💁🏻 "AI는 '확신'을 가지고 판단하는 것이 아니라,데이터에 기반한 가장 그럴듯한 답변을 제시합니다."
인공지능(Artificial Intelligence, AI)
∙ 인간의 지능적인 행동(이해, 판단, 학습, 추론 등)을 컴퓨터가 모방하도록 만드는 기술
AI의 오해
∙ AI는 인간처럼 생각하거나 느끼지 않는다.
∙ 자율성을 가진 존재가 아니라, 입력된 구조 안에서 작동한다.
∙ 대부분의 AI는 특정 작업만 수행하는 '좁은 AI'이다.
AI의 구성 요소와 아키텍처
1. 데이터: 인간이 경험을 통해 배우듯, AI는 데이터를 통해 세상을 이해합니다.
좋은 데이터의 조건:
∙ 충분한 양(Volume): 복잡한 패턴을 학습하기 위한 데이터 규모
∙ 대표성(Representativeness): 실제 사용 환경의 다양한 케이스 포함
∙ 품질(Quality): 정확하고 일관된 데이터
∙ 적절한 형태(Format): 목표 작업에 적합한 데이터 구조
2. 알고리즘(모델): 알고리즘은 데이터에서 패턴을 학습하고 새로운 상황에 적용하는 방법을 정의합니다.
주요 알고리즘 유형:
∙ 지도학습(Supervised Learning): 입력과 원하는 출력이 쌍으로 제공된 데이터로 학습
∙ 비지도학습(Unsupervised Learning): 레이블 없는 데이터에서 패턴과 구조 발견
∙ 강화학습(Reinforcement Learning): 환경과 상호작용하며 보상을 최대화하는 행동 학습
3. 인프라: AI 시스템의 성능, 확장성, 비용 효율성을 결정
주요 인프라 구성 요소:
