 사용
id_to_name = [""] * (n + 1) # 인덱스 -> 이름 (배열)
name_to_id = {} # 이름 -> 인덱스 (딕셔너리)
# 1. 포켓몬 도감 입력 받기
for i in range(1, n + 1):
name = input().rstrip()
id_to_name[i] = name
name_to_id[name] = i
# 데이터 저장 결과 (예시 기준):
# id_to_name = ['', 'Bulbasaur', 'Ivysaur', 'Venusaur']
# name_to_id = {'Bulbasaur': 1, 'Ivysaur': 2, 'Venusaur': 3}출력 예시
import sys
def solve_with_hashmap():
"""
[입력 예시 시나리오]
3 4 <-- N(포켓몬 수: 3), M(문제 수: 4)
Bulbasaur <-- 1번 포켓몬
Ivysaur <-- 2번 포켓몬
Venusaur <-- 3번 포켓몬
2 <-- 문제 1: 숫자 (2번 포켓몬 이름 출력)
Venusaur <-- 문제 2: 문자 (Venusaur의 번호 출력)
1 <-- 문제 3: 숫자 (1번 포켓몬 이름 출력)
Bulbasaur <-- 문제 4: 문자 (Bulbasaur의 번호 출력)
"""
# 빠른 입력을 위해 sys.stdin.readline 사용
input = sys.stdin.readline
# 예시 기준: n = 3, m = 4 가 저장됩니다.
n, m = map(int, input().split())
# 두 개의 자료구조를 사용합니다.
id_to_name = [""] * (n + 1) # 인덱스 -> 이름 (배열)
name_to_id = {} # 이름 -> 인덱스 (딕셔너리)
# 1. 포켓몬 도감 입력 받기
for i in range(1, n + 1):
name = input().rstrip()
id_to_name[i] = name
name_to_id[name] = i
# 데이터 저장 결과 (예시 기준):
# id_to_name = ['', 'Bulbasaur', 'Ivysaur', 'Venusaur']
# name_to_id = {'Bulbasaur': 1, 'Ivysaur': 2, 'Venusaur': 3}
result = []
# 2. 문제 풀기 (총 4번 반복)
for _ in range(m):
query = input().rstrip()
# 쿼리가 숫자인지 문자열인지 판별합니다.
if query.isdigit():
# 예: query가 "2" 라면
# int(query)는 2가 되고, id_to_name[2]인 "Ivysaur"가 추가됨
result.append(id_to_name[int(query)])
else:
# 예: query가 "Venusaur" 라면
# name_to_id["Venusaur"] 값인 3이 문자열 "3"으로 변환되어 추가됨
result.append(str(name_to_id[query]))
# 최종 결과 출력 (예시 기준):
# Ivysaur
# 3
# Bulbasaur
# 1
print('\n'.join(result))
if __name__ == "__main__":
solve_with_hashmap()풀이(해시맵 (Dictionary) 활용)
import sys
def solve_pokemon():
input = sys.stdin.readline
n, m = map(int, input().split())
id_to_name = [""] * (n + 1) # ['', '', '', '', ''...]
