doubly linked list의 핵심은 노드와 노드가 서로 연결되어 있다는 점이다
단순 연결리스트(linked list)와는 다르게 노드가 이전노드(previous)와 다음 노드(next)로 구성되어있다
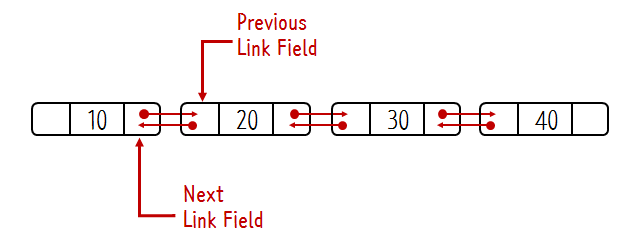
이것의 가장 큰 장점은 양방향으로 연결되어 있기 때문에 노드를 탐색하는 방향이 양쪽으로 가능하다는 것이다
[장점]
양방향 탐색의 가장 큰 장점은 특정 인덱스 위치의 엘리먼트를 가져올 때와 반복자를 이용해서 탐색할때 드러난다
[인덱스의 데이터 가져오기]
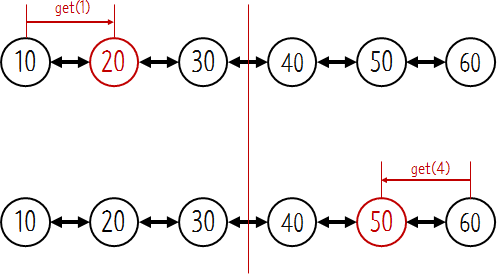
그림처럼 노드가 6개일 때 3번째 엘리먼트 이전은 처음부터 시작해서 next를 이용해서 탐색하고, 4번째 이후의 엘리먼트는 마지막 노드부터 previous를 이용해서 조회한다. 단순 연결 리스트가 최악의 경우 노드 전체를 탐색해야 했던 것에 비해서 양방향 연결 리스트는 탐색해야하는 엘리먼트가 반으로 줄어든다
[노드 탐색하기]
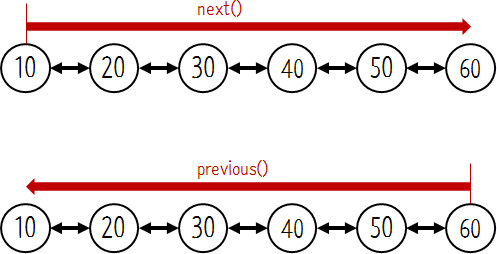
단방향 연결 리스트는 다음 노드의 탐색만 가능했던 것에 비해서 이중 연결 리스트의 경우 앞뒤로 탐색이 가능하다. 상황에 따라 탐색의 방향이 바뀌어야 하는 경우라면 이중 연결 리스트를 사용한다
[단점]
이전 노드를 지정하기 위한 변수를 하나 더 사용해야 한다. 이것은 메모리를 더 많이 사용해야 한다는 의미인데 구현이 조금 더 복잡해진다는 단점도 있다.
하지만 장점이 크기 때문에 현실에서 사용하는 연결 리스트는 대부분 이중 연결 리스트이다
[노드의 추가]
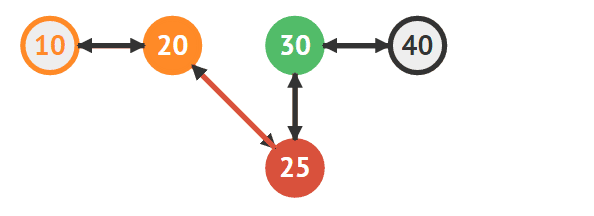
단순 연결 리스트와 거의 비슷하지만 중요한 차이점은 양방향으로 연결을 해야 한다는 점이다. 새로운 노드(25)를 기존의 노드(20,30)와 연결하는 방법을 먼저 살펴볼 것이다
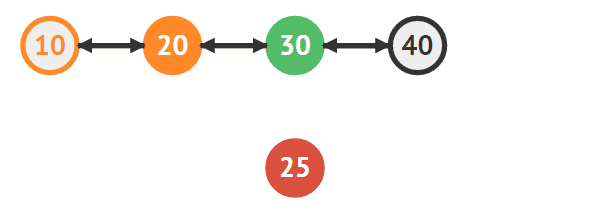
25의 다음 노드로 30을 연결한다
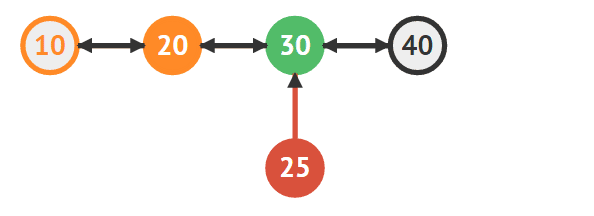
30의 이전 노드로 25를 연결한다
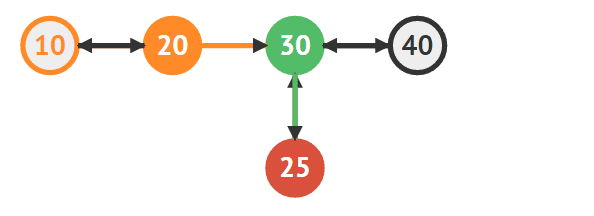
20의 다음 노드로 25를 지정한다
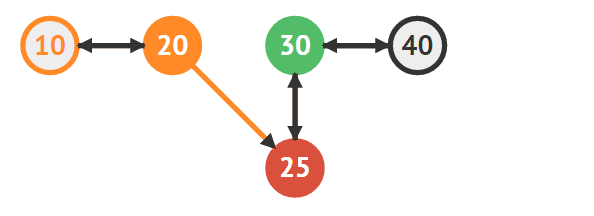
25의 이전 노드로 20을 지정한다

[노드의 제거]
노드를 제거하는 방법도 거의 비슷하다
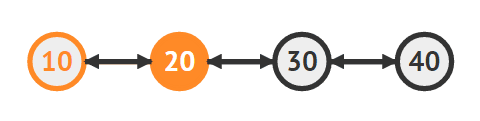
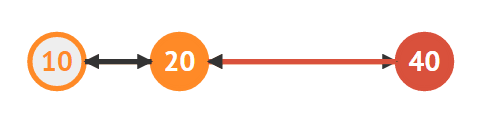
삭제하려는 노드의 이전 노드(20)을 찾는다
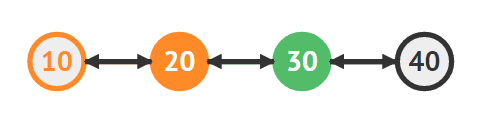
삭제하려는 노드(30)도 찾는다
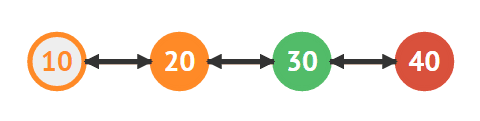
삭제하려는 노드의 다음 노드(40)도 찾는다

30을 삭제한다
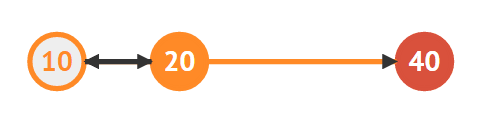
20의 다음 노드로 40을 지정한다
40의 이전 노드로 20을 저장한다
차이점을 중심으로 이해하기
prev = next와 같이 노드 데이터 타입을 가지고 있다
[클래스]
public class DoublyLinkedList {
// 첫번째 노드를 가리키는 필드
private Node head;
// 노드의 마지막 부분
private Node tail;