∙ 컴퓨팅 자원: 모델 학습 및 추론에 필요한 처리 능력
∙ 데이터 파이프라인: 데이터 수집, 전처리, 저장, 접근을 위한 시스템
∙ 모델 개발 환경: 모델 설계, 훈련, 평가, 개선을 위한 도구
∙ 배포 및 모니터링 시스템: 모델을 실제 환경에 적용하고 성능 관리
∙ 피드백 루프: 실제 데이터로 모델 재훈련 메커니즘
머신러닝의 기본 원리
명시적인 프로그래밍 없이 데이터로부터 학습하여 성능을 향상시키는 기술
∙ 전통적 프로그래밍: 규칙 + 데이터 → 프로그램 → 결과
◦ 사람이 규칙을 정의한다
◦ (예: if 온도 > 30도 → 에어컨 켜기)
◦ 프로그램은 이 규칙을 따라 실행될 뿐이다
∙ 머신러닝: 데이터 + 결과 → 학습 알고리즘 → 규칙(모델)
◦ 규칙을 알 수 없거나 복잡할 때,
◦ '입력 데이터'와 '정답 결과'를 함께 주면
◦ 컴퓨터가 반복 학습을 통해 규칙을 스스로 찾아낸다
지도 학습(Supervised Learning)
예시를 통해 배우기: 입력(X)과 원하는 출력(Y)이 쌍으로 제공되는 데이터로부터 학습
∙ 인간 교육 비유: 명확한 정답이 있는 문제집으로 공부하기
지도학습의 작동 방식
∙ 레이블이 있는 훈련 데이터 준비 (예: 이메일 텍스트 + 스팸 여부)
∙ 모델이 입력에서 출력을 예측하도록 훈련
∙ 실제 레이블과 예측 간의 오차를 최소화하도록 모델 조정
∙ 새로운 데이터에 모델 적용하여 예측 생성
지도학습의 실제 적용 사례
∙ 이메일 스팸 필터링: 스팸 메일과 정상 메일 구분
∙ 신용 평가: 대출 상환 가능성 예측
∙ 의료 진단: 의료 영상에서 질병 감지
