LinkdeList의 경우 ArrayList와 가장 큰 차이점은 '노드'라는 객체를 이용하여 연결한다는 것이다.
ArrayList의 경우 최상위 타입인 오브젝트 배열(Object[])을 사용하여 데이터를 담아두었다면
LinkedList는 배열을 이용하는 것이 아닌 하나의 객체를 두고 그 안에 데이터와 다른 노드를 가리키는 레퍼런스 데이터로 구성하여 여러 노드를 하나의 체인처럼 연결하는 것이다
데이터와 다른 노드를 가리킬 주소 데이터를 담을 객체가 필요한데 우리는 이것을 노드(node)라고 부른다,
node가 가장 기초적 단위라고 생각하자
리스트는 노드(엘리먼트)들의 모임이다. 따라서 내부적으로 노드를 가지고 있어야한다
ArrayList의 경우 엘리먼트가 배열의 엘리먼트였지만 LinkedList는 배열 대신에 다른 구조를 사용해야 한다
노드는 최소한 두가지 정보를 알고있어야 하는데, 노드의 값과 다음 노드이다.
각각의 노드가 다음 노드를 알고 있기 때문에 하나의 연결된 값의 모임을 만들 수 있다
사용자가 저장할 데이터는 data변수에 담기고, reference데이터(참조 데이터)는 다음에 연결할 노드를 가리키는 데이터가 담긴다,
이렇게 노드들이 여러개가 연결되어 있는 것을 연결리스트, 즉 LinkedList라고 한다
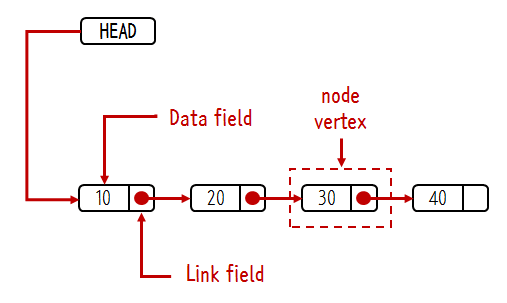
자바같은 객체지향 언어라면 객체에 데이터 필드와 링크 필드를 만든다.
보통 데이터 필드는 value라는 이름의 변수, 링크 필드는 next 변수를 사용한다.
value에는 노드의 값이 저장되고 next에는 다음 노드의 포인터나 참조값을 저장해서 노드와 노드를 연결시키는 방법을 사용한다.
리스트를 하나의 건물로 비유하자만 출입문에 해당하는 것이 head이다. linked list를 사용하기 위해서는 이 head가 가리키는 첫번째 노드를 찾아야 한다.
array list와 linked list의 핵심적인 차이점은
배열의 경우는 엘리먼트를 중간에 추가/삭제할 경우 해당 엘리먼트의 뒤에 있는 모든 엘리먼트의 자리 이동이 필요하다. 그래서 배열은 추가/삭제가 느리다
반대로 linked list의 경우 추가/삭제가 될 엘리먼트의 이전,이후 노드의 참조값(next)만 변경하면 되기때문에 속도가 빠르다.
인덱스를 이용해서 데이터를 조회할 때 linked list는 head가 가리키는 노드부터 시작해서 순차적으로 노드를 찾아가는 과정을 거쳐야 한다. 만약 찾고자 하는 엘리먼트가 가장 끝에 있다면 모든 노드를 탐색해야 한다.
반면에 array를 이용해서 리스트를 구현하면 인덱스를 이용해서 해당 엘리먼트에 바로 접근할 수 있기 때문에 매우 빠르다.
= array list는 추가/삭제가 느리지만 인덱스 조회는 빠르다 / linked list는 추가 삭제는 빠르지만 인덱스 조회는 느리다
LinkedList에서 가장 중요한 것은 노드의 구현이다. 노드는 실제로 데이터가 저장되는 그릇과 같은 것이기 때문에 이것부터 구현을 시작한다.
자바는 객체지향언어이기 때문에 노드는 객체로 만들기 좋은 대상이다. 그리고 노드 객체는 리스트의 내부 부품이기 때문에 외부에는 노출되지 않는 것이 좋기 때문에 private로 지정한다.
사용자는 이 객체에 대해서 알 필요가 없다.
