
SQL

Structured Query Language(구조적 질의 언어), 관계형 데이터베이스 시스템(RDBMS)에서 자료를 관리 및 처리하기 위해 설계된 언어.


SQL 첫 걸음 책
SQL 제대로 공부할려고 책 구입!
다시 이걸로 공부 시작!
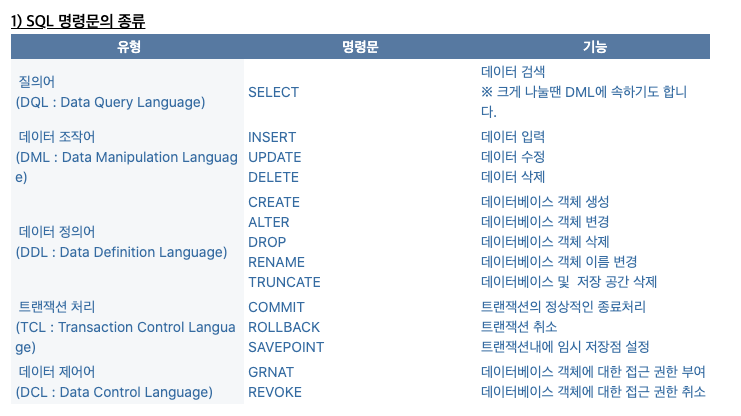
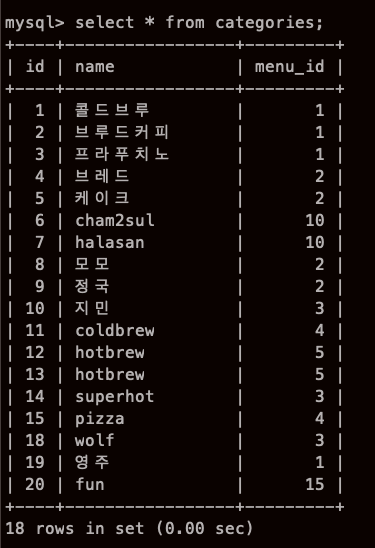
SELECT 구에서 열 지정하기
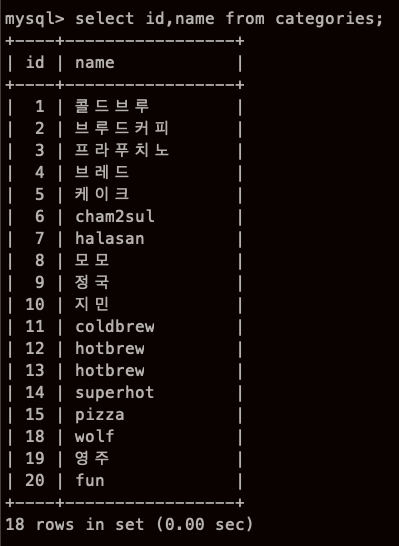
WHERE 구에서 행 지정하기 (조건식)
SELECT 열 FROM 테이블명 WHERE 조건식
궁금했던 것인데 방금 풀린 것이 있다!
SQL에서는 구의 순서가 정해져 있어 바꿔 적을 수 없다.
SELECT -> FROM -> WHERE
근데 WHERE는 생략할 수 있음, 생략하면 위에 테이블 처럼 다 나온다.

오!!

오오오!!! 모모!!
그럼 같은게 2개면 어떡하지?(해보면 되지)
오오오오!!! 이거 완전 장고에서 filter 기능이랑 같은거 같은데?
생소하긴하지만 심지어 이게 더 직관적이고 쉬워 보이는데 ?
<> 연산자
<> 연산자는 서로 다른 값인지를 비교하는 연산자입니다.

오오,,., menu_id 1 을 제외한 모든 게 나왔다,, 그럼, 2개도 되나?

내가 잘못한건지,,, 왜 안될까
리터럴
자료형에 맞게 표기한 상수값을 '리터럴',literal 이라 부른다.
수치형 상수 예
1 100 -3.7
문자열형 상수
'ABC' '신재훈'
날짜시간형 상수
'2020-10-11' '2020-10-11 11:11:22'
싱글쿼드로 감싼거 유의!!
NULL 값 검색
IS NULL

