Stack은 말 그대로 '~을 쌓다'라는 의미다
책을 쌓았을때 가장 먼저 놓은 책은 맨 아래 있을 것이고, 가장 나중에 놓은 책은 맨 위에 있을 때
책을 치운다하면 맨 위에 있는 책 먼저 빼게 된다
이렇게 먼저 들어온 데이터가 마지막에 나가는 구조를 후입선출(LIFO: Last in First out)또는 선입후출(FILO : First in Last out)이라고 한다
스택오버플로우에러는 재귀가 깊어지면서 발생한다
이는 메소드를 호출할 때마다 메소드 내에 정의된 변수들의 값이 stack 메모리에 쌓이게 되는데 재귀가 깊어지면 stack 메모리에 이 값들이 쌓이면서 해당 총량이 할당 된 메모리 양보다 커질때 발생한다
자바 내부에서는 스택은 Vector 클래스를 상속받아 사용한다. Vector 자료구조는 ArrayList와 크게 다르지 않다. 내부 구조는 Object[] 배열로 데이터들을 관리하며 전체적인 메소드 구조 또한 많이 유사하다. 다만 차이점은 동기화를 지원하냐 안하냐의 여부인데, ArrayList에서는 동기화를 지원하지 않고, Vector에서는 동기화를 지원한다. 그렇다보니 속도 자체는 ArrayList가 조금 더 빠르지만, Thread safe하지 않다.
쉽게 생각해서 멀티스레드 환경에서는 Vector를, 아닐 경우 ArrayList를 쓰는 것이 현명하다
[Stack의 활용]
1. 페이지 뒤로가기
2. 실행 취소
3. 수식 괄호 검사
4. 역순 문자열 만들기
5. 후위 표기법 계산
6. 재귀 알고리즘
- 재귀적으로 함수를 호출해야하는 경우에 임시 테이터를 스택에 넣어준다
- 재귀함수를 빠져나와 퇴각 검색을 할 때는 스택에 넣어두었던 임시 데이터를 빼줘야한다
- 스택은 이런 일련의 행위를 직관적으로 가능하게 해준다
- 스택은 재귀 알고리즘을 반복적 형태(iterative)를 통해서 구현할 수 있게 한다
<Stack Interface에 선언된 대표적인 메소드>
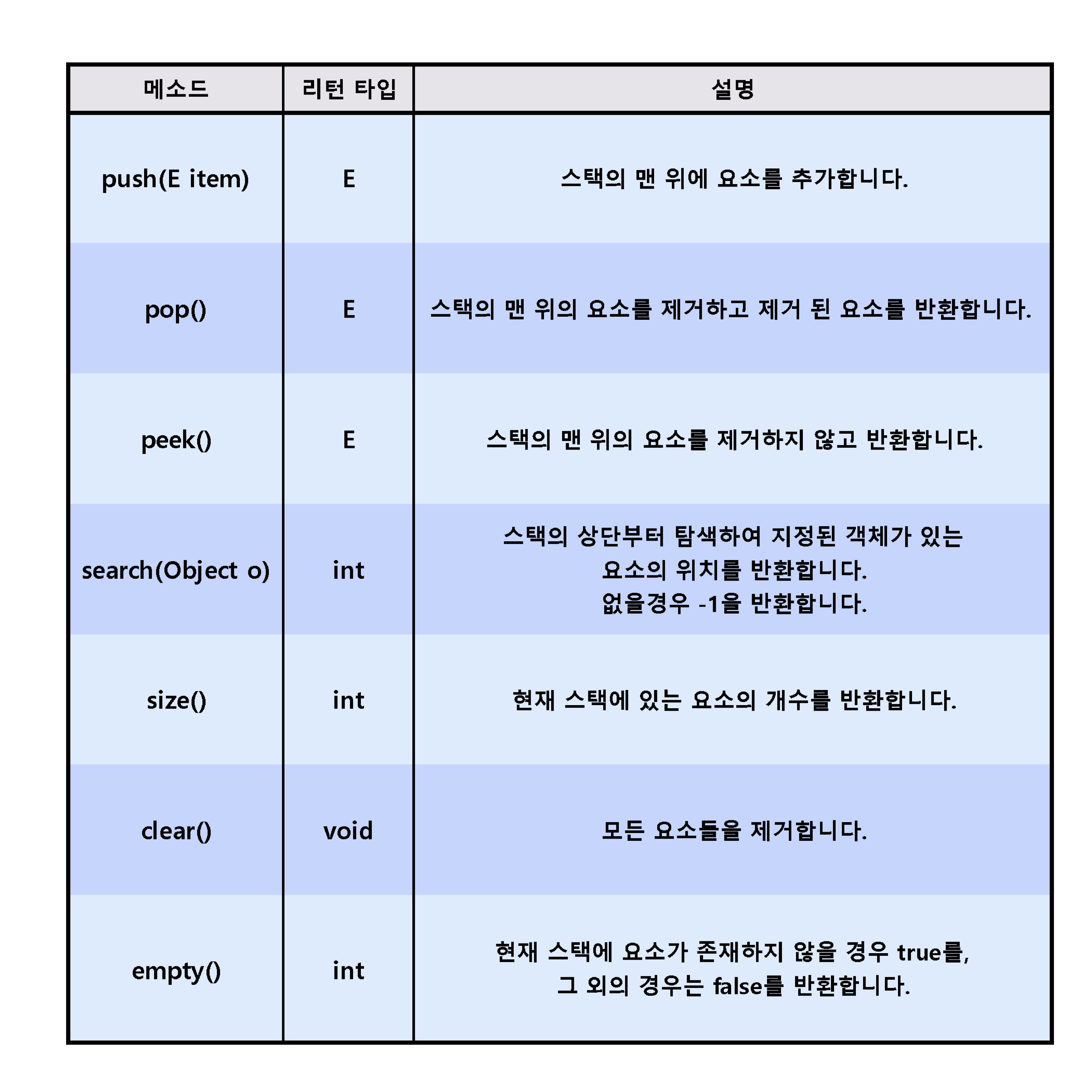
search() 메소드는 스택 내부 배열의 인덱스 값이 아니라 스택의 '상단으로부터 몇 번째에 위치하는지'를 반환한다. 즉 거리개념이라고 생각하면 된다.