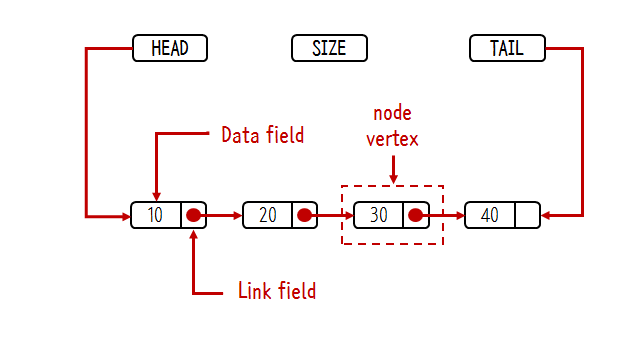
head는 첫번째 노드를 지정하는 참조값이다. tail은 꼬리라는 뜻으로 마지막 노드를 지정한다
size는 노드의 크기를 의미한다. 노드를 변경할 때마다 이 값들을 수정해야한다.
tail이나 size는 마지막 노드를 찾거나 노드의 수를 셀 때 연산의 횟수를 획기적으로 줄여준다.
객체 Node는 내부적으로 data와 next변수를 가지고 있다. data는 노드의 값이고 next는 다음 노드를 기리키는 참조값이다.
public class LinkedList {
// 첫번째 노드를 가리키는 필드
private Node head;
// 노드의 마지막 부분
private Node tail;
// 리스트에 있는 요소의 개수(=연결 된 노드의 개수)
// 처음 생성할 때는 아무런 데이터가 없으므로 head와 tail이 가리킬 노드가 없기 때문에 0으로 초기화
private int size = 0;
private class Node {
// 데이터가 저장될 필드
private Object data;
// 다음 노드를 가리키는 필드
private Node next;
// 생성자
public Node(Object input){
this.data = input;
this.next = null;
}
// 노드의 내용을 쉽게 출력해서 확인해 볼 수 있는 기능
public String toString(){
return String.valueOf(this.data);
}
}[데이터 추가]
1. 시작에 추가 > addFirst(Object input)
2. 마지막에 추가 > addLast(Object inpur)
3. 중간에 추가 > add(int k,Object input)
[1. 시작에 추가]
// 처음에 추가
public void addFirst(Object input){
// 노드 생성
Node newNode = new Node(input);
// 새로운 노드의 다음 노드로 헤드 지정
newNode.next = head;
// 헤드로 새로운 노드 지정
head = newNode;
size++;
if(head.next == null){
tail = head;
}
}[2. 마지막에 추가]
// 마지막에 추가
public void addLast(Object input){
// 노드 생성
Node newNode = new Node(input);
// 리스트의 노드가 없다면 첫번째 노드를 추가하는 메소드 사용
if(size == 0){
addFirst(input);
}else {
// 마지막 노드의 다음 노드로 생성노드 지정
tail.next = newNode;
// 마지막 노드 갱신
tail = newNode;
// 엘리먼트 갯수 1 증가
size++;
}
}리스트의 끝에 데이터를 추가할때는 tail을 이용한다. tail이 없이도 구현이 가능하지만 없다면 마지막 노드를 찾아야한다. 리스트의 끝에 데이터를 추가하는 작업은 자주있는 일이고, 마지막 노드를 찾는 작업은 첫 노드부터 마지막 노드까지 순차적으로 탐색해야하기 때문에 최악의 상황이다.