언어가 상당히 직관적이고 사람 언어같다.
무슨 영어 그대로 읽으면 말이 된다. 어떻게 보면 파이썬보다 쉬워 보인다.
반대는 IS NOT NULL
연산자 종류
=
<>
'<'
'>'
'>='
'<='
조건 조합하기
조건식1 AND 조건식2
조건식1 OR 조건식2
NOT 조건식
AND 로 조합하기
복수의 조건을 조합할 경우 AND를 가장 많이 사용,
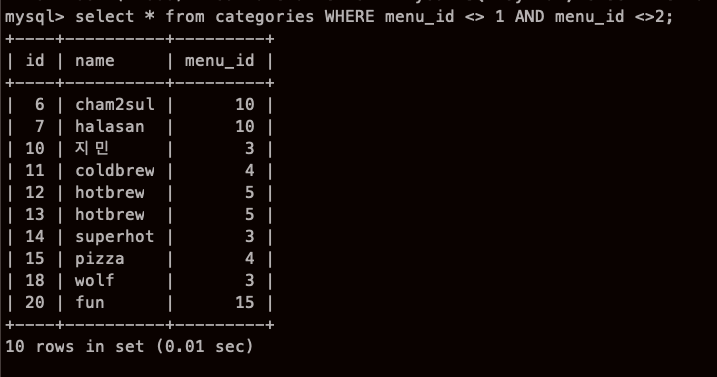
(menu_id 1 & 2 제외하고 모두 출력)
ㅇㅁㅇ! 내가 방금 위에서 복수 조건 어떻게 하냐고 궁금해 했는데 바로 나오다니..
좋은 책이군...
AND, OR, NOT 모두 파이썬 조건문을 공부할 때 익혔던 개념들이라
그렇게 생소하지는 않다! 그래도 꼼꼼히!
OR
은근히 헷갈리지만 둘중하나라도 참이면 되니까, 거의 다 뿌린다.
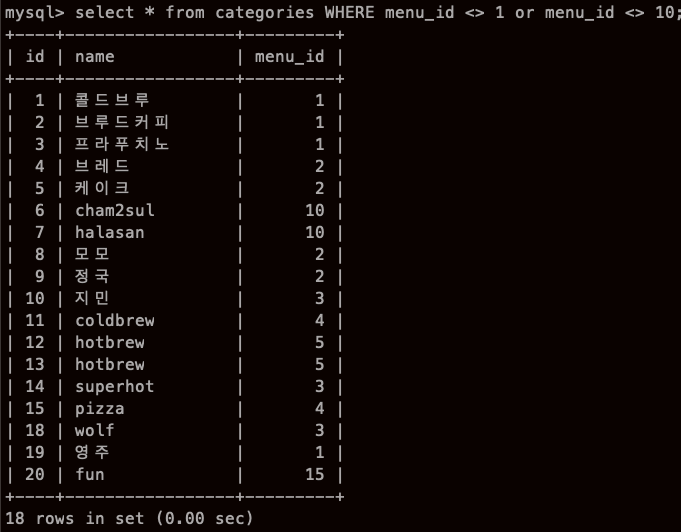
연산자의 우선순위
WHERE a=1 OR a=2 AND b=1 OR b=2
WHERE a=1 OR (a=2 AND b=1) OR b=2
즉 3개의 조건식이 OR로 연결된 것과 같아집니다.
AND는 OR에 비래 우선 순위가 높다!
NOT
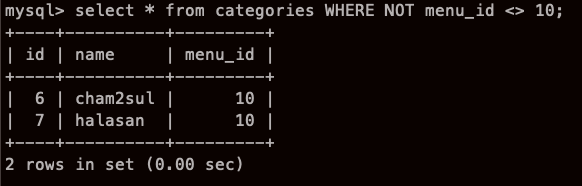
menu_id가 10이 아닌것의 NOT 이니까
부정의 부정이니까 긍정. 그러니까 10만 나와라

menu_id 가 10 이 아닌것을 다 가져와라!
패턴 매칭에 의한 검색
LIKE
열 LIKE 패턴
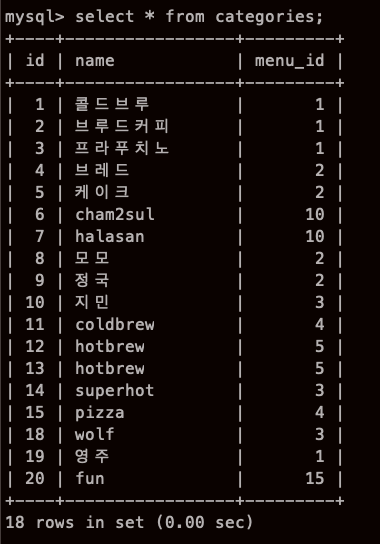
전체 가 이렇게 있을때,
name 컬럼에 hot 라는 글자가 들어가면 다 내놔
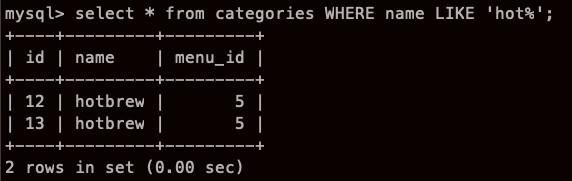
으음.. 이런식으로도 응용 가능 하군
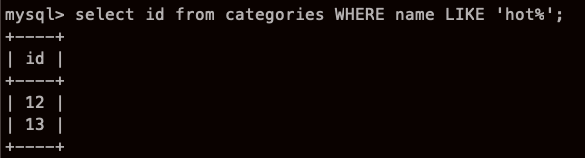
여기서 %는 임의의 문자열 을 의미하며
_ 는 임의의 문자 하나를 의미 한다.
hot% < 전방일치 (그니까 hot으로 시작해야한다는 뜻)
도중에 낑기는거 찾고 싶으면
%hot% 이렇게 해야한다.
물론 후방일치도 있다
hot%
만약 검색하고 싶은 문장중에 % 를 검색하고 싶다?
그럼 %%% 이렇게 해야하나? 노노
파이썬에서도 특수문자 escape가 있듯
앞에 백슬래쉬 \ 를 붙히면 그문자 그대로 찾아진다.
%\%% <<< 중간에 끼거나, 시작하거나 끝나거나 하는 %를 찾아줘
문자열 상수' 의 이스케이프!
IT'S << 안에 이미 싱글쿼트가 있다,
그럼 sql에선 'IT'S' << 이러면 에러가 난다.(파이썬도 비슷)
이럴때 안쪽은 쌍따옴표로 해준다 .
'IT"S' <<이러면 에러가 나지 않는다.
sql은 무조건 싱글쿼트
정렬 ORDER BY
SELECT 컬럼 FROM 테이블 WHERE 조건식 ORDER BY 컬럼
(이때 WHERE는 생략 가능)

음,, 일단 영어 먼저 나오는군,,
그럼 복수 정렬은 어떡하지, 일단 menu_id로 정렬하고 menu_id가 같은것 중에서도 이름으로 정렬한다면?
AND 붙이면되나

