속담에 이런 말이 있죠.
하나를 가르치면 열을 안다.
공부를 하면,
똑같은 문제뿐만 아니라
비슷한 문제도 해결할 수 있는
총명한 사람들을 두고 하는 말입니다.
'이런 총기를 기계에 부여해서
스스로 결정하도록 할 수 없을까?’ 라는
꿈을 꾼 사람들에 의해서
만들어진 기술이
바로 기계학습,
영어로 Machine Learning 입니다.
Model
모델은 머신러닝을
이해하는 중요한 열쇠입니다.
머신러닝에서 이야기하는
모델의 의미를 이해했다면
머신러닝의 개념을 파악한 것이라고 할 수 있습니다.
과정을 통해서 갖게 된 판단능력을
‘교훈’이라고 부릅니다.
교훈 덕분에 경험해보지 않아도
그 결과를 예측 혹은 추측할 수 있습니다.
우리는 추측 덕분에 먹어보지 않아도
그것이 먹어도 되는 것인지,
먹을 수 없는 것인지를 결정할 수 있습니다.
과학자들의 모델
과학자들은 현상을 관찰합니다.
그리고 그 현상을 설명할 수 있는 이유를 추측합니다.
이것을 ‘가설’이라고 합니다
그리고 그 가설을 검증하기 위해서
여러 가지 실험을 진행합니다.
실험 결과가 도출된 후,
가설에 모순이 없다면 이론으로 인정됩니다.
이론 덕분에 낙하하고 있는 물체가
10초 후에는 어디에 있을지도 예측할 수 있습니다.
교훈과 이론은 판단력의 다른 이름이라고도 볼 수 있습니다.
좋은 판단력은 나의 삶과 인류의 진보에
필수적인 도구입니다.
‘머신러닝’이란 판단력을 기계에게
부여하는 기술이라고 할 수 있습니다.
머신러닝을 만든 사람들은
이런 ‘판단력’을 ‘모델(Model)’이라고 부르기로 했습니다.
또 이 모델을 만드는 ‘과정’을
‘학습(Learning)’이라고 부르기로 했습니다.
학습이 잘 되어야 좋은 모델을 만들 수 있고,
모델이 좋아야 더 좋은 추측을 할 수 있습니다.
추측이 정확해야 좋은 결정을 할 수 있는 것은
말할 것도 없습니다.
모델이 무엇인지 알~겠나요?
머신러닝
‘머신러닝’을 도입하면 어떤 기능을 실행할 것인가를
장치 스스로 판단할 수 있게 됩니다.
장치에 연결된 여러 가지 센서들을 통해서
데이터를 수집한 후에 그 데이터의 의미를
‘머신러닝’의 모델이 판단합니다.
그 판단 결과에 따라서 여러 가지 결정을
기계 스스로 할 수 있게 됩니다.
데이터 과학(Science)과 데이터 공학(Engineering)
데이터 과학은 데이터를 만들고,
만들어진 데이터를 이용하는 일을 합니다
데이터 공학은 데이터를 다루는 도구를 만들고,
도구를 관리하는 일을 합니다.
표
데이터 산업에 입문하려면
표에 대해서 이해하는 것이 중요합니다.
표는 이렇게 생겼습니다.
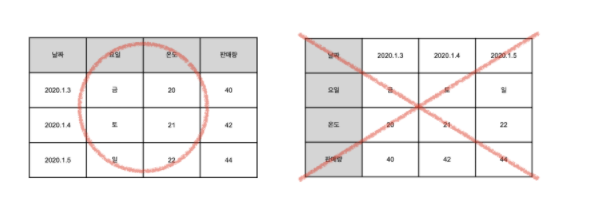
위 표 둘다 맞지만 데이터 산업에서는 오른쪽처럼 하지 않습니다.
왼쪽처럼 입력하자고 약속을 했으니 헷갈리지 맙시다.
- 표를 데이터 셋(data set)이라고도 부릅니다.
