😂 Django Project
😭 Machine Learning part
- pandas dataframe에서 불필요 부분 제외
- 데이터셋을 kaggle에서 다운로드 받은 뒤 압축을 해제해 우리의 프로젝트에 사용할 데이터만을 남겨서 사용하기 위해 먼저
column 기준으로 불필요 부분을 제외하기로 하였다. - 데이터셋 사용
- 해당 데이터셋을 압축 해제하면 두 가지의 데이터셋이 나오게 되는데, 그 중
credits.csv는 확인해보니 우리의 프로젝트에 크게 필요없다고 판단해 사용하지 않았다.
- 해당 데이터셋을 압축 해제하면 두 가지의 데이터셋이 나오게 되는데, 그 중
import os
os.environ['KAGGLE_USERNAME'] = 'username'
os.environ['KAGGLE_KEY'] = 'key'
import pandas as pd
import numpy as np
!kaggle datasets download -d victorsoeiro/netflix-tv-shows-and-movies
!unzip netflix-tv-shows-and-movies.zip
titles = pd.read_csv('titles.csv')
titles.head(20)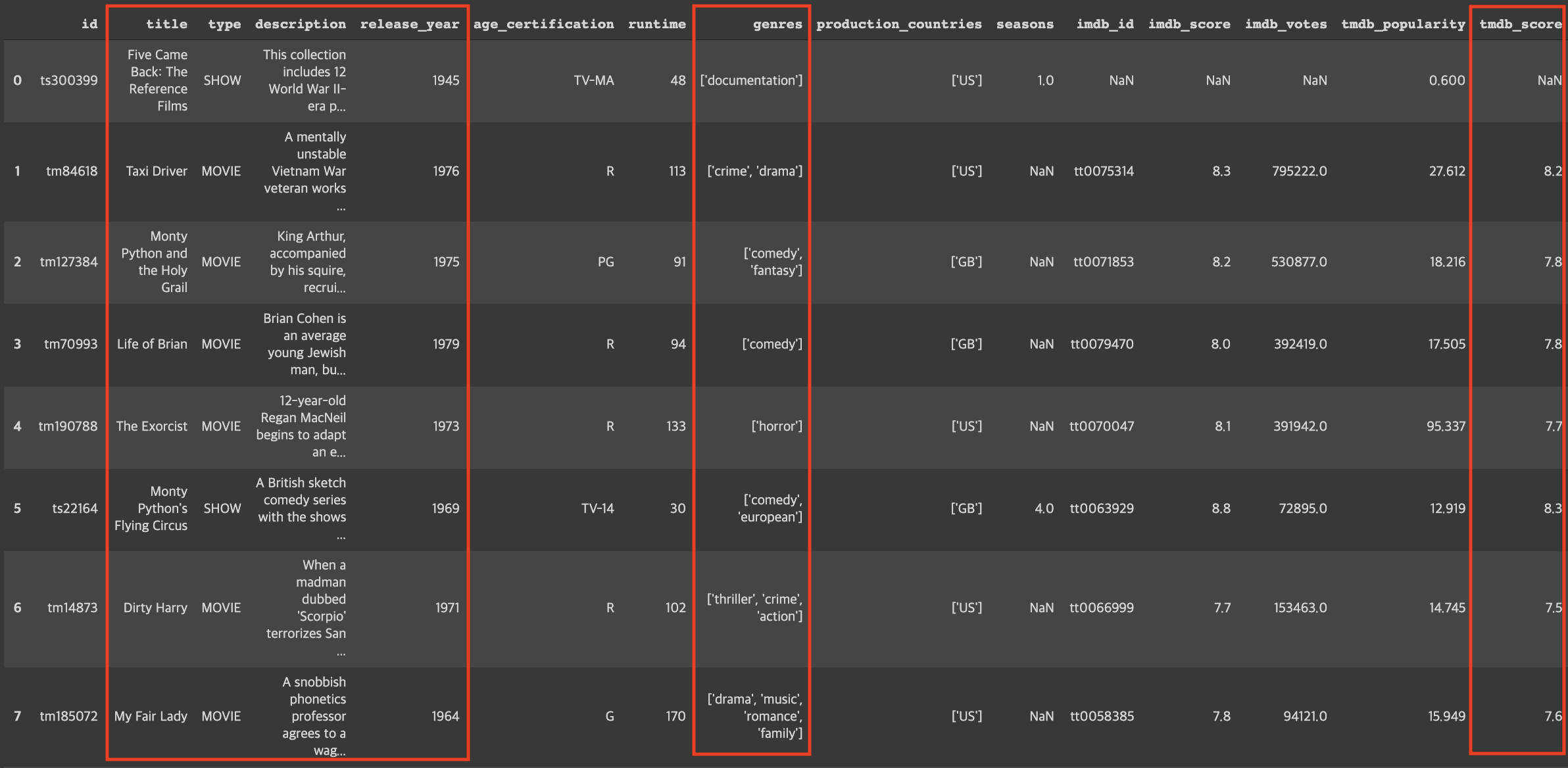
- 불필요 부분 제외
- 불필요한 부분을 제외하기 위해
pandas.DataFrame.drop을 사용하였다. - 기본 형태
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise') - 각 파라미터의 뜻

참조 문서 : pandas 공식 문서
- 위의 기본형 중에서 나의 상황에 맞다고 생각하는 부분을 가져다 사용하였다.