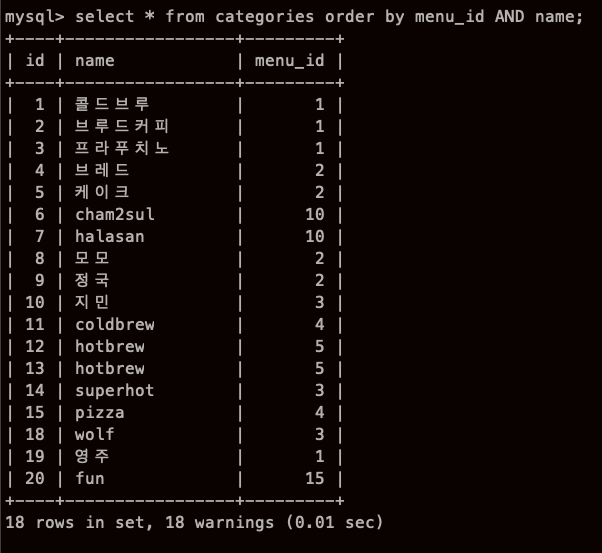
AND 붙히면 아예 아무것도 안먹힌다.. (장고에선 2개 정렬 됬는데,, 예를들어 SOLD OUT먼저 정렬하고, 그다음에 물건들을 업데이트순 정렬..이런식)
내림차순 정렬 DESC
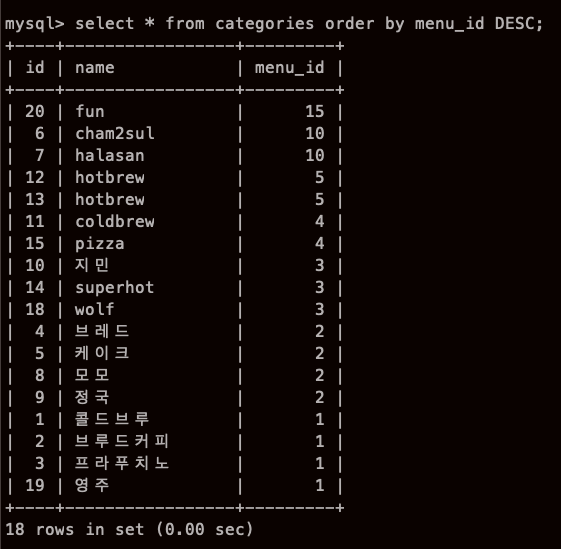
뒤에 DESC를 붙히면 되는데, 아마 내려가는 descending 의 약자 같다.
ASC 를 붙히면 오름차순으로 된다!
+추가
descendant, ascendant 의 약자라고 한다.
근데 ORDER BY의 기본정렬을 오름 차순이다.
대소관계
- 숫자는 대소관계가 쉽다
1은 100보다 작고, 100은 1000보다 작으니까!
- 날짜 시간형
작다 = 이전, 크다 = 더 최근
1950년 < 2000년
자.. 여기까지는 할만한데 문제는 문자열형 데이터.
알파벳 -> 한글 (자음 -> 모음) 순
ex) 나비, 가방, 가족 비교
1.가방
2.가족
3.나비
나비는 ㄴ 으로 시작해서 밀리고
가방과 가족의 ㄱ 이 같고, 그다음 ㅏ 도 같아서
방 과 족으로 비교를 하는데 ㅂ 이 ㅈ 보다 빨라서 위처럼 정렬된다.
order by 는 테이블에 영향을 주지 않는다!
복수의 열을 지정해 정렬하기
와.. 바로 위에서 내가 궁금했던 건데.. 조급해하지말자 재훈아..
SELECT 컬럼 FROM 테이블 ORDER BY 컬럼1, 컬럼2
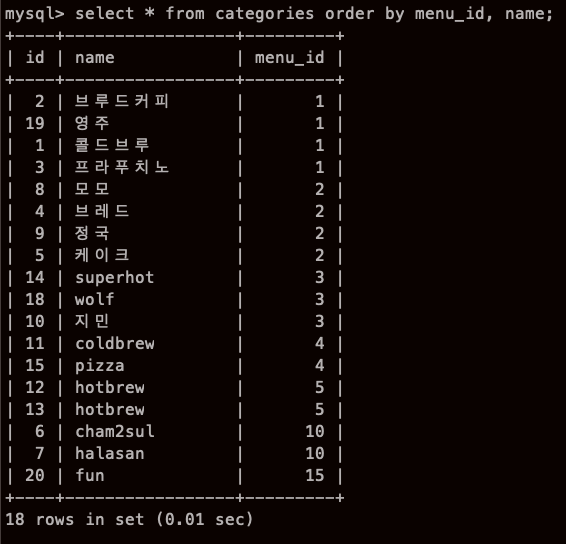
왜 안되지..?
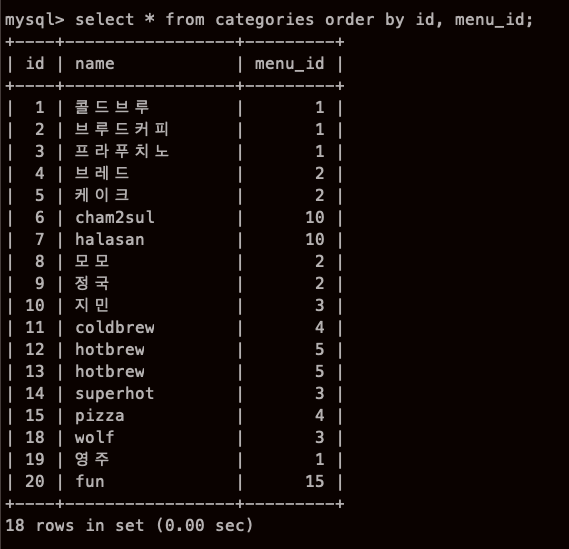
이러고 질문을 하려고 다시 봤는데,,, 바보였다.. 잘 되고 있었다.