자바에서는 Vector 클래스를 상속받다보니 위의 클래스보다 훨씬 많은 메소드를 지원한다.
Vector 클래스에 있는 메소드 + 위에서 선언된 메소드를 합쳐야 한다.
데이터를 추가하는 작업을 push 라고 한다 (리스트에서의 add와 같은 역할)
데이터를 삭제하는 작업을 pop 라고한다 (리스트에서의 remove와 같은 역할)
- 삭제 pop() : 스택에서 가장 위에 있는 항목을 제거하고 해당 item을 반환한다. 마지막 데이터 위치에서 삭제된다. top의 위치는 -1이 된다
- 삽입 push(E item) : item 하나를 스택의 가장 윗 부분에 추가한다. Vector의 addElement(item)과 동일하다. 스택의 구조 상 마지막 데이터 위치에 삽입된다. 코딩 시 마지막 데이터 위치를 기억하기 위해 top이라는 변수를 만든다. 삽입시 top는 +1이 된다
- 읽기 peek() : 스택의 가장 위(마지막)에 있는 항목을 반환한다. top의 변화는 없다
- isEmpty() : 스택이 비어있을 때 true를 반환한다
push는 데이터를 기존의 리스트와 같은 메커니즘으로 인덱스가 증가하면서 추가하지만, 삭제는 리스트와는 달리 '가장 마지막 데이터'를 삭제한다. (리스트에서의 remove()는 대게 가장 앞의 원소를 삭제한다)
스택을 구현하는 방법에는 두 가지가 있다
- 배열사용
장점 : 구현하기 쉽다. 원하는 데이터의 접근 속도가 빠르다
단점 : 크기가 동적이 아니다. 런타임시 필요에 따라 늘어나거나 줄어들지 않는다. 데이터 최대 개수를 미리 정해야하고 삽입, 삭제에 비효율적이다
= 데이터 양이 많지만 삽입/삭제가 거의 없고 데이터의 접근이 빈번히 이뤄질때 유리하다
프로퍼티(속성) - top(데이터 삽입/삭제하는 위치), maxSize(배열의 최대 크기), stackArray(배열)로 구성
메소드(함수) - pop(삭제),push(삽입),peek(탐색),isEmpty(스택이 비어있는지 확인)
public class ArrStack {
private int top; //마지막 위치 (삽입,삭제가 이루어질 위치)
private int maxSize;
private Object[] stackArray;
//생성자 : 프로퍼티 초기
public ArrStack(int size){
this.top = -1;
this.maxSize = size;
this.stackArray = new Object[maxSize];
}
//스택이 비어있는지 확인
public boolean isEmpty(){
return (top==-1);
}
//데이터 삽입
public void push(Object item){
//스택에 가득찼을 때 예외처리
if(top >= maxSize-1) throw new ArrayIndexOutOfBoundsException((top+1)+">="+maxSize);
stackArray[++top] = item;
}
//데이터 읽기
public Object peek(){
//스택이 비어있을 때 예외처리
if(isEmpty()) throw new ArrayIndexOutOfBoundsException(top);
return stackArray[top];
}
//데이터 삭제 : 삭제된 데이터 반환(백업용도)
public Object pop(){
Object item = peek();
top--;
return item;
}
}//배열 기반 스택을 사용하는 main함수
public class main {
public static void main(String[] args) {
ArrStack stackA = new ArrStack(5);
stackA.push(3);
stackA.push("Hi");
stackA.push("Monsieur");
stackA.push("Songsong");
while(!stackA.isEmpty()){
System.out.println(stackA.pop());
}
}
}- 스택 객체를 생성할 떄 최대 크기를 정해준다. new ArrStack(5);
- 생성된 스택 객체를 이용하여 원하는 데이터를 삽입한다. stackA.push("Hi");
- 데이터를 읽기만 하고 싶을 땐 peek함수를, 삭제하면서 읽고 싶을 때는 pop메소드를 사용한다. stackA.pop()
(1) 생성자
우선 생성자를 통해 프로퍼티를 초기화한다. 이때 top의 위치는 -1인데, 그 이유는 배열의 인덱스 떄문이다. 만약 top를 0으로 초기화 한다면 다음 push의 위치는 1이 된다. 그러면 배열의 0번째 인덱스는 비어있는 상태가 된다
(2) 삽입 push()
push메소드는 삽입 함수로 우선 top의 위치를 하나 더해준 후 그 위치에 원하는 data를 삽입한다
(3) 삭제 pop()
pop메소드를 쉽게 구현하려면 단순히 top의 위치를 하나 빼주기만 하면 된다. 하지만 데이터 삭제 시 실수를 한다면 치명적이므로 만약을 대비하여 삭제될 데이터를 백업해야한다
*Object 라는 데이터 타입은 쉽게 생각해서 int,string,double 모든 타입을 포함한다고 생각하면 된다
예외처리(Overflow, Underflow)
push(),peek() 함수 내부에 if문으로 예외 처리한 부분이 있다.
