프렌즈대학교 컴퓨터공학과 조교인 제이지는 네오 학과장님의 지시로, 학생들의 인적사항을 정리하는 업무를 담당하게 되었다.
그의 학부 시절 프로그래밍 경험을 되살려, 모든 인적사항을 데이터베이스에 넣기로 하였고, 이를 위해 정리를 하던 중에 후보키(Candidate Key)에 대한 고민이 필요하게 되었다.
후보키에 대한 내용이 잘 기억나지 않던 제이지는, 정확한 내용을 파악하기 위해 데이터베이스 관련 서적을 확인하여 아래와 같은 내용을 확인하였다.
- 관계 데이터베이스에서 릴레이션(Relation)의 튜플(Tuple)을 유일하게 식별할 수 있는 속성(Attribute) 또는 속성의 집합 중, 다음 두 성질을 만족하는 것을 후보 키(Candidate Key)라고 한다.
- 유일성(uniqueness) : 릴레이션에 있는 모든 튜플에 대해 유일하게 식별되어야 한다.
- 최소성(minimality) : 유일성을 가진 키를 구성하는 속성(Attribute) 중 하나라도 제외하는 경우 유일성이 깨지는 것을 의미한다. 즉, 릴레이션의 모든 튜플을 유일하게 식별하는 데 꼭 필요한 속성들로만 구성되어야 한다.
제이지를 위해, 아래와 같은 학생들의 인적사항이 주어졌을 때, 후보 키의 최대 개수를 구하라.
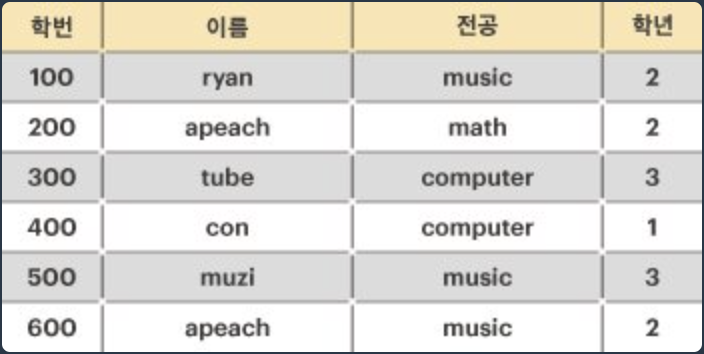
위의 예를 설명하면, 학생의 인적사항 릴레이션에서 모든 학생은 각자 유일한 "학번"을 가지고 있다. 따라서 "학번"은 릴레이션의 후보 키가 될 수 있다.
그다음 "이름"에 대해서는 같은 이름("apeach")을 사용하는 학생이 있기 때문에, "이름"은 후보 키가 될 수 없다. 그러나, 만약 ["이름", "전공"]을 함께 사용한다면 릴레이션의 모든 튜플을 유일하게 식별 가능하므로 후보 키가 될 수 있게 된다.
물론 ["이름", "전공", "학년"]을 함께 사용해도 릴레이션의 모든 튜플을 유일하게 식별할 수 있지만, 최소성을 만족하지 못하기 때문에 후보 키가 될 수 없다.
따라서, 위의 학생 인적사항의 후보키는 "학번", ["이름", "전공"] 두 개가 된다.
릴레이션을 나타내는 문자열 배열 relation이 매개변수로 주어질 때, 이 릴레이션에서 후보 키의 개수를 return 하도록 solution 함수를 완성하라.
입출력
- relation은 2차원 문자열 배열이다.
- relation의 컬럼(column)의 길이는 1 이상 8 이하이며, 각각의 컬럼은 릴레이션의 속성을 나타낸다.
- relation의 로우(row)의 길이는 1 이상 20 이하이며, 각각의 로우는 릴레이션의 튜플을 나타낸다.
- relation의 모든 문자열의 길이는 1 이상 8 이하이며, 알파벳 소문자와 숫자로만 이루어져 있다.
