Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 정리
Abstact
chain-of-thought를 생성하는 것이 language model의 complex reasoning을 어떻게 향상시켜주는지 확인합니다. 특히 chain-of-thought prompting을 사용하여 어떻게 reasoning ability가 향상이 되는지 보여줍니다.
chain-of-thought prompting은 arithmetic, commonsense, symbolic reasoning task에서 전반적으로 language model들의(GPT-3, PaLM, LLaMA) 성능을 향상시켰습니다. 그 중에서도 chain-of-thought prompting을 적용한 PaLM(540B)모델은 GSM8K에 대해서 fine-tuned GPT-3의 성능을 초과하여 SOTA를 달성하였습니다.
1. Introduction
최근 들어서 language model의 size를 늘리는 것이 NLP task에서 성능 향상으로 이어지고 있습니다. 특히 sentiment analysis나 machine translation과 같은 분야에 대해서는 심지어 training example을 적게 사용하거나 없어도 높은 성능을 달성했습니다. (few-shot learning, zero-shot learning) 하지만 model size를 늘려도 어려움을 가지는 Task가 있었습니다. 대표적으로 multi-step reasoning을 요구하는 task입니다. 이러한 task에 대해서는 model size를 늘린다고 해서 큰 성능 향상 폭으로 이어지지 않았습니다.
- math word problem
- commonsense reasoning
- symbolic reasoning
이번 논문에서는 language model의 reasoning ability를 향상시켜주는 방법을 제안합니다. 특히 large language model의 능력을 활용한 few-shot learning 방식을 사용하여 model의 reasoning 능력을 올리는 방법인 chain-of-thought Prompting 방법을 제안합니다.
2. Chain-of-Thought Prompting