name_to_id = {} # {'' : 1, ...}
for i in range(1, n + 1):
name = input().rstrip()
id_to_name[i] = name
name_to_id[name] = i
result = []
for _ in range(m):
ans = input().rstrip()
# 쿼리가 숫자인지 문자열인지 판별
if ans.isdigit():
result.append(id_to_name[int(ans)])
else:
result.append(str(name_to_id[ans]))
print('\n'.join(result))
solve_pokemon()다른 풀이(배열과 이진 탐색 (Binary Search) 활용)
import sys
from bisect import bisect_left
def solve_with_binary_search():
input = sys.stdin.readline
n, m = map(int, input().split())
original_arr = [""] * (n + 1)
sorted_arr = []
for i in range(1, n + 1):
name = input().rstrip()
original_arr[i] = name
# (포켓몬 이름, 원래 인덱스) 형태로 저장
sorted_arr.append((name, i))
# 이름을 기준으로 오름차순 정렬 (이진 탐색을 위함)
sorted_arr.sort()
# 이진 탐색을 위한 키(이름)만 따로 분리
keys = [item[0] for item in sorted_arr]
result = []
for _ in range(m):
query = input().rstrip()
if query.isdigit():
# 번호가 주어지면 원본 배열에서 즉시 찾음
result.append(original_arr[int(query)])
else:
# 이름이 주어지면 이진 탐색으로 위치를 찾음
idx = bisect_left(keys, query)
# 찾은 위치에서 원래 인덱스를 추출
result.append(str(sorted_arr[idx][1]))
print('\n'.join(result))
if __name__ == "__main__":
solve_with_binary_search()2026/03/17
11047(동전())
풀이(시간초과)
- K의 입력조건이 1<K<1억이어서 K가 0일경우를 배제했는데
- 생각해보니까 계산후에 0이 되는 경우를 생각하지 않았음
# 11047
import sys
input = sys.stdin.readline
N, K = map(int,input().split())
li = [int(input()) for _ in range(N)]
num=0
for i in reversed(li):
if i > K:
pass
else:
while True:
if i <= K:
K -= i
num +=1
else:
break
print(num)원인
- Python은 보통 1초에 약 2,000만 ~ 5,000만 번의 연산을 수행
- 제약 조건은 최대 1억회임
for i in reversed(li):
while True:
if i <= K:
K -= i # 1. 반복적으로 뺄셈 수행
num += 1
else:
break해결(몫(//)과 나머지(%) 연산 사용)
import sys
input = sys.stdin.readline
N, K = map(int, input().split())
li = [int(input()) for _ in range(N)]
num = 0
for i in reversed(li):
if K == 0:
break
if i <= K:
# K원을 i원짜리 동전으로 나눈 몫이 사용되는 동전의 개수
num += K // i
# 남은 금액을 K에 다시 저장
K %= i
print(num)앵간하면 반복문을 사용하는 습관을 버리자
2026/03/18
11399(ATM)
각 사람이 돈을 인출하는데 필요한 시간의 합의 최솟값
입력 예시
# 입력
5
3 1 4 3 2
# 출력
32
# 해석
[1,2,3,4,5]
3 + 4 + 8 + 11 + 13 = 39
[2,5,1,4,3,]
1 + 3 + 6 + 9 + 13 = 32 (최소값)풀이
import sys
input = sys.stdin.readline
N = int(input())
M = list(map(int,input().split()))
M.sort()
result = 0
for i in range(1,N+1):
result += sum(M[:i])
print(result)2026/03/19
17219(비밀번호 찾기)
풀이1 = 틀림
- 줄바꿈 문자 처리 안함
sys.stdin.readline은 입력받을 때 맨 끝의 줄바꿈 문자(\n)까지 함께 읽어옴- li_2를 만들 때 사용한 input()은 줄바꿈 문자를 그대로 유지 (예: 'site.com\n')
- 결과적으로
i == j[0]를 비교할 때 'site.com\n' == 'site.com'이 되어 두 값이 영원히 같아질 수 없어 출력 불가
- 어차피 이거 처리했어도 시간초과 났을듯
- 줄바꿈 문자 처리 안함
# 17219
import sys
input = sys.stdin.readline
N,M = map(int,input().split())
li = [input().split() for _ in range(N)]
li_2 = [input() for _ in range(M)]
for i in li_2:
for j in li:
if i == j[0]:
print(j[1])
else:
pass풀이2 - 딕셔너리 사용
- 파이썬의 내장 딕셔너리는 해시 테이블로 구현되어 있어
- 값을 검색할 때 리스트처럼 순회하지 않고 한 번에 찾아냄 (가장 실행 속도가 빠름)
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
passwords = {}
# N개의 사이트와 비밀번호를 딕셔너리에 저장
for _ in range(N):
site, pwd = input().split()
passwords[site] = pwd
# M개의 사이트에 대한 비밀번호 출력
for _ in range(M):
# 줄바꿈 문자(\n)를 제거
target_site = input().rstrip()
print(passwords[target_site])다른풀이 - 정렬과 이분 탐색(Binary Search)을 활용
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
li = [input().split() for _ in range(N)]