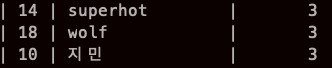
NULL 값의 정렬 순서
NULL에 대한 대소비교 방법은 표준 SQL에도 규정되어 있지 않아 데이터베이스 제품 기준에 따라 다르다.
MySQL에 경우 NULL 값을 가장 작은 값으로 취급해 ASC에서는 가장 먼저 표시한다. (desc는 반대)
결과 행 제한하기 - LIMIT
SELECT 명령에서는 결괏값으로 반환되는 행을 제한할 수 있다.
여기서는 LIMIT 으로 결과 행을 제한하는 방법에 관해 알아보자.
SELECT 컬럼 FROM 테이블 LIMIT 로우(행) [OFFSET 시작행]
(앗 이게 프로젝트 때 배웠던 limit, offset, pagination?)
- 일단! LIMIT 은 표준 SQL 은 아니다. MySQL PostgreSQL에서만 사용가능 문법
LIMIT은 SELECT 명령의 마지막에 지정하는 것으로 WHERE 이나 ORDER BY 뒤에 지정한다.
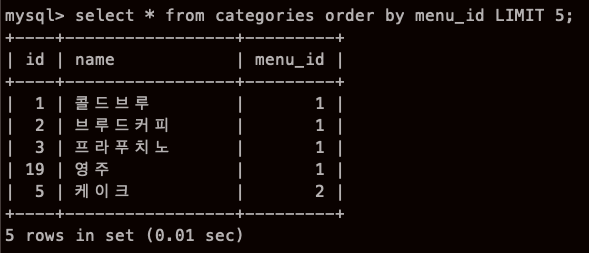
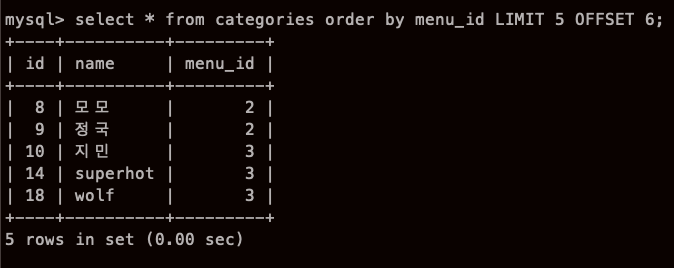
OFFSET 6 이라고 되어있는데, 시작하는 부분을 뜻한다. 아까 1~5번째까지 뽑았으니
이번엔 6 7 8 9 10 을 뽑는것이다.
수치 연산
SQL 은 DB를 조작하는 언어이지만 컴퓨터를 조작하는 언어이기도 한 만큼 기본적으로
계산 기능을 포함한다.
수치연산에 대해 알아보자
산술 연산
+,-,*,/,%,MOD
기본적으로 사칙연산이 있고,
%는 나머지를 찾는 것
(파이썬에서 봐서 생소하지 않다)
물론 우선순위는 곱하기 나누기가 먼저 ( *,/,% )
직접 실험해보고 싶었지만 지금 스타벅스 DB로 하고 있어서
INT 가 없을것 같았는데, 혹시나 해서 id 랑 menu_id를 곱해봤다..
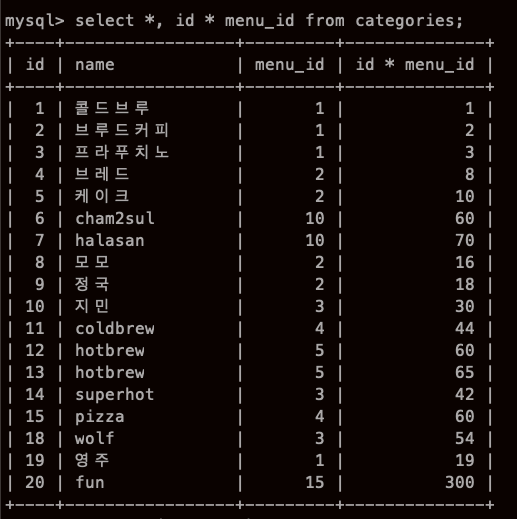
아니...이게 된다고?

아니.. 아무리 그래도.. id는 PK고 ,,, menu_id는 FK 인데,, 그래서 뭔가 특별할 줄 알았는데
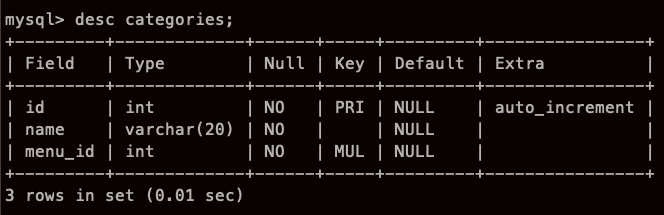
SQL...너에겐 그저 INT 그 이상도 이하도 아닌거냐....
아 그리고 지금 id * menu_id 컬럼이 추가 되었는데! 이거
장고에서 annotate아닌가..? 아니 aggregate까지 아닌가..?
컬럼 새로 만들고 합친게 들어가...?
아 칼럼 이름 id * menu_id 마음에 안드는데,, 앗 저거 바꾸는거 있었던거 같은데...
내 벨로그 찾아봐야겠다
(주섬주섬)
- 출처: 내 벨로그:SQL

(쓸모 있는진 모르겠음) 이라고 적어놨었는데.. 하루만에 쓰네...

아무튼 그리하여,
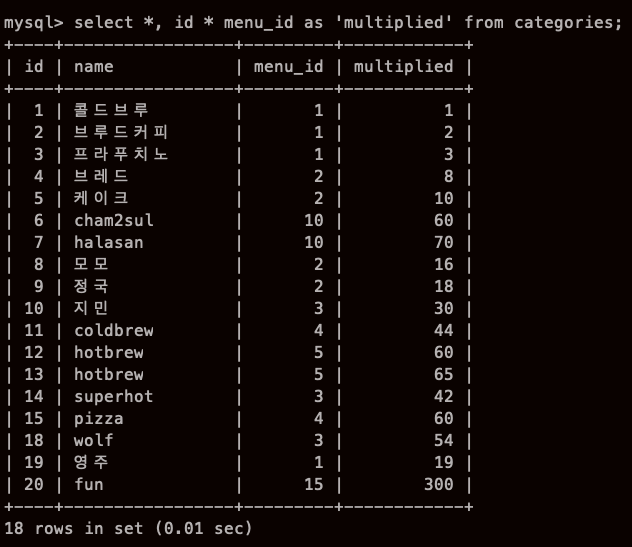
아! 한글은 오류가 날수 있으므로 alias에 더블쿼트를 해준다!

