
소개
Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.
인덱스를 대상으로 사이즈 10의 1001번째 페이지를 조회하는 경우, from + size의 값이 10000을 초과하게 되면서 에러가 발생합니다. 인덱스의 총 문서가 10000개보다 더 많은 경우, 검색 결과 UI에서는 실제로 결과는 존재하지만 조회할 수 없는 페이지들이 사용자에게 노출될 수 있습니다.
elasticsearch는 샤딩 전략을 사용하여 인덱스를 샤드라는 단위로 나누어, 클러스터를 구성하는 각 노드들에게 분산하여 저장하는 분산 시스템입니다. 조회 시, 각 샤드를 대상으로 조회한 결과를 중앙에서 정렬하여 최종 결과를 반환합니다.
실제로 클러스터에 인덱스 조회를 쿼리하는 경우, 다음과 같은 일이 발생합니다.
- 코디네이터 노드는 가져올 문서를 식별하고 관련 샤드에 GET 요청을 보내 조회합니다.
- 각 샤드는 문서를 정렬하여 필요한만큼 조회하고 코디네이터 노드로 결과를 반환합니다.
- 코디네이터 노드는 각 샤드가 조회한 문서를 정렬하여 클라이언트로 최종 결과를 반환합니다.
모든 노드는 암시적으로 코디네이터 노드이고 충분한 메모리와 CPU를 가지고 있어야합니다.

만약 인덱스가 5개의 프라이머리 샤드로 구성되어 있을 때, 사이즈 10의 1001번째 페이지를 조회하는 경우, 각 샤드에서 문서를 정렬하여 10010개를 조회하고, 코디네이터 노드에서는 모든 조회 결과 문서 50050개를 정렬하여 10개의 문서를 반환하고 50040개의 문서는 버립니다.
페이지네이션이 깊어질수록 코디네이터 노드에서 정렬해야 할 문서가 기하급수적으로 늘어나게 되면서 더 많은 CPU, 메모리를 사용하기 때문에 index.max_result_window 기본 값으로 설정된 10000을 초과하는 경우, 경고와 함께 에러가 발생하게 됩니다.
해결
index.max_result_window 설정
기본으로 설정된 index.max_result_window 값을 사용하지 않고, 설정 값을 변경할 수 있습니다.
PUT _settings
{
"index.max_result_window": {size}
}하지만 페이지네이션이 깊어질수록 발생하는 성능 문제를 해결할 수 없기 때문에, 설정한 값을 초과하면 동일한 문제가 지속적으로 발생합니다.
scroll

