Example: 1x1 Convolution
이번 예시는 필터 사이즈가 1x1인 경우입니다.

이 경우에는 레이어를 아무리 쌓아도 이전 레이어에 대응하는 1 x 1 영역만 계속해서 가져오기 때문에 receptive field도 1x1입니다. 56x56 이미지 각 한 칸 한 칸에 대해 독립적으로 neural network를 쌓는 구조로 볼 수 있습니다.
Convolution Summary
Conv 레이어의 총 정리입니다.

Weight matrix와 output 사이즈는 자동으로 결정됩니다.
Parameter는 모델이 학습을 통해 자동으로 최적화하는 값이며, Hyperparameter는 학습 전에 유저가 설정해야 하는 값(예: 학습률, 배치 크기, 필터 크기 등)입니다. Hyperparameter로 정해야할 것이 너무 많기 때문에 주로 활용하는 세팅이 정해져 있습니다.
PyTorch Convolution Layer
pytorch에서 conv 레이어를 정의하는 방법에 대해 알아보겠습니다.
아래는 2D Convolution Layer 정의 코드입니다.
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias, padding_mode)- in_channels (C_in): 입력 채널의 개수 (RGB라면 3)
- out_channels (C_out): output 채널의 개수 (필터의 개수)
- kernel_size (K): 필터 크기
- stride (S): 필터가 움직이는 간격 (1이 기본)
- padding (P): 패딩 개수 (0이 기본)
- bias: bias텀 유무 (boolean)
- padding_mode: padding을 뭘로 채울 것인지 (0으로 채우는 'zeros'이 기본)
y=torch.nn.conv2d(~~)(x)는 클래스이므로, 정의 후에는 해당 객체를 호출하여 입력 데이터에 적용해야 합니다.
Pooling Layers: Another way to downsample
ConvNet의 요소 중 Convolution Layers에 이어 살펴볼 두 번째는 Pooling Layers입니다.
Downsampling이란 input의 가로 세로를 줄이는 것으로, Kernel size(필터 크기) 외에 다른 방법인 Pooling을 이용하여 줄일 수 있습니다. Pooling layer의 종류에는 Max Pooling과 Average Pooling이 있습니다.
Max Pooling
Max Pooling을 위해서는 Kernel size(필터 크기)와 stride가 필요합니다.
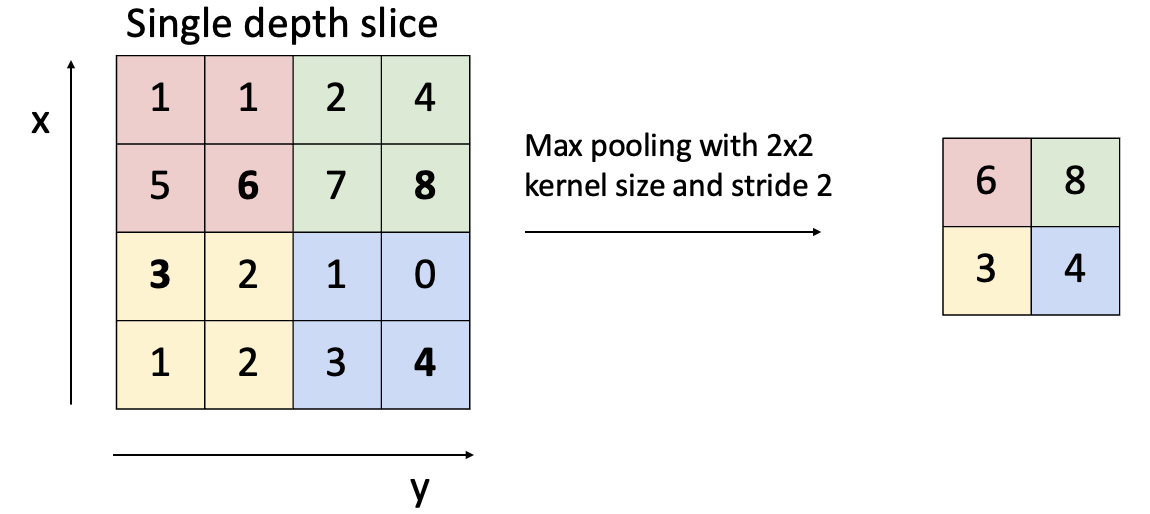
2x2영역에서 max값만 뽑아내는 것입니다. input이미지가 공간적으로 조금씩 이동하는 것은 크게 영향을 미치지 않습니다.