객체명은 더블쿼트 (칼럼 이름)
문자열은 싱글쿼트
객체명은 숫자로 시작 NO!
WHERE 에서 연산하기
id 와 menu_id 를 곱하는데
그 결과가 30 보다 크거나 같은 것들을 모두 가져오는데 amount의 오름 차순으로 가져와라
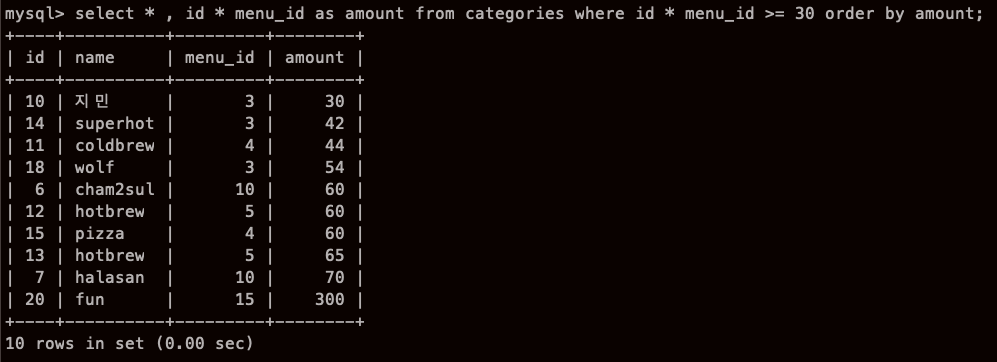
신기 했던게
WHERE id* menu_id >=30 이부분을
WHERE amount >=30 라고 했는데 에러가 났다.
ERROR 1054 (42S22): Unknown column 'amount' in 'where clause'
as amount 라고 하는 순간 그 컬럼은 amount 가 되는 줄 알았는데,
근대 또 신기한 건 order by 는 amount로 됐다.!? ㅇㅁㅇ??
와.. 위처럼 궁금해 하고 있었는데, 내부처리 순서가 다음 파트에 나왔다
(사람들 생각하는게 다 같은가 보다)
WHERE , SELECT 내부처리 순서
WHERE -> SELECT 순서로 처리 된다.
따라서 WHERE 구로 행이 조건에 일치하는지 아닌지를 먼저 조사한 후에 SELECT 구에 지정된 열을 선택에 결과로 반환하는 식으로 처리.
별명은 SELECT 구문을 내부 처리할 때 비로소 붙여집니다. 즉, WHERE 구에서 사용한 별칭은 아직 내부적으로 지정되지 않은 상태가 되어 에러가 발생하는 것.
NULL 값의 연산
NULL + 1 = ?
1 아닙니다!
NULL 은 0이 아니므로 답은 그냥 NULL!
(1이라고 생각했다면 당신은 hoxy... C or PHP 언어 능력자?)
- 정리: NULL 로 연산하면 결과는 NULL이 된다!
ORDER BY 구에서 연산하기
ORDER BY 구에서도 연산할 수 있고 그 결괏값을들 정렬할 수 있다.
WHERE -> SELECT -> ORDER BY
SELECT부분에서 as 별명(alias)를 지정
그래서 order by amount 가 된것이다.
함수
MOD = %
ROUND(amount,자릿수)
자릿수가 1,2 면 소수점 123.135 => 123.1 ,123.14 이렇게 뒤에 자릿수 남기는 것
자릿수가 -1, -2면 5432 => 5430 , 5400 이렇게 정수 단위 끊는 것,
나는 소숫점테이블이 없어서, 정수로만 해봤다.
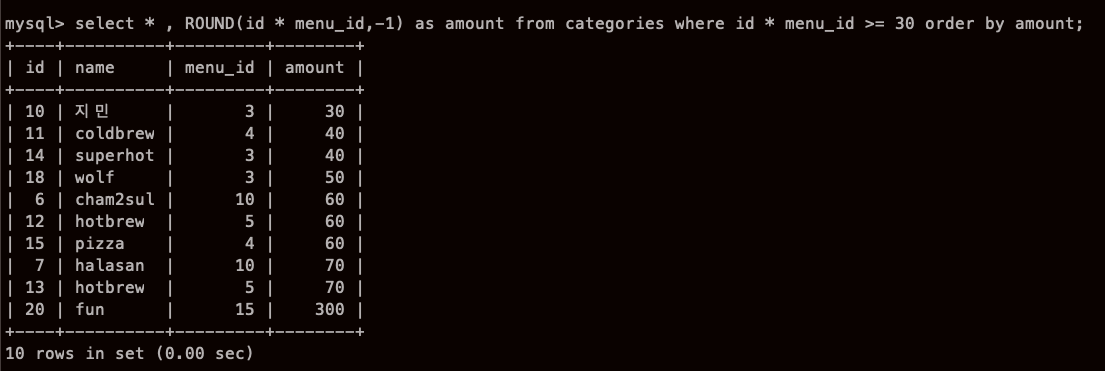
반올림 외에 버림을 하는 경우도 있는데 그때는 TRUNCATE로 버린다.
SIN, COS, SQRT, LOG, 이런 수많은 함수들도 있다.
문자열 연산
문자열 결합
'ABC' || '1234' -> 'ABC1234' => ORACLE, DB2, PostgreSQL,
'ABC' + '1234' -> 'ABC1234' => SQL Server
CONCAT ('1234','ABC' ) -> 'ABC1234' => MySQL,
근데 이게 DB 제품마다 방언이 달라서,MySQL은 CONCAT 을 쓴다
(concatenate)에서 따온듯 하다.
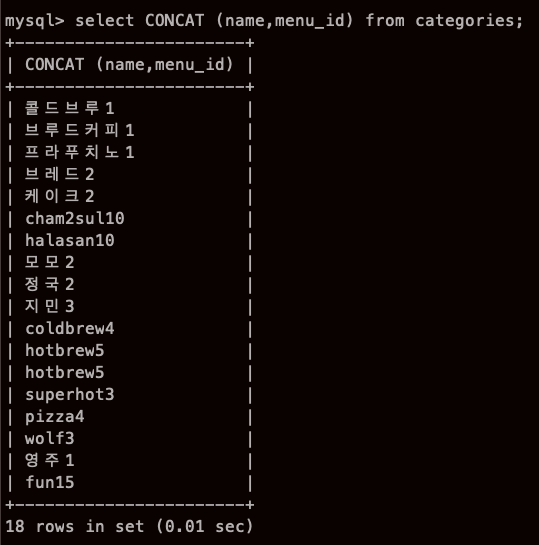
오우.. 뭐야 이 끔찍한 혼종은...
심지어 name은 VARCHAR 고, menu_id는 INT인데
그냥 어거지로 갖다 붙힌 느낌인데?
근데 출력할때 편하겠다....
SUBSTRING 함수
SUBSTRING 함수는 무자열의 일부분을 계산해서 반환해주는 함수입니다.
데이터베이스에 따라서는 함수명이 SUBSTR 인 경우도 있다.
앞 4자리 추출
SUBSTRING('20201212001', 1,4) -> '2020'
SUBSTRING('20201212001', 5,2) -> '12'
- 첫번째는 시작점,
- 두번째는 거기서부터 몇자리 가져올 것인가.
TRIM 함수
- 문자열의 앞뒤로 여분의 스페이스가 있을 경우 이를 제거해주는 함수로
문자열 도중에 존재하는 스페이스는 제거 되지 않는다.
CHARACTER_LENGTH 함수
- 문자열의 길이 계산
- CHAR_LENGTH 로도 줄여서 사용 가능
OCTET_LENGTH 함수는 문자열의 길이를 바이트 단위로 계산해 돌려주는 함수
여기서 이제 바이트가 나오는데,
컴퓨터 안에는 이미지 데이터, 음성데이터, 수치데이처, 문자열데이터, 등 다양한 종류의 데이터가 저장되지만, 결국 수치로 저장되며 바이트로 계산된다.
문자 세트 character set ASCII, EUC-KR, UTF-8
ASCII = 반각문자인 알파벳이나 숫자 기호
EUC-KR = 전각문자 , 에서는 ASCII는 1바이트 한글은 2바이트
UTF-8 = 전각문자 , 에서는 ASCII는 1바이트 한글은 3바이트
날짜 연산
날짜, 시간 데이터를 저장하는 방법은 DB제품에 따라 크게 달라진다.
이책은 날짜와 시간을 초단위로 저장할 수 있는 날짜 시간형을 중점으로 설명한다
(역시 MySQL이 최고)
SQL에서의 날짜
기간(간격)의 차를 나타내는 기간형(interval) 데이터를 반환하는 경우도 있다
ex) 2시간, 10일간
시스템 날짜
일단 시스템 날짜 확인부터!
지금 이라고 찍으면 어느 기준으로 지금인지 알아야하니까!
컴퓨터에는 반드시 시계가 내장되어있다.
네트워크나 주변기기와 데이터통신을 하기 위해서는 시간을 정확하게 측정할 필요가 있기 때문!
- 표준 SQL에는 'CURRENT_TIMESTAMP' 라는 함수가 있다
- parameter도 필요없다. 괄호도 쓰지않는 특이한 함수다