배열 특성상 실행 하기 이전에 배열의 최대 크기를 정해주어야한다. 그런데 삽입을 여러번 하여 이 최대 크기보다 많은 데이터를 삽입하였을 경우 error가 생기게 된다. 이러한 error를 overflow라고 한다. 반대로 스택에 아무것도 없을 경우 pop()데이터 삭제를 하면 또한 error가 생기는데 이를 underflow라고 한다.
- 연결 리스트 사용
장점 : 크기가 동적이다. 런타임시 필요에 따라 크기가 확장 및 축소될 수 있다(데이터의 최대 개수가 한정되어 있지 않다), 데이터의 삽입 삭제가 용이하다
단점 : 배열과 다르게 데이터들이 순차적으로 나열되있지 않기 때문에 포인터를 위한 추가 메모리 공간이 필요하다
= 삽입/삭제가 빈번히 이뤄지고 데이터의 접근이 거의 없을 때 유리하다
//연결 리스트로 사용 할 노드 class
public class Node {
private Object data;
private Node nextNode;
public Node(Object data){
this.data = data;
this.nextNode = null;
}
//해당 노드를 원하는 노드(Node top)와 연결해주는 메소드
public void linkNode(Node top){
this.nextNode = top;
}
//해당 노드의 데이터를 가져오는 get메소드
public Object getData(){
return this.data;
}
//해당 노드와 연결된 노드를 가져오는 get메소드
public Node getNextNode(){
return this.nextNode;
}
}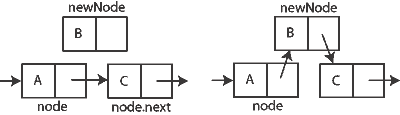
연결리스트는 노드로 구성되어 있다. 노드는 데이터와 다음 노드를 가리키는 주소로 구성되어 있다. 왼쪽의 칸은 데이터를 갖는 칸, 오른쪽 칸은 다음 노드를 가리키고 있다.
프로퍼티 - data, nextNode
메소드 - linkNode(Node top), (getData(),getNextNode() : private로 설정된 속성의 값을 외부에서 가져오기 위해 구현)
linkNode메소드는 자신의 nextNode 속성에 인자로 받은 top노드를 할당한다. 즉 자신과 top노드를 연결시켜준다.
public class ListStack {
private Node top;
public ListStack(){
top = null;
}
public boolean isEmpty(){
return (top==null);
}
public void push(Object item){
Node newNode = new Node(item);
newNode.linkNode(top);
top = newNode;
}
public Object peek(){
return top.getData();
}
public Object pop(){
if(isEmpty()) throw new ArrayIndexOutOfBoundsException();
else{
Object item = peek();
top = top.getNextNode();
return item;
}
}
}push(Object item)을 보면
우선 노드를 새로 하나 만든다. Node newNode = new Node(item);
그 후에 새로만든 노드와 이전의 노드를 연결한다. newNode.linkNode(top);
마지막으로 top = newNode; 는 새로운 노드가 가장 앞에 있으니 top으로 표시한다
pop()은 백업용도로 지울 데이터를 반환하고, top(head)의 위치를 이전 노드로 표시해준다.
top = top.getNextNode(); 여기서 조금 헷갈릴 수 있는데 오른쪽 항의 top은 지울 노드를 가리킨다
. 즉, 지울 노드의 getNextNode()는 지울 노드의 이전 노드를 말한다. 이제 top은 지울 노드의 이전 노드를 가리키게 된다.
public class main {
public static void main(String[] args) {
//array를 사용한 스택과 사용방법이 같다.
ListStack stackL = new ListStack();
stackL.push(5);
stackL.push("Hi");
stackL.push("again");
stackL.push("Monsieur Songsong");
while(!stackL.isEmpty()){
System.out.println(stackL.pop());
}
}
}참고자료