titles.drop(columns=['id', 'age_certification', 'runtime', 'production_countries', 'seasons', 'imdb_id', 'imdb_score', 'imdb_votes', 'tmdb_popularity'], axis=1)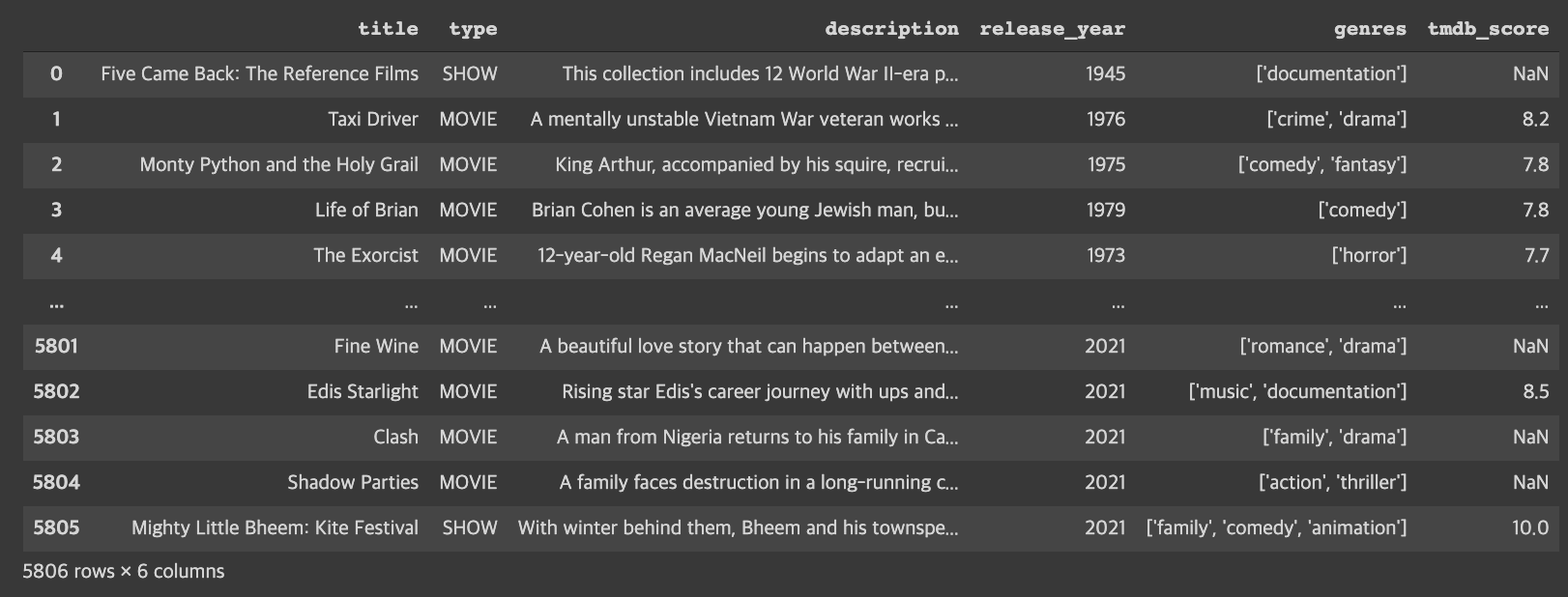
- 하지만
NaN타입을 0으로 바꾸려pandas.Dataframe.fillna(0)을 시도하자 테이블이 원상태로 돌아가버렸다. - 그래서 빼는거말고 필요한거만 가져다 쓰는 방식을 사용해 보았고, 내가 원하는 테이블을 만들 수 있었다.