// 리스트에 있는 요소의 개수(=연결 된 노드의 개수)
// 처음 생성할 때는 아무런 데이터가 없으므로 head와 tail이 가리킬 노드가 없기 때문에 0으로 초기화
private int size = 0;[노드]
private class Node {
// 데이터가 저장될 필드
private Object data;
// 다음 노드를 가리키는 필드
private Node next;
private Node prev;
// 생성자
public Node(Object input){
this.data = input;
this.next = null;
this.prev = null;
}
// 노드의 내용을 쉽게 출력해서 확인해 볼 수 있는 기능
public String toString(){
return String.valueOf(this.data);
}
}[시작 위치에 추가]
// 처음에 추가
public void addFirst(Object input){
// 노드 생성
Node newNode = new Node(input);
// 새로운 노드의 다음 노드로 헤드 지정
newNode.next = head;
// 기존에 노드가 있었다면 현재 헤드의 이전 노드로 새로운 노드 지정
if(head!=null)
head.prev = newNode;
// 헤드로 새로운 노드 지정
head = newNode;
size++;
if(head.next == null){
tail = head;
}
}head앞에 새로운 노드가 위치하게 되기 때문에 head의 이전 값으로 새로운 노드를 지정하는 부분이 추가 되었다
[마지막에 추가]
// 마지막에 추가
public void addLast(Object input){
// 노드 생성
Node newNode = new Node(input);
// 리스트의 노드가 없다면 첫번째 노드를 추가하는 메소드 사용
if(size == 0){
addFirst(input);
}else {
// 마지막 노드의 다음 노드로 생성노드 지정
tail.next = newNode;
// 새로운 노드의 이전 노드로 tail을 지정
newNode.prev = tail;
// 마지막 노드 갱신
tail = newNode;
// 엘리먼트 갯수 1 증가
size++;
}
}[특정 위치에 추가]
// 중간에 노드 추가
public void add(int k, Object input){
// 만약 k가 0이라면 첫번째 노드에 추가하는 것이기때문에 addFirst 사용
if(k==0){
addFirst(input);
}else {
Node temp1 = node(k-1);
// k번째 노드를 temp2로 지정
Node temp2 = temp1.next;
// 새로운 노드 생성
Node newNode = new Node(input);
// temp1의 다음 노드로 새로운 노드 지정
temp1.next = newNode;
// 새로운 노드의 다음 노드로 temp2지정
newNode.next = temp2;
// temp2의 이전 노드로 새로운 노드 지정
if(temp2!=null){
temp2.prev = newNode;
}
// 새로운 노드의 이전 노드로 temp1 지정
newNode.prev = temp1;
size++;
// 새로운 노드의 다음 노드가 없다면 마지막 노드이기 때문에 tail로 지정
if(newNode.next == null){
tail = newNode;
}
}
}temp1을 지정라는 로직이 node(k-1)로 변경되었다.
