📊 사례별 코드 차이 및 실행 결과 분석
1. [1번 vs 2번] 비교: "SELECT 다이어트의 중요성"
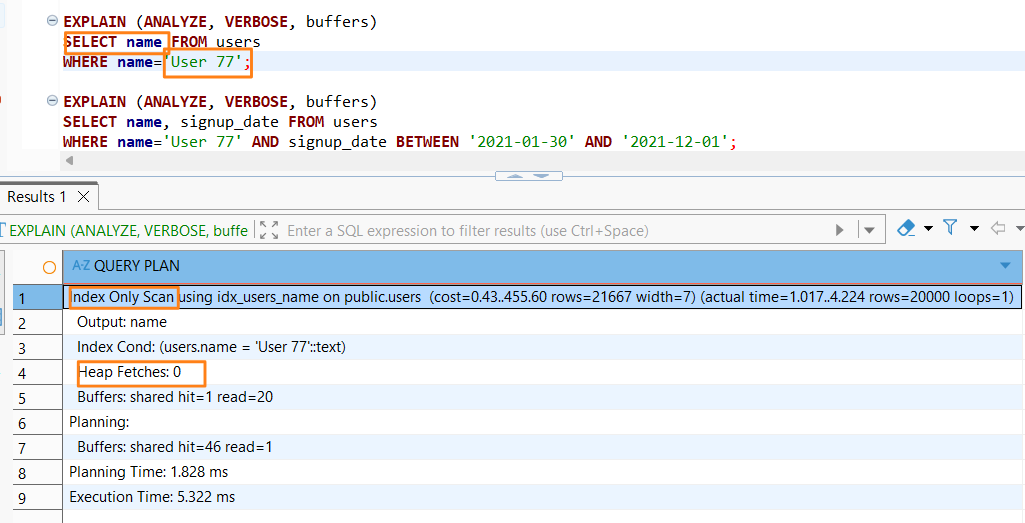
- 차이점: 1번은
SELECT *(모든 컬럼)을 가져오고, 2번은 인덱스에 있는name컬럼만 가져옵니다. - Plan 변화: Bitmap Heap Scan (1번) → Index Only Scan (2번)
- 결과 해석: 1번은 인덱스(
name)에 없는id,email,signup_date를 찾으러 실제 데이터 테이블(Heap)로 가야만 했습니다. 반면, 2번은 Planner(플래너)가 "인덱스만 봐도 답이 다 있네?"라고 판단해 테이블 근처에도 가지 않았습니다. - 학습 한 줄 정리: 불필요한 컬럼을 버리는 'SELECT 다이어트'만으로도 디스크 방문(Heap Scan)을 막을 수 있습니다.
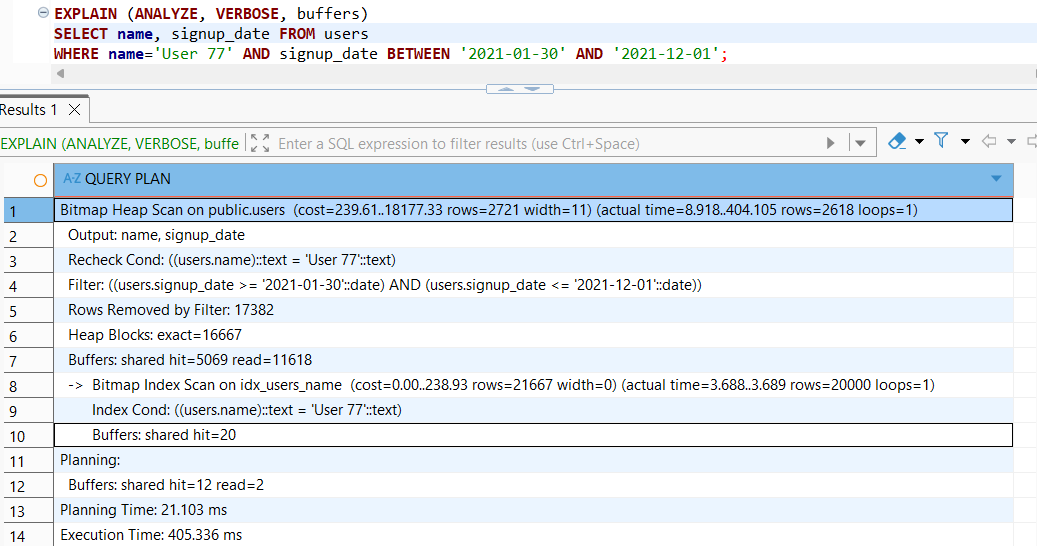
2. [2번 vs 3번] 비교: "인덱스 범위를 벗어난 필터"
- 차이점: 3번은
WHERE절에 인덱스에 없는signup_date조건을 추가하고,SELECT결과에도 포함했습니다. - Plan 변화: Index Only Scan (2번) → Bitmap Heap Scan (3번)
- [cite_start]결과 해석: 3번은 인덱스에 없는
signup_date를 확인하고 출력해야 하므로, Executor(실행기)가 실제 데이터 파일 영역을 뒤져야 하는 비싼 비용(Cost)을 지불하게 된 것입니다[cite: 324, 331]. - 학습 한 줄 정리: 인덱스에 없는 컬럼을 조건이나 결과에 넣는 순간, '인덱스 전용 스캔'의 마법은 풀립니다.