오오,, 뭐야뭐야 나 저런 테이블도 컬럼도 없는데 그냥 찍어보니까 생겼고,,
(내가 언제 벨로그 이쪽 부분 쓰고 있는지 들킴..ㅎㅎ)
날짜 데이터는 서식을 지정할수 있다.
날짜 덧셈과 뺄셈
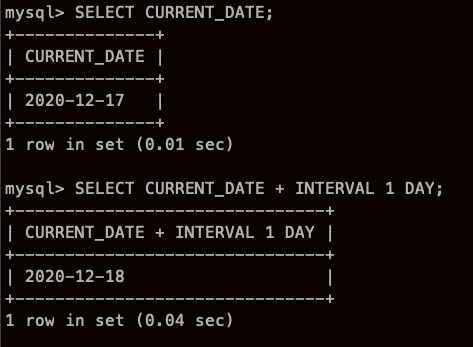
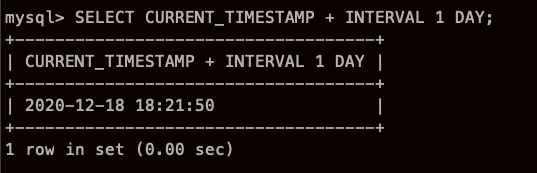
+INTERVAL 1 DAY
근데 칼럼 명이 쫌 맘에 안드는데?
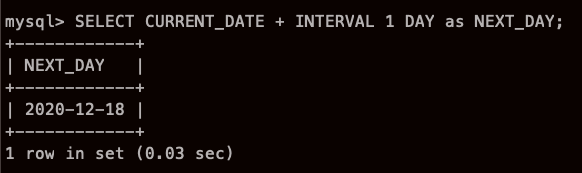
바로 응용까지...
날짜 뺄셈
MySQL에서는 DATEDIFF 로 계산 가능
SELECT DATEDIFF(더 먼큰 빼기 더 작은시간)
(큰시간 작은시간은 앞에서 배웠기에 써먹기)
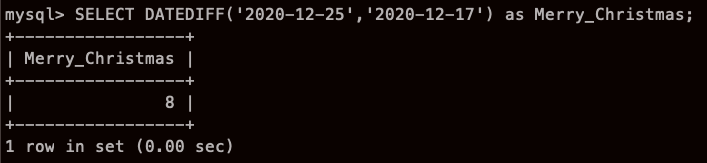
아 크리스마스까지 8일 남았네,,
예수님 생일인데 왜 커플들이 난리지..
아 잠시만...

