Supervised learning
Supervised learning(지도 학습)의 목표는 새로운 입력에 대한 최상의 출력을 예측하는 것입니다.
미래 실적을 예측하는 방법은 minimize empirical risk(경험적 위험 최소화)가 있습니다. 이는 주어진 데이터에 대해 loss function의 평균값을 최소화하여 모델을 최적화합니다.
Tranditional and deep learning
- 전통적 비전 pipeline
- 클래식 머신 러닝 pipeline
- 딥러닝 pipeline
Cross-entropy Loss (Multinomail Logistic Regression)
Cross-entropy Loss는 확률 관점에서 Maximum Likelihood Estimation (MLE)를 수행하는 방법과 동일합니다.
Cross-entropy Loss는 분류 문제에서 모델이 예측한 확률 분포와 실제 레이블(정답)의 분포 간 차이를 측정하는 데 사용됩니다. 이 Loss를 최소화하는 것은, 모델이 올바른 정답에 대해 가장 높은 확률을 예측하도록 만드는 과정입니다.
MLE는 주어진 데이터를 생성했을 가능성이 가장 높은 매개변수를 찾는 방법입니다. 이 과정은 데이터가 주어졌을 때, 모델의 예측 확률(우도, likelihood)을 최대화하는 것과 동일합니다.
Cross-entropy Loss는 MLE의 목적을 손실 함수의 형태로 변환하여 최적화를 가능하게 한 방식이라고 볼 수 있습니다.
Lecture 5: Neural Networks
Problem: Linear Classifiers aren’t that powerful
이번 장의 목표는 linear 모델의 성능이 나쁜 것을 Neural Networks(신경망)를 사용해서 해결하고자 합니다.
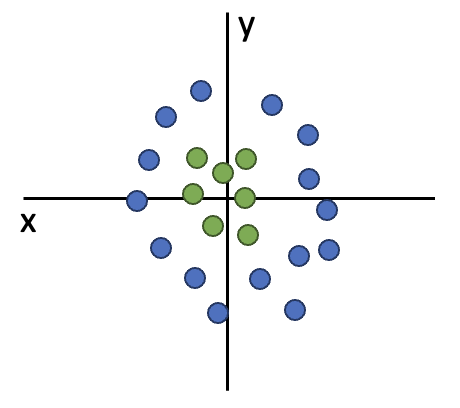 linear classifier로는 이런 형식의 데이터는 좋은 성능으로 분류할 수가 없습니다.
linear classifier로는 이런 형식의 데이터는 좋은 성능으로 분류할 수가 없습니다.
 클래스당 하나의 템플릿만 가질 수 있기 때문에, 실제로 같은 클래스라도 템플릿과 다른 생김새면 그 클래스로 인식될 수가 없습니다.
클래스당 하나의 템플릿만 가질 수 있기 때문에, 실제로 같은 클래스라도 템플릿과 다른 생김새면 그 클래스로 인식될 수가 없습니다.
이러한 linear classifier의 성능을 보완하기 위해 여러 레이어를 겹쳐 비선형성을 추가한 Neural Networks으로 복잡한 데이터를 처리합니다.
Feature Transforms
linear 모델의 성능을 끌어올리기 위한 전통적인 방법으로 Feature Transforms가 존재합니다. 하지만 해당 방법을 사용하기 위한 조건이 현실적으로 적용될 수 없기에 다른 방법을 사용합니다.
Activation Functions
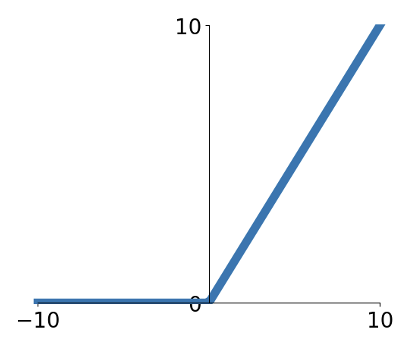
가장 일반적으로 사용되는 Activation Function는 ReLU입니다. 특징으로는, x값이 0보다 작으면 0을 출력하고, 0보다 크면 그대로 출력하게 됩니다.
Neural Networks
기존의 Linear function은 의 형태를 가집니다. 하지만 레이어를 한 개 더 쌓은 2-layer Neural Network은 다음과 같이 표현됩니다. (ReLU를 사용한 예시)
이렇듯 max를 사용하는 것을 Activation function이라고 합니다.
max을 사용하는 이유는 W가 선형성을 띄기 때문입니다. max 없이 단순히 곱하게 된다면 선형성에 의해 결합 법칙이 성립하여, 레이어를 몇 개를 쌓든 레이어 한 개와 같은 효과가 됩니다.
이를 방지하기 위해 Activation Function을 이용하여 각 레이어의 비선형성을 유지하고자 합니다. 형태는 '선형(비선형(선형 변환(x))'의 형태로, 선형과 비선형의 합성함수를 계속 반복하여 적용합니다.
예시는 아래와 같습니다.
- layer 2개: 2개의 weight, 1개의 nonlinear activation 이용
- layer 3개: 3개의 weight, 2개의 nonlinear activation 이용
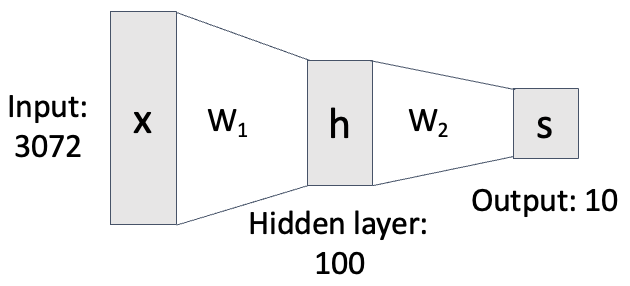
아래는 2-layer Neural Network를 그림으로 표현한 형태입니다.
여기서 은 템플릿 역할을 합니다. 이전 시간에서 W의 row 한 개(class 하나에 대응)를 그림처럼 나타낸 것이 templete이라고 하였습니다.
hidden layer는 Neural Network에서 input layer와 output layer 사이에 위치한 층을 말합니다. 입력 데이터를 비선형적으로 변환하여 더 복잡한 패턴이나 관계를 학습할 수 있도록 도와줍니다.
h 하나를 만들기 위해 템플릿()을 한 번 매칭한 후, 새로 만들어진 템플릿()을 다시 한 번 조합하는 것입니다. 레이어가 두 개가 되면 horse에 대한 템플릿이 여러 개일 때 조합할 수 있게 됩니다.
 이전에는 모습 하나만 있었던 말 템플릿이, 레이어가 두 개가 되면서 여러 모드로 표현되었습니다. 그러나 학습된 템플릿이 복잡해지면서, 인간이 이를 해석하기 어려워지는 단점도 존재합니다.
이전에는 모습 하나만 있었던 말 템플릿이, 레이어가 두 개가 되면서 여러 모드로 표현되었습니다. 그러나 학습된 템플릿이 복잡해지면서, 인간이 이를 해석하기 어려워지는 단점도 존재합니다.
(+) Fully-connected neural network은 같은 말로 Multi-Layer Preception이라고도 합니다. 이는 모든 뉴런이 이전 레이어의 모든 뉴런과 연결된 구조로, Neural Network의 기본 구조입니다. 이전 레이어의 모든 백터들이 다음 레이어의 모든 백터에 영향을 미치게 됩니다.
Deep Neural Networks
따라서 10개의 output를 가지는 6-layer Neural Network의 수식은 다음과 같습니다. 또한 W6을 구하기 위해서는, 10xh5가 됩니다.