title_data = titles[titles['type']=='MOVIE'][['title', 'type', 'description', 'release_year', 'genres', 'tmdb_score']] title_data.fillna(0, inplace=True) title_data
- 불필요한 부분을 제외하기 위해
- 유저 기반 협업 필터링
- 위의 데이터를 가지고 하고 싶었는데, 내가 배운 내용을 보니 사용자의 평점이 있는
ratings가 있어야 했다. 우리의 데이터셋에는 해당 영화를 찍은 배우 혹은 감독의 정보가 있는 것 같다. - 그래서 놀고 있을 순 없어 배운 내용을 통해 직접
유저 기반 협업 필터링을 진행해 보았다. - 먼저 필요한 모듈을 임포트하고 데이터셋을 가져와 어떤 데이터가 있는지 확인해 보았다.
- 아래의 결과를 보면 영화의 고유 아이디를 기준으로 잡아
해당 영화에 어떤 유저가 얼마나 평점을 주었는지확인할 수 있다. 또한 영화의장르를 볼 수 있다.
- 아래의 결과를 보면 영화의 고유 아이디를 기준으로 잡아
import pandas as pd
import numpy as np
ratings = pd.read_csv('ratings.csv')
movies = pd.read_csv('movies.csv')
# ratings와 movies를 movieId를 기준으로 조인한거라 생각하면 됨
movie_ratings = pd.merge(ratings, movies, on='movieId')
movie_ratings.head(20)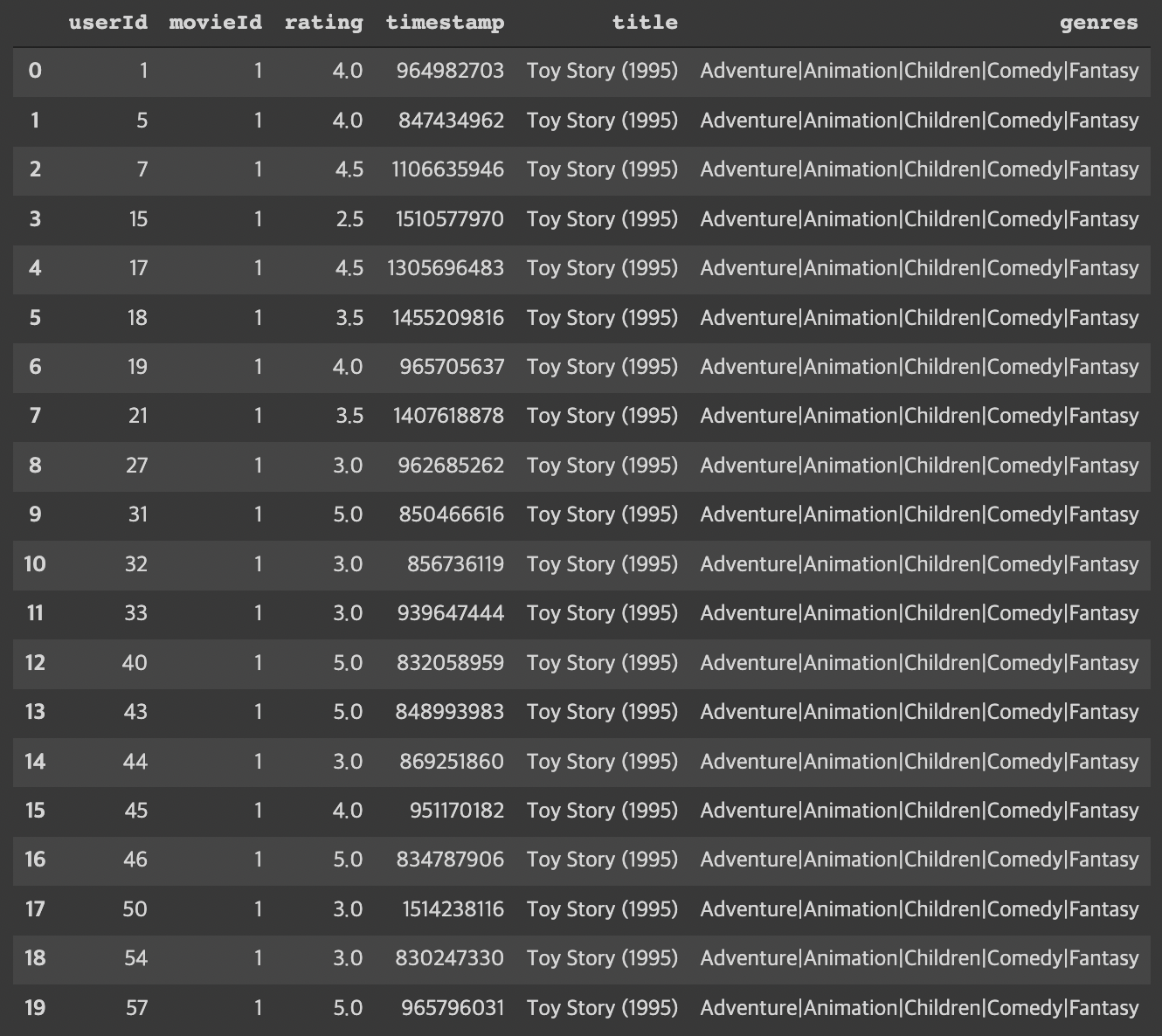
title_user라는 변수에 각 열의 기준을 사용자의 아이디, 컬럼의 기준을 영화 제목으로 잡은 피벗 테이블을 만들어 저장하였다. 또한NaN 값을 모두 0으로 처리하였다.
title_user = movie_ratings.pivot_table('rating', index='userId', columns='title')
title_user = title_user.fillna(0)