[특정 위치의 노드 찾기]
// 특정 위치의 노드를 찾아내기
Node node(int index){
Node x = head;
for (int i = 0; i < index; i++)
x = x.next;
return x;
}[3. 중간에 노드 추가]
// 중간에 노드 추가
public void add(int k, Object input){
// 만약 k가 0이라면 첫번째 노드에 추가하는 것이기때문에 addFirst 사용
if(k==0){
addFirst(input);
}else {
Node temp1 = node(k-1);
// k번째 노드를 temp2로 지정
Node temp2 = temp1.next;
// 새로운 노드 생성
Node newNode = new Node(input);
// temp1의 다음 노드로 새로운 노드 지정
temp1.next = newNode;
// 새로운 노드의 다음 노드로 temp2지정
newNode = temp2.next;
size++;
// 새로운 노드의 다음 노드가 없다면 마지막 노드이기 때문에 tail로 지정
if(newNode.next == null){
tail = newNode;
}
}
}[데이터가 제대로 추가되는지 확인]
LinkedList의 toString메소드 사용
// 데이터가 제대로 추가되고 있는지 확인
public String toString(){
// 노드가 없다면 [] 리턴
if(head == null){
return "[]";
}
// 탐색 시작
Node temp = head;
String str = "[";
// 다음 노드가 없을 때 까지 반복문 실행
// 마지막 노드는 다음 노드가 없기 때문에 아래의 구문은 마지막 노드 제외
while(temp.next != null){
str += temp.data + ",";
temp = temp.next;
}
// 마지막 노드를 출력결과에 포함
str += temp.data;
return str+"]";
}여기서 data는 Object로 데이터가 저장될 필드 변수
[삭제]
// 첫번째 삭제
public Object removeFirst(){
// 첫번째 노드를 temp로 지정하고 head의 값을 두번째 노드로 변경
Node temp = head;
head = temp.next;
// 데이터를 삭제하기 전에 리턴할 값을 임시 변수에 담는다
Object returnData = temp.data;
temp = null;
size--;
return returnData;
}
// 중간의 데이터 삭제
public Object remove(int k){
if(k==0) return removeFirst();
// k-1번째 노드를 temp의 값으로 지정
Node temp = node(k-1);
// 삭제 노드를 todoDeleted에 기록
// 삭제 노드를 지금 제거하면 삭제 앞 노드와 삭제 뒤 노드를 연결할 수 없다
Node todoDeleted = temp.next;
// 삭제 앞 노드의 다음 노드로 삭제 뒤 노드를 지정
temp.next = temp.next.next;
// 삭제된 데이터를 리턴하기위해 returnData에 데이터를 저장
Object returnData = todoDeleted.data;
if(todoDeleted == tail) {
tail = temp;
}
// cur.next 삭제
todoDeleted = null;
size--;
return returnData;
}
// 마지막 데이터 삭제
public Object removeLast(){
return remove(size-1);
}[엘리먼트의 크기]
내부적으로 size라는 값을 유지하고 있기 때문에 이 값을 돌려주기만 하면 된다
// 엘리먼트의 크기
public int size(){
return size;
}[엘리먼트 가져오기]
// 엘리먼트 가져오기
public Object get(int k){
Node temp = node(k);
return temp.data;
}[탐색]
특정한 값을 가진 인덱스의 값을 알아내는 방법
값이 있다면 그 값이 발견되는 첫번째 인덱스를 리턴하고
값이 없다면 -1을 리턴한다
// 일정한 값을 가진 엘리먼트의 인덱스 값을 알아내는 방법
public int indexOf(Object data){
// 탐색 대상이 되는 노드를 temp로 지정한다
Node temp = head;
// 탐색 대상이 몇번째 엘리먼트에 있는지를 의미하는 변수로 index사용
int index = 0;
// 모든 노드를 순회할땐 while문을 사용할 수 있다
// 탐색 값과 탐색 대상의 값을 비교한다
while(temp.data != data){ // 맞지않다면 계속 탐색
temp = temp.next;
index++;
//temp의 값이 null이라는 것은 더 이상 탐색 대상이 없다는 것을 의미. 이때 -1 리턴
if(temp == null)
return -1;
}
// 탐색 대상을 찾았다면 대상의 인덱스 값을 리턴
return index;
}[반복]
ArrayList와 다르게 LinkedList에서 get은 효율적이지 않다
get을 호출할 때마다 내부적으로는 반복문이 실행되는데 이런 경우 Iterator을 사용하는 것이 유리하다
Iterator은 내부적으로 반복 처리된 노드가 무엇인지에 대한 정보를 유지하고 있다.
nextIndex;
ListIterator(){
next = head;
}
// next()메소드를 호출하면 next의 참조값이 기존 next.next로 변경된
public Object next() {
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.data;
}
public boolean hasNext() {
// size가 nextIndex보다 같거나 크면 리턴할 값이 없다
return nextIndex < size();
}
public void remove() {
// 아무런 엘리먼트도 선택하지 않은 상태
if(nextIndex==0){
throw new IllegalStateException();
}
LinkedList.this.remove(nextIndex-1);
nextIndex--;
}
public void add(Object input) {
Node newNode = new Node(input);
// 처음 위치에 노드 추가
if(lastReturned == null){
head = newNode;
newNode.next = next;
} else { // 중간 위치에 노드 추가
lastReturned.next = newNode;
newNode.next = next;
}
lastReturned = newNode;
nextIndex++;
size++;
}
}참고링크
