LinkedList의 단점은 리스트내에서 무언가를 찾고싶을때 시간복잡도입니다.
모든 요소를 살펴봐야하기 때문에 비효율적입니다.
그래서 빠르게 찾거나, 삭제, 추가를 할 수있는 자료구조에 대해 알아보겠습니다.
해시 (hash)
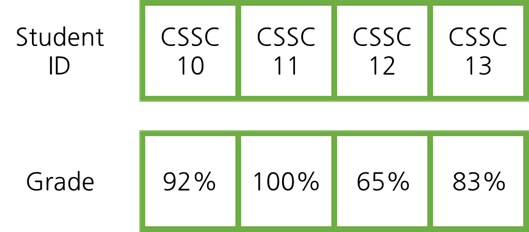
위 예시는 순서대로 학생아이디와 학생의 점수입니다. 학생의 점수를 빠르게 알려면
학생과 점수를 연결시켜주는 자료구조가 있어야합니다.
리스트에서는 cssc13의 점수를 찾기위해 첫 요소부터 13까지 한개씩 확인해야합니다. 즉 시간복잡도는 입니다.
이러한 단점을 해결하여, 데이터를 빠르게 추가하거나 제거하도록 한 데이터 구조가 해시입니다.
해시는 키, 그리고 그와 연관된 값을 가지고 있습니다.
모든 요소를 살펴본 후 동일한 노드를 찾는 연결 리스트와 달리, 해시에서는 키가 주어지면 바로 그와 연관된 값을 찾을 수 있습니다.
해시함수 (hash Function)
해시 함수를 작성할 때는 아래와 같은 점들을 고려해야 합니다.
- 데이터의 속성
예를 들어, CSSC 아이디가 있다면 CSSC 부분을 제거해야 합니다.- 빠른 연산 속도
- 같은 요소인 경우엔 같은 값을 반환
- 같은 실행 환경일 경우 같은 객체라면 같은 값 반환.
- 코드를 새로 실행하면 객체가 같더라도 다른 값이 나올 수 있음.
객체를 비교하면 메모리 주소로 비교를 하게 되는데 코드는 새로 실행할때마다 다른 위치에 할당되므로 hashCode로 덮어씌우지 않으면 다른 값이 반환될 수 있기 때문입니다.- 코드에서 최대한 충돌이 일어나지 않도록 해야 함.
해시충돌 (Collision)
서로 다른 값을 가진 키가 일치하는 경우를 해시 충돌이라고 합니다.
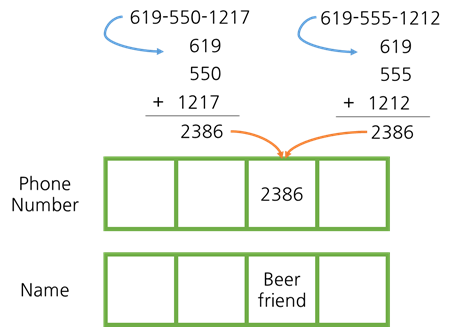
위 사진에서는 전화번호를 3분할한 것의 합을 키로 지정하였습니다.
그런데 키가 2386으로 같아 해시 충돌이 발생합니다.
해시함수에서의 문자열
해시에 저장하고 싶은 문자열이 있는 경우 이 문자열을 먼저 숫자로 바꿔야합니다.
문자열은 유니코드로 변환 해 숫자형태로 나타낼 수 있습니다.
따라서 문자열의 각 문자를 유니코드로 변환하고 그 숫자들을 더하면 숫자로 문자열을 표현할 수 있습니다.
그러나 이 경우에는 충돌이 여러번 일어날 수 있습니다.
this, hits, tish 등 이런 문자들은 유니코드로 변환했을때 같은 숫자로 표현되기때문입니다.
이 문자열들이 다른 값을 가지게하려면 각 문자의 위치까지 고려해주어야합니다.
그 방법으로 문자의 위치만큼 제곱해 사용합니다.
그러면 문자열들이 모두 다른 숫자를 반환하고 이 값들을 배열에 넣어서 키로 사용할 수 있습니다.
public int hashCode(String s) {
int g=31;
int hash=0;
// 문자열을 숫자로 나타내기
// 상수 g를 문자의 위치만큼 제곱한 뒤 곱합니다.
for (int i=0; i<s.length; i++)
hash = g*hash + s.charAt(i);
return hash;
}해시크기 최적화
앞서 말했듯이 해시충돌은 이미 요소가 있는 곳에 다른 요소를 추가하려고 할 때 일어납니다.