# 이분 탐색을 위해 사이트명(알파벳) 기준으로 리스트를 정렬합니다.
li.sort(key=lambda x: x[0])
for _ in range(M):
target_site = input().rstrip()
# 이분 탐색 알고리즘
start, end = 0, N - 1
while start <= end:
mid = (start + end) // 2
if li[mid][0] == target_site:
print(li[mid][1])
break
elif li[mid][0] < target_site:
start = mid + 1
else:
end = mid - 12026/03/20
1003(피보나치 함수)
f(n) = f(n-1) + f(n-2)
입력 예시
# 입력
3
0
1
3
# 출력
1 0
0 1
1 2
# 해석(f())
f(0) = 0을 호출하고 끝
f(1) = 1을 호출하고 끝
f(3) = f(2) + f(1)
f(2) = f(1) + f(0)
f(2) = 0을 한번 1을 한번 호출
f(3) = 0을 한번 1을 두번 호출 = 1 2
풀이
import sys
def solve_fibonaccii():
input = sys.stdin.read
data = input().split()
T = int(data[0])
N = [int(i) for i in data[1:]]
for j in N:
count_0 = [1, 0]
count_1 = [0, 1]
if j >= 2:
for k in range(2, j + 1):
count_0.append(count_0[k-1] + count_0[k-2])
count_1.append(count_1[k-1] + count_1[k-2])
print(f"{count_0[j]} {count_1[j]}")
solve_fibonaccii()다른풀이 (다이나믹 프로그래밍 최적화 (변수만 사용))
def fibonacci_optimized():
t = int(input("테스트 케이스 수를 입력하세요: "))
for _ in range(t):
n = int(input())
# 초기 변수 설정 (N=0일 때의 0 호출 횟수, 1 호출 횟수)
zero_count = 1
one_count = 0
# N번 만큼 반복하며 값을 갱신
for _ in range(n):
# 다음 0의 횟수는 현재 1의 횟수와 같고,
# 다음 1의 횟수는 현재 0과 1의 횟수를 더한 것과 같음
zero_count, one_count = one_count, zero_count + one_count
print(f"{zero_count} {one_count}")
# 실행
# fibonacci_optimized()2026/03/21
1463(1로 만들기) - hard
풀이1(틀림)
- 반례 (N = 10일 때)
- 10은 3으로 안 나뉘므로 2로 나눔 (10 -> 5) -> 5는 1을 뺌 (5 -> 4)
- -> 4를 2로 나눔 (4 -> 2) -> 2를 2로 나눔 (2 -> 1). 총 4번의 연산이 필요
- 실제 최적의 흐름
- 10에서 먼저 1을 뺌 (10 -> 9) -> 9를 3으로 나눔 (9 -> 3)
- -> 3을 3으로 나눔 (3 -> 1). 총 3번의 연산으로 끝
- 반례 (N = 10일 때)
N = int(input())
result = 0
while N == 1:
if N % 3==0:
N /= 3
result +=1
elif N % 2==0:
N /= 2
result +=1
else:
N -=1
result +=1
print(result)풀이2(바텀업 동적 계획법 (Bottom-Up DP))
- "과거의 정답을 적어두는 장부"

- "과거의 정답을 적어두는 장부"
N = int(input())
# dp 배열 초기화: 길이를 N+1로 설정하여 인덱스가 곧 해당 숫자를 의미하도록 함
# dp[i]는 i를 1로 만드는 데 필요한 최소 연산 횟수
dp = [0] * (N + 1)
# 2부터 N까지 차례대로 최소 횟수를 구해 나감
for i in range(2, N + 1):
# 1. 먼저 1을 빼는 경우의 연산 횟수를 가져옵니다. (+1은 이번 연산 횟수 추가)
dp[i] = dp[i - 1] + 1
# 2. 2로 나누어 떨어지는 경우, 기존 횟수와 2로 나누었을 때의 횟수 중 최솟값을 선택
if i % 2 == 0:
dp[i] = min(dp[i], dp[i // 2] + 1)
# 3. 3으로 나누어 떨어지는 경우, 현재까지의 최솟값과 3으로 나누었을 때의 횟수 중 최솟값을 선택
if i % 3 == 0:
dp[i] = min(dp[i], dp[i // 3] + 1)
print(dp[N])풀이3(너비 우선 탐색 (BFS))
- 내 몸을 여러 개로 복제해서 한 걸음씩 모든 방향으로 동시에 퍼져나가는 방식

- 내 몸을 여러 개로 복제해서 한 걸음씩 모든 방향으로 동시에 퍼져나가는 방식
# 솔루션 2: BFS (Queue 활용)
from collections import deque
N = int(input())
def bfs(start):
# (현재 숫자, 연산 횟수) 형태로 큐에 저장
queue = deque([(start, 0)])