Chain-of-Thought Prompting 방법은 Model이 문제를 해결하기 위해 intermediate reasoning step을 거쳐 최종적인 answer를 구할 수 있도록 도와줍니다. 특히 이 방법은 model의 size가 클수록 효과적이었습니다.
방법은 다음과 같습니다.
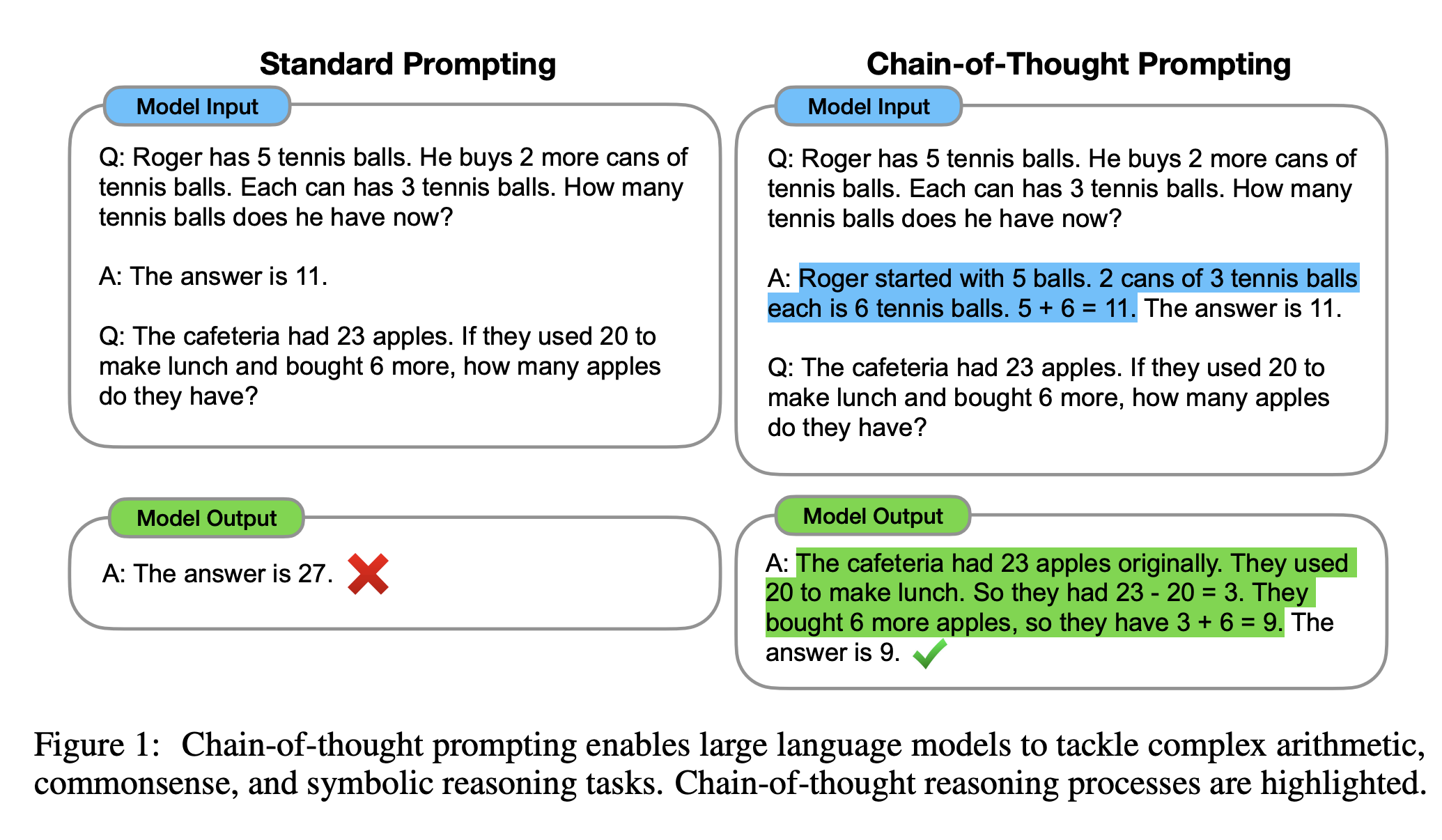
왼쪽이 일반적인 standard prompting이고 오른쪽이 본 논문에서 제시하는 chain-of-thought prompting입니다. 먼저 model input에서 standard prompting에서는 example을 줄 때 question과 answer를 directly하게 제공하는 반면 chain-of-thought는 natural language를 통해 최종적인 답을 구할 수 있도록 제시합니다. Model output을 보면 standard prompting은 틀린 정답을 내어놓지만 chain-of-thought prompting에서는 Model input에서 제시된 것과 같이 문제를 푸는 중간과정을 나열한 뒤 올바른 정답을 구하게 됩니다.
chain-of-thought prompting은 step-by-step thought process를 통해 answer를 구하는 과정을 흉내낼 수 있도록 도와줍니다. (여기서 흉내낸다는 의미는 Limitations에 나와있습니다.)
chain-of-thought prompting은 reasoning task에 있어 몇가지 좋은 특성들을 가지게 됩니다.
- chain-of-thought prompting은 모델이 문제를 Intermediate step으로 쪼갠 후 해결할 수 있도록 도와줍니다. 이를 통해 문제를 해결하기 위해 reasoning step을 요구하는 문제에 대해 더 많은 계산을 수행할 수 있도록 도와줍니다.
- chain-of-thought prompting은 model의 행동에 관해 해석할 수 있는 window를 제공합니다. 특정한 answer에 어떻게 도착했는지 알 수 있기 때문에 어떤 intermediate step이 잘못되었는지 debugging할 수도 있습니다.
- chain-of-thought prompting은 사람이 language를 이용하여 해결할 수 있는 task에 대해 적용이 가능할 수도 있습니다.
- chain-of-thought prompting은 large language model에 쉽게 적용이 가능한 방법입니다.
