아주 구차한 변명이지만 2025/11/01 ~ 2026/01월 까지
부트캠프에서 진행한 메인프로젝트 / 합동프로젝트로 인해 매우 바빠서
지속적으로 코딩테스트를 진행하지 못했었음
2026/01/25 ~ 2026/02/09 (2주정도)
2026/01/25
2562
- 첫째 줄부터 아홉 번째 줄까지 한 줄에 하나의 자연수가 주어진다. 주어지는 자연수는 100 보다 작다.
- 첫째 줄에 최댓값을 출력하고, 둘째 줄에 최댓값이 몇 번째 수인지를 출력한다.
li = []
for _ in range(9):
li.append(int(input()))
a=max(li)
print(a)
print(li.index(a)+1)max_value = 0
max_index = 0
for i in range(9):
current_num = int(input())
# 현재 입력받은 숫자가 지금까지의 최댓값보다 크다면?
if current_num > max_value:
max_value = current_num # 최댓값 갱신
max_index = i + 1 # 현재 위치 저장
print(max_value)
print(max_index)2475
- 첫째 줄에 고유번호의 처음 5자리의 숫자들이 빈칸을 사이에 두고 하나씩 주어진다.
- ex. 고유번호의 처음 5자리의 숫자들이 04256이면
- 각 숫자를 제곱한 수들의 합 0+16+4+25+36 = 81 을 10으로 나눈 나머지인 1이 검증수
number = list(map(int, input().split()))
li=[]
for i in number:
a=i*i
li.append(a)
b=sum(li)
print(b%10)[표현식 for 항목 in 반복가능객체]형태
# 리스트 컴프리헨션
# 입력받으면서 동시에 제곱한 리스트를 만듭니다.
numbers = [int(i)**2 for i in input().split()]
# 합산 후 10으로 나눈 나머지 출력
print(sum(numbers) % 10)변수 하나로 합산하기
total = 0
numbers = map(int, input().split())
for n in numbers:
total += n ** 2 # n * n과 같습니다.
print(total % 10)map()을 극한으로 활용하기
ans = sum(map(lambda x: int(x)**2, input().split()))
print(ans % 10)2741
- 자연수 N이 주어졌을 때, 1부터 N까지 한 줄에 하나씩 출력하는 프로그램을 작성
- 첫째 줄에 100,000보다 작거나 같은 자연수 N이 주어진다.
- 첫째 줄부터 N번째 줄 까지 차례대로 출력한다.
n = int(input())
li = list(range(1,n+1))
for i in li:
print(i)메모리 효율화 (리스트 생성 없이 출력)
- range는 숫자를 미리 다 만들어두는 게 아니라,
- 필요할 때마다 하나씩 생성하는 '제너레이터' 역할
- 따라서 리스트를 만들 때보다 메모리를 훨씬 적게 사용
- range는 숫자를 미리 다 만들어두는 게 아니라,
n = int(input())
# 리스트로 변환하지 않고 range 객체를 그대로 사용합니다.
for i in range(1, n + 1):
print(i)속도 최적화
- print()를 번 호출하는 것보다, 큰 문자열 하나를 만들어 딱 한 번 출력하는 것이 훨씬 빠름
- join은 문자열 리스트를 하나로 합쳐주는 함수
- input() 대신 sys.stdin.readline()을 쓰는 습관을 들이는 것이 좋음
import sys
n = int(sys.stdin.readline())
# 모든 숫자를 문자열로 바꿔서 줄바꿈(\n)으로 이어 붙인 뒤 한 번에 출력
print('\n'.join(map(str, range(1, n + 1))))언팩 연산자 활용 (*)
- '언팩(Unpack)'을 사용하면 반복문 없이도 출력이 가능
n = int(input())