- relation의 모든 튜플은 유일하게 식별 가능하다.(즉, 중복되는 튜플은 없다.)
| relation | result |
|---|---|
| [["100","ryan","music","2"],["200","apeach","math","2"],["300","tube","computer","3"], ["400","con","computer","4"],["500","muzi","music","3"],["600","apeach","music","2"]] | 2 |
나의 풀이
level 2의 문제이고 시험 중 두번째로 쉬운 문제였기 때문에 역시나 특별한 방법 없이 꼼꼼히 확인하며 풀어야겠다 생각했다.
나의 경우, 먼저 주어진 relation 의 column 별로 한가지 column을 key 로 잡았을 때 후보키로 가능한 경우를 확인한 후, 가능하지 않은 column 의 index 를 배열 vector<int> notCandidates 에 담아두었다.
이후 notCandidates 에 담긴 column 을 이용해서 2개, 3개, ,, n개를 조합하여 groupKey를 만들었다. 만들어진 groupKey 에 따라 속성을 조합하여 먼저 유일성을 검사한다.
유일성 검사에 통과한 groupKey를 대상으로 최소성 검사를 진행하는데 이 과정이 제일 고민스럽고 어려웠지만 그냥 단순 무식하게 했다. 시험에서 이렇게 출제되어도 그게 제일 빠를 것 같아서,, 나에겐,, ㅎ
만약 groupKey 가 [1,2,3] 이라면 현재 확인된 후보키 중에 [1], [2], [3], [1,2], [1,3], [2,3] 있는지 확인하고 모두 없다면 최소성 검사를 통과시켜 새로운 후보키로 저장한다.
이후 마지막에 저장된 후보키들의 갯수 candidateKeys.size() 반환하여 문제를 통과하였다.
코드
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
// keys 에서 r 개 뽑는 모든 조합
vector<vector<int>> getCombination(vector<int> keys, int r){
vector<vector<int>> combinations;
vector<bool> select( keys.size()-r, false);
for (int i = 0; i < r; ++i) select.push_back(true);
do{
vector<int> combi;
for (int i = 0; i < select.size(); ++i) {
if (select[i]) combi.push_back(keys[i]);
}
combinations.push_back(combi);
}while (next_permutation(select.begin(), select.end()));
return combinations;
}
int solution(vector<vector<string>> relation) {
int columnSize = relation[0].size(), rowSize = relation.size();
map<vector<int>, bool> candidateKey; // 최종 후보키들
vector<int> notCandidate;
// 각 column 중에서 후보키가 아닌 notCandidate 구하기
for (int i = 0; i < columnSize; ++i) {
map<string, bool> checkAttribute;
bool able = true;
for (int j = 0; j < rowSize; ++j) {
string attribute = relation[j][i];
if (checkAttribute.find(attribute) != checkAttribute.end()) {
able = false;
break;
}else{
checkAttribute[attribute] = true;
}
}
if (able) candidateKey[{i}] = true;
else notCandidate.push_back(i);
}
for (int r = 2; r <= notCandidate.size(); ++r) {
vector<vector<int>> groupKeys = getCombination(notCandidate, r);
// r 개씩 뽑은 모든 groupKey 별로 유일성, 최소성 검사
for (int i = 0; i < groupKeys.size(); ++i) {
map<string, bool> checkAttribute;
bool able = true;
// 유일성 검사
for (int j = 0; j < rowSize; ++j) {
string groupAttribute = "";
for (int k = 0; k < groupKeys[i].size(); ++k) {
groupAttribute += relation[j][groupKeys[i][k]];
}
// 이미 존재하는 조합이면
if (checkAttribute.find(groupAttribute) != checkAttribute.end()){
able = false;
break;
}else{
checkAttribute[groupAttribute] = true;
}
}
// 최소성 검사
if (able){
bool isMinimal = true;
for (int j = 1; j < groupKeys[i].size(); ++j) {
// r 개 보다 작은 수의 후보키가 존재하는지 확인
vector<vector<int>> partKeys = getCombination(groupKeys[i], j);
for (int k = 0; k < partKeys.size(); ++k) {
if (candidateKey.find(partKeys[k]) != candidateKey.end()) {
isMinimal = false;
break;
}
}
}
if (isMinimal) candidateKey[groupKeys[i]] = true;
}
}
}
return candidateKey.size();
}