print(title_user)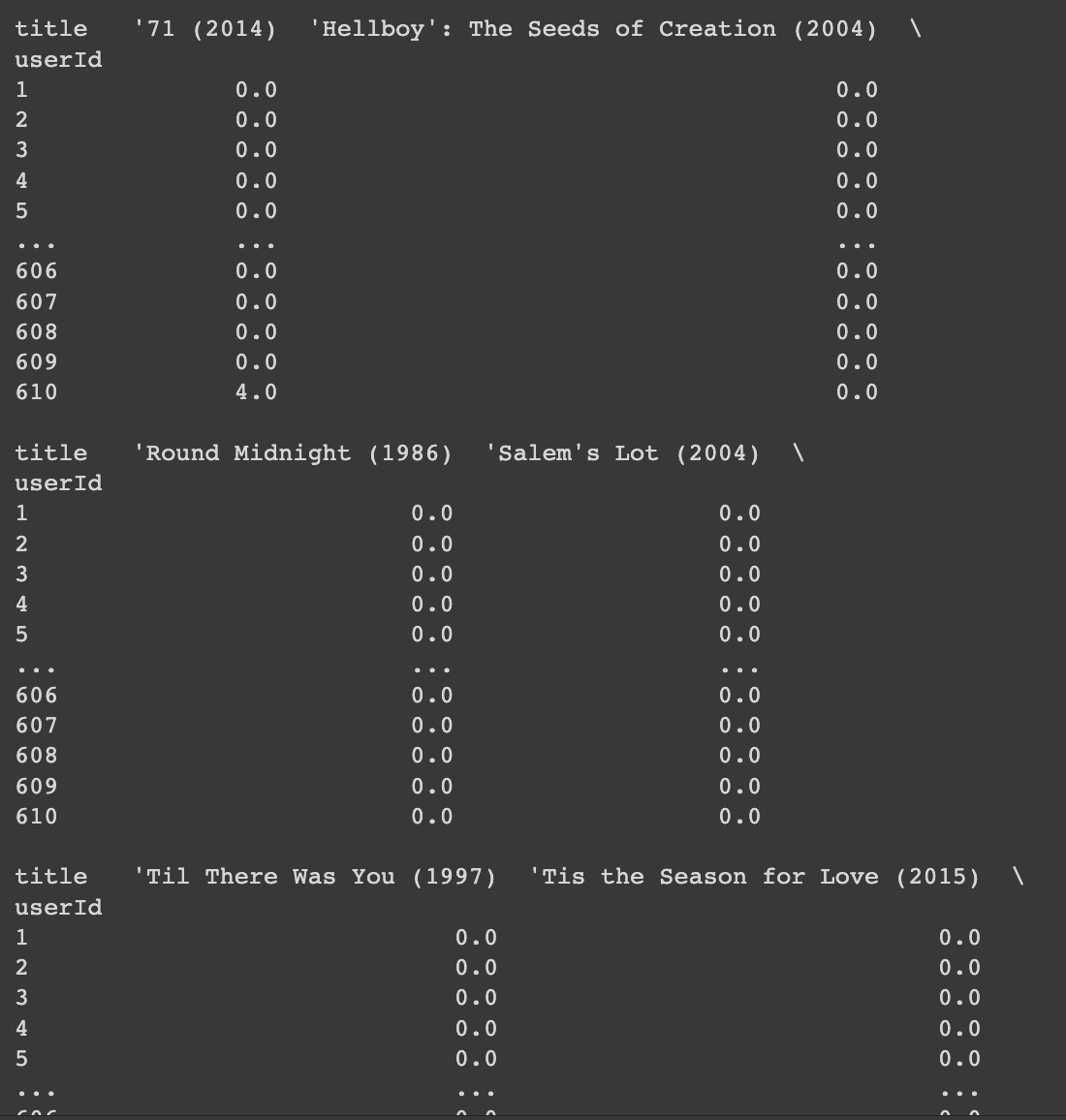
cosine similarity를 구하기 전에 의미를 짚고 넘어가보도록 하겠다.
cosine similarity를 구해 보았다. 우리는 1에 유사한 코사인 유사도를 원한다. 엄청 많이.- 처음 구하게 되면 넘파이 배열로 출력된다. 필터링에 해당 데이터를 사용하려면 데이터프레임으로 만들어주어야 한다.
- 구조를 보면 공학수학에서 많이 봐왔던
단위 행렬과 유사하다. 따라서 데칼코마니처럼1로 이루어진 대각선을 기준으로양쪽의 값이 똑같다.
from sklearn.metrics.pairwise import cosine_similarity
user_based_collab = cosine_similarity(title_user, title_user)
print(user_based_collab)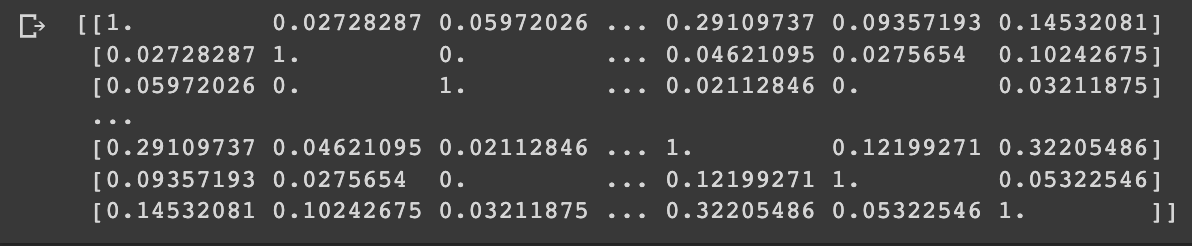
- 위의 넘파이 행렬을 데이터프레임화 해주었다.