# range 안의 숫자들을 하나씩 꺼내서 print에 전달합니다.
# sep='\n'은 숫자들 사이의 구분자를 줄바꿈으로 하겠다는 뜻입니다.
print(*range(1, n + 1), sep='\n')31403

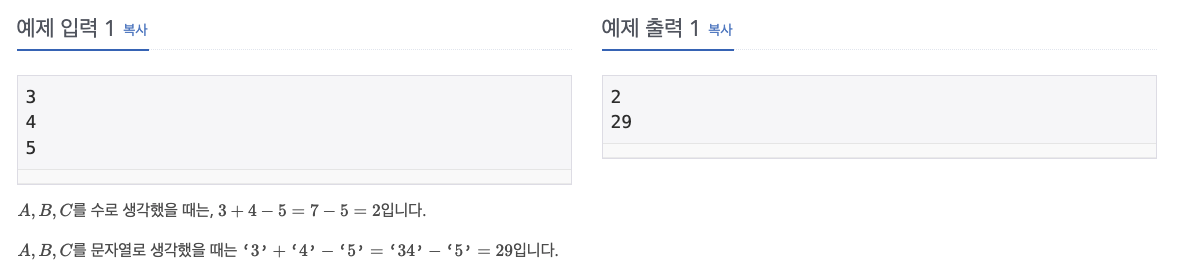
li=[]
for _ in range(3):
a= int(input())
li.append(a)
print(li[0]+li[1]-li[2])
b=str(li[0])
c=str(li[1])
d=str(li[2])
e=int(b+c)
print(e-li[2])변수 할당과 문자열 포매팅
- 처음부터 A, B, C라는 변수에 담으면 가독성이 훨씬 좋아짐
- f-string이나 문자열 더하기를 활용하면 e를 만드는 과정이 단순해짐
# 1. 입력을 변수에 바로 할당
A = input()
B = input()
C = input()
# 첫 번째 결과: 정수로 변환하여 계산
print(int(A) + int(B) - int(C))
# 두 번째 결과: 문자열로 붙인 뒤 정수로 변환하여 계산
# f-string을 쓰면 str(A) + str(B)보다 간결합니다.
combined_AB = int(f"{A}{B}")
print(combined_AB - int(C))한 줄 입력을 활용한 방식
- 문자열끼리는 + 연산자를 쓰면 바로 이어 붙여짐 (예: "10" + "20"은 "1020"이 됨)
- 굳이 f-string을 안 써도 A + B만으로 충분히 효율적
import sys
# 입력을 리스트에 저장 (모두 문자열 상태)
A, B, C = [sys.stdin.readline().strip() for _ in range(3)]
# 정수 계산
print(int(A) + int(B) - int(C))
# 문자열 이어붙이기 후 계산
print(int(A + B) - int(C))2026/01/26
10250(re)
- 프로그램은 표준 입력에서 입력 데이터를 받는다.
- 프로그램의 입력은 T 개의 테스트 데이터로 이루어져 있는데 T 는 입력의 맨 첫 줄에 주어진다.
- 각 테스트 데이터는 한 행으로서 H, W, N, 세 정수를 포함하고 있으며
- 각각 호텔의 층 수, 각 층의 방 수, 몇 번째 손님인지를 나타낸다
- (1 ≤ H, W ≤ 99, 1 ≤ N ≤ H × W)
- ex
# 6 12 10
402호
# 30 50 72
1203t = int(input())
for _ in range(t):
h, w, n = map(int, input().split())
floor = 0
room = 1
while n > h:
n -= h
room += 1
floor = n
print(f"{floor}{room:02d}")import sys
t = int(sys.stdin.readline())
for _ in range(t):
h, w, n = map(int, sys.stdin.readline().split())
# 1. 층수 계산
floor = n % h
# 2. 호수 계산
room = (n // h) + 1
# 예외 처리: n이 h의 배수인 경우 (꼭대기 층)
if floor == 0:
floor = h
room -= 1
# 출력 포맷 지정: :02d는 두 자리 숫자로 만들되 빈칸은 0으로 채움
print(f"{floor}{room:02d}")2577
- 첫째 줄에 A, 둘째 줄에 B, 셋째 줄에 C가 주어진다.
- 첫째 줄에는 A × B × C의 결과에 0 이 몇 번 쓰였는지 출력한다.