visited = set([start]) # 이미 계산한 숫자는 다시 계산하지 않도록 방문 처리
while queue:
current, count = queue.popleft()
# 1에 도달하면 현재까지의 연산 횟수를 반환하고 종료
if current == 1:
return count
# 3가지 연산을 모두 큐에 넣고 탐색
# 연산 결과가 1 이상이고 아직 방문하지 않은 숫자라면 큐에 추가
if current % 3 == 0 and (current // 3) not in visited:
visited.add(current // 3)
queue.append((current // 3, count + 1))
if current % 2 == 0 and (current // 2) not in visited:
visited.add(current // 2)
queue.append((current // 2, count + 1))
if (current - 1) not in visited:
visited.add(current - 1)
queue.append((current - 1, count + 1))
print(bfs(N))2026/03/22
10699(오늘 날짜)
from datetime import date
print(date.today())2026/03/23
7287(등록)
2026/03/24
2420(사파리)
절대값 출력 메서드
# 정수 및 실수 사용 예시
num1 = -10
num2 = 3.14
num3 = -5.5
print(abs(num1)) # 출력: 10
print(abs(num2)) # 출력: 3.14
print(abs(num3)) # 출력: 5.5풀이
import sys
input = sys.stdin.readline
N,M = map(int,input().split())
print(abs(N-M))2026/03/25
2744(대소문자 바꾸기)
swapcase 사용
N = str(input())
print(N.swapcase())2026/03/26
2754(학점계산)
- 딕셔너리 안쓴지 오래되어서 한번 사용해봤음
N = dict(zip
(
["A+","A0","A-","B+","B0","B-","C+","C0","C-","D+","D0","D-","F"],
[4.3,4.0,3.7,3.3,3.0,2.7,2.3,2.0,1.7,1.3,1.0,0.7,0.0]
)
)
M = list(N.items())
L = str(input())
for i in M:
if L == i[0]:
print(i[1])
else:
pass 2026/03/27
15964(이상한 기호)
-
기호는 @으로, A@B = (A+B)×(A-B)
-
풀이
# 15964
import sys
def solve_function(A,B):
N = (A+B)*(A-B)
print(N)
input = sys.stdin.readline
A, B = map(int,input().split())
solve_function(A,B)2026/03/28
1927번 - 최소 힙
- 연산 1: 자연수 가 주어지면 배열에 넣는다.
- 연산 2: 이 주어지면 배열에서 가장 작은(혹은 큰) 값을 출력하고 그 값을 배열에서 제거한다. (비어있으면 출력)
- heapq 모듈은 기본적으로 최소 힙(Min Heap)으로 구현되어 있음
# 1927
import sys
import heapq
input = sys.stdin.readline
n = int(input())
li = []
for _ in range(n):
x = int(input())
if x == 0:
if len(li) == 0:
print(0)
else:
print(heapq.heappop(li))
else:
heapq.heappush(li, x)11279번 - 최대 힙
- 원리: 어떤 수들에 마이너스()를 붙이면, 가장 컸던 수가 가장 작은 수가 됩니다.
- (예: 로 만들면 가 최소 힙의 꼭대기로 올라갑니다.)
- 방법: 값을 힙에 넣을 때 -x로 넣고, 뽑을 때 다시 -를 붙여서 원래 숫자로 되돌려 줍니다.
# 11279
import sys
import heapq
input = sys.stdin.readline
n = int(input())
li = []
for _ in range(n):
x = int(input())
if x == 0:
if len(li) == 0:
print(0)
else:
print(-heapq.heappop(li))
else:
heapq.heappush(li, -x)2026/03/29
1260(DFS와 BFS)
이해
- 그래프: '사람들 간의 친구 관계'
- 정점 (Node): 사람 (예: 1번=철수, 2번=영희, 3번=민수...)
- 간선 (Edge): 두 사람이 '친구'라는 것을 나타내는 선
- 방문 처리 (visited): "이미 연락한 사람" 명단.
- (이 명단이 없으면 서로 계속 연락하다가 무한 루프에 빠지게 됩니다.)
- 인접 행렬: "학급 전체 교우관계표 (O/X 표)"
- 인접 행렬은 반 학생 전체의 이름을 가로세로로 적어놓고, 친구면 1, 아니면 0을 표시한 거대한 표입니다.