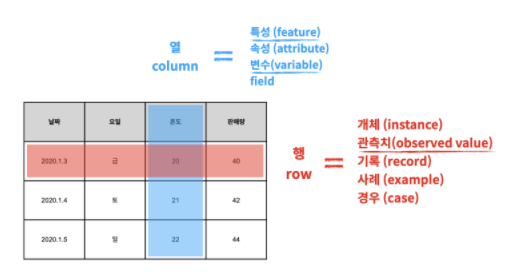
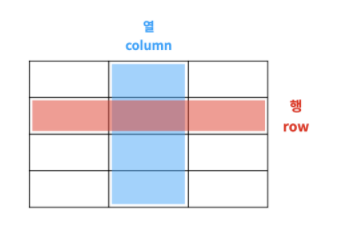
o 행(row)
- 개체(instance)
- 관측치(observed value)
- 기록(record)
- 사례(example)
- 경우(case)
o 열(column)
- 특성(feature)
- 속성(attribute)
- 변수(variable)
- field
현업에서는 맥락에 따라서 이런 표현들을
섞어서 사용합니다.
데이터 분야가 어렵게 느껴지는 이유 중의 하나입니다.
위의 표를 자세히 보면, 개체를 행에 적고,
그 개체의 특성을 열로 구분하고 있습니다.
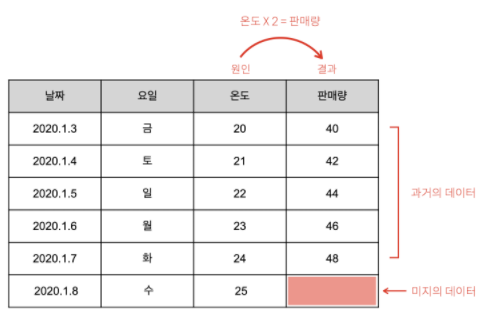
독립변수와 종속변수
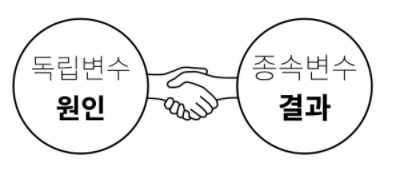
- 독립변수 = 원인이 되는 열
- 종속변수 = 결과가 되는 열
예를 들어,
‘온도가 20도일 때 40잔이 팔렸다.’
여기서 원인은 온도 20도이고 결과는 판매량 40잔입니다.
잘 생각해보면 원인은 결과와 상관없이 일어나는 사건입니다.
판매량 때문에 온도가 달라질리가 없잖아요?
결과에 영향을 받지 않는 독립적인 사건입니다.
하지만 결과는 원인에 종속되어서 발생한 사건입니다.
그래서 원인은 독립적이기 때문에 ‘독립변수’,
결과는 원인에 종속되어 있기 때문에 ‘종속변수'라고 합니다.
상관관계
한쪽의 값이 바뀌었을 때, 다른 쪽의 값도 바뀐다면,
두 개의 특성은 ‘서로 관련이 있다’고 추측할 수 있습니다.
이 때, 두 개의 특성을 ‘서로 상관이 있다’고 합니다.
그리고, 이런 관계를 ‘상관관계’라고 합니다.
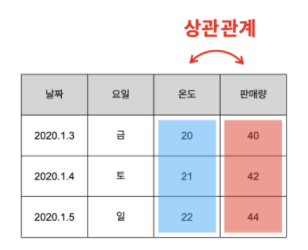
온도와 판매량은 서로 상관관계가 있다고
의심해볼 수 있습니다.
온도와 판매량이 같이 변하고 있거든요 :)
이렇게 각 열이 원인과 결과의 관계일 때
인과관계가 있다고 합니다.
상관관계와 인과관계는 비슷한 듯 하지만
중요한 차이가 있습니다.
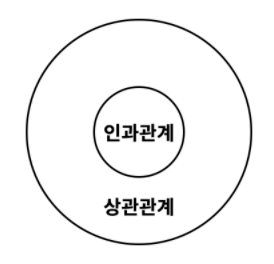
즉, 모든 인과관계는 상관관계입니다.
하지만, 모든 상관관계가 인과관계인 것은 아닙니다.