- 마찬가지로 둘째 줄부터 열 번째 줄까지 A × B × C의 결과에
- 1부터 9까지의 숫자가 각각 몇 번 쓰였는지 차례로 한 줄에 하나씩 출력
- 마찬가지로 둘째 줄부터 열 번째 줄까지 A × B × C의 결과에
li=[]
for _ in range(3):
a=int(input())
li.append(a)
b=li[0]*li[1]*li[2]
for i in range(0,10):
c=str(b).count(str(i))
print(c)- 방법 1: 산술 연산(Modulo)을 이용한 풀이
A = int(input())
B = int(input())
C = int(input())
result = A * B * C
# 0부터 9까지의 개수를 저장할 리스트 (인덱스 0~9 활용)
counts = [0] * 10
while result > 0:
# 1. 가장 마지막 자릿수(일의 자리)를 구함
digit = result % 10
counts[digit] += 1
# 2. 일의 자리를 제거 (다음 자릿수로 이동)
result //= 10
# 결과 출력
for count in counts:
print(count)- 리스트 인덱스를 활용한 풀이
A = int(input())
B = int(input())
C = int(input())
result_str = str(A * B * C)
counts = [0] * 10
# 숫자를 한 글자씩 확인하며 해당 인덱스의 값을 1 증가
for char in result_str:
counts[int(char)] += 1
for n in counts:
print(n)2920
- 첫째 줄에 8개 숫자가 주어진다. 이 숫자는 문제 설명에서 설명한 음이며, 1부터 8까지 숫자가 한 번씩 등장
- 첫째 줄에 ascending, descending, mixed 중 하나를 출력한다.
number = list(map(int,input().split()))
a = [1,2,3,4,5,6,7,8]
b = [8,7,6,5,4,3,2,1]
if number == a :
print("ascending")
elif number == b:
print("descending")
else:
print("mixed")- sorted() 함수 활용
numbers = list(map(int, input().split()))
if numbers == sorted(numbers):
print("ascending")
elif numbers == sorted(numbers, reverse=True):
print("descending")
else:
print("mixed")- 플래그(Flag) 변수 활용
numbers = list(map(int, input().split()))
ascending = True
descending = True
for i in range(7): # 0부터 6까지 반복 (다음 숫자와 비교하므로)
if numbers[i] < numbers[i+1]:
descending = False
elif numbers[i] > numbers[i+1]:
ascending = False
if ascending:
print("ascending")
elif descending:
print("descending")
else:
print("mixed")8958
- 첫째 줄에 테스트 케이스의 개수가 주어진다.
- 각 테스트 케이스는 한 줄로 이루어져 있고, 길이가 0보다 크고 80보다 작은 문자열이 주어진다.
- 문자열은 O와 X만으로 이루어져 있다.
- 각 테스트 케이스마다 점수를 출력한다.
N = int(input())
for _ in range(N):
a=str(input())
T = 0
C = 0
for i in a:
if i == 'O':
C+=1
T+=C
else:
C=0
print(T)import sys
# 테스트 케이스 개수 입력
n = int(sys.stdin.readline())
for _ in range(n):
ox_list = sys.stdin.readline().strip()
total_score = 0
current_score = 0
for char in ox_list:
if char == 'O':
# 'O'를 만나면 현재 점수를 1 증가시키고 총합에 더함
current_score += 1
total_score += current_score
else:
# 'X'를 만나면 연속 점수를 0으로 초기화
current_score = 0
print(total_score)2026/01/27
4153
- 입력은 여러개의 테스트케이스로 주어지며 마지막줄에는 0 0 0이 입력된다.
- 각 테스트케이스는 모두 30,000보다 작은 양의 정수로 주어지며, 각 입력은 변의 길이를 의미한다.
- 각 입력에 대해 직각 삼각형이 맞다면 "right", 아니라면 "wrong"을 출력한다.
while True:
nums = list(map(int, input().split()))
if sum(nums) == 0:
break
nums.sort()
if nums[0]**2 + nums[1]**2 == nums[2]**2:
print("right")
else:
print("wrong")max() 함수를 이용한 조건문 풀이
while True:
A, B, C = map(int, input().split())
if A == 0 and B == 0 and C == 0:
break
# 세 변 중 가장 긴 변을 찾습니다.
max_side = max(A, B, C)
if max_side == A:
if A**2 == B**2 + C**2: print("right")
else: print("wrong")
elif max_side == B:
if B**2 == A**2 + C**2: print("right")
else: print("wrong")
else: # max_side == C
if C**2 == A**2 + B**2: print("right")
else: print("wrong")2026/01/26
1436
- N은 최대 10,000
- 숫자를 1부터 1씩 더해가며 모든 숫자를 검사해버리는게 나음
- 브루트 포스
def shom(n):
count = 0
num = 666
while True:
if '666' in str(num):
count += 1
if count == n:
return num
num += 1
n = int(input())
print(shom(n))2026/01/29
10814
- 첫째 줄에 온라인 저지 회원의 수 N이 주어진다. (1 ≤ N ≤ 100,000)
- 둘째 줄부터 N개의 줄에는 각 회원의 나이와 이름이 공백으로 구분되어 주어진다.