∙ 감성 분석: 텍스트의 긍정/부정 감정 분석
∙ 수요 예측: 제품 판매량 예측
비지도 학습(Unsupervised Learning)
레이블 없는 데이터에서 숨겨진 구조와 패턴을 찾아내기
∙ 인간 교육 비유: 정답 없이 패턴과 관계를 스스로 발견하기
비지도학습의 작동 방식
∙ 레이블 없는 데이터 수집 (예: 고객 구매 기록)
∙ 데이터의 내재적 구조를 찾는 알고리즘 적용
∙ 발견된 패턴을 활용하여 인사이트 도출 또는 다운스트림 작업 수행
비지도학습의 실제 적용 사례
∙ 고객 세분화: 유사한 행동 패턴을 가진 고객 그룹 식별
∙ 추천 시스템: 사용자 행동 기반 연관 상품 추천
∙ 이상 거래 탐지: 신용카드 사기 감지
∙ 토픽 모델링: 문서 컬렉션에서 주요 주제 식별
∙ 이미지 압축: 중요한 특성만 보존하면서 이미지 크기 축소
강화 학습(Reinforcement Learning)
에이전트가 환경과 상호작용하며 보상을 최대화하는 행동 정책을 학습
∙ 인간 교육 비유: 시행착오를 통해 배우기, 좋은 결과는 강화하고 나쁜 결과는 피하기
강화학습의 작동 방식
∙ 에이전트가 환경에서 상태를 관찰
∙ 현재 정책에 따라 행동 선택
∙ 환경으로부터 보상 수신 및 새로운 상태로 전이
∙ 보상을 최대화하도록 정책 업데이트
강화학습의 실제 적용 사례
∙ 게임 AI: AlphaGo, Atari 게임 등에서 인간 수준 이상 성능 달성
∙ 로봇 제어: 물리적 환경에서 로봇의 운동 제어
∙ 자원 관리: 데이터 센터 에너지 최적화
∙ 개인화된 추천: 사용자 피드백을 통한 추천 시스템 최적화
