📊 [SQL] 세로 데이터를 가로로! Pivot 완벽 가이드 (CASE WHEN vs CROSSTAB)
데이터를 분석하다 보면, 아래로 길게 나열된 행(Row) 데이터를 엑셀 피벗 테이블처럼 옆으로(Column) 펼쳐야 할 때가 많습니다. SQL에서 이를 구현하는 두 가지 정석 방법을 정리합니다.
1. 가장 클래식한 방법: CASE WHEN + SUM
별도의 설치 없이 모든 SQL 엔진에서 사용할 수 있는 가장 범용적인 방식입니다.
✅ 작동 원리
특정 조건일 때만 값을 남기고, 아니면 0을 주어 합산하는 방식입니다.
SELECT
prod_month,
SUM(CASE WHEN breeds_nm = 'Cornish' THEN total_sum ELSE 0 END) AS "Cornish_Total",
SUM(CASE WHEN breeds_nm = 'Cochin' THEN total_sum ELSE 0 END) AS "Cochin_Total",
SUM(total_sum) AS monthly_total
FROM breeds_prod
GROUP BY prod_month;⚠️ 주의할 점 (삽질 포인트)
- 별칭 사용 주의:
SELECT절에서 만든 별칭(예:prod_month)은 엔진에 따라GROUP BY에서 바로 쓸 수 있지만,SUM으로 만든 결과물 별칭은GROUP BY에서 쓸 수 없습니다. (닭이 먼저냐 달걀이 먼저냐의 싸움 방지!) - 0 또는 NULL: 합계 시
ELSE 0을 써야NULL때문에 전체 합계가NULL이 되는 대참사를 막을 수 있습니다.
2. 전문가의 도구: tablefunc와 crosstab
PostgreSQL을 사용한다면 tablefunc 확장 기능을 사용하여 더 세련되게 피벗할 수 있습니다.
🛠 준비 단계 (Import와 동일)
CREATE EXTENSION IF NOT EXISTS tablefunc;- 의미: DB에 '피벗 전용 도구 상자'를 들여놓는 것. 한 번만 실행하면 됩니다.
🍱 crosstab의 '3단 도시락' 규칙
crosstab 함수는 반드시 딱 3개의 컬럼으로 구성된 쿼리를 입력받아야 합니다.
1. 첫 번째 컬럼: 행의 기준 (예: 부화일자)
2. 두 번째 컬럼: 열(컬럼명)이 될 카테고리 (예: 성별)
3. 세 번째 컬럼: 실제 칸을 채울 값 (예: 마릿수)
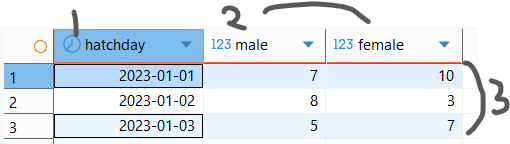
✅ 실행 코드 예시
SELECT * FROM crosstab(
--count는 bigint를 내뱉으므로 int로 형변환
'SELECT hatchday, gender, count(chick_no)::int
FROM chick_info
GROUP BY hatchday, gender
ORDER BY hatchday, gender' -- 반드시 정렬(ORDER BY) 필요!
) AS 별칭(
hatchday date, -- 첫 번째 컬럼 (기준)
male int, -- 두 번째 컬럼 (값)
female int -- 세 번째 컬럼 (값)
); --열 이름의 타입이 아니라 내부 값의 타입을 적어야한단다⚠️ 주의할 점 (삽질 포인트)
- 쿼리는 문자열이다:
crosstab은 함수이므로 내부 쿼리를 통째로 작은따옴표(')로 감싸서 문자열 데이터로 넘겨야 합니다. - 설계도(
AS) 필수:crosstab은 결과 모양을 스스로 알지 못하므로,AS 별칭(컬럼명 타입, ...)으로 결과표의 구조를 명시해줘야 합니다. - 따옴표 규칙: 설계도 안에서 컬럼 이름에 작은따옴표를 쓰면 에러가 납니다. (
'male'❌ →male⭕)

이제 개발해야지...