Linked List
각각의 노드들이 해당 노드의 값과 다음 노드를 가리키는 정보(포인터)로 구성되어 연결된 노드로 표현된 자료 형태
노드 중 특별히 제일 앞에 있는 노드는 헤드(head), 제일 끝 노드는 테일(tail)이라고 부른다.
array가 물리적인 연결과 논리적인 연결이 동일하게 되어있는 반면
Linked list는 각각의 노드가 연속적으로 연결은 되어있지만, 실제 메모리상에서는 물리적으로 떨어진 공간에 위치한다.
(이를 포인터로 연결해둔 것)
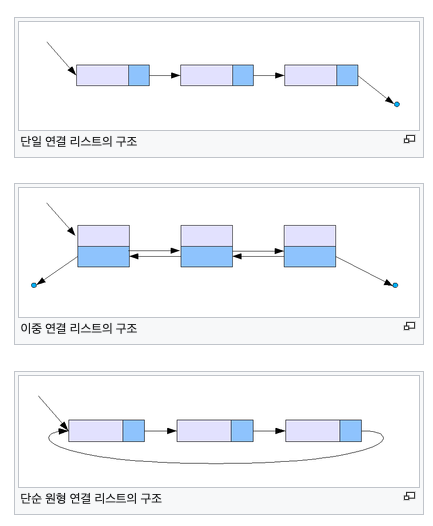
연결 리스트는 위와 같이 다른 형태로 존재할 수 있다.
원형 연결 리스트가 아니라면 연결 리스트의 마지막(tail)에서는 None을 가리킨다.
Linked List 특징
| Array | Linked List | |
|---|---|---|
| 탐색, 접근 | O(1) | O(n) |
| 삽입, 제거 | O(n) | O(1)(단, 위치를 알고 있는 경우) |
Linked List 에서 삽입, 제거할 경우 기존의 연결고리를 끊고 끼워넣거나 혹은 새로 연결을 달아주면 되기 때문에, 상수시간의 시간복잡도를 갖는다. 하지만, 이는 어디까지나 해당 원소의 위치를 알고 있을 경우인데, Linked List는 원소에 접근하려면 head부터 순서대로 탐색해가는 방법 밖에 없다. 즉, O(n)이 걸린다.
결과적으로 놓고 봤을 때, array에 비해 이점이 없어보인다.
하지만, Linked List 결국 Tree 구조의 근간으로서 그 의미가 있다고 보면된다.
Linked List의 코드 구현
class Node:
def __init__(self, key=None):
self.key = key
self.next = None
def __str__(self): # Node의 값을 표현하는 함수
return str(self.key)
'''
a = Node(3)
b = Node(9)
c = Node(-1)
a.next = b
b.next = c
'''
# 한 방향 연결리스트의 표현 (head의 정보만 갖고있는 것)
class SinglyLinkedList:
def __init__(self):
self.head = None
self.size = 0
def __len__(self):
return self.size
#삽입 method 구현 (pushFront, pushBack)
def pushFront(self,key):
new_node = Node(key)
new_node.next = self.head
self.head = new.node
self.size += 1
def pushBack(self,key):
new_node = Node(key)
if len(self)==0:
self.head = Node
else:
tail = self.head
while tail.next != None:
tail = tail.next
tail.next = new_node
self.size += 1
#삭제 method 구현
def popFront(self):
if len(self)==0
return None
else:
x = self.head
key = x.key
self.head = x.next
self.size -= 1
del x # x 객체의 메모리를 해제시킨다.
return key
def popBack(self):
if len(self)==0
return None
else: # running technique (한 발씩 뒤에서 따라간다.)
prev, tail = None, self.head
while tail.next != None:
prev = tail
tail = tail.next
if len(self)==1:
self.head = None
self.size = 0
else:
prev.next = None
key = tail.key
self.size -= 1
del tail
return key
# 탐색(search)
def search(self,key):
v = self.head
while v != None:
if v.key==key:
return v
v = v.next
return v
# 제너레이터(generator)
def __iterator__(self): # for 문이 해당 메서드를 호출
v = self.head
while v != None:
yield v
v = v.next
# yield : return과 거의 유사한 작동을 한다.
# 대신 다음의 호출 때, yield 다음부터 이어서 진행한다.
# loop가 전부 끝나면 StopIterator 라는 에러메시지가 발생
# for loop는 이 메시지를 감지하고 loop를 중단.양방향 연결 리스트
연결 리스트는 기본적으로 next node에 대한 정보만 갖고 있기에 tail에서 previous node에 대한 정보를 찾는 것은 최대 n의 시간이 걸린다 (O(n))
이러한 문제점을 해결하기 위해 node의 정보에 이전을 가리키는 포인터를 추가(prev)하여 역방향으로 탐색하는 경우에 사용할 수 있다.
이렇게 양방향 리스트를 만든 뒤에 tail node가 가리키는 next 포인터를 head로 연결, head node가 가리키는 prev node는 tail로 연결해주면 원형 양방향 리스트가 된다.(Circulaly Double Linked List)
원형 연결리스트가 빈 리스트일 경우에, key가 None인 dummy node가 있다.
이 node의 next, prev를 self loop로 만들어두면 원형 연결리스트의 빈 리스트 형태를 만들 수 있다. 이 빈 리스트에 노드가 추가되면 포인터들을 바꿔서 연결해주면 되고 이 dummy node가 일종의 head node 역할을 한다. 이 node의 key는 None이므로 key값은 의미가 없다.
class Node:
def __init__(self,key=None):
self.key = None
self.next = self
self.prev = self
class DoublyLinkedList:
def __init__(self):
self.head = Node()
sefl.size = 0
def __len__(self):
def __iterator__(self):
def __str__(self):
...
# splice = a와 b사이의 노드를 cut 해서 x 노드 다음에 붙여 넣는다.
# node a, b, x
# 조건 1 : a -> ... -> b
# 조건 2 : a와 b 사이에 head와 x node가 있으면 안 된다.
def splice(self, a, b, x):
ap = a.prev
bn = b.next
xn = x.next
#cut
ap.next = bn
bn.prev = ap
#paste
x.next = a
a.prev = x
b.next = xn
xn.prev = b
# a노드를 x노드 다음으로 이동
def moveAfter(self, a, x):
splice(a,a,x)
# a노드를 x노드 전으로 이동
def moveBefore(self, a, x):
splice(a,a,x.prev)
# 새로운 노드를 x노드 다음에 삽입
def insertAfter(self, x, key):
moveAfter(Node(key), x)
# 새로운 노드를 x노드 전에 삽입
def insertBefore(self, x, key):
moveBefore(Node(key), x)
def pushFront(self, key):
insertAfter(self.head, key)
def pushBack(self, key):
insertBefore(self.head, key)
#탐색
def search(self, key):
v = self.head # dummy node
while v.next != self.head:
if v.key==key:
return v
v=v.next
return None
#삭제
def remove(self, x):
if x==None or x==self.head:
return None
x.prev.next = x.next
x.next.prev = x.prev
del x
# popFront, popBack 은 remove 함수를 쓰면 된다.연산의 시간복잡도
- search(key) : O(n)
- splice(a,b,x) : O(1)
- moveAfter/Before(a,x), insertAfter/Before(x,key), pushFront/Back(key) :
splice 사용 = O(1) - remove(x) : O(1) (but search를 불러내기 때문에 실질적으로 O(n))
- popFront/Back() : O(1)