CASE 문으로 데이터 변환하기
CASE WHEN 조건식1 THEN 식1
[WHEN 조건식2 THEN 식2...]'
[ELSE 식3]
END
(마크다운땜에 따옴표 썼는데 무시바람)
ELSE 는 생략가능하며
생략했을 경우 ELSE NULL 로 간주

(내 샘플 테이블에 NULL이 없어서 책으로 대체)
NULL이면 0으로 하고 아니면 a로 해라, 뒤에는 칼럼 이름(AS 안써도 됨)
COALESCE 함수
사실 NULL 값을 변환하는 경우라면 COALESCE 함수를 사용하는게 더 편하다고 한다
(왜 이제알려줘?)
SELECT a, COALESCE(a,0) FROM sample37;
COALESCE 함수는 여러개의 인수를 지정할 수 있다.
주어진 인수 가운데 NULL이 아니면 가장먼저 지정된 인수의 값을 반환
위에 예문은 a 가 NULL이 아니면 a값을 그대로 출력하고, a가 NULL이면 0을 출력합니다.
단순 CASE
encode, decode 또 하나의 CASE
1은 남자 2는 여자라는 코드 체계가 있다면, 모르는 사람과 소통할때
그냥 남자/여자라고 표시하는 편이 낫다. (DB관리 효율상 1,2로 처음에 쓴거같다)
코드(=수치데이터) 를 정보로 바꾸는 것을 디코드 DECODE
정보를 수치데이터로 바꾸는 것을 인코드 ENCODE
이와 같은 것을 CASE로도 처리할 수 있다.
WHEN a = 1 THEN '남자'
WHEN a = 2 THEN '여자'
이렇게 위처럼 단순 CASE식은
CASE 식1
WHEN 식2 THEN 식3
[WHEN 식4 THEN 식5 ...]'
[ELSE 식6]
END
검색 CASE 의 경우

단순 CASE 의 경우

CASE 사용시 주의사항!
이제까지 예제에서
SELECT 구에서 CASE 사용했는데,
CASE 는 어디서나 사용할 수 있고, WHERE에서 조건식의 일부로 쓸 수도 있고,
ORDER BY 에서도 쓸 수 있다.
ELSE 생략
ELSE 생략하면 ELSE NULL이 되는것을 주의,
대응하는 WHEN이 하나도 없으면 ELSE 절이 사용된다.
그래서
CASE문의 ELSE는 생략하지 않는 편이 낫다.
행 추가하기 INSERT INTO
INSERT INTO 테이블 VALUES (값1,값2,...)
이제까지 SELECT는 검색!
이때 데이터 형식을 맞춰야함
바로 실습!

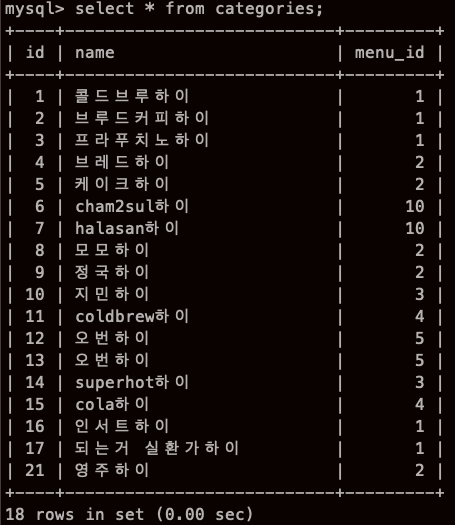
내 카테고리 테이블에서 16 17 PKs 들이 비어있는게 신경쓰였는데
이번에 채워 넣어봤다.

값을 저장할 열 지정하기
INSERT INTO 테이블(열1,열2...) VALUES (값1,값2...)
내가 원하는 컬럼에다가 정보를 넣는것 같은데..
이건 다른 컬럼들이 NULL=TRUE 여야 가능한거 아닌가?
라는 생각에 바로 실험,,,

그치.. 될리가 없지 default 값이 없어서 빈칸으로 못놔둠
삭제하기 - DELETE ..FROM
DELETE FROM 테이블 WHERE 조건식
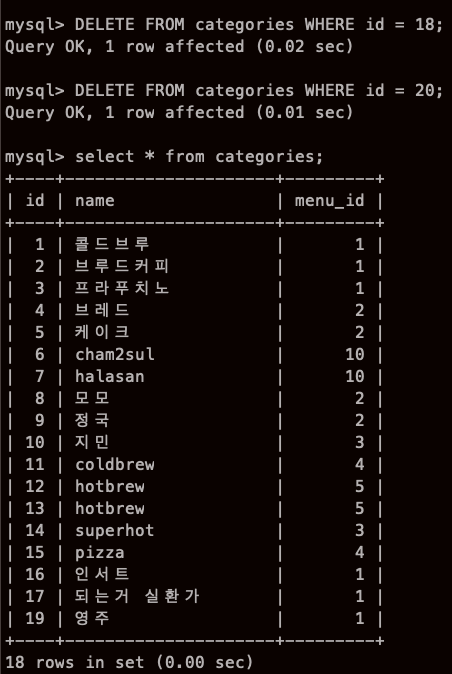
여러줄 한번에 삭제는??
실험해봤는데 안되네..
데이터 갱신하기 - UPDATE ..SET
UPDATE 테이블 SET 열1 = 값1, 열2 = 값2... WHERE 조건식
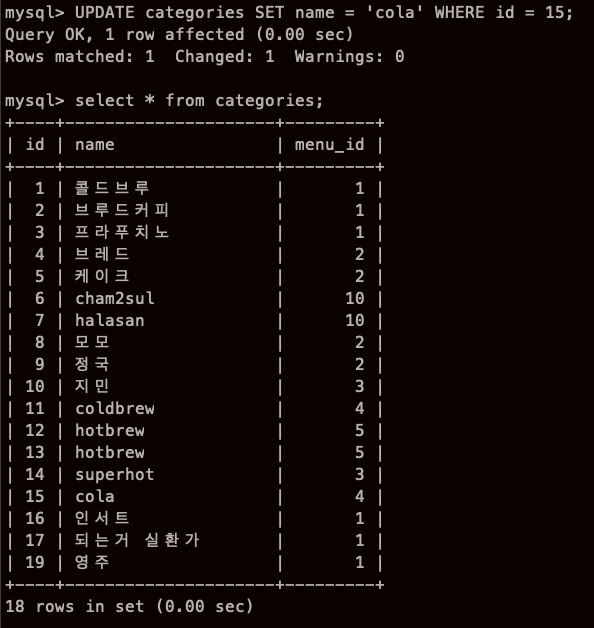
위쪽 사진 보면 알겠지만 원래 15번은 pizza였다!
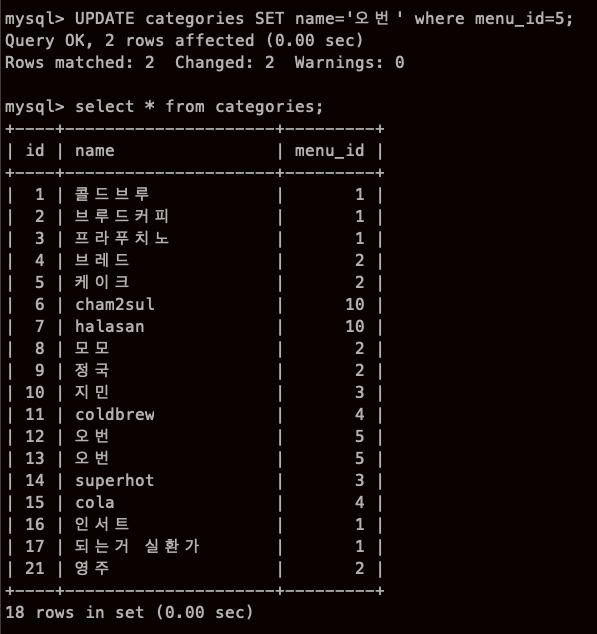
위 사진 처럼 UPDATE 명령에서는 WHERE 조건에 일치하는 '모든 행'이 갱신된다!
실험삼아 한번 해봤는데,, 일 저질렀다... 이거 어떻게 지우지
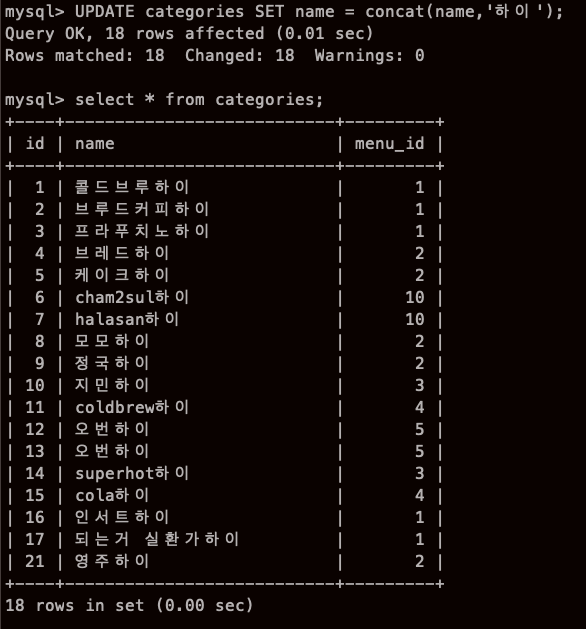
WHERE를 안 썼더니 모두 하이가 붙어버렸다... 맙소사...
NULL 로 갱신하기