3. Arithmetic Reasoning
3.1. Experimental Setup
Benchmarks 5가지 math word problem benchmark 데이터셋을 사용하여 성능을 측정하였습니다. (1) GSM8K (2) SVAMP (3) ASDiv (4) AQuA (5) MAWPS
Standard Prompting chain-of-thought prompting과 비교하기위해 standard few-shot prompting을 사용하였습니다. mode의 input으로 question과 answer를 직접적으로 줍니다.
Chain-of-thought Prompting FIgure 1의 오른쪽에 나온 방법대로 prompting을 사용합니다. AQuA를 제외한 나머지 데이터셋에 대해서 8-shot을 사용하였고, AQuA에 대해서는 4-shot을 사용하였습니다.\
Language models 5개의 large language model을 사용하였습니다. (1) GPT-3 (2) LaMDA (3) PaLM (4) UL2 20B (5) Codex

3.2. Results
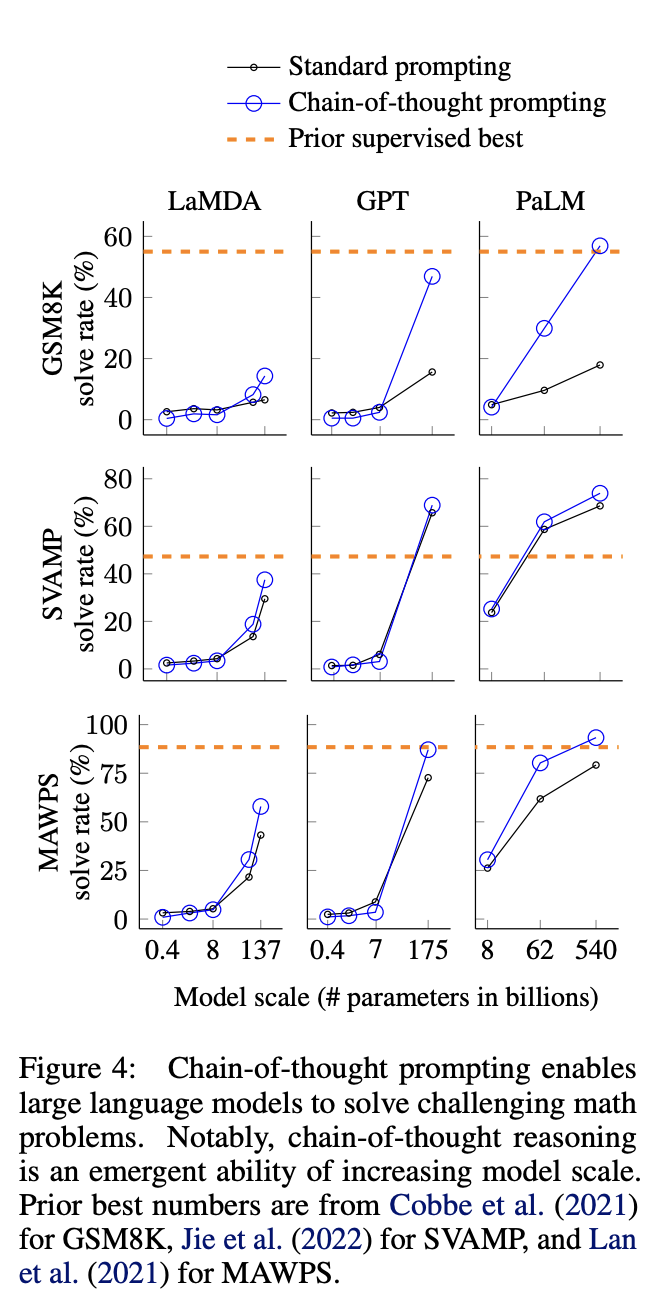
3가지 중요한 점을 확인할 수 있습니다.