결론적으로

머신러닝의 컨셉
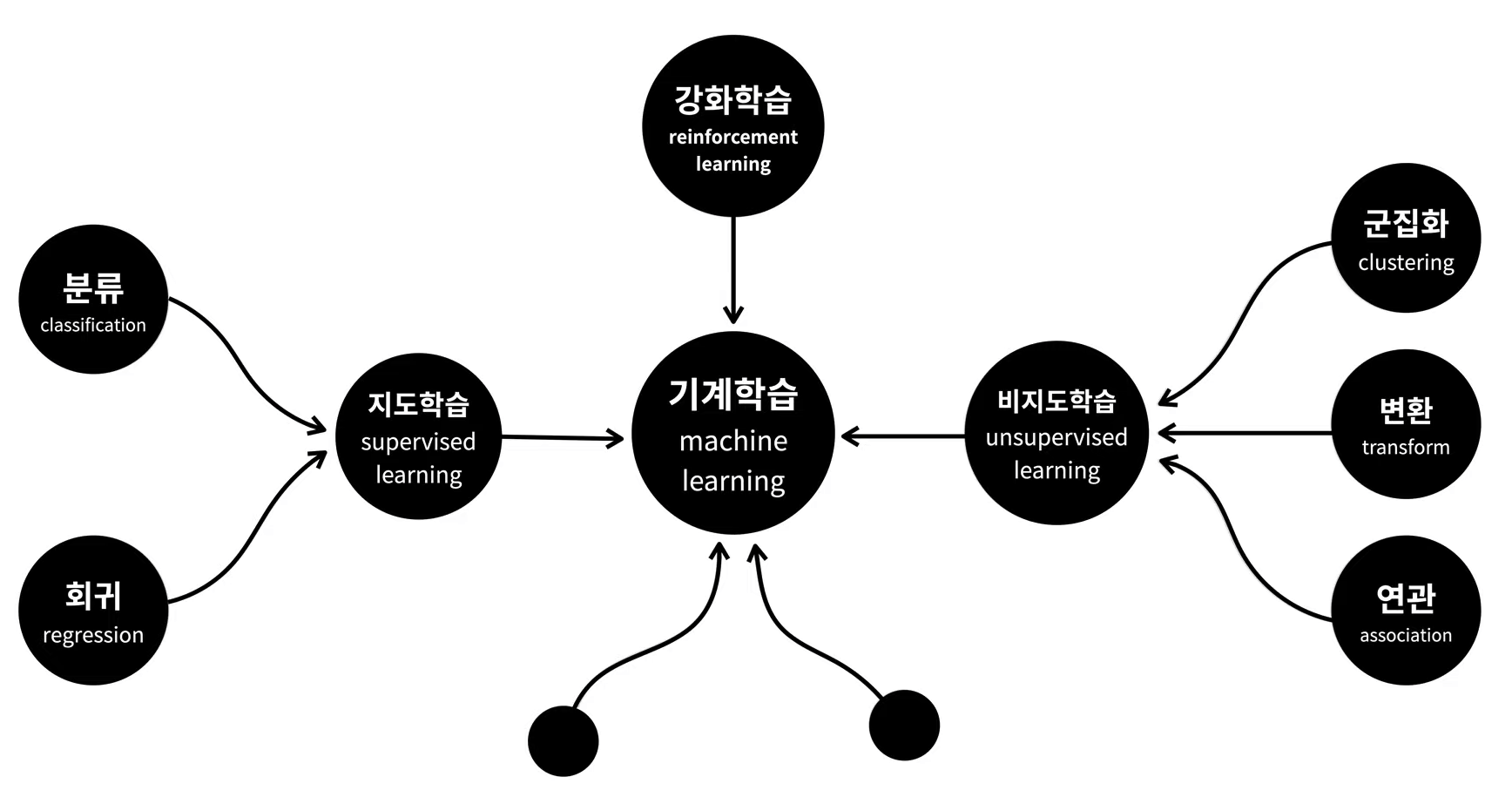
지도학습

지도학습의 ‘지도'는
기계를 가르친다(supervised)는 의미입니다.
마치 문제집을 푸는 것과 비슷합니다.
문제집에는 문제가 있고, 정답이 있습니다.
문제와 정답을 비교하고 맞추다 보면
문제풀이에 익숙해지게 됩니다 .
이후에 비슷한 문제를 만나면
오답에 빠질 확률은 점점 낮아집니다.
문제집으로 학생을 가르치듯이 데이터로
컴퓨터를 학습시켜서 모델을 만드는 방식을
‘지도학습’이라고 합니다.
