https://programmers.co.kr/learn/courses/30/lessons/42577
문제 설명
전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인한다.
아래는 구조대와 지영석의 전화번호의 접두어가 일치하는 경우이다.
- 구조대 119
- 박준영 97 674 223
- 지영석 11 9552 4421
문제의 조건은 다음과 같다.
- 전화번호의 갯수는 1 이상 1000000 이하이다.
- 전화번호의 길이는 1 이상 20 이하이다.
- 전화번호는 중복되지 않는다.
문제 풀이
해시 자료구조 사용
import java.util.*;
public class Main {
public static class Solution {
public boolean solution(String[] phone_book) {
Set<String> set = new HashSet<>();
Arrays.sort(phone_book, Comparator.comparingInt(String::length).reversed());
int minLength = phone_book[phone_book.length - 1].length();
for (String number : phone_book) {
if (set.contains(number)) {
return false;
}
for (int i = minLength; i <= number.length(); i++) {
set.add(number.substring(0, i));
}
}
return true;
}
}
public static void main(String[] args) {
Solution solution = new Solution();
solution.solution(new String[]{"12","123","1235","567","88"});
}
}
해시 자료구조를 사용하는 경우, 문자열의 길이가 긴 순서대로 정렬을 수행하여 가장 길이가 짧은 문자열의 길이를 구한다. 길이가 긴 순으로 정렬된 문자열을 순회하면서 가장 짧은 문자열의 길이부터 현재 문자열의 길이까지 문자열을 쪼개어 저장한다. 쪼개진 문자열에 포함되는 문자열이 있는지 검사하여 다른 문자열의 접두어인 경우를 구할 수 있다. 정렬의 시간 복잡도는 O(N log)이고 문자열을 순회하며 문자열을 쪼개어 저장하고 탐색하는 시간 복잡도는 가장 길이가 짧은 문자열을 제외하고 모든 전화번호의 길이가 일치하는 최악의 경우 길이가 긴 전화번호의 길이가 M일때 O(NM)이다.
문자열 정렬 사용
import java.util.*;
public class Main {
public static class Solution {
public boolean solution(String[] phone_book) {
Arrays.sort(phone_book);
for (int i = 0; i < phone_book.length - 1; i++) {
if (phone_book[i + 1].indexOf(phone_book[i]) == 0) {
return false;
}
}
return true;
}
}
public static void main(String[] args) {
Solution solution = new Solution();
solution.solution(new String[]{"12","123","1235","567","88"});
}
}
문자열 정렬을 사용하는 경우, 문자열을 한 문자씩 순회하면서 유니코드 순서 기준으로 비교하여 정렬한다. 만약 문자들이 일치하지만 길이가 다른 경우는 길이가 짧은 문자열이 낮은 순위로 정렬된다. 문자열 비교의 특징으로 인해 배열[N]의 문자열을 접두어로 포함하는 문자열이 배열[N + 1]에 위치할 수 있게된다. 정렬의 시간 복잡도는 O(N log)이고 문자열을 순회하며 다음 문자열이 현재 문자열을 포함하는지 검사하는 시간 복잡도는 O(N)이다. 시간 복잡도 관점에서 문자열 정렬 방법이 항상 효율적이라고 생각할 수 있지만 정렬을 하는 과정에서 호출되는 String 클래스의 compare 메소드는 문자열을 순회하며 비교하기 때문에 시간 복잡도는 두 문자열의 접두어 중복 문자 갯수가 C이라고 했을 때 O(C)이다. 반면 길이를 기준으로 비교하는 경우 비교 연산의 시간 복잡도는 O(1)이다. 정렬의 시간 복잡도가 O(N log)으로 같더라도 상황에 따라 비교 연산의 시간 복잡도 O(C)는 무시할 수 없을 정도로 커지게 된다.
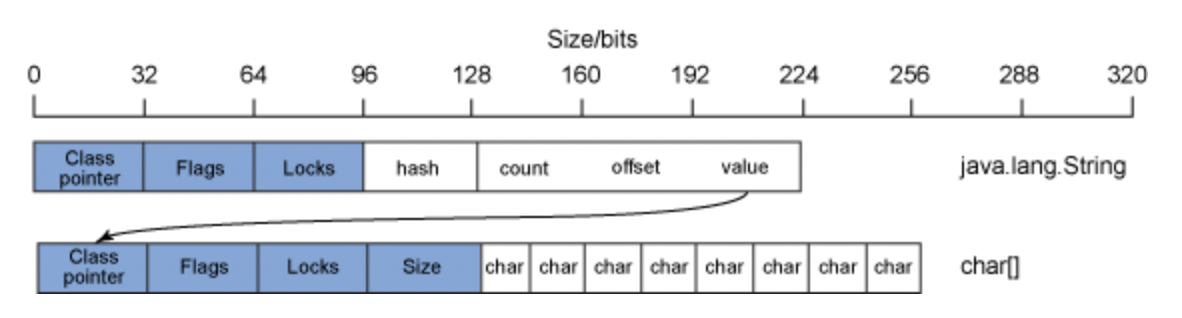
String 객체는 내부에서 필드로 문자 배열을 가진다. 자바에서 객체로 다루어지는 배열은 생성시 할당받은 길이를 필드로 가지고 있다.
| 비교 | 해시 | 문자열 |
|---|---|---|
| 정렬 | O(N log) | O(N log) |
| 저장 및 탐색 | O(NM) | O(N) |
가장 짧은 문자열을 포함해서 평균 길이가 길어지는 경우, 쪼개어 저장할 문자열의 갯수가 줄어들기 때문에 해시 방식이 유리해질 수 있다. 접두어가 중복되는 문자열이 많아지면서 평균 길이가 길어지는 경우, 비교 연산의 비용이 증가하기 때문에 불리해질 수 있다. 상황에 따라 최적의 방법을 사용하면 될 것 같다.