첫번째로, model size가 커질수록 model의 reasoning performance도 좋아졌습니다. 특히 model의 size가 100B 이상일수록 Chain-of-thought prompting의 효과가 컸습니다. 하지만 model size가 100B 미만이면 나오는 output이 fluent하나 illogical하게 정답이 생성이 되었습니다.
두번째로, 데이터셋의 난이도가 어려울수록 chain-of-thought prompting의 방법이 효과적이었습니다. multi-step reasoning을 요구하는 GSM8K에서는 standard prompting과 chain-of-thought prompting의 결과가 확연하게 차이가 납니다. 하지만 MAWPS와 같은 single-step reasoning을 요구하는 데이터셋에 대해서는 엄청 큰 향상 폭을 가진 것은 아니고 오히려 성능의 폭이 떨어질 수도 있습니다.
세번째로, PaLM(540B)와 GPT-3(175B)는 fine-tuned model과 비교할만한 성능을 기록했습니다. 특히 PaLM 540B은 GSM8K, SVAMP, MAWPS 데이터셋에 대해 SOTA를 달성하였습니다.
왜 chain-of-thought prompting이 잘 작동하는지 더 잘 이해하기 위해서 LaMDA 137모델의 GSM8K에 대한 output 중에서 correct answer를 가진 것을 분석하였습니다. 50개의 random example들 중에서 우연하게 정답과 일치한 2개를 제외하고는 logically, mathematically하게 정답과 일치하였습니다.
그 다음 wrong answer를 반환한 50개의 examples들을 분석하였습니다. 46%는 calculator error, symbol mapping error, one reasoning step missing과 같은 minor mistakes를 보여주었고 나머지 54%는 문제를 제대로 이해하지 못한 것과 같이 major mistakes를 보여주었습니다.
PaLM 62B에서는 error를 보이나 PaLM 540B에서는 정상적으로 동작하는 example을 비교하였습니다. model size가 커질 수록 One-step missing이나 semantic understanding error와 같은 부분이 해결된 것을 확인할 수 있었습니다.
3.3. Ablation Study
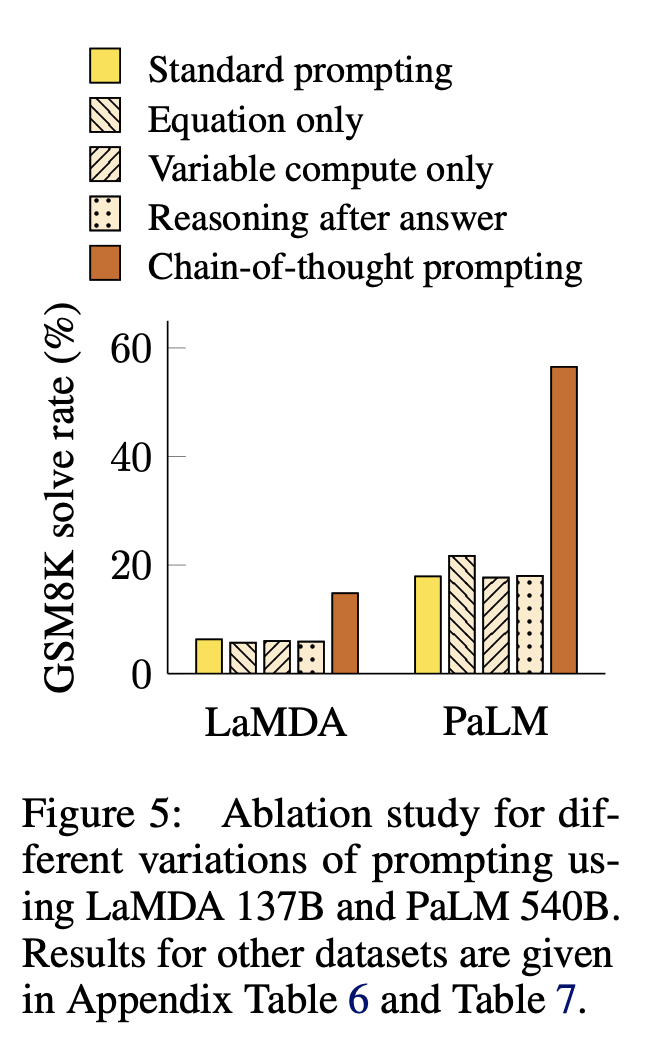
chain-of-thought prompting이 아니라 다른 형태의 prompting이더라도 성능이 chain-of-thought prompting처럼 향상될 수 있는지 확인합니다.
