PyMySql 설치
pip install PyMySql
이제 사용할 때 import pymysql!
DB 연결 - connect()
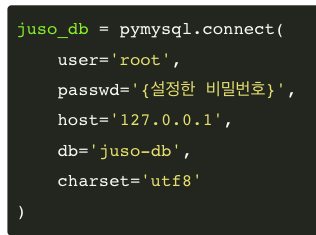
connect() 함수를 이용하면 MySQL host내 DB와 직접 연결할 수 있습니다.
- user: user name
- passwd: 설정한 패스워드
- host: DB가 존재하는 host
- db: 연결할 데이터베이스 이름
- charset: 인코딩 설정
모두 따옴표로 묶어주어 텍스트로 인자를 넘겨야 합니다.
cursor 설정 - cursor()
cursor = juso_db.cursor(pymysql.cursors.DictCursor)
연결한 DB와 상호작용하기 위해 cursor 객체를 생성해주어야 합니다.
다양한 커서의 종류가 있지만,
Python에서 RDBMS(Relational Database System)를 주로 사용하기 때문에
데이터 분석가에게 익숙한 데이터프레임 형태로 결과를 쉽게 변환할 수 있도록
딕셔너리 형태로 결과를 반환해주는 DictCursor를 사용한다.
(보통 그냥 juso.db.cursor() 이렇게도 함 )
하지만 차이가 있다.
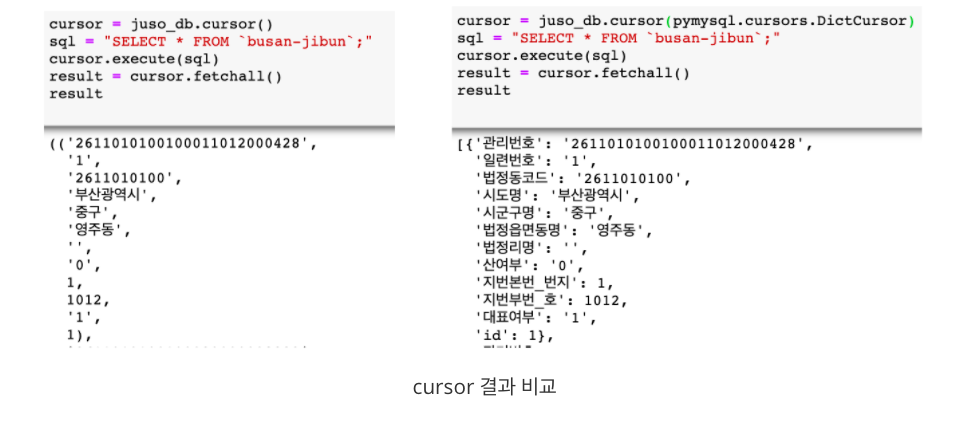
DictCursor가 아닌 일반 cursor를 사용하면 결과가 일반적으로는 튜플 형태로 반영된다.
execute() 와 fetch()
데이터 조회 - SELECT
sql = "SELECT * FROM
busan-jibun;"
cursor.execute(sql)
result = cursor.fetchall()
- SELECT 명령을 위해 SQL 문을 따로 변수에 넣어주고 cursor.execute(sql) 을 사용해 SQL을 실행하고
- 실행한 결과를 fetchall()을 이용해 받아온다.

데이터 삽입/변경/삭제 - INSERT/UPDATE/DELETE
데이터 삽입/변경/삭제를 명령할 때에는 SELECT문 사용과 다르게 변수에 할당하지 않는다.
명령을 DB에 전송한 후 결과를 데이터로 받아오는 것이 아니기 때문
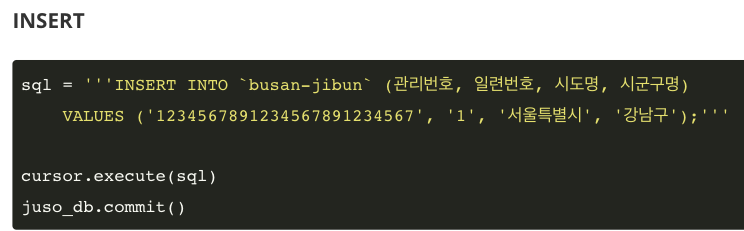
(실험을 위해) 부산 지번 주소 테이블에 서울특별시의 주소를 넣어보겠다.
execute()를 이용해 INSERT 쿼리를 실행한 후, commit()을 날려줍니다.
커밋을 날리지 않으면 execute()를 아무리 해도 결과가 DB에 반영되지 않습니다.
처음에 DB 커넥션을 만들 때 autocommit=True 파라미터를 넣어줄 수도 있지만, 개인적으로 추천하지는 않는다.
보다 안전하게 사용하기 위해 변경할 쿼리문을 한 번 더 확인하고 commit 문을 직접 써주는 것을 추천
UPDATE

