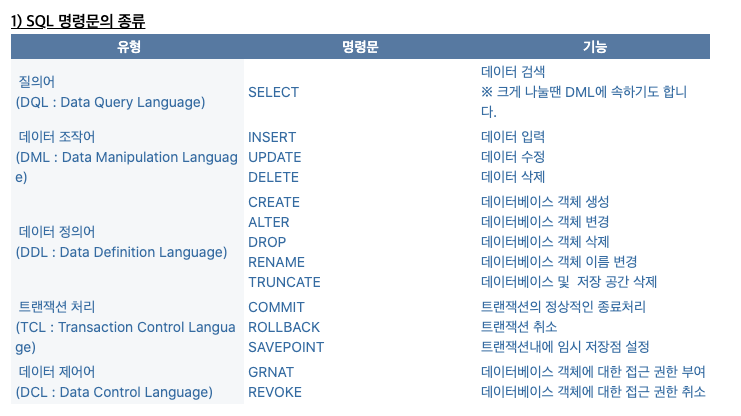
SQL

Structured Query Language(구조적 질의 언어), 관계형 데이터베이스 시스템(RDBMS)에서 자료를 관리 및 처리하기 위해 설계된 언어.


CHAR vs VARCHAR?

하지만 속도차이가 미미하고 혹여나 CHAR에서 길이 바꿀일 생기면 일일히 다 바꾸는거 비효율적이므로
실무에서는 그냥 VARCHAR를 쓴다고 한다.
바로 실습

어디서 본 것 같지 않은가? 장고에서 썼던 models.py에
테이블 column 적고, CharField인지, IntergerField인지, Null=False인지,
썼던 것인데, 그건 ORM 호로록 다 해주는 것이고, 이것이 쿼리로 데이터베이스를 짜고 만드는 것.
일단 Person 이라는 테이블에
- id PK(AI)
- Name text, null=false
- Birthday text
이렇게 3개의 column이 생겼다.
추가 INSERT

삭제 DELETE

갱신 UPDATE
방금 위에서 삭제 했으니까 INSERT INTO로 추가해주고

조회 SELECT

여러 행 INSERT하기

열(column) 값의 자동 증가(AUTOINCREMENT)
위에 잘 보면 ID 열에 대해 AUTO INCREMENT 속성을 설정했다.
NULL
Birthday 열은 NULL값을 허용 했다.

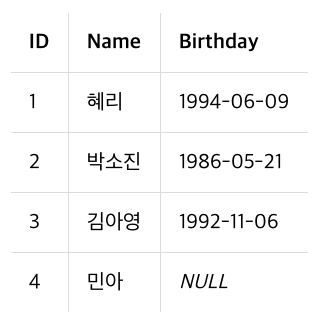
특정 Column 조회

특정 순서로 조회

역순

SELECT ... WHERE
이름이 박소진인 친구를 찾아보자


UPDATE ... WHERE

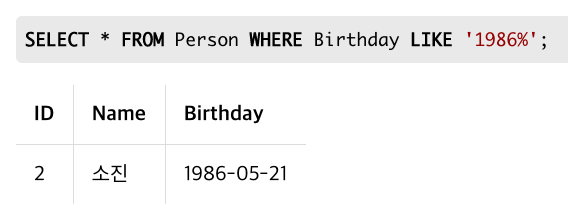
LIKE
WHERE 절에 '=' 대신 LIKE를 사용하여, 패턴과 일치하는 문자열을 찾을 수 있다.
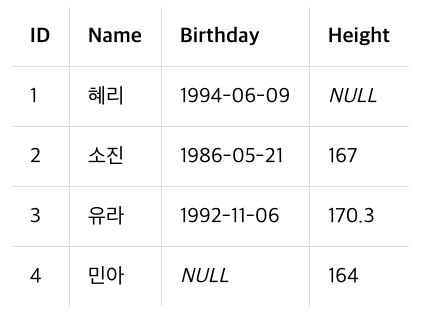
테이블 변경 ALTER TABLE
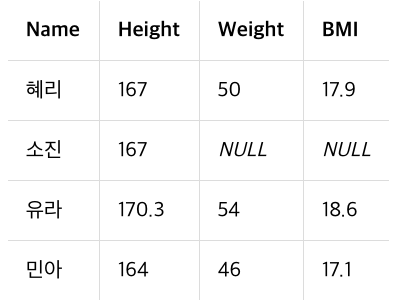
Height 컬럼을 추가해보자.

새 값도 넣고

테이블 삭제 (DROP TABLE)
DROP TABLE 을 실행하면 DATABASE SCHEMA와 디스크 파일에서 테이블이 삭제되며, 되돌릴 수 없다.

아래처럼 삭제된 테이블을 처음부터 다시 만들고 채워 넣어야 한다.