Equation Only. GSM8K처럼 multi-step reasoning을 요구하는 것은 equation-only만 있어서는 성능 향상 폭이 크지 않았습니다. 이것을 보아 multi-step reasoning을 요구하는 것 데이터셋에 대해서는 natural language로 reasoning step을 표현한 것이 효과적인 것을 확인할 수 있었습니다. question을 통해 단순하게 추론이 가능한 one-step reasoning을 요구하는 데이터셋에 대해서는 Equation Only도 효과적이었습니다.
Variable compute only chain-of-thought prompting이 intermediate step을 제공하기때문에 standard prompting에 비해 더 많은 연산을 사용하게 해서 어려운 문제를 풀 수 있기 때문에 잘된다는 직관에 대한 실험입니다. 별도의 natural language를 통해 설명하는 intermediate step을 모두 … 과 같은 sequence of dots로 대체하여 실험하였습니다.
Chain-of-thought after answer answer를 먼저 주고 intermediate step 과정을 그 다음에 제시하는 형태로 prompting을 했을 때 오히려 성능 향상 폭이 크지 않은 것을 확인하였습니다.
3.4. Robustness of Chain of Thought
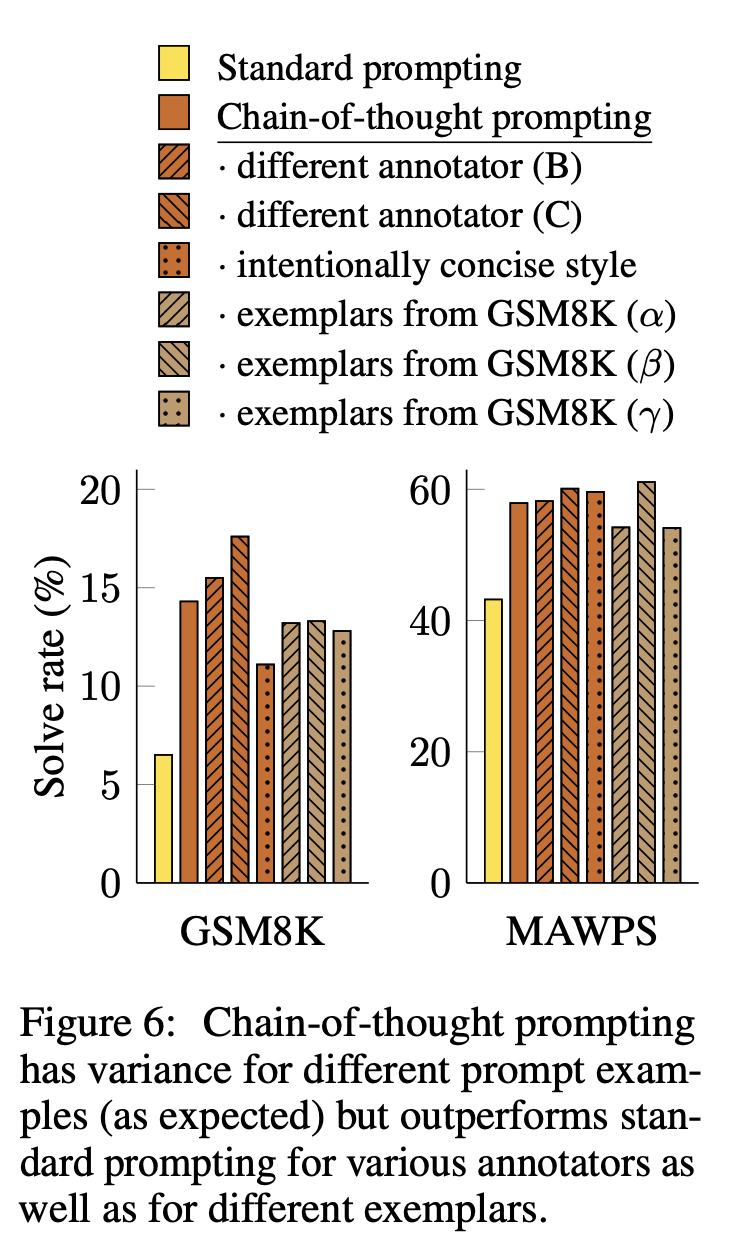