Pooling Summary

K x k에서 max를 뽑고, s만큼 이동합니다.
Learnable parameter가 없다. (업데이트할 파라미터가 없다) #중요
Convolutional Networks
지금까지 Fully-Connected Layers, Activation Function, Convolution Layers, Pooling Layers에 대해 살펴보았습니다.
이제 Convolution, Pooling을 활용한 CNN architecture 예시를 살펴보겠습니다.
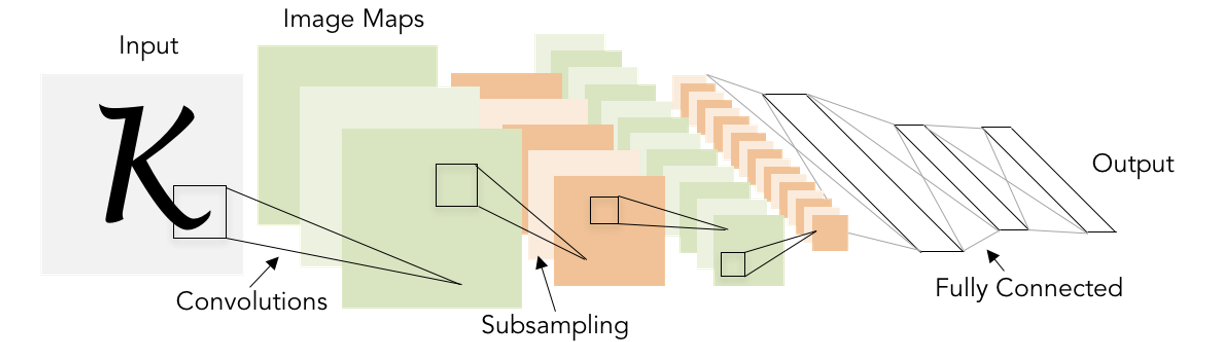
CNN 아키텍처 중 하나인 LeNet-5입니다. LeNet-5의 구조는 다음과 같습니다.
1. Conv - ReLU - Pool(downsampling)를 N번 반복합니다.
2. Cout x H x W를 한 줄로 폅니다. (Fletten)
3. FC - ReLU를 N번 반복하고, 마지막 output은 c차원이 되도록 합니다.
Example: LeNet-5
1. Conv - ReLU - Pool(downsampling)를 N번 반복합니다.
input: 1채널, 28×28 크기
1번째 반복
Convolution Layer (Conv): 필터 20개, 커널 크기 5×5
필터가 20개이므로 출력 크기는 20x28x28
가중치 크기는 20×1×5×5 (필터 20개, 입력 채널 1개, 필터 5×5)
ReLU는 nonlinear 효과만 주고 파라미터 관여 X이므로, 출력 크기는 20x28x28
MaxPooling에서 K=2, s=2로 주고 크기를 반으로 다운샘플링 시킨다. 출력 크기는 20x14x14.
2번째 반복
Convolution Layer (Conv): 필터 50개, 커널 크기 5×5
패딩(P=2), 스트라이드(S=1)
필터가 50개이므로 출력 크기는 50x14x14
가중치 크기는 50×20×5×5 (필터 50개, 입력 채널 20개, 필터 5×5 크기)
ReLU는 nonlinear 효과만 주고 파라미터 관여 X이므로, 출력 크기는 50x14x14
MaxPooling에서 K=2, s=2로 주고 크기를 반으로 다운샘플링 시킨다. 출력 크기: 50×7×7
2. Cout x H x W를 한 줄로 폅니다. (Fletten)
Flatten: Fully Connected Layer에 입력하기 위해 3D 텐서를 1D 벡터로 변환합니다. 50×7×7=2450 차원으로 변환됩니다. 출력 크기: 2450
3. FC - ReLU를 N번 반복하고, 마지막 output은 c차원이 되도록 합니다.
Fully Connected Layer (Linear 2450 → 500): Flatten된 데이터를 받아 500개의 뉴런으로 변환합니다. 출력 크기: 500x500 가중치 크기: 2450 × 500
선택된 뉴런 수인 500인 모델 설계자가 직접 설정한 하이퍼파라미터.