user_based_collab = pd.DataFrame(user_based_collab, index=title_user.index, columns=title_user.index)
print(user_based_collab)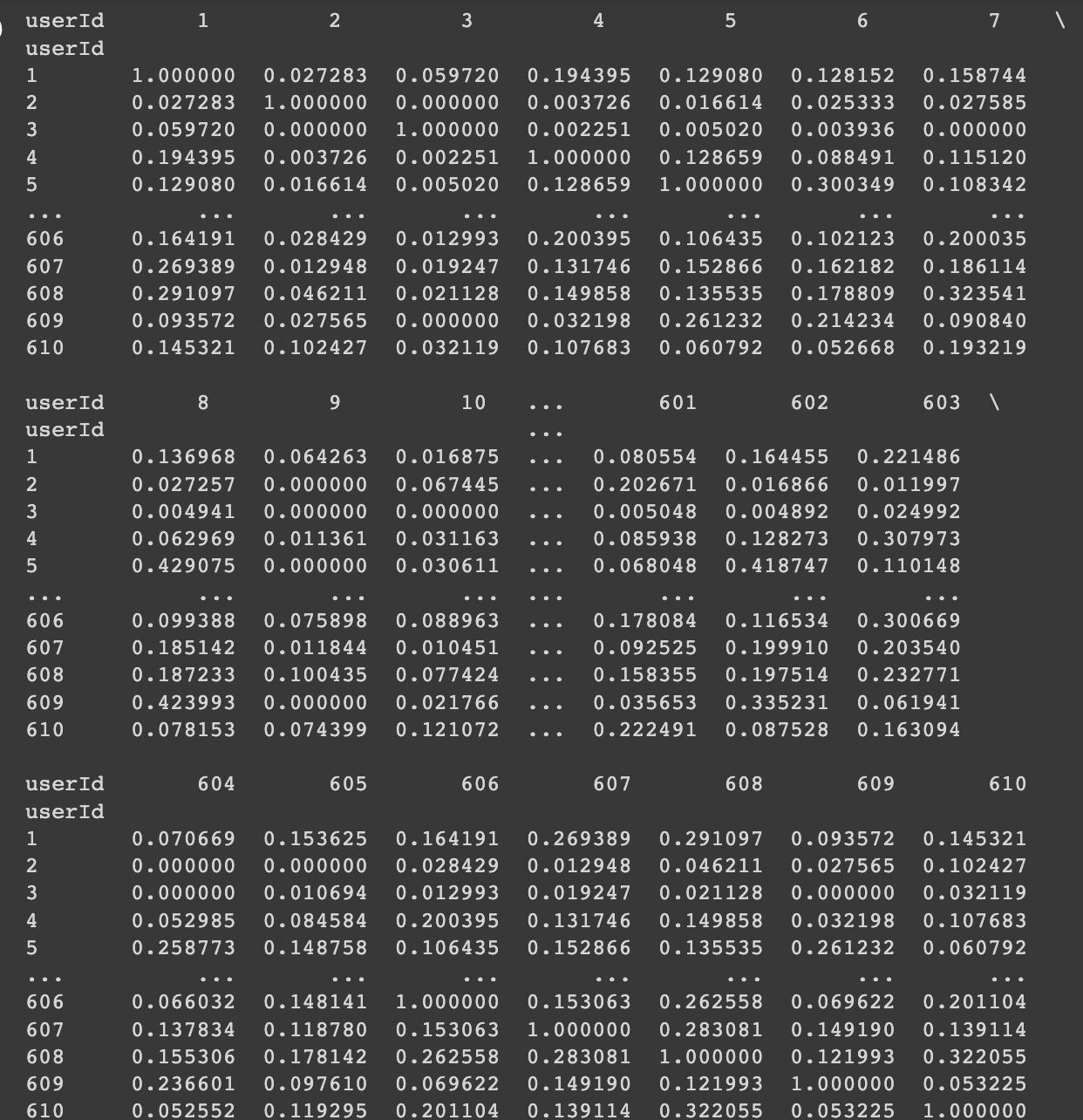
- 이제 위의 데이터프레임을 바탕으로 내가 선택한 유저와 코사인 유사도의 값이 높은 유저들을 뽑아보겠다.
# 610명 중에서 5번 유저와 가장 유사한 사람은 470번 유저다.
chosen_user = user_based_collab[5].sort_values(ascending=False)[:10]
print(chosen_user)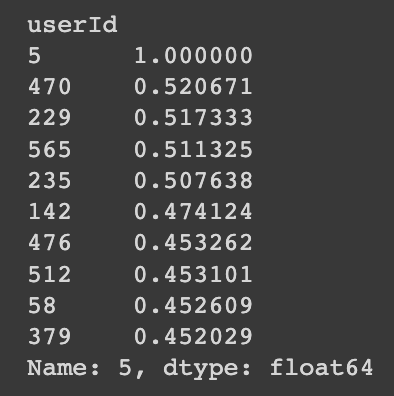
- 여기서의
chosen_user는 위에 나온 5번 유저와 유사도 값이 가장 비슷한 470번 유저다.- 해당 유저의 id를 쿼리에 넣어 값들을 정렬하는데, 그 값들의 정렬 순서는 역순이다. 행의 기준은
chosen_user이고 열들은 영화 제목이 나오게 된다. - 쉽게 생각하면 맨 위에서 구했던
title_user는 모든 유저의 평점이 다 나왔는데 여기서는 딱 470번 유저의 값만 나오게 되는 것이다.