컬럼 별명
조회 결과에서 컬럼명이 다른이름으로 보이게 할수 있다. (쓸모 있는진 모르겠음)

AS 생략 가능

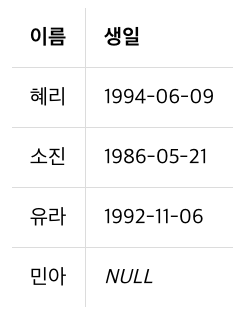
계산해서 컬럼 만들기
오.. 쿼리에서 계산해서 테이블을 만들 수 있다니..


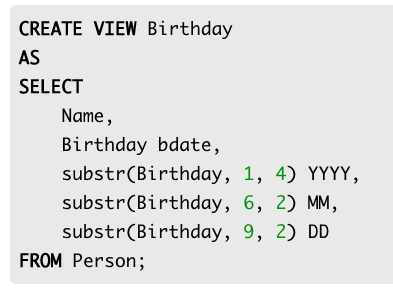
View 생성
뷰는 SELECT 문을 미리 만들어서 이름을 붙여둔 것이라 할 수 있다. 다음 문장은 Person 테이블에서 Birthday와 Birthday의 년, 월, 일에 해당하는 값을 조회하는 뷰를 생성한다

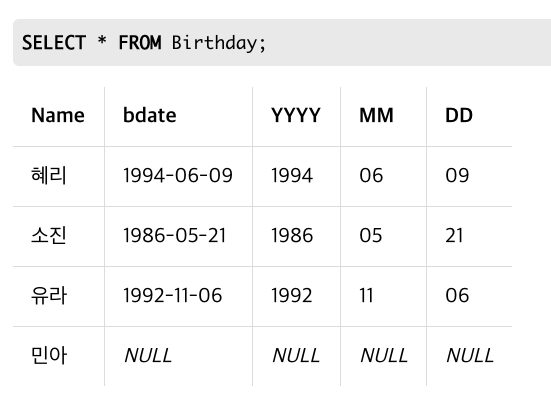
View 삭제

조건절
if-then-else의 조건분기에 익숙할 것이다.
SQL은 절차형 프로그래밍 언어와 작동 방식이 다르므로
SQL의 CASE가 절차형 프로그래밍 언어의 조건분기와 똑같지는 않다.
오히려 함수형 언어 또는 용법에서 분기문을 사용하는 것과 유사하다고 할 수 있다
아까 만든 Birthday 뷰 사용

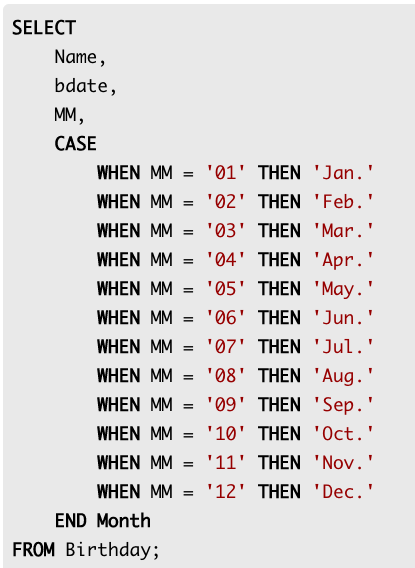
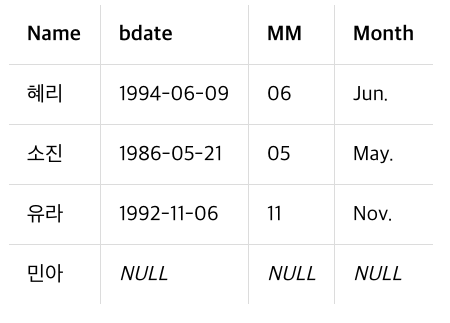
CASE
SQLite라서,, CASE 쓰나...

집계 함수
위에서 만든 Person 테이블을 가지고 AGGREGATE함수를 사용


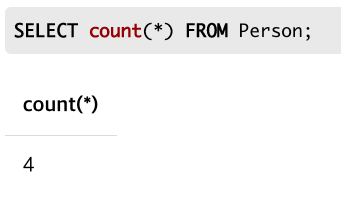
count()

max()

min()

sum()

avg()

그룹화
GROUP BY


GROUP BY 의 1은 첫번째 컬럼, 그래서 위 2개 테이블은 같은 결과를 가진다.
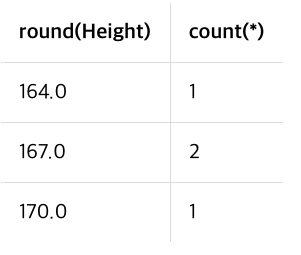
HAVING
두명이상인 경우만, 그러니까 count(*)가 2 이상인 경우만 조회
- 참고 자료