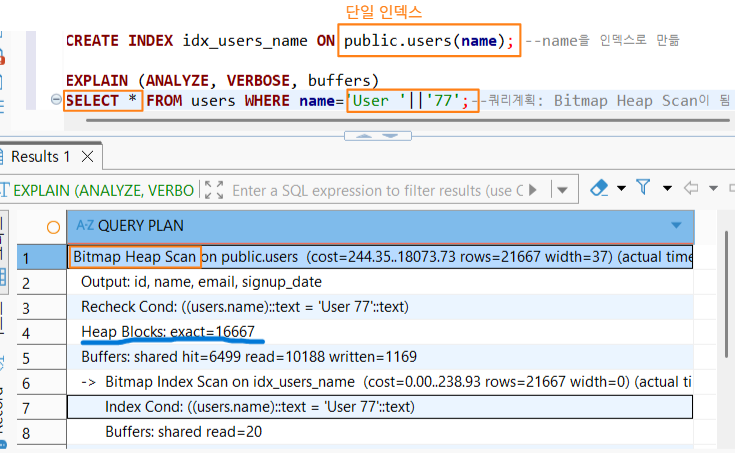
3. [3번 vs 4번] 비교: "단일 인덱스 vs 복합 인덱스"
- 차이점: 3번은
name만 있는 인덱스고, 4번은(name, signup_date)가 묶인 복합 인덱스입니다. - Plan 변화: Bitmap Heap Scan (3번) → Index Only Scan (4번)
- 결과 해석: 4번은 자주 같이 쓰이는 두 컬럼을 하나로 묶어버렸습니다. [cite_start]플래너는 이제
signup_date정보까지 인덱스 안에서 모두 찾을 수 있게 되어 다시 가장 빠른 경로를 선택했습니다[cite: 322, 324]. - 학습 한 줄 정리: 자주 함께 쓰이는 필터 조건들은 '복합 인덱스'로 묶어야 플래너가 가장 '싼 비용'의 계획을 세웁니다.
4. [1번 vs 5번] 비교: "인덱스 전용 스캔의 마법, Covering Index"
-
차이점 (Condition): * 1번:
SELECT로 테이블의 모든 컬럼(id,name,email,signup_date)을 요구하지만, 인덱스는name하나만 가지고 있습니다.- 5번:
SELECT id, name, email을 요구하며, 인덱스 생성 시INCLUDE (id, email)를 사용하여 결과에 필요한 데이터를 인덱스 안에 미리 복사해 두었습니다.
- 5번:
-
Plan 변화 (Query Plan): Bitmap Heap Scan → Index Only Scan
-
결과 해석 (Interpretation): * 1번은 인덱스에 없는 나머지 정보를 찾기 위해 Planner(플래너)가 실제 Data Files(Heap) 영역을 뒤져야 한다고 판단했습니다. 이 과정에서 디스크 읽기(
read)가 발생하며 비용이 급증합니다.- 5번은 여러 컬럼을 요구함에도 불구하고, 필요한 모든 데이터가 인덱스라는 '보조 주머니'안에 다 들어있습니다. Executor(실행기)는 무거운 테이블 파일(
base/디렉토리) 근처에도 가지 않고 인덱스만으로 모든 응답을 끝냈습니다.
- 5번은 여러 컬럼을 요구함에도 불구하고, 필요한 모든 데이터가 인덱스라는 '보조 주머니'안에 다 들어있습니다. Executor(실행기)는 무거운 테이블 파일(
- 학습 한 줄 정리: 검색 조건은 아니지만 결과로 자주 쓰이는 데이터는
INCLUDE로 인덱스에 태워두면, '테이블 방문' 없는 초고속 조회가 가능합니다.

이제 개발해야지...