- 해당 유저의 id를 쿼리에 넣어 값들을 정렬하는데, 그 값들의 정렬 순서는 역순이다. 행의 기준은
chosen_user = user_based_collab[5].sort_values(ascending=False)[:10].index[1]
result = title_user.query(f'userId == {chosen_user}').sort_values(ascending=False, by=chosen_user, axis=1)
print(result)
- list화 작업을 진행한다.
# 기준 유저인 5번 유저와 유사한 순서를 나타냄(아까 위에서 10명 맨 처음에 뽑은 그 값을 다시 뽑아서 리스트로 만든거임)
user_index_list = user_based_collab[5].sort_values(ascending=False)[:10].index.tolist()
# 이거는 위와 똑같은데 순서가 아닌 가중치를 리스트화한거임
user_weight_list = user_based_collab[5].sort_values(ascending=False)[:10].tolist()
print(user_index_list)
print(user_weight_list)
- 이제 영화 하나를 찝어주고, 우리가 만든 모델에게 5번 유저가 얼마의 평점을 줄것인지 예측하게 한다.
- 여기서 시간을 많이 소비하게 되었다. 헬보이를 보니 중학생때가 기억나 헬보이를 넣어봤는 데,
weighted_sum이랑weighted_user에 아무 값도 들어가지 않아devision by zero에러가 났었다. - 내가 잘못한줄 알고 코드를 진짜 한 시간가량 뚫어지게 쳐다보다가 질문을 하게 되었는데, 하면서
아 값이 없을수도 있지 참이라는 생각이 들었다. - 해당 모델은 기준 유저와 비슷한 유저들이 평점을 입력하지 않았다면 평생 기준 유저의 평점을 예측하지는 못한다.
- 여기서 시간을 많이 소비하게 되었다. 헬보이를 보니 중학생때가 기억나 헬보이를 넣어봤는 데,
movie_title = "Batman Forever (1995)"
weighted_sum = []
weighted_user = []
# 0번은 자기 자신이니까 1번부터 10번까지 돌리는거야!
for i in range(1, 10):
value = title_user[movie_title][user_index_list[i]]
print(value)
if int(value) is not 0:
# 5번 유저랑 유사한 사람들이 단 평점에다가 그 사람들의 위에 있는 가중치를 곱한 값
weighted_sum.append(title_user[movie_title][user_index_list[i]] * user_weight_list[i])
# user_weight_list를 다시 한 번 만드는것과 같다.
weighted_user.append(user_weight_list[i])
print(weighted_sum)
print(weighted_user)
print(sum(weighted_sum)/sum(weighted_user))😂 Time Attack
😭 카테고리 속 음료 제시
- Django를 사용해 타임어택 진행
- 제한 시간 내에 거의 다 푼 유일한 타임어택이었다. 화면에 출력만 하면 되는 상황에서 시간이 끝나 그 뒤로 조금만 더 손보고 완성하였다.
- 사진도 넣을 생각이기 때문에 django에서의 이미지 처리를 질문을 드려 어떻게 처리할지 구상해 놓았다.
- django 부분
- 프로젝트에 필요한 app인
product생성
$ django-admin startapp product- 그 후,
timeattack_0603/settings.py에서 생성한 app 등록
#### 상단 생략 ####
INSTALLED_APPS = [
'product',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
#### 하단 생략 ####http://127.0.0.1:8000/으로 들어가 우주선이 잘 나오나 확인- 우주선이 잘 나오면 에러가 없는 것이므로 행복한 마음을 가지고 app에서 사용할 model을 만들러
product/models.py로 이동- 튜터님은 이 부분을 아예
class로 만드셨다. 아래 모델을 빠르게 만들고 흐뭇해 했었는데 역시 난 미개했다.ㅋ - 여기서 주의깊게 볼 부분은
Category와Drink의 관계이다.Drink가Category의 category를 외래키로 가져다 쓰고 있다. - django를 한지 얼마 안되긴 했지만, 완전 초반에는 외래키를 제공하는 모델을 제일 하단에 만들고 '왜 안돼' 한 적도 있었다. 처음이라면 주의해야 한다. 생각없이 치다 시간 날릴 수 있다.