- 나이는 1보다 크거나 같으며, 200보다 작거나 같은 정수이고, 이름은 알파벳 대소문자로 이루어져 있고,
- 길이가 100보다 작거나 같은 문자열이다. 입력은 가입한 순서로 주어진다.
- 첫째 줄부터 총 N개의 줄에 걸쳐 온라인 저지 회원을 나이 순
- 나이가 같으면 가입한 순으로 한 줄에 한 명씩 나이와 이름을 공백으로 구분해 출력한다.
# input().split()
data = input().split() → ['21', 'Junkyu'] (둘 다 문자열 상태)
age = int(data[0]) → 21 (정수로 변환)
name = data[1] → 'Junkyu' (문자열 그대로 사용)
# 입력 받기
age, name = input().split()
# 나이만 int로 변환
age = int(age)
# 리스트에 튜플 형태로 저장 예시: (21, 'Junkyu')
member_list.append((age, name))import sys
# 테스트를 위해 sys.stdin.readline을 사용하는 것이 좋습니다 (데이터 양이 많을 때)
# input = sys.stdin.readline
def solve():
# 1. 회원 수 입력 받기
n = int(input())
members = []
for _ in range(n):
# 2. 나이와 이름을 공백 기준으로 분리
age, name = input().split()
# 3. 나이는 정수로 변환하여 리스트에 (나이, 이름) 튜플로 저장
members.append((int(age), name))
# 4. 정렬하기
# key=lambda x: x[0] -> 튜플의 첫 번째 요소(나이)만을 기준으로 정렬합니다.
# 파이썬은 안정 정렬이므로, 나이가 같으면 입력 순서(가입 순서)가 유지됩니다.
members.sort(key=lambda x: x[0])
# 5. 출력하기
for member in members:
print(member[0], member[1])
# 실행
solve()import sys
def solve_fast():
# 빠른 입력을 위해 sys.stdin.readline 사용
input_func = sys.stdin.readline
n = int(input_func())
members = []
for _ in range(n):
# 한 줄을 읽고 바로 분리
data = input_func().split()
# data[0]은 나이(int 변환), data[1]은 이름(str 유지)
members.append((int(data[0]), data[1]))
# 정렬: 나이(x[0])를 기준으로 정렬
members.sort(key=lambda x: x[0])
# 출력
for age, name in members:
print(f"{age} {name}")
solve_fast()2026/01/31
1920
- 첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다.
- 다음 줄에는 N개의 정수
A[1], A[2], …, A[N]이 주어진다. - 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데,
- 이 수들이 A안에 존재하는지 알아내면 된다.
- 모든 정수의 범위는 -231 보다 크거나 같고 231보다 작다.
- 다음 줄에는 N개의 정수
- M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
원하는 결과값은 출력하지만 "시간초과" 되어버림
- 원인
- Python 리스트에서 in 연산을 사용하면,
- 최악의 경우 리스트의 처음부터 끝까지 다 훑어야 합니다.
- 이를 선형 탐색(Linear Search)이라고 하며, 시간 복잡도는 입니다.
- Python 리스트에서 in 연산을 사용하면,
- 원인
N = int(input())
li=list(map(int,input().split()))
M = int(input())
li2=list(map(int,input().split()))
for i in range(N):
a = li2[i]
if a in li:
print(1)
else:
print(0) 집합(set) 자료구조를 사용
import sys
input = sys.stdin.read
data = input().split()
N = int(data[0])
li = set(data[1:N+1])
M = int(data[N+1])
li2 = data[N+2:]
for a in li2:
if a in li: # 여기서 걸리는 시간이 O(N)에서 O(1)로 줄어듭니다.
print(1)
else:
print(0)이분 탐색 (Binary Search)
- 원리: 정렬된 데이터에서 중간값을 확인하며 범위를 좁힙니다.
- 시간 복잡도는 입니다.
- 장점: 데이터가 정렬되어 있어야 한다는 조건이 있지만, 매우 효율적입니다.