chain-of-thought prompting의 robustness를 확인하기위해 다른 annnotator가 작성한 chain-of-thought prompting과 비교해보고 few-shot example을 바꾸어도 실험한 것과도 비교하였습니다. 추가로 Training verifiers to solve math word problems에서 제시된 Concise한 Prompting 방법과도 비교하였습니다.
특정 annotation style에 관계없이 모두 standard prompting보다 성능이 좋게 나왔습니다. example에 상관없이 standard prompting보다 결과가 좋게 나온 것을 확인할 수 있었습니다.
4. Commonsense Reasoning
Benchmarks CSQA, StrategyQA, Date Understanding, Sports Understanding, SayCan 데이터셋을 사용하여 일반적인 상식과 관련해서도 Reasoning task를 잘 수행할 수 있는지 측정하였습니다.
Prompts Figure 3에 제시된 방법된 방법을 확인하면 됩니다.

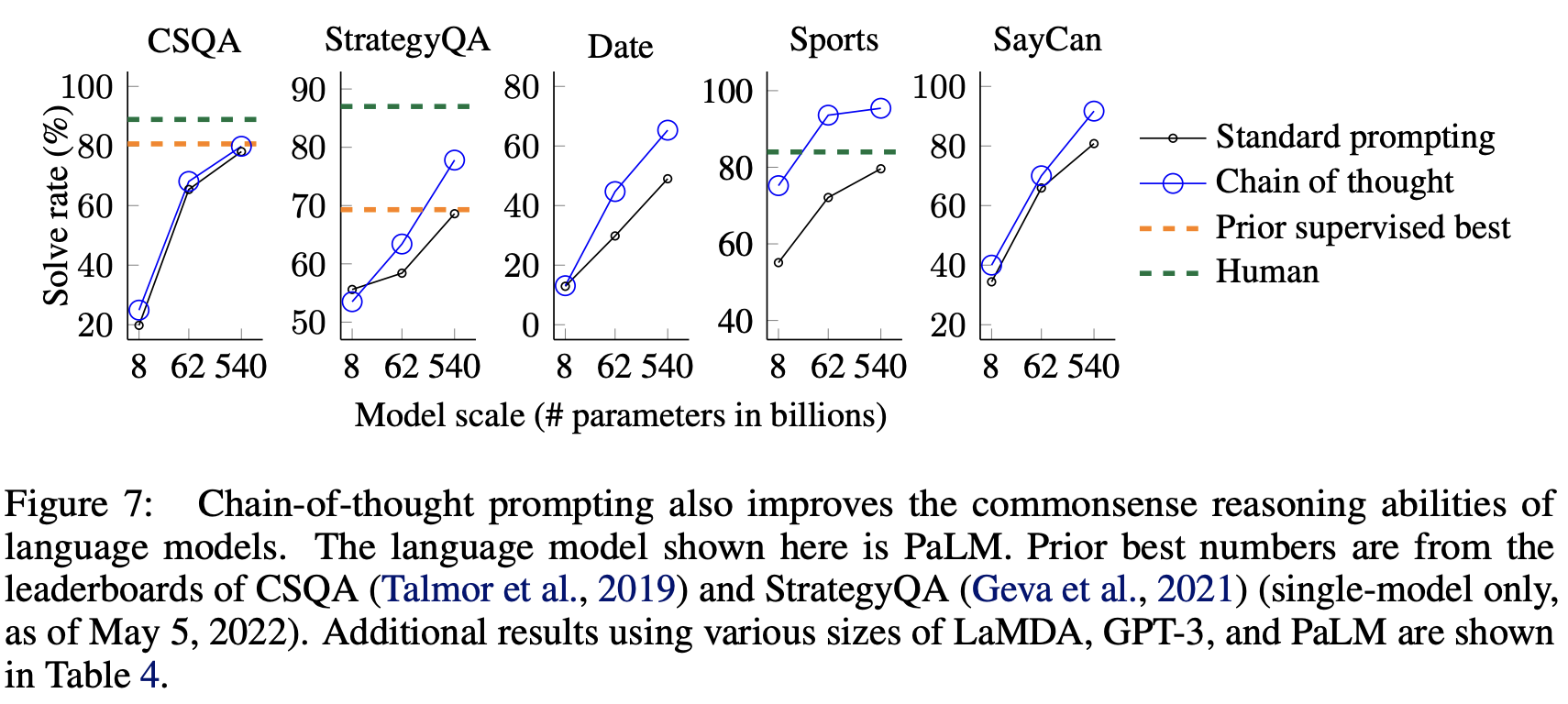
Results. Figure 7에서 결과를 확인할 수 있습니다. chain-of-thought prompting 방법이 commonsense reasoing을 요구하는 task에 대해서도 효과적으로 성능을 향상시킨 것을 확인할 수 있습니다.
5. Symbolic Reasoning
Task