- 튜터님은 이 부분을 아예
from django.db import models
# Create your models here.
class Category(models.Model):
class Meta:
db_table = 'category'
category = models.CharField(max_length=50)
class Drink(models.Model):
class Meta:
db_table = 'drink'
drink = models.CharField(max_length=50)
category = models.ForeignKey(Category, on_delete=models.CASCADE)
# url은 글씨로 저장
# image = models.CharField(max_length=200)- 모델을 만들었으니
product/admin.py로 등록하러 가겠다.
from django.contrib import admin
from .models import Category, Drink
# Register your models here.
admin.site.register(Category)
admin.site.register(Drink)- 모델도 다 생성하였으니 조건에 맞게
url, views, html을 설정하면 된다. 여기서 순서는 딱히 없으나 나는timeattack_0603/urls.py와product/urls.py를 먼저 설정하도록 하겠다. timeattack_0603/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('product.urls')),
]product/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('show/', views.category_view, name="category"),
]- 자연스럽게
views.category_view에 눈이 가므로views.py를 작성하러 가보겠다.- 바로 다음에서 볼 수 있겠지만 나는
html의input의 name값을 cate에 있는 키값과 같이 정하였고,POST통신이 이루어질 때 해당 키값이 가지고 있는 value 값을 가지고 바로 Category db에서 아이디 값을 찾기를 원했다. - 해당 이유로 딕셔너리를 생성했고, 키값과 name 이 일치하면 바로 조건문 안으로 타고 들어가 id를 찾도록 했다. 그리고 바로 Drink db에서 조건에 해당하는 음료들을
filter기능을 통해 찾아내었고, 프론트로 보내주었다. - 곧 이미지 처리도 진행할 것인데 추가적으로 진행할 작업이 없다는 것이 좋다.
- 바로 다음에서 볼 수 있겠지만 나는
from django.shortcuts import render, redirect
from .models import Category, Drink
def category_view(request):
if request.method == 'GET':
return render(request, 'choose.html')
elif request.method == 'POST':
cate = {'cold': '콜드 브루 커피', 'brewed': '브루드 커피', 'espre': '에스프레소'}
if request.POST.get('cold'):
category = Category.objects.get(category=cate['cold']).id
drink = Drink.objects.filter(category_id=category)
elif request.POST.get('brewed'):
category = Category.objects.get(category=cate['brewed']).id
drink = Drink.objects.filter(category_id=category)
else:
category = Category.objects.get(category=cate['espre']).id
drink = Drink.objects.filter(category_id=category)
return render(request, 'drink.html', {'drinks': drink})- html 부분
- 이제 html들을 보도록 하겠다.
- 나는 이번에 원격 강의에서 배운
template 문법을 사용해 html들을 연결했다. 보기만 하다가 직접 코딩을 통해 만들어보니 신기하고 추가적으로 딴 것을 안해도 되어 너무 좋다.
- 나는 이번에 원격 강의에서 배운
<!-- choose.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form method="post">
{% csrf_token %}
<div>
<input type="checkbox" name="cold"/>
<label for="cold">콜드 브루 커피</label>
</div>
<div>
<input type="checkbox" name="brewed"/>
<label for="brewed">브루드 커피</label>
</div>
<div>
<input type="checkbox" name="espre"/>
<label for="espre">에스프레소</label>
</div>
<button type="submit">선택</button>
</form>
{% block content %}
{% endblock %}
</body>
</html>- 원래는 맨 앞에 if 조건문을 쓰지 않았었는데, 쓰지 않는다면 아무 짓도 안했는데 결과값들이 화면에 뜨게 되어 다음과 같이 세팅하였다.
<!-- drink.html -->
{% extends 'choose.html' %}
{% block content %}
{% if drinks %}
{% for drink in drinks %}
<p>{{ drink.drink }}</p>
{% endfor %}
{% endif %}
{% endblock %}
https://github.com/nikevapormax