비지도학습

비지도학습은 지도학습에 포함되지 않는 방법들입니다.
여기에 속하는 도구들은 대체로 기계에게 데이터에 대한
통찰력을 부여하는 것이라고 이야기할 수 있을 것 같습니다.
'통찰'의 사전적 의미는 '예리한 관찰력으로
사물을 꿰뚫어 봄'입니다.
즉, 누가 정답을 알려주지 않았는데도
무언가에 대한 관찰을 통해 새로운 의미나 관계를
밝혀내는 것이라고 할 수 있습니다.
데이터의 성격을 파악하거나 데이터를
잘 정리정돈 하는 것에 주로 사용됩니다.
강화학습

강화학습은 학습을 통해서 능력을 향상시킨다는 점에서는
지도학습이랑 비슷합니다.
차이점은 지도학습이 정답을 알려주는
문제집이 있는 것이라면,
강화학습은 어떻게 하는 것이
더 좋은 결과를 낼 수 있는지를
스스로 느끼면서 실력 향상을 위해서
노력하는 수련과 비슷합니다.
경험을 통해 “더 좋은 답”을 찾아가는 것입니다.
마치 게임 실력을 키우는 것처럼요.
게임에는 룰이 있고, 룰에 따라 어떤 행동을 하면,
그 결과에 따라서 상이나 벌을 받습니다.
더 큰 상을 받기 위한 과정을 끝없이 반복하다 보면
그 게임의 고수가 됩니다.
이런 과정을 기계에게 시켜서
기계 스스로가 고수로 성장하도록
고안된 방법이 강화학습이라고 할 수 있습니다.
결론적으로

지도학습
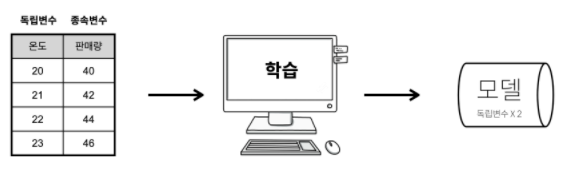
독립변수와 종속변수의 관계를 컴퓨터에게 학습시키면
컴퓨터는 그 관계를 설명할 수 있는 공식을 만들어냅니다.
이 공식을 머신러닝에서는 ‘모델’이라고 합니다.
좋은 모델이 되려면 데이터가 많을수록, 정확할수록 좋습니다.
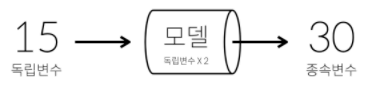
일단 모델을 만들면 아직 결과를 모르는 원인을
모델에 입력했을 때 결과를 순식간에 계산해서 알려줍니다.
회귀 & 분류
지도학습은 크게 ‘회귀’와 ‘분류’로 나뉩니다.
회귀는 Regression이고,
분류는 Classification입니다.
회귀 Regression
예측하고 싶은 종속변수가 숫자일 때
보통 회귀라는 머신러닝의 방법을 사용합니다.
레모네이드 예제가 바로 회귀를 이용한 것입니다.
저 아래 빨간색 은 어떤 형태의 데이터가 들어가나요?
숫자입니다!! 숫자는!!
회귀!!
Regression!!
회귀의 여러 사례들
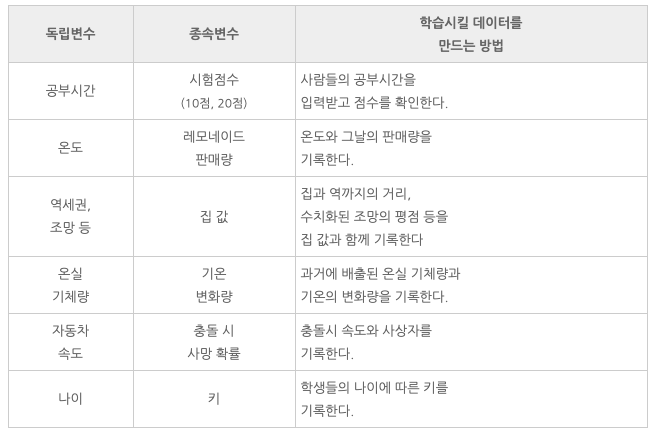
분류 Classification
앞으로 어떤 문제를 만났는데
그 문제에서 추측하고 싶은 결과가
이름 혹은 문자라면 이렇게 하면 됩니다.