∙ 자율주행: 복잡한 교통 환경에서 의사결정
딥러닝과 신경망: 뇌에서 영감을 얻다
∙ 인간 뇌의 신경망 구조에서 영감을 받은 머신러닝의 발전된 형태
∙ 복잡한 패턴 인식과 특성 추출에 탁월한 성능을 보임
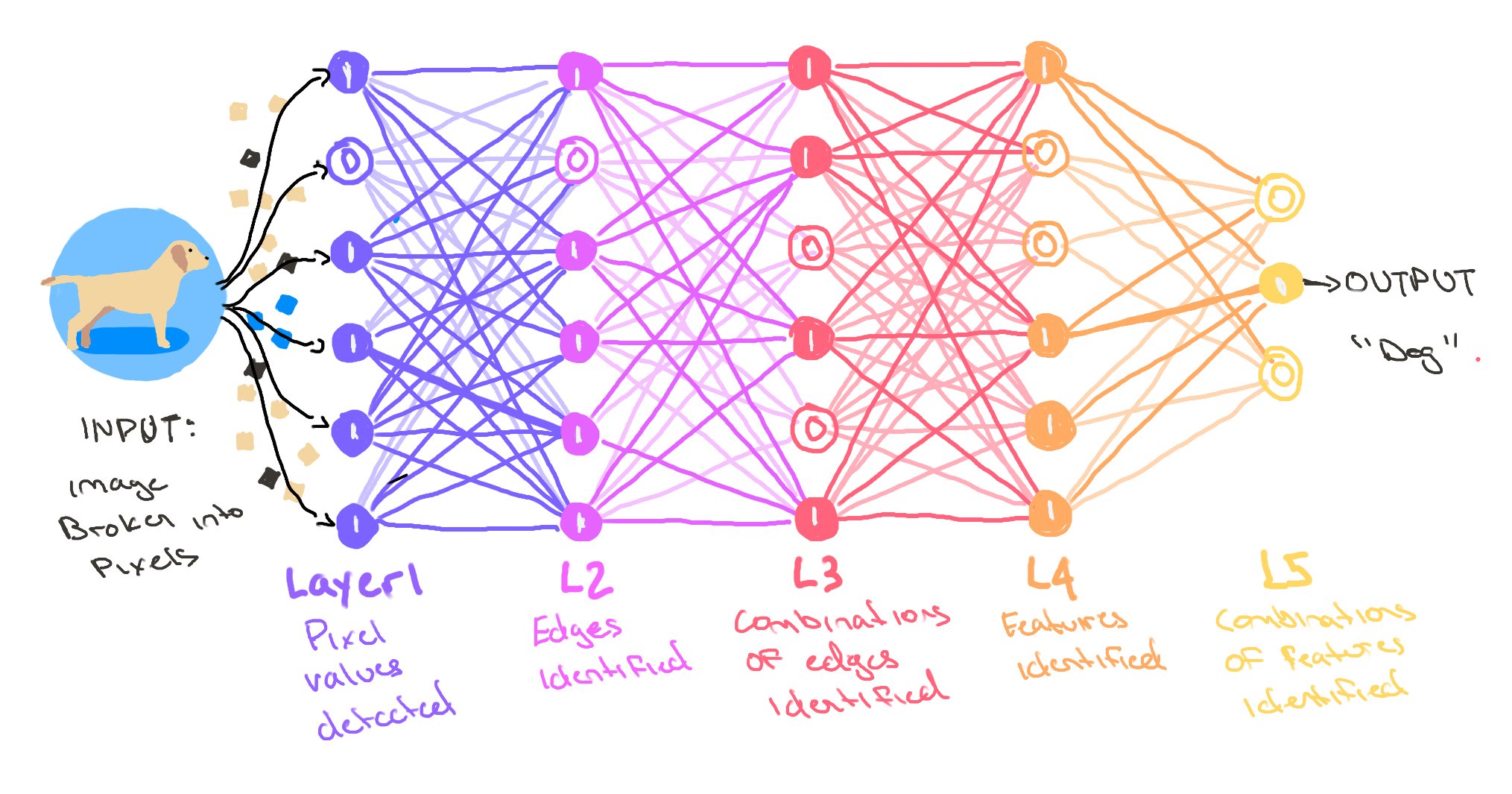
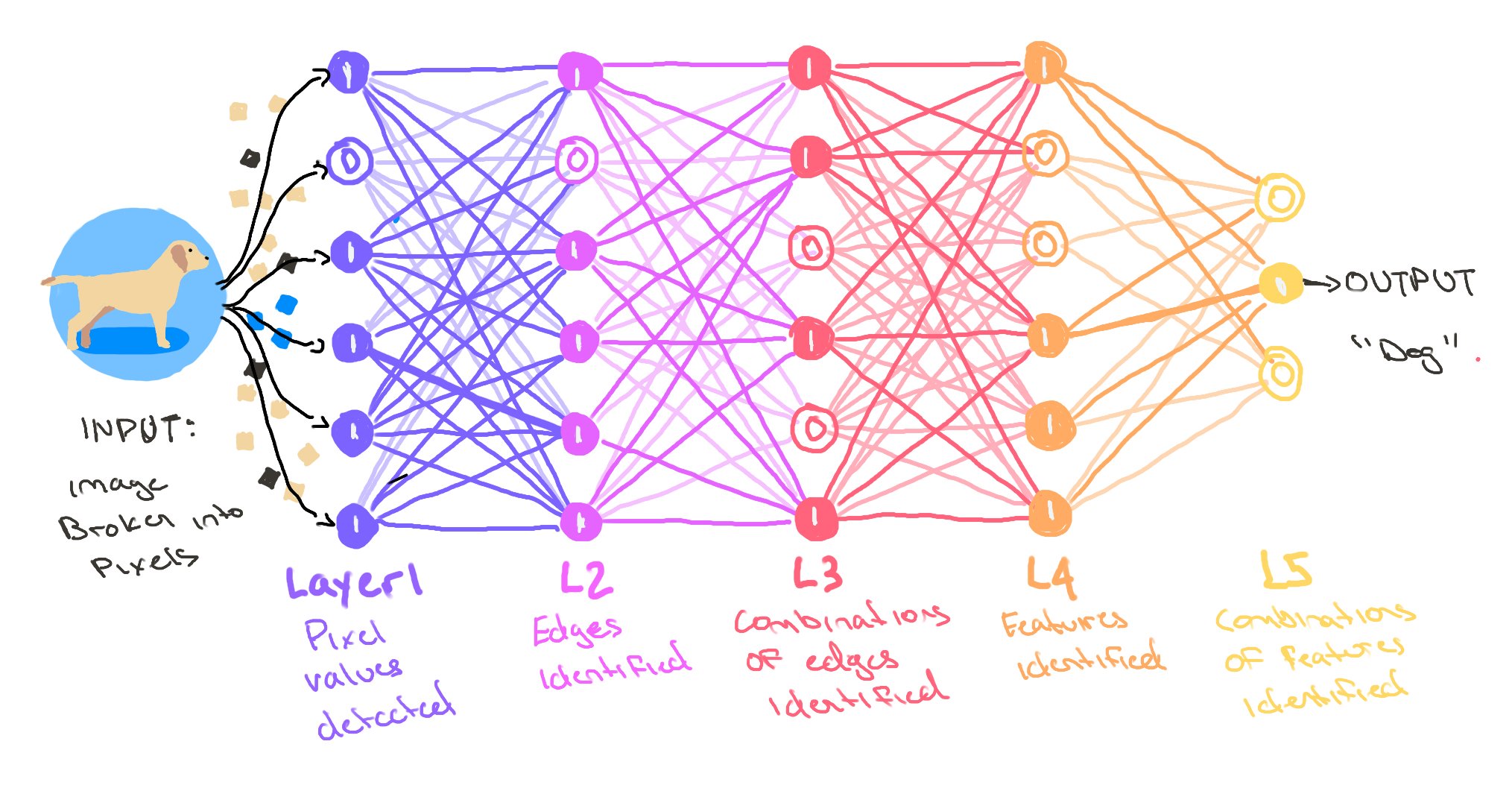
∙ 뉴런(노드): 입력을 받아 처리하는 기본 계산 단위
∙ 층(Layer): 여러 뉴런의 집합
◦ 초기 층: 단순한 패턴(선, 모서리)
◦ 중간 층: 더 복잡한 패턴(눈, 코, 입)
◦ 후기 층: 고수준 개념(얼굴 전체)
∙ 연결(Connection): 뉴런 간의 신호 전달 경로
📌 실제 예시와 비교
∙ 입력: 얼굴 이미지 정보를 습득
∙ 첫 번째 층: 이미지의 가장 기본 요소 감지(수직선, 수평선, 곡선, 명암 차이)
∙ 중간 층: 기본 요소를 조합해 더 복잡한 패턴 감지(눈, 코, 입, 귀와 같은 얼굴 구성 요소)
∙ 상위 층: 구성 요소들을 종합해 전체 얼굴 패턴 인식
👉🏻 "이 패턴의 조합은 90% 확률로 김민수의 얼굴이다"
그룹 연구
-
AI 서비스를 실제 운용하고 있는 기업의 기술 블로그를 방문해 주요 기능의 실제 구현 기술과 그 배경을 살펴봅니다. 👉🏻 카카오페이지 / 멜론
-
이 기술이 어떤 과정을 통해 고객 가치를 만들어내는지 기술적 측면과 비즈니스적 측면 두 관점에서 분석해 봅니다.
-
학습한 내용을 바탕으로, 해당 기술이 앞으로 더 나은 고객 가치를 창출하기 위해 필요한 발전 방향과 접근법을 정리합니다.