RDBMS의 cursor 방식과 동일하게 작동하는 scroll API는 모든 검색 결과를 메모리에 컨텍스트로 유지하고 다음 조회 요청 시, 이전 조회 결과를 이어서 조회할 수 있습니다.
GET /index/_search?scroll=1m
{
"size": 10,
"query": {
"match": {
"message": "foo"
}
}
}{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlZjTHFyckUwUnpHS1ZqZnJhOVliZ3cAAAAAAAELxxZTUXpBNklNaVFFT0kwS3BHdDNQTHR3",
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : [...]
}scroll API로 조회 시, scroll 파라미터를 통해 컨텍스트를 유지하는 기간을 전달합니다. 조회 결과와 함께 다음 조회에 전달해야 할 scroll_id를 반환합니다.
GET _search/scroll
{
"scroll": "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFlZjTHFyckUwUnpHS1ZqZnJhOVliZ3cAAAAAAAELzxZTUXpBNklNaVFFT0kwS3BHdDNQTHR3"
}컨텍스트에 유지되고 있는 다음 결과를 조회 시, 컨텍스트를 식별할 수 있는 scroll_id와 컨텍스트를 유지하는 기간을 전달하여 갱신합니다.
하지만 scrol API에서도 여전히 해결할 수 없는 문제점이 있습니다.
- from 값을 사용할 수 없기 때문에, UI에서 더보기 버튼이나 스크롤 방식이 아닌 페이지 번호 조회인 경우는 사용할 수 없습니다.
- 컨텍스트 조회 시점 이후에 발생한 변경 사항이 반영되지 않은 스냅샷에서 조회하기 때문에, 사용자의 실시간 조회에는 적합하지 않습니다.
- 컨텍스트의 유지 기간을 짧게 설정하는 경우, 사용자의 사용성이 하락할 수 있습니다. 반대로, 유지 기간을 길게 설정하는 경우, 사용자의 사용성이 증대될 수 있지만, 더 이상 조회를 하지 않는 경우에도 컨텍스트가 불필요하게 유지될 수 있습니다.
- 백그라운드 세그먼트 병합 프로세스 과정에서는 더 이상 사용되지 않는 세그먼트가 컨텍스트에서 사용되고 있는지 추적합니다. 만약 사용되고 있는 경우, 해당 세그먼트는 삭제 대상에서 제외됩니다. 수정 및 삭제가 잦은 인덱스를 대상으로 유지되고 있는 컨텍스트가 많을수록 많은 메모리를 사용하게 되고, 제거되지 않은 세그먼트들로 인해 더 많은 디스크 공간과 파일 핸들링이 필요하게 됩니다.
search_after
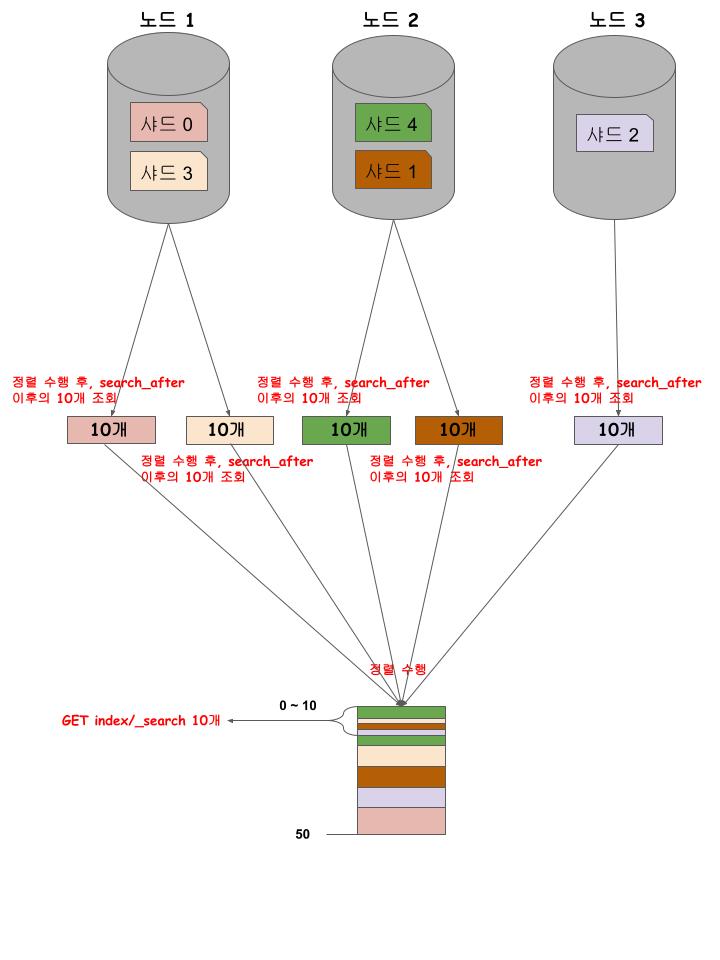
조회 결과를 고유한 키를 기준으로 정렬하고, 전달한 키 값 이후의 결과들만 조회할 수 있습니다. 메모리에 컨텍스트를 유지하는 방식이 아닌 매번 인덱스를 대상으로 새로 조회하기 때문에, 실시간 변경이 반영된 결과를 이어서 조회할 수 있습니다.
pit(point in time) API를 사용하면 scroll API처럼 특정 시점의 인덱스 상태를 대상으로 조회할 수 있습니다.
GET index/_search
{
"size": 10,
"query": {
"match": {
"message": "foo"
}
},
"sort": [
{"title": "asc"}
]
}{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : [
...,
{
"_index" : "index",
"_type" : "doc",
"_id" : "uyNoH2cBvWxWFgHQ86L9",
"_score" : null,
"_source" : {
"message" : "foo",
"title" : "bar"
},
"sort" : [
"bar"
]
}
]
}search API로 조회 시, sort 필드를 통해 고유한 값을 가질 수 있는 필드로 구성된 정렬 조건을 사용해야합니다. 조회 결과로 반환되는 sort 값은 다음 조회 시, 조회 기준이 되기 때문에, 고유하지 않은 경우 조회 결과가 손실될 수 있습니다.
GET index/_search
{
"size": 10,
"query": {
"match": {
"message": "foo"
}
},
"sort": [
{"title": "asc"}
],
"search_after": ["bar"]
}다음 조회 시에 search_after 필드를 통해 이전 조회 결과에서 반환한 조회 기준이 되는 값을 전달합니다.
search_after API를 사용하여 페이지네이션이 깊어질수록 발생하는 성능 문제를 해결할 수 있지만 경우에 따라 사용하기 어려울 수 있습니다.
- 정렬 기준 값이 고유하지 않은 경우, 결과가 손실되어 조회 결과가 정확하지 않을 수 있습니다.
- from 값을 사용할 수 없기 때문에, UI에서 더보기 버튼이나 스크롤 방식이 아닌 페이지 번호 조회인 경우는 사용할 수 없습니다.
검색 범위 조절
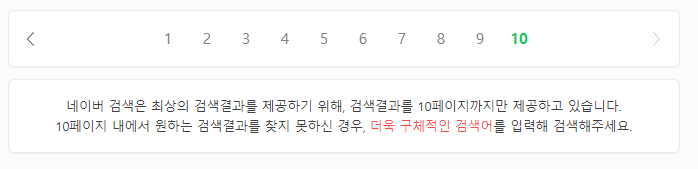

검색 UI에서 페이지 번호를 통한 조회가 가능해야 하는 경우는 search_after API를 사용할 수 없기 때문에, 정확도 및 관련성이 높은 결과만 일부 제공하고 일정 수 이상의 결과를 제공하지 않는 정책으로 검색 범위를 조절하여 해결할 수 있습니다.
references
- https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/pagination.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/_fetch_phase.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html



좋은 정보 감사합니다 ^^