ReLU는 nonlinear 효과만 주고 파라미터 관여 X이므로, 출력 크기는 500
Fully Connected Layer (Linear 500 → 10): 500개의 뉴런에서 최종적으로 10개의 뉴런(클래스)를 출력합니다 (MNIST 숫자 분류: 0~9). 출력 크기: 10x10 가중치 크기: 500×10
10도 모델 설계자가 직접 설정한 하이퍼파라미터.
Problem: Deep Networks very hard to train!
레이어를 쌓으면 쌓을수록 학습이 어려워집니다. 즉, training 단계에서 loss function이 충분히 낮아지지 않기 때문에 optimization이 잘 되지 않습니다.
이를 해결하기 위해 많이 쓰이는 방법인 Batch normalization을 소개하겠습니다.
Batch Normalization
Batch Normalization은 딥러닝 모델의 각 레이어를 지날 때 출력값(activation)을 정규화(normalize)해주는 방법입니다. 레이어를 한 번 지날 때마다 나온 결과를 normalizaion을 해주고 다음 레이어에 input 시켜줍니다.
normalizaion의 목적은 출력값의 분포를 안정적으로 만들어 최적화가 빠르게 이루어지게 도와주고, overfitting을 줄이는 것입니다.
공간적 정보가 없는 Fully Connected layer 상황에서, Batch Normalization가 어떻게 적용되는지 살펴보겠습니다.
- N: batch size
- D: Variable 수 (이전 hidden 노드의 수)
현재 input된 배치 개수에 대해서 mean, std를 구하고, 매 레이어를 지날때마다 normalize를 해줍니다.
"항상 정규화하면 모델이 너무 제약적이지 않을까?"라는 문제가 있습니다. 이처럼 정규화된 값만 사용하면 출력의 스케일(크기)과 위치(중심값)가 제한되어 학습이 비효율적일 수 있습니다.
이를 해결하기 위해 learnable parameter인 감마(𝛾)와 베타(𝛽)를 추가합니다. 𝛾와 𝛽를 learnable rate로 설정하여, variance를 유지하고 mean을 취한 후에 다음 layer에 넣어줍니다.
BN을 쉽게 비유해보면:
- 평균(mean)과 분산(variance) 계산: 데이터를 정리해서 "일단 평균과 범위를 맞추자!"라고 말하는 단계.
- 정규화: 데이터를 평균 0, 범위 1로 표준화. (마치 체육복을 입힌다고 생각해보세요.)
- 와 : "체육복을 입혔지만, 필요하면 다시 옷을 맞추자"라는 단계.
- : 옷 크기를 키우거나 줄임. (범위 조절)
- : 체육복 위치를 옮김. (평균 이동)
Batch Normalization: Test-Time
Batch Normalization은 N개씩의 미니배치(batch)를 기반으로 평균(mean)과 분산(variance)을 계산하여 정규화를 합니다.
Training 단계에서는 매번 들어오는 배치의 데이터로 평균과 분산을 계산합니다. 즉, 각 배치에서 실시간으로 계산합니다. 그러나 Val/Test 단계에서는 배치 크기가 1개거나(한 샘플씩 예측) 배치 크기가 일정하지 않을 수 있습니다. 이 경우, 실시간으로 배치의 평균과 분산을 계산하기 어렵습니다.
해결 방법으로는, Training 단계마다 기록되는 mean, variance을 저장했다가 테스팅 단계에서도 사용하는 것입니다.
- Training 단계: 각 미니배치마다 평균 μ와 분산 를 계산합니다. 모든 배치에서 계산된 평균과 분산을 축적하여 모든 데이터의 전역 평균(global mean)과 전역 분산(global variance)을 계산합니다.
- Test 단계: Test 데이터의 개수에 관계없이 Training 단계에서 저장된 global_mean과 global_variance를 사용해 정규화합니다.
따라서 유의할 것으로, Training과 Test 단계에서 동일한 동작을 하지 않기 때문에 코드 구현이 달라져야 합니다.