- 원리: 정렬된 데이터에서 중간값을 확인하며 범위를 좁힙니다.
N = int(input())
li = sorted(list(map(int, input().split()))) # 이분 탐색을 위해 반드시 정렬!
M = int(input())
li2 = list(map(int, input().split()))
for target in li2:
start, end = 0, N - 1
found = False
while start <= end:
mid = (start + end) // 2
if li[mid] == target:
found = True
break
elif li[mid] < target:
start = mid + 1
else:
end = mid - 1
print(1 if found else 0)2026/02/01
1181
N = int(input())
li=[]
for _ in range(N):
li.append(str(input()))
li = list(set(li))
li.sort(key=lambda x: (len(x), x))
for i in li:
print(i)- 팁 1: input() 대신 sys.stdin.read 사용
- 입력값이 최대 20,000개이므로,
- 하나씩 input()으로 받는 것보다 한꺼번에 읽는 것이 훨씬 빠릅니다.
- 팁 2: 처음에 입력받을 때부터 set으로 받기
- 리스트에 다 넣고 나중에 set으로 바꾸는 것보다,
- 처음부터 set에 넣으면 중복 체크를 실시간으로 해서 메모리를 아낄 수 있습니다.
import sys
# 입력을 한 번에 다 읽어서 줄바꿈으로 나눕니다.
input_data = sys.stdin.read().splitlines()
# 첫 번째 값은 N이므로 제외하고, 나머지를 set으로 변환해 중복 제거
n = input_data[0]
words = list(set(input_data[1:]))
# 정렬: 1순위 길이, 2순위 사전순
words.sort(key=lambda x: (len(x), x))
# 한 줄씩 출력
print('\n'.join(words))2026/02/02
10039
li=[]
for _ in range(5):
N=int(input())
if N > 40:
li.append(N)
else:
li.append(40)
print(int(sum(li)/5))리스트 없이 누적 합 구하기
- 특징: 메모리 사용량을 에서 로 줄임.
total = 0 # 합계를 저장할 변수
for _ in range(5):
score = int(input())
# 입력받은 점수와 40 중 큰 값을 바로 더합니다.
total += max(score, 40)
# 정수 나눗셈 연산자 // 를 사용하면 int() 형변환이 필요 없습니다.
print(total // 5)리스트 컴프리헨션 (Pythonic한 방법)
- 코드가 짧고 가독성이 좋음 (파이썬 숙련자들이 선호).
# 5번 반복하며 입력을 받고, max 로직을 적용하여 리스트를 생성
scores = [max(int(input()), 40) for _ in range(5)]
print(sum(scores) // 5)숏코딩 (입력과 출력을 한 번에)
- print(sum(max(int(input()), 40) for _ in range(5)) // 5)
2026/02/03
2750
N = int(input())
li = []
for _ in range(N):
A = int(input())
li.append(A)
li.sort()
for i in li:
print(i)버블 정렬 (Bubble Sort)
N = int(input())
li = []
for _ in range(N):
li.append(int(input()))
# 버블 정렬 구현
for i in range(N):
# 이미 정렬된 뒷부분을 제외하고 반복 (N-i-1)
for j in range(N - i - 1):
if li[j] > li[j+1]: # 앞의 숫자가 뒤의 숫자보다 크다면
li[j], li[j+1] = li[j+1], li[j] # 두 수의 위치를 바꿈 (Swap)
for i in li:
print(i)삽입 정렬 (Insertion Sort)
N = int(input())
li = []
for _ in range(N):
li.append(int(input()))
# 삽입 정렬 구현
for i in range(1, N): # 두 번째 요소부터 시작
key = li[i]
j = i - 1
# key보다 큰 값들은 한 칸씩 뒤로 밀어냄
while j >= 0 and li[j] > key:
li[j + 1] = li[j]
j -= 1
# 적절한 위치에 key 삽입
li[j + 1] = key
for i in li:
print(i)2026/02/04
- 100문제 / 실버4 - 48포인트
2587
- 다섯 개의 자연수가 주어질 때 이들의 평균과 중앙값을 구하는 프로그램을 작성하시오.