DELETE

execute()/executemany()에 Placeholder 사용하기
만약 DB내 데이터에 대해 대량 삽입/변경/삭제가 필요한데, 조건이 다 다르다면?
동적 값이 들어갈 위치에 %s를 이용해 SQL문을 만들어 놓고,
execute() 계열 메서드 첫번째 파라미터에는 SQL을, 두번째 파라미터에 실제 데이터를 리스트나 튜플 형태로 넣어주면 된다.
- excute(SQL, a-data)
- executemany(SQL, multiple-data)
하나의 데이터만 적용시킬 거라면 execute(),
여러 개의 데이터를 한 번에 대량으로 적용시킬 거라면 executemany()
- 두번째 파라미터에 들어간 데이터 순서대로 SQL이 적용되고,
- 특히 문자의 경우 따옴표 등의 특수문자들이 자동으로 이스케이프(Escape)되어 처리됩니다. (완전 간편!)
- 문자열, 숫자 등에 관계 없이 대치할 값은 모두 %s로 쓰입니다. (일반 문자열에서 사용하는 %s, %d와는 다름)
- %s는 컬럼 값을 대치할 때만 사용할 수 있습니다.
example

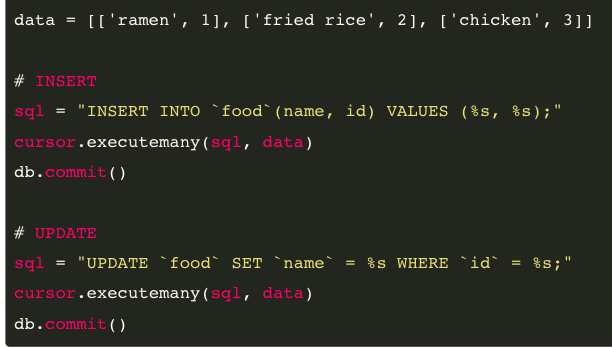
반복문 + execute() 메서드를 사용하는 것보다 훨-씬 속도와 메모리 면에서 효율적입니다.
(몇 십 만에서 몇 백 만 데이터 UPDATE시 반복문 + execute()는 몇 시간, executemany()는 몇 분 컷!)

-. Connection클래스
연결된 데이터베이스를 동작시키는 역할을 한다.
Connection.cursor()
Cursor객체를 생성한다.
Connection.commit()
현재 트랜잭션의 변경내역을 DB에 반영(commit)한다.
이 메서드를 명시적으로 호출하지 않으면 작업한 내용이 DB에 반영되지 않으므로, 다른 연결(Connection)에 그 내용이 나타나지 않는다.
Connection.rollback()
가장 최근의 commit()이후 지금까지 작업한 내용에 대해서 DB에 반영하지 않고, 트랜잭션 이전 상태로 되돌린다.
Connection.close()
DB연결을 종료한다.
자동으로 commit()메서드를 호출하는것이 아니기에, close()메서드를 호출하기 이전에 commit()/rollback()중 하나를 명시적으로 호출해야 한다.
Connection.isolation_level
트랜잭션의 격리수준(isolation level)을 확인/설정한다.
입력가능한 값은 None, DEFERRED, IMMEDIATE, EXCLUSIVE이다.
Connection.execute(sql[, parameters])
Connection.executemany(sql[, parameters])
Connection.executescript(sql_script)
임시 Cursor객체를 생성하여 해당 execute계열메서드를 수행한다
(Cursor클래스의 해당 메서드와 동일하므로 Cursor클래스에서 설명하겠다.)
Connection.create_aggregate(name, num_params, aggregate_class)
사용자정의 집계(aggregate)함수를 생성한다.
Connection.create_collation(name, callable)
문자열 정렬시 SQL구문에서 사용될 이름(name)과 정렬 함수를 지정한다.
정렬함수는 인자로 문자열 2개를 받으며, 첫 문자열이 두번째 문자열보다 순서가 낮은경우 -1, 같은경우 0, 높은경우 1을 반환해야 한다.
Connection.iterdump()
연결된 DB의 내용을 SQL질의 형태로 출력할수 있는 이터레이터를 반환
-. Cursor클래스
실질적으로 데이터베이스에 SQL문장을 수행하고, 주회된 결과를 가지고 오는 역할을 한다.
Cursor.execute(sql[, parameters])
SQL문장을 실행한다. 실행할 문장은 인자를 가질수 있다.
Cursor.executemany(sql, seq_of_parameters)
동일한 SQL문장을 파라미터만 변경하며 수행한다.
파라미터 변경은 파라미터 시퀸스, 이터레이터를 이용할수 있다.
Curosr.executescript(sql_script)
세미콜론으로 구분된 연속된 SQL문장을 수행한다.
Cursor.fetchone()
조회된 결과(Record Set)로부터 데이터 1개를 반환한다. 더 이상 데이터가 없는 경우 None을 반환한다.
Cursor.fetchmany([size=cursor.arraysize])
조회된 결과로부터 입력받은 size만큼의 데이터를 리스트 형태로 반환한다.
데이터가 없는 경우 빈 리스트를 반환한다.
Cursor.fetchall()
조회된 결과 모두를 리스트형태로 반환한다.
데이터가 없는 경우, 빈리스트를 반환한다.
참고자료