노트 탐색 작업이 빈번한 작업이기때문에 별도의 메소드로 분리시켰다.
그 외의 코드 변화는 앞 뒤노드를 연결해주는것과 관련되어있다
[노드 찾기]
// 특정 위치의 노드를 찾아내기. search라고 생각
Node node(int index) {
// 노드의 인덱스가 전체 노드 수의 반보다 큰지 작은지 계산
// head부터 탐색
if (index < size / 2) { // 사이즈를 반으로 나눠서 각각 탐색
Node x = head;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// tail부터 prev를 이용해서 인덱스에 해당하는 노드를 찾는다
Node x = tail;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}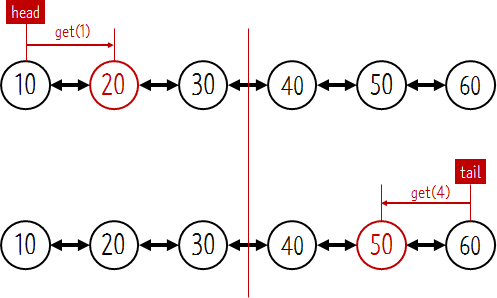
위의 그림과 같이 리스트의 노드가 6개라고 했을 때 get의 인자로 전달된 인덱스가 2(30의 인덱스)이하라면 head부터 next를 이용해서 탐색을 한다. 인덱스가 3이상이라면 tail부터 prev를 이용해서 탐색을 할 수 있다. 즉 인덱스의 위치에 따라서 탐색방향을 달리 할 수 있다. 덕분에 탐색 시간을 두배로 향상시킬 수 있다. 이것이 양방향으로 연결했을 때의 효율이다
[삭제]
// 첫번째 삭제
public Object removeFirst(){
// 첫번째 노드를 temp로 지정하고 head의 값을 두번째 노드로 변경
Node temp = head;
head = temp.next;
// 데이터를 삭제하기 전에 리턴할 값을 임시 변수에 담는다
Object returnData = temp.data;
temp = null;
if(head != null){
head.prev = null;
}
size--;
return returnData;
}
// 중간의 데이터 삭제
public Object remove(int k){
if(k==0) return removeFirst();
// k-1번째 노드를 temp의 값으로 지정
Node temp = node(k-1);
// 삭제 노드를 todoDeleted에 기록
// 삭제 노드를 지금 제거하면 삭제 앞 노드와 삭제 뒤 노드를 연결할 수 없다
Node todoDeleted = temp.next;
// 삭제 앞 노드의 다음 노드로 삭제 뒤 노드를 지정
temp.next = temp.next.next;
if(temp.next!=null)
// 삭제한 노드의 전후 노드 연
temp.next.prev = temp;
// 삭제된 데이터를 리턴하기위해 returnData에 데이터를 저장
Object returnData = todoDeleted.data;
if(todoDeleted == tail) {
// 삭제된 노드가 tail이였다면 이전 노드를 tail로 지정
tail = temp;
}
// cur.next 삭제
todoDeleted = null;
size--;
return returnData;
}
// 마지막 데이터 삭제
public Object removeLast(){
return remove(size-1);
}removeFirst는 가장 앞에 있는 요소를 제거한다. temp가 가리키는 요소만 없애면 된다
temp를 head로 지정하고 head를 두번째 값으로 지정한다. returnData에 temp의 데이터를 담고 삭제한다
remove(int k)메소드는 사용자가 원하는 특정위치를 리스트에서 찾아서 삭제한다.