분류의 여러 사례들
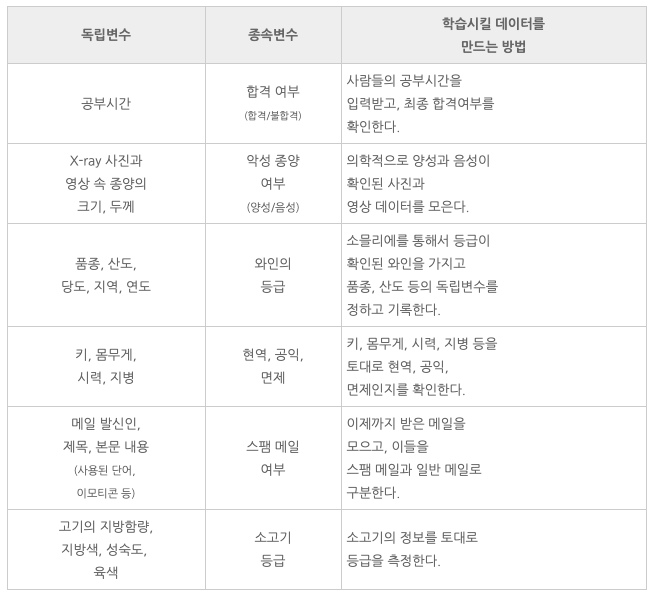
정리하자면,

양적 데이터와 범주형 데이터
얼마나 큰지, 얼마나 많은지,
어느 정도인지를 의미하는 데이터라는 뜻에서
‘양적(量的, Quantitative)'이라고 합니다.
누가 양적 데이터라고 말했다면
숫자라고 알아들으면 됩니다.
또 산업에서는 ‘이름'이라는 표현 대신에
‘범주(範疇, Categorical)'라는 말을 씁니다.
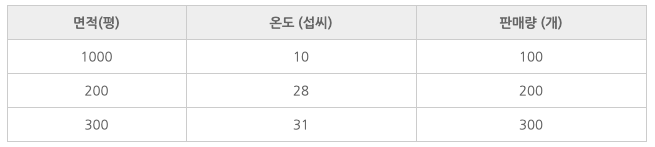
양적 데이터입니다.
종속변수가 양적 데이터라면 회귀를 사용하면 됩니다.
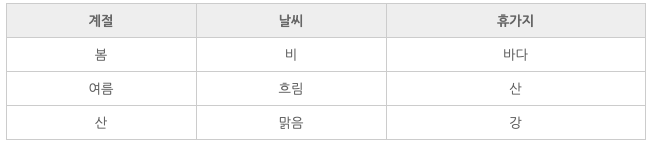
범주형 데이터입니다.
종속변수가 범주형 데이터라면 분류를 사용하면 됩니다.
비지도학습
군집화 clustering
비슷한 것들끼리 모아서 적당한 그룹을 만들 것입니다.
이렇게 그룹을 만드는 것이 군집화입니다.
그룹을 만들고 난 후에는 각각의 물건을
적당한 그룹에 위치시키겠죠?
이것이 분류입니다.
정리하자면,
어떤 대상들을 구분해서 그룹을 만드는 것이 군집화라면,
분류는 어떤 대상이 어떤 그룹에 속하는지를
판단하는 것이라고 할 수 있습니다.
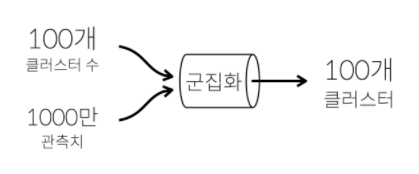
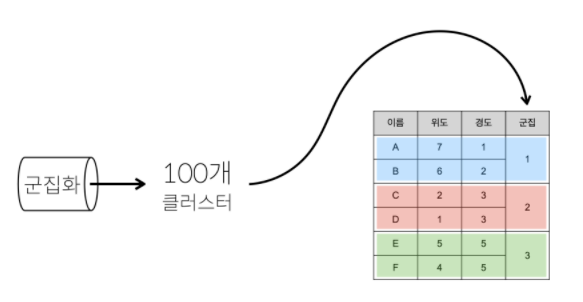

연관규칙학습 Association rule learning
아래는 지금까지 판매 내역입니다.