이 충돌을 피하기위해 해시크기 최적화를 해야합니다.
이 최적화 방법에는 아래 예시를 포함해 여러가지가 있을 수 있습니다.
- 예시 1: 해시의 크기를 홀수로 설정하여 % 연산자를 사용했을 때 다양한 결과가 나오게 합니다.
- 예시 2: 해시의 크기를 소수로 설정하여 나머지가 다양한 숫자가 나오게 합니다.
양수 변환
8 비트 2의 보수는 정수를 표현하는 방법입니다.
0 0 0 0 0 0 0 0 = 0
0 0 0 0 0 0 0 1 = 1
0 0 0 0 0 0 1 0 = 2
.
.
0 1 1 1 1 1 1 0 = 126
0 1 1 1 1 1 1 1 = 127
127은 8비트 부호로 표현할 수 있는 가장 큰 숫자입니다.
반대로
1 1 1 1 1 1 1 1 = -1
1 1 1 1 1 1 1 0 = -2
.
.
1 0 0 0 0 0 0 1 = -127
1 0 0 0 0 0 0 0 = -128
자바에서 정수는 첫번째 숫자로 부호를 표현합니다.
그래서 정수를 반환하는 hashCode함수는 음수와 양수를 모두 반환 할 수 있습니다.
배열의 인덱스는 음수가 될 수 없기때문에 첫 비트가 1인경우 0으로 바꿔주어야합니다.
그리고 배열의 크기만큼 % 나머지 연산을 하면 데이터를 추가할 수 있는 위치가 나옵니다.
이 과정을 작성하면 아래와 같습니다.
int hashval = data.hashCode(s);
hashval = hashval & ox7FFFFFFF;
hashval = hashval % tableSize;LoadFactor
배열에 요소가 얼마나 차있는가를 LoadFactor(적재율)이라고 합니다.
적재율은 자료구조에있는 항목 수를 자료 구조의 크기만큼 나눈 값으로 기호로는 λ로 표기합니다.
예를 들어 100인배열에 25칸이 차있으면 적재율은 0.25λ입니다.
적재율의 크기에 따라 해시 충돌이 일어나지 않도록 해시의 크기를 조절해주어야합니다.
해시 충돌 해결
해시 충돌 해결방법에는 선형조사법, 2차식 조사법, 이중 해싱이있습니다.
선형조사법
빈 공간을 찾을 때까지 다음 칸을 확인하는 방법입니다. 그리고 빈 공간을 찾았다면 위치가 바뀌었다는 사실을 알려야합니다.
요소를 제거할때도 제거할 칸을 null로 표현하는 것이 아니라, 그 칸이 비어있는 표식을 해야합니다. null로 바꾸었다면 요소를 탐색할때 null을 마주치면 탐색을 종료하기 때문입니다.
이렇게 선형 조사법은 해시값에서 시작해 null에 도착할때까지 1씩 더하고 그 위치에 저장합니다.
다만 선형조사법은 데이터가 뭉쳐지게 되므로 비효율적인 방법입니다.
2차식 조사법
선형조사법의 문제점을 해결하기위해 사용합니다.
2차식 조사법은 요소를 넣으려 하는데 공간이 차있으면 그 값의 제곱만큼 더한 칸을 확인하는 방법입니다.
다시말해 1의제곱을 했는데 그 위치가 차있으면 2의제곱, 3의제곱을 하면서 남는 공간을 찾아갑니다.
만약 마지막 공간을 넘어갔다면 % 연산으로 다시 범위 안에 들어오게 합니다.
이중 해싱
hashCode 함수가 2개 있어 채우려는 공간이 이미 차 있다면 두 hashCode의 결과를 더한 값을 테이블 내의 위치가 되게 하는 방법입니다.
이중 해싱은 아예 다른 해시 함수를 사용할 수 있기 때문에 데이터를 더 골고루 넣을 수 있습니다. 하지만 해시 함수가 2개 필요하다는 단점이 있습니다.