- Last letter concatenation: 단어의 마지막 문자를 이어 붙이는 task를 가리킵니다. 일반적으로 단어의 첫번째 문자를 합치는 것보다 어려운 task입니다. e.g.) “Amy Brown” → “yn”
- Coin flip: 동전을 뒤집는 행동에 관한 text가 나올 때, 동전이 앞면이 보이는지 뒷면이 보이는지 답하는 것입니다. e.g. ) “A coin is heads up. Phoebe flips the coin. Osvaldo does not flip the coin. Is the coin still heads up?” → “no”
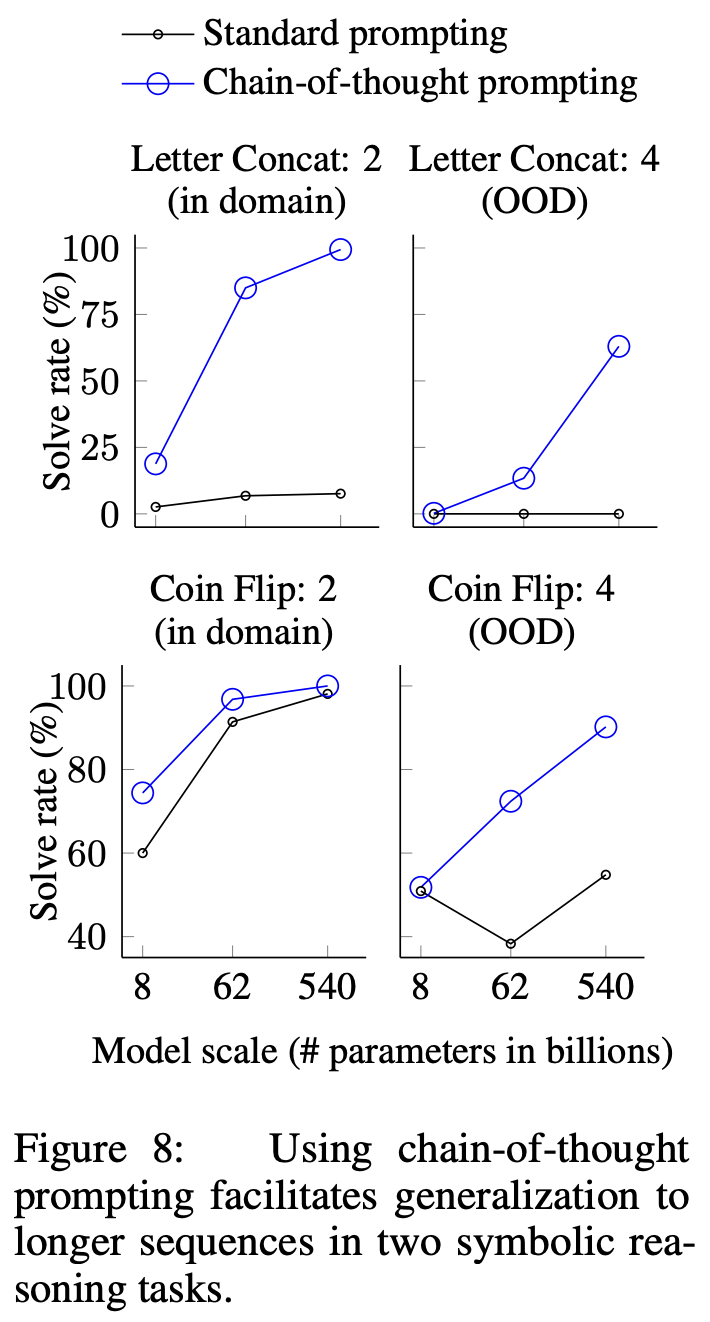
여기에 추가로 OOD 실험을 하여서 training example에 나온 step보다 더 많은 step이 나왔을 때도 chain-of-thought로 인한 성능이 잘 나올지 확인하였습니다.
- 예를 들어, coin flip 실험을 OOD로 실험한다는 의미는 model input으로 동전을 뒤집는 행동이 5개가 나왔는데 실제 질문할 때는 5개 보다 많이 나오는 text를 준 것을 의미합니다.
Results
smaller model에서는 성능이 좋지 않지만 100B scale이상에 대해서는 성능 향상 폭이 큰 것을 확인할 수 있습니다. OOD 실험에 대해서도 성능이 좋게 나온 것을 확인할 수 있기 때무네 chain-of-thought prompting이 입력으로 주어지는 text 길이에 상관없이 generalization 성능이 좋은 것을 확인할 수 있습니다.