li=[]
for _ in range(5):
N = int(input())
li.append(N)
li.sort()
print(int(sum(li)/5))
print(li[2])
개선
- 입력 처리
- input()보다 sys.stdin.readline이 대량의 데이터 처리 시 훨씬 빠름
- 리스트 컴프리헨션
- for 문을 한 줄로 줄일 수 있음
- 연산자
- int(sum(li)/5) 대신 정수 나눗셈 연산자 //를 사용하면 형변환(int()) 과정을 생략 가능
- 입력 처리
import sys
# 1. 리스트 컴프리헨션으로 입력 간소화
# sys.stdin.readline을 사용하여 입력 속도 향상
li = [int(sys.stdin.readline()) for _ in range(5)]
li.sort()
# 2. 정수 나눗셈 연산자(//) 사용
print(sum(li) // 5)
print(li[2])Statistics 모듈 사용
import sys
import statistics # 통계 모듈
li = [int(sys.stdin.readline()) for _ in range(5)]
# 별도의 정렬 코드 없이 함수 사용
print(statistics.mean(li)) # 평균
print(statistics.median(li)) # 중앙값25305
N,k = map(int,input().split())
li=list(map(int,input().split()))
li.sort(reverse=True)
print(li[k-1])2026/02/05
2751
import sys
input = sys.stdin.readline
N = int(input())
li=[]
for _ in range(N):
A = int(input())
li.append(A)
li.sort()
for i in li:
print(i)내장 정렬 + 출력 최적화 (추천 방법)
import sys
# 입력 속도 최적화
input = sys.stdin.readline
def solve_optimized():
try:
line = input()
if not line:
return
N = int(line)
li = []
for _ in range(N):
li.append(int(input()))
# 1. 정렬 (Timsort: O(N log N))
li.sort()
# 2. 출력 최적화
# 리스트의 각 요소를 문자열로 변환하고, 개행문자(\n)로 합칩니다.
# 이렇게 하면 print 함수를 100만 번 호출하는 대신 1번만 호출하게 됩니다.
print('\n'.join(map(str, li)))
except ValueError:
pass
if __name__ == "__main__":
solve_optimized()병합 정렬 (Merge Sort) 구현
import sys
input = sys.stdin.readline
def merge_sort(arr):
if len(arr) < 2:
return arr
mid = len(arr) // 2
low_arr = merge_sort(arr[:mid])
high_arr = merge_sort(arr[mid:])
merged_arr = []
l = h = 0
# 두 리스트(low, high)를 비교하며 작은 값을 순서대로 병합
while l < len(low_arr) and h < len(high_arr):
if low_arr[l] < high_arr[h]:
merged_arr.append(low_arr[l])
l += 1
else:
merged_arr.append(high_arr[h])
h += 1
# 남은 요소들 추가
merged_arr += low_arr[l:]
merged_arr += high_arr[h:]
return merged_arr
def solve_merge():
try:
N = int(input())
li = [int(input()) for _ in range(N)]
sorted_li = merge_sort(li)
print('\n'.join(map(str, sorted_li)))
except:
pass
# 실행 시에는 solve_merge()를 호출
# 참고: 파이썬(CPython)에서는 이 구현이 내장 sort보다 느려 시간 초과가 날 수도 있습니다.
# 알고리즘 학습용으로 참고해주세요.2026/02/06
11650
파이썬의 기본 정렬 기능 활용 (가장 추천)
import sys
# 1. 입력 속도를 높이기 위해 sys.stdin.readline 사용
input = sys.stdin.readline
def solve():
# 2. 점의 개수 N 입력 받기
try:
line = input().strip()
if not line:
return # 입력이 없는 경우 처리
n = int(line)
except ValueError:
return
points = []
# 3. N개의 좌표를 입력받아 리스트에 저장
for _ in range(n):
# map을 이용해 공백으로 구분된 두 수를 정수로 변환하여 리스트에 추가
x, y = map(int, input().split())
points.append((x, y))