삭제하려는 노드의 이전노드의 next변수를 삭제하려는 노드의 다음노드를 가리키도록 설정한다
반복
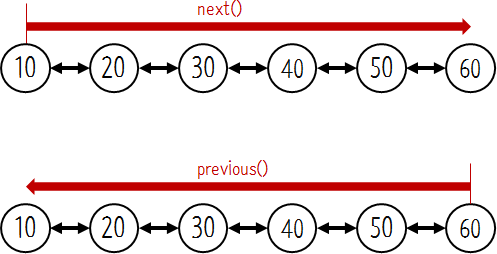
반복자(iterator)을 이용해서 순차적으로 노드를 탐색을 반복한다. doubly linked list는 탐색 방향을 자유롭게 변경할 수 있다.
Next는 다음번 리턴할 노드를 가르키도 lastReturned는 마지막으로 리턴된 노드를 가리킨다. lastReturned는 next를 한칸 뒤에서 따라다닌다. nextIndex는 next를 호출했을 때 다음번 리턴될 노드의 인덱스 값을 의미한다
// 반복작업. 반복자를 생성해서 리턴해준다
public ListIterator listIterator() {
return new ListIterator();
}
public class ListIterator{
// 다음번 리턴할 노드를 가리킨다
private Node next;
// 마지막으로 리턴된 노드를 가리킨다. next를 한칸 뒤에서 따라다닌다
private Node lastReturned;
// next를 호출했을 때 다음번 리턴될 노드의 인덱스 값
private int nextIndex;
ListIterator(){
next = head;
nextIndex = 0;
}
// next()메소드를 호출하면 next의 참조값이 기존 next.next로 변경된다
public Object next() {
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.data;
}
// previous를 호출해도되는지, 이전 노드가 남아있는지 확인하는 메소드
public boolean hasPrevious(){
// 0보다 크다면 이전 노드를 가져올 수 있다
return nextIndex > 0;
}
public Object previous(){
if(next == null){
lastReturned = next = tail;
}else{
lastReturned = next = next.prev;
}
nextIndex--;
return lastReturned.data;
}
// cursor의 값이 없다면 다시 말해서 더 이상 next를 통해서 가져올 노드가 없다면 falsefmf flxjs
// 이를 통해서 next를 호출해도 되는지를 사전에 판단할 수 있다
public boolean hasNext() {
// size가 nextIndex보다 같거나 크면 리턴할 값이 없다
return nextIndex < size();
}[추가,삭제]
public void remove() {
// 아무런 엘리먼트도 선택하지 않은 상태
if(nextIndex==0){ // lastReturned == null
throw new IllegalStateException();
}
Node n = lastReturned.next;
Node p = lastReturned.prev;
if(p==null) { // p가 존재하지 않는다면
head = n;
head.prev = null;
lastReturned = null;
} else {
p.next = next; // 현재 next가 가리키고 있는 노드이다
lastReturned.prev = null; // 더이상 가리킬 필요가 없기 때문에 null
}
if (n == null) {
// tail은 마지막 노드를 가리켜야한다
tail = p;
tail.next = null;
}else {
// p가 가리키고 있는 노드가 next 여야함
n.prev = p;
}
if (next == null) {
lastReturned = tail;
}else {
// 중간노드를 삭제해야하니까 lastReturned가 next의 이전노드
lastReturned = next.prev;
}
size--;
nextIndex--;
}
public void add(Object input) {
Node newNode = new Node(input);
// 처음 위치에 노드 추가
if(lastReturned == null){ // next()를 한번도 실행하지 않은 상태. 첫번째 노드를 리턴하지 않은 상
head = newNode;
newNode.next = next;
} else { // 중간 위치에 노드 추가
lastReturned.next = newNode;
newNode.prev = lastReturned;
if(next != null){
newNode.next = next;
next.prev = newNode;
}else{
tail = newNode;
}
}
lastReturned = newNode;
nextIndex++;
size++;
}
}
}