
테스팅
네, 일반적으로 단위 테스트를 위한 클래스와 통합 테스트를 위한 클래스는 따로 두는 편입니다. 이것은 테스트 전략에서 권장되는 모범 사례 중 하나입니다.분리하는 이유테스트의 목적 및 범위 명확화:단위 테스트: 개별 코드 단위(메서드, 클래스)의 독립적인 기능이 올바르게
트랜잭션 아웃박스, Saga 역할과 범위
네, 정확히 보셨습니다. 트랜잭션 아웃박스 패턴과 Saga 패턴의 역할과 범위가 다르기 때문에, 아웃박스 패턴으로 이벤트 발행의 성공을 보장하더라도, 여전히 Saga 패턴과 보상 트랜잭션이 필요한 상황은 존재합니다.이것이 바로 "메시지 발행의 성공" 과 "분산된 비즈니
동기/비동기 , 블로킹/논블로킹
동기 vs 비동기 > 두 개념은 호출하는 쪽(call site)이 결과를 기다리느냐(동기) 아니면 기다리지 않느냐(비동기)를 구분 동기(Synchronous) – 호출한 메서드가 작업 완료(또는 오류) → 결과 반환 전까지 호출 스레드가 대기 – 장점: 제어 흐름이
05/07 면접 준비/자바의 실행 과정, 스프링과 스프링 부트, 의존성 주입, 스프링 빈
소스 코드 작성개발자가 .java 확장자의 자바 소스 파일을 작성합니다.컴파일자바 컴파일러(javac)가 소스 코드를 바이트코드(.class 파일)로 변환합니다.이 바이트코드는 사람이 읽을 수 없고, JVM이 이해할 수 있는 중간 언어입니다.클래스 로딩실행 시, 클래스
05/07 면접준비/인터페이스와 클래스의 차이, 제네릭
클래스는 객체의 속성과 동작(메서드)을 정의하며, 실제 인스턴스를 생성. 객체지향 프로그래밍의 기본 단위클래스는 멤버 변수와 메서드를 모두 가질 수 있고, 메서드의 구체적인 구현을 포함클래스는 단일 상속클래스는 객체의 설계도이자, 기능의 구체적인 구현을 담당객체를 만들
05/05 면접 준비/ 제어의 역전, 프레임워크와 라이브러리
프레임워크(Framework)와 라이브러리(Library)의 차이는 "제어 흐름의 주도권(제어의 역전, IoC)"라이브러리는 개발자가 필요할 때 직접 호출해서 사용하는 도구애플리케이션의 흐름(Flow)을 개발자가 직접 제어하며, 필요한 기능만 골라서 가져다 씀프레임워크
05/06 면접 준비/개인키,공개키
입력값을 고정된 길이의 해시값으로 변환복호화(원래 값 복원)가 불가능, 동일 입력값 → 항상 동일 해시값대표 예: SHA-256, SHA-512, MD5 등 해시 함수비밀번호 저장, 데이터 무결성 체크, 디지털 서명암호화된 데이터를 복호화(원래 값 복원)할 수 있음대칭
05/05 면접 준비(SpringBoot), HTTP 요청
HTTP GET 요청을 처리주로 데이터를 조회할 때 사용요청 데이터는 URL의 쿼리 파라미터로 전달되며, URL에 노출여러 번 요청해도 결과가 바뀌지 않는 idempotent한 작업에 적합@GetMapping은 데이터를 URL의 쿼리스트링에 포함시켜 전송하므로, 요청