- 컴퓨터의 생각
- 1번(철수)의 친구를 찾기 위해, 표에서 1번 줄을 쭉 보면서 1번부터 마지막 번호까지 전부 다 확인
- 코드와 연결
- 그래서 코드에 for i in range(1, V + 1): 이라는 반복문이 들어감
- 무조건 1번 사람부터 V번(끝 번호) 사람까지 한 명씩 지목하면서
- "너 철수랑 친구니?(
matrix[v][i] == 1)" 하고 묻는 과정
- "너 철수랑 친구니?(
- 특징
- 무조건 1번부터 차례대로 묻기 때문에 "번호가 작은 순서대로 방문하라"는 문제의 조건을 충족
- 하지만 친구가 없어도 전교생을 다 찔러봐야 해서 시간이 좀 걸림
- 인접 리스트: "개인 스마트폰 연락처"
- 인접 리스트는 각자 자기 스마트폰에 진짜 친구들의 번호만 저장해 둔 것입니다.
- 컴퓨터의 생각
- 1번(철수)의 친구를 찾으려면, 그냥 1번의 스마트폰 연락처 앱을 켜서 저장된 목록만 확인합니다.\
- 코드와 연결
- 코드에서
for i in graph[v]:라는 반복문이 쓰임 - 전교생을 다 확인하지 않고, 철수의 연락처(
graph[v])에 있는 사람들만 쏙쏙 빼서 확인
- 코드에서
- 특징
- 진짜 친구만 확인하니까 탐색 속도가 훨씬 빠름
- 단, 연락처에 번호가 뒤죽박죽 저장되어 있을 수 있으므로,
- 작은 번호부터 연락하라는 규칙을 지키기 위해 사전에
- 연락처를 오름차순으로 정리(
graph[i].sort())해두는 과정이 꼭 필요
인접 행렬 (Adjacency Matrix) 활용
import sys
from collections import deque
def dfs_matrix(v):
visited_dfs[v] = True
print(v, end=' ')
# 1번 정점부터 V번 정점까지 순서대로 확인 (자동으로 번호가 작은 순서대로 방문)
for i in range(1, V + 1):
if not visited_dfs[i] and matrix[v][i] == 1:
dfs_matrix(i)
def bfs_matrix(start):
queue = deque([start])
visited_bfs[start] = True
while queue:
v = queue.popleft()
print(v, end=' ')
for i in range(1, V + 1):
if not visited_bfs[i] and matrix[v][i] == 1:
queue.append(i)
visited_bfs[i] = True
# 입력 받기
input = sys.stdin.readline
V, E, start = map(int, input().split())
# 인접 행렬 초기화 (정점 번호가 1부터 시작하므로 V+1 크기로 생성)
matrix = [[0] * (V + 1) for _ in range(V + 1)]
visited_dfs = [False] * (V + 1)
visited_bfs = [False] * (V + 1)
# 간선 정보 입력
for _ in range(E):
u, v = map(int, input().split())
matrix[u][v] = 1
matrix[v][u] = 1 # 양방향 간선
dfs_matrix(start)
print()
bfs_matrix(start)인접 리스트 (Adjacency List) 활용
import sys
from collections import deque
def dfs_list(v):
visited_dfs[v] = True
print(v, end=' ')
# 연결된 정점들만 순회
for i in graph[v]:
if not visited_dfs[i]:
dfs_list(i)
def bfs_list(start):
queue = deque([start])
visited_bfs[start] = True
while queue:
v = queue.popleft()
print(v, end=' ')
for i in graph[v]:
if not visited_bfs[i]:
queue.append(i)
visited_bfs[i] = True
# 입력 받기
input = sys.stdin.readline
V, E, start = map(int, input().split())
# 인접 리스트 초기화
graph = [[] for _ in range(V + 1)]
visited_dfs = [False] * (V + 1)
visited_bfs = [False] * (V + 1)
# 간선 정보 입력
for _ in range(E):
u, v = map(int, input().split())
graph[u].append(v)
graph[v].append(u) # 양방향 간선
# 방문할 수 있는 정점이 여러 개인 경우 작은 번호부터 방문하기 위해 정렬
for i in range(1, V + 1):
graph[i].sort()
dfs_list(start)
print()
bfs_list(start)결과 예시
import sys
from collections import deque
def dfs_matrix(v):
visited_dfs[v] = True
print(v, end=' ') # 방문한 정점 출력 (예: 1 -> 2 -> 4 -> 3 순서로 출력됨)
# 1번 정점부터 V(4)번 정점까지 순서대로 표를 확인
for i in range(1, V + 1):
if not visited_dfs[i] and matrix[v][i] == 1:
dfs_matrix(i)
def bfs_matrix(start):
queue = deque([start])
visited_bfs[start] = True
while queue:
v = queue.popleft()
print(v, end=' ') # 큐에서 꺼낸 정점 출력 (예: 1 -> 2 -> 3 -> 4 순서로 출력됨)
for i in range(1, V + 1):
if not visited_bfs[i] and matrix[v][i] == 1:
queue.append(i)