6. Discussion
chain-of-thought prompting과 같은 simple한 mechanism을 이용하여 language model의 multi-step reasoning 성능 향상에 큰 도움을 준다는 것을 확인할 수 있었습니다. 특히 fine-tuning하는 것 없이 few-shot prompting을 통해 SOTA를 달성한 데이터셋도 존재합니다. model의 scale이 커짐에 따라 chain-of-thought prompting으로 인한 성능 향상 폭도 커지는 것을 확인할 수 있었습니다. 반면에 standard prompting은 model의 성능이 커져도 큰 향상 폭을 불러오지는 않았습니다.
한계점도 분명히 존재합니다
- 실제 model이 multi-step reasoning을 하는 것인지 아니면 단순하게 mimic을 하는 것인지 확인할 수 없습니다.
- chain-of-thought를 prompting에서 적용할 수는 있지만 fine-tuning할 때 쓰기는 어렵습니다. 즉, 중간 step을 묘사하는 것이 prompting할 때는 example이 적어서 쉽지만 fine-tuning할 때 데이터셋이 많기 때문에 사용하기 어렵습니다.
- chain-of-thought prompting이 항상 correct answer를 보장하는 것이 아닙니다.
- large language model에서는 성능이 뛰어나지만 100B보다 작은 model에 대해서는 성능 향상을 볼 수 없습니다.