# 4. 정렬 수행 (핵심!)
# 파이썬의 기본 sort는 튜플의 첫 번째 요소를 먼저 비교하고,
# 같으면 두 번째 요소를 비교합니다.
points.sort()
# 5. 결과 출력
for x, y in points:
print(f"{x} {y}")
if __name__ == "__main__":
solve()lambda를 이용한 명시적 정렬 기준 설정
import sys
input = sys.stdin.readline
def solve_explicit():
try:
line = input().strip()
if not line: return
n = int(line)
except ValueError: return
points = []
for _ in range(n):
x, y = map(int, input().split())
points.append((x, y))
# 핵심 부분: key를 사용하여 정렬 기준을 명시
# "x[0](x좌표)를 기준으로 먼저 정렬하고, 그 다음 x[1](y좌표)를 기준으로 정렬하라"
points.sort(key=lambda x: (x[0], x[1]))
for x, y in points:
print(f"{x} {y}")
if __name__ == "__main__":
solve_explicit()- sort는 리스트로 정렬해도 앞에먼저 정렬 해주고 뒤에도 정렬해줌
import sys
input = sys.stdin.readline # 빠른 입력을 위해 사용 권장
N = int(input())
points = [] # 하나의 리스트만 만듭니다.
for _ in range(N):
A, B = map(int, input().split())
points.append([A, B]) # x, y를 묶어서 하나의 덩어리로 넣습니다.
# 이렇게 정렬하면 파이썬이 알아서
# 1. 첫 번째 값(x)을 비교하고
# 2. x가 같으면 두 번째 값(y)을 비교해서 정렬해줍니다.
points.sort()
for i in range(N):
print(points[i][0], points[i][1])2026/02/07
11651
- 문제 이해하기
- y좌표 오름차순 정렬
- y좌표가 동일할 경우, x좌표 오름차순 정렬
- y좌표 오름차순 정렬
- 파이썬의 내장 함수인 sort와 lambda 식을 활용
import sys
input = sys.stdin.readline
N = int(input())
li = []
for _ in range(N):
A,B = map(int,input().split())
li.append([A,B])
li.sort(key=lambda point: (point[1], point[0]))
for A,B in li:
print(A,B)- 입력 시 순서를 뒤집어 저장하는 방법
import sys
input = sys.stdin.readline
N = int(input())
points = []
for _ in range(N):
x, y = map(int, input().split())
# y를 먼저 고려해야 하므로, [y, x] 순서로 리스트에 넣습니다.
points.append([y, x])
# 파이썬의 기본 sort는 첫 번째 요소(y)를 비교하고, 같으면 두 번째 요소(x)를 비교합니다.
# 따라서 별도의 key 없이 그냥 정렬하면 문제의 조건과 일치합니다.
points.sort()
# 출력할 때는 다시 원래 순서인 x, y로 출력해야 하므로 순서를 바꿔줍니다.
for y, x in points:
print(x, y)2026/02/08
2869
- (반복문): - 최악의 경우 매우 느림 (오답)
A, B, V = map(int, input().split())
current_height = 0
day = 0
while True:
day += 1
current_height += A # 낮에 올라감
if current_height >= V: # 정상 도달 확인
break
current_height -= B # 밤에 미끄러짐
print(day)(수학): - 입력값의 크기와 상관없이 즉시 계산
import sys
import math
# A: 낮, B: 밤, V: 목표
A, B, V = map(int, sys.stdin.readline().split())
# 1. 마지막 날 낮에 올라갈 거리(A)를 미리 뺍니다.
target_height = V - A
# 2. 하루에 실질적으로 올라가는 거리
daily_climb = A - B
# 3. target_height까지 며칠이 걸리는지 계산합니다.
# 나누어 떨어지지 않으면 하루가 더 필요한 것이므로 올림(ceil)을 합니다.
days_needed = math.ceil(target_height / daily_climb)
# 4. 마지막 날 하루(+1)를 더해줍니다.
print(days_needed + 1)import sys
import math
A, B, V = map(int, sys.stdin.readline().split())
H = V - A
D = A - B
R = math.ceil(H/D)
print(R + 1)2026/02/09
10872
팩토리얼
- 0보다 크거나 같은 정수 N이 주어진다. 이때, N!을 출력하는 프로그램을 작성하시오.
1676
- (N 팩토리얼)을 계산했을 때, 결과값의 뒤에서부터 이어지는 0의 개수를 구하는 것입니다.
- 소인수 5의 개수만 세면 그것이 곧 만들 수 있는 10(2×5)의 개수, 즉 0의 개수
N = int(input())
result = 1
for i in range(1, N + 1):
result *= i
print(result)재귀함수
N = int(input())
def factorial(n):
if n <= 1:
return 1
return n * factorial(n - 1)
print(factorial(N))
안녕하세요.