또한 Batch도 linear 연산이므로, 특정 조건에서 연산을 합쳐 효율성을 높일 수 있습니다. 즉, Linear(FC or Conv)-linar와 붙어있다면 연산을 하나로 합쳐서 저장할 수 있습니다.
Batch Normalization for ConvNets
Convolutional Neural Networks에서 batch normalizaion가 어떻게 진행할지 알아보겠습니다.
Convolutional Neural Networks는 이미지 데이터를 다루므로, 데이터가 4차원 텐서로 표현됩니다.

BN은 Convolutional Layer에서 각 채널에 대해 정규화를 적용합니다. 각 데이터(N은 데이터 개수) 안에서 각 채널의 데이터를 기준으로 평균과 분산을 계산합니다. 같은 채널의 모든 픽셀(가로와 세로)의 값을 평균내고 분산을 구하기 때문에 각 채널을 하나의 전체적인 값으로 간주합니다.
BN은 채널별로 계산된 평균과 분산을 사용하여 각 채널에 대해 동일한 방식으로 정규화를 적용합니다.
Batch Normalization
batch normalizeation은 일반적으로 FC 또는 Conv layer (nonlinear activation) 사이에 넣습니다.

batch normalizeation의 장점은 다음과 같습니다.
- 더 적은 iteration으로 더 높은 accuracy를 달성합니다.
- deep network에도 학습이 잘 됩니다.
- Training 단계에서 regularizaion의 효과가 있습니다.
- Test단계에서 추가적인 계산이 필요 없습니다.
batch normalizeation의 한계는 다음과 같습니다.
- BN이 왜 그렇게 잘 작동하는지에 대한 명확한 이론적인 설명은 아직 부족합니다.
- Training과 Test의 작동 방식이 달라 코드 버그가 발생할 가능성이 높습니다.
Layer Normalization
Batch normalizaion 이후, 새로운 normalization 방법들이 제안되었습니다.
Batch Normalizationm (Fully-Connected Network)
- μ, σ: 1xD
- 배치 크기(N)는 BN에서 계산에 사용되지 않으며, 대신 D(특성 차원, 예를 들어 각 뉴런의 출력값)에 대해 평균과 표준편차가 배치 내 모든 샘플에 대해 구해집니다. 따라서 1xD 크기의 평균과 표준편차가 계산되어 배치 크기(N)와는 무관하게 모든 샘플에 대해 동일한 평균과 표준편차를 사용하여 정규화됩니다.
- γ, β: 1xD
- 감마와 베타는 각 채널(C)에 대해 하나씩만 존재합니다. 즉, 각 채널을 따로 scale(γ)하고 shift(β)할 수 있습니다. BN에서는 배치 내 모든 샘플이 동일한 γ와 β 값을 공유합니다.
Layer Normalization (Fully-Connected Network)
- μ, σ: NxD
- 배치 내 각 샘플(N개)에 대해 각 샘플의 특성 차원(D)에 대해 평균과 표준편차를 계산합니다. 즉, 각 샘플에 대해 독립적으로 평균과 표준편차를 계산하며, 이 계산은 배치 크기(N)와 특성 차원(D)에 따라 달라집니다.
- γ, β: 1xD
- 감마(γ)와 베타(β)는 특성 차원(D)에 대해 하나씩 존재합니다. 즉, 각 특성 차원마다 별도로 scale(γ)과 shift(β)를 수행할 수 있습니다. 하지만 배치 내 샘플들은 각각 독립적으로 정규화되므로, γ와 β는 배치 내 샘플들에 대해 동일하게 적용됩니다.
Instance Normalization
Batch Normalization (Convolutional Network)
- μ, σ: 1xCx1x1
- 배치 크기 N에 관계없이 각 채널(C)에 대해 하나의 평균과 표준편차 값이 계산됩니다. 따라서 배치 크기와 높이/너비에 관계없이 각 채널별로 하나의 평균과 표준편차만 존재합니다. 배치 크기(N)는 무시되고, 각 채널에 대해 1개의 평균과 표준편차가 존재합니다.