visited_bfs[i] = True
# ----------------- 실행 및 결과 -----------------
# 입력: V=4, E=5, start=1
V, E, start = 4, 5, 1
# [데이터 저장 상태] 간선 정보를 입력받아 만든 인접 행렬의 최종 모습
# (가로세로 0번 인덱스는 사용하지 않으므로 모두 0입니다.)
matrix = [
[0, 0, 0, 0, 0],
[0, 0, 1, 1, 1], # 1번 정점은 2, 3, 4번과 연결됨 (행렬[1][2], [1][3], [1][4]가 1)
[0, 1, 0, 0, 1], # 2번 정점은 1, 4번과 연결됨
[0, 1, 0, 0, 1], # 3번 정점은 1, 4번과 연결됨
[0, 1, 1, 1, 0] # 4번 정점은 1, 2, 3번과 연결됨
]
visited_dfs = [False] * 5
visited_bfs = [False] * 5
# 1. DFS 실행
dfs_matrix(start)
# [DFS 출력 결과]: 1 2 4 3
# 과정: 1방문 -> 1의 연결인 2방문 -> 2의 연결인 4방문 -> 4의 연결 중 남은 3방문
print() # 줄바꿈
# 2. BFS 실행
bfs_matrix(start)
# [BFS 출력 결과]: 1 2 3 4
# 과정: 1방문 -> 1과 직접 연결된 2, 3, 4를 모두 큐에 넣음 -> 큐에서 순서대로 2, 3, 4를 꺼내며 방문import sys
from collections import deque
def dfs_list(v):
visited_dfs[v] = True
print(v, end=' ') # 방문한 정점 출력 (예: 1 -> 2 -> 4 -> 3)
# 개인 연락처에 있는 번호만 꺼내서 확인
for i in graph[v]:
if not visited_dfs[i]:
dfs_list(i)
def bfs_list(start):
queue = deque([start])
visited_bfs[start] = True
while queue:
v = queue.popleft()
print(v, end=' ') # 큐에서 꺼낸 정점 출력 (예: 1 -> 2 -> 3 -> 4)
for i in graph[v]:
if not visited_bfs[i]:
queue.append(i)
visited_bfs[i] = True
# ----------------- 실행 및 결과 -----------------
V, E, start = 4, 5, 1
# [데이터 저장 상태] 간선 정보를 입력받고 정렬(sort)까지 완료된 인접 리스트의 최종 모습
# (0번 인덱스는 비어있습니다.)
graph = [
[],
[2, 3, 4], # 1번 정점의 연락처 (오름차순 정렬됨)
[1, 4], # 2번 정점의 연락처
[1, 4], # 3번 정점의 연락처
[1, 2, 3] # 4번 정점의 연락처
]
visited_dfs = [False] * 5
visited_bfs = [False] * 5
# 1. DFS 실행
dfs_list(start)
# [DFS 출력 결과]: 1 2 4 3
# 과정: 1방문 -> 리스트의 첫 번째인 2방문 -> 2의 리스트 첫 번째인 1은 이미 방문, 다음인 4방문 -> 4의 리스트 중 방문 안 한 3방문
print() # 줄바꿈
# 2. BFS 실행
bfs_list(start)
# [BFS 출력 결과]: 1 2 3 4
# 과정: 1방문 -> 1의 리스트에 있는 2, 3, 4를 모두 큐에 넣음 -> 큐에서 순서대로 2, 3, 4를 꺼내며 출력
안녕하세요.