하나 이상 구매했다면 O, 구매하지 않았다면 X입니다.
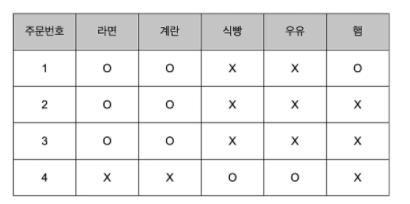
유심히 보면,
라면을 구입한 사람은 계란을 구입할 확률이 높습니다.
즉, 라면과 계란은 서로 연관성(Association) 이
높다는 것을 알 수 있습니다.
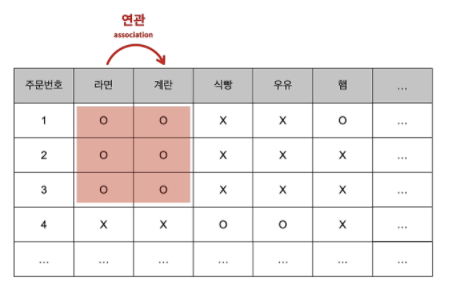
정리하자면
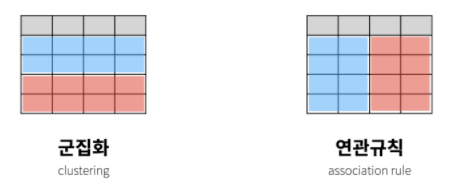
- 관측치(행)를 그룹핑 해주는 것 군집화
- 특성(열)을 그룹핑 해주는 것 연관규칙
지도 vs 비지도 학습

비지도학습은 탐험적입니다.
탐험이 미지의 세계를 파악하는 것이듯,
데이터들의 성격을 파악하는 것이 목적입니다.
독립변수와 종속변수의 구분이 중요하지 않습니다.
데이터만 있으면 됩니다.
지도학습은 역사적입니다.
과거의 원인과 결과를 바탕으로 결과를
모르는 원인이 발생했을 때
그것은 어떤 결과를 초래할 것인가를
추측하는 것이 목적입니다.
그래서 원인인 독립변수와 결과인
종속변수가 꼭 필요합니다.
강화학습 Reinforcement Learning
강화학습의 핵심은 일단 해보는 것입니다.

비유하자면 지도학습이 배움을 통해서
실력을 키우는 것이라면,
강화학습은 일단 해보면서 경험을 통해서
실력을 키워가는 것입니다.
그 행동의 결과가 자신에게 유리한 것이었다면
상을 받고, 불리한 것이었다면 벌을 받는 것입니다.
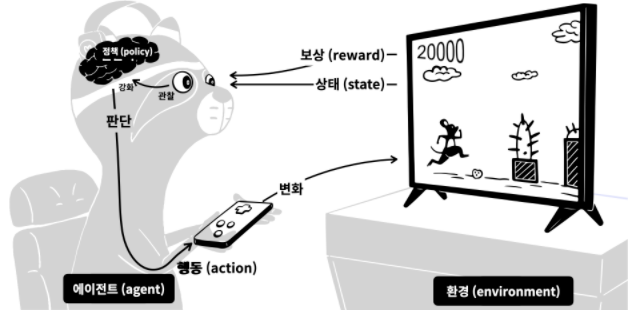
- 게임 => 환경(environment)
- 게이머 => 에이전트(agent)
- 게임화면 => 상태(state)
- 게이머의 => 조작 행동(action)
- 상과 벌 => 보상(reward)
- 게이머의 => 판단력 정책(policy)
강화학습에서는 더 많은 보상을 받을 수 있는
정책을 만드는 것이 핵심입니다.
이렇게 만들어진 정책은 게임의 인공지능 플레이어를
만드는 데 사용될 수 있습니다.
바둑으로 인간을 이긴 알파고가
바로 강화학습을 통해서 구현된 소프트웨어입니다.
자동차의 자율주행 기능도 강화학습을
이용해서 만들어집니다.
source