- γ, β: 1xCx1x1
- 감마와 베타는 각 채널(C)에 대해 하나씩만 존재합니다. 즉, 각 채널을 따로 scale(γ)하고 shift(β)할 수 있습니다. BN에서는 배치 내 모든 샘플이 동일한 γ와 β 값을 공유합니다.
Instance Normalization (Convolutional Network)
- μ, σ: NxCx1x1
- 배치 크기 N과 채널 C마다 각각의 평균과 표준편차가 계산됩니다. 즉, 배치의 각 인스턴스(샘플)마다 각 채널별로 평균과 표준편차가 계산되어 정규화됩니다. 배치 크기(N)가 다르면, 각 배치마다 독립적인 평균과 표준편차를 사용합니다.
- γ, β: 1xCx1x1
- 감마와 베타는 여전히 채널별로 하나씩 존재합니다. 즉, 각 채널을 scale하고 shift할 수 있는 파라미터가 존재하지만, 배치에 관계없이 채널 단위로 적용됩니다.
Comparison of Normalization Layers
Batch Normalization (Batch Norm), Layer Normalization (Layer Norm), Instance Normalization (Instance Norm)을 3D 텐서 형태로 설명하고 있습니다. 각 Normalization 방법은 어떻게 데이터를 Normalize하는지에 따라 다르게 작용하는데, 각 Normalization가 텐서에서 어떤 차원에 대해 계산을 수행하는지 보여줍니다.
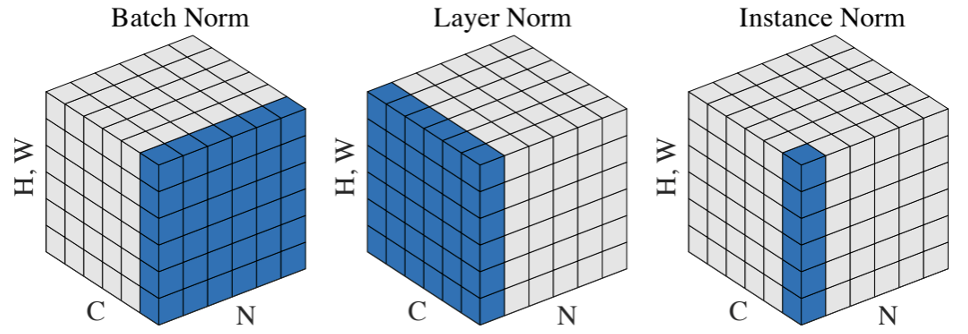
H, W는 텐서의 Height와 Width를 나타냅니다. C는 Channel 수를 의미하고, N은 Batch size (배치 크기)를 나타냅니다.
Batch Normalization 이미지에서 파란색 영역: Channel별로 평균과 표준편차를 계산합니다. 배치 내 샘플들을 함께 고려해서 각 채널에 대해 계산합니다. 즉, 채널마다 하나의 평균과 표준편차가 계산되고, 배치 크기가 계산에 영향을 미칩니다.
Layer Normalization 이미지에서 파란색 영역: Batch별로 평균과 표준편차를 계산합니다. 각 샘플(배치의 각 인스턴스)에 대해 모든 특성을 평균내고 표준편차를 계산합니다. 배치 크기와 관계없이 각 샘플에서 특성 차원만을 기준으로 정규화합니다. 배치 내 각 샘플을 독립적으로 정규화합니다.
Instance Normalization 이미지에서 파란색 영역: 채널과 배치 모두에서 독립적으로 평균과 표준편차를 계산합니다. 각 샘플에 대해 각 채널별로 독립적인 평균과 표준편차를 계산하고 정규화합니다. 즉, 배치 내 각 샘플과 각 채널에 대해 독립적으로 계산됩니다.
Batch Normalization: Channel별로 평균과 표준편차를 계산 (Batch 크기 상관 O)
Layer Normalization: Batch별로 평균과 표준편차를 계산 (Batch 크기 상관 X)
Instance Normalization: Channel, Batch 모두에서 독립적으로 평균과 표준편차를 계산 (Batch 크기 상관 X)
컨볼루션 네트워크를 구성하려면, Conv- activation - pooling 사이에 normalizaion를 사용하다가 FC를 쌓아서 output을 낸다.