05/04 면접 준비(Java), 문자열 리터럴
String X = "123";X = "0"+X; 의 연산문자열 리터럴 저장:"123"과 "0"은 모두 자바의 String Pool (문자열 상수 풀)에 저장.이 풀은 힙 메모리 내의 특별한 공간으로, 동일한 문자열 리터럴이 여러 번 등장해도 한 번만 저장되고 여러 참
05/02 면접준비(Java)/OOP
//상속, 클래스 상속과 인터페이스 상속의 차이.//Java OOP 정리//캡슐화, 상속, 다형성//정규화, 트랜잭션 정리
05/01 면접 준비(DB)/RDBMS,NoSQL
RDBMS는 구조화된 데이터와 일관성이 중요한 환경일 때NoSQL은 대규모, 다양하고 변화가 많은 데이터를 빠르게 처리해야 하는 환경일 때전통적인 RDBMS는 ACID(원자성, 일관성, 고립성, 지속성)라는 트랜잭션 보장 규칙을 따름.원자성(Atomicity) - 트랜
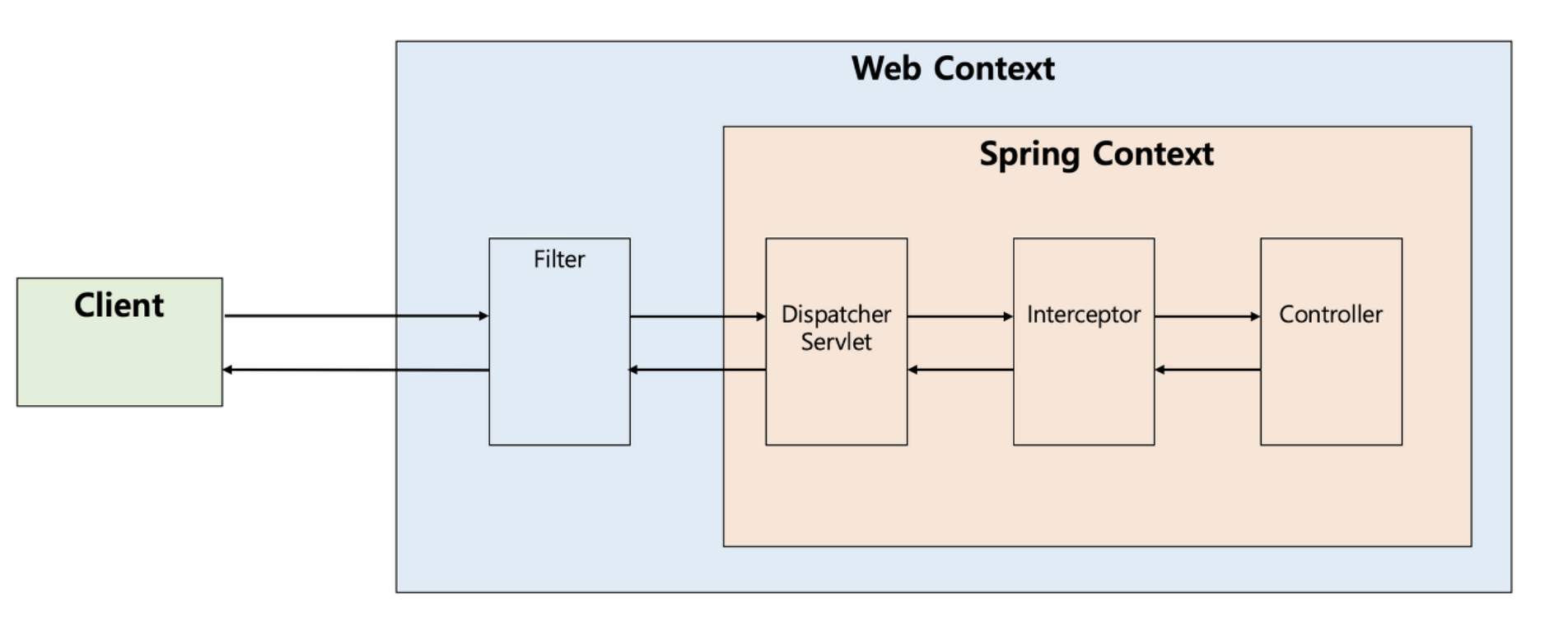
필터와 인터셉터
공통적으로 여러 작업을 처리함으로써 중복된 코드를 제거하도록 하는 기능.디스패처 서블릿에 요청이 전달되기 전/후에 url 패턴에 맞는 모든 요청에 대해 부가 작업을 처리할 수 있는 기능 제공.디스패처 서블릿은 스프링의 가장 맢단에 존재하는 프론트 컨트롤러이므로, 필터는
6. 프레임워크와 라이브러리
개발자가 소프트웨어를 개발함에 있어 코드를 구현하는 개발 시간을 줄이고 코드의 재사용성을 증가 시키기 위해 일련의 클래스 묶음이나 뼈대, 틀을 라이브러리 형태로 제공되는 것. 제어의 역전 개념이 적용된 기술(작성한 객체나 메서드의 제어를 개발자가 아니라 애플리케이션이
해시
여러 길이의 데이터를 효율적으로 관리하기 위해 해시함수를 통해 일정한 길이의 값으로 매핑하는 것.그래서 데이터가 많아지면 같은 해시 값을 가지는 경우가 생겨서 충돌 발생해시는 내부적으로 배열을 사용하여 데이터를 저장하기 때문에 검색 속도가 빠름.임의의 길이의 데이터를
스택과 큐
스택 2개로 큐(FIFO) stack 1과 stack 2 생성 enqueue : stack 1에 원소를 push, O(1) dequeue : stack 2가 비어있을 경우 stack 1의 원소를 pop한 뒤 stack 2에 push 후 stack 2의 top을 pop,
배열과 리스트
배열과 링크드리스트는 데이터를 저장하고 관리하는데 사용되는 두 가지 기본적인 자료구조연속된 메모리 공간에 데이터를 저장인덱스를 사용해서 원소에 빠르게 접근이 가능, O(1)의 시간복잡도.인덱스 : 추가적인 쓰기 작업과 저장 공간을 활용해서 검색속도를 향상시키는 자료구조