저 명령어를 치면 NULL로 되지만.. 내 name 컬럼은 null=True가 아니기 때문에.. 에러..
물리삭제와 논리삭제
물삭.. 논삭..
물리삭제
실제로 그 데이터 행을 지움으로써 지극히 자연스러운 발상에 의한 삭제방법
DELETE FROM xxx WHERE id =11
논리삭제
한편 논리삭제의 경우
삭제 플래그라는 컬럼을 하나 두고
0(FALSE) 이면 존재한다는 것
1(TRUE) 이면 삭제 되었다는 것
논리삭제의
- 장점: 데이터를 삭제하지 않기 때문에 삭제되기 전의 상태로 간단히 되돌릴수 있다는 것
- 단점: 삭제해도 데이터베이스의 저장공간이 늘어나지 않는 점 (DB크기가 증가함에 따라 검색속도가 떨어지는 점을 들 수 있다. 또한 애플리케이션 측 프로그램에서는 삭제임에도 불구하고 UPDATE 명령을 실행하므로 혼란을 야기할 수도 있다.
example)
SNS 서비스처럼 사용자의 개인정보를 다루는 시스템에서는 개인정보 유출 때문이라도 물리삭제가 안전하다
하지만 쇼핑 사이트의 경우 사용자가 주문 취소했을때 논리삭제를 많이 이용한다.
주문이 취소됐다고는 하나 발주는 된 것으로 해당 정보는 완전히 불필요하지 않다.
이러한 데이터는 주문관련 통계를 낼 때 유용하게 사용할 수 있기 때문
결론: 물삭과 논삭은 용도에 맞게 선택한다.
(내가 듣기론 논삭으로 지우고 정해진 기간내에 물삭을 한다고 들은 적이 있다)
집계함수
COUNT(집합)
SUM(집합)
AVG(집합)
MIN(집합)
MAX(집합)
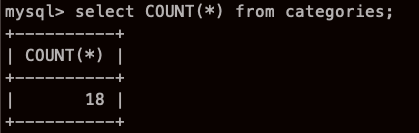
카테고리 테이블의 행 갯수를 센다.
혹시 이것도 이름 바꿀수 있나
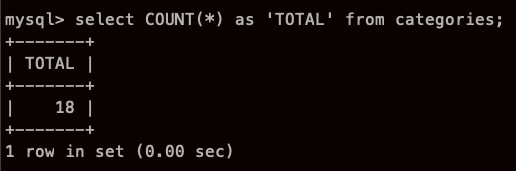
오오.. 된다..
WHERE 구로 지정하여 갯수 세기
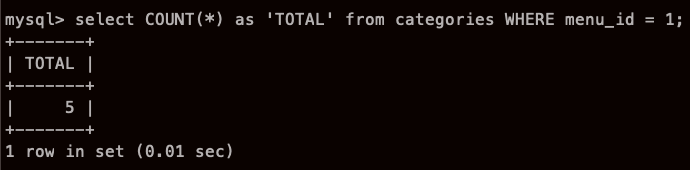
오오.. menu_id 가 1 인 행들 갯수 5개 카운트.. 완벽🌟
- 다만 COUNT()를 할때 NULL 이 있다면 NULL값은 무시하고 갯수를 센다.
DISTINCT 로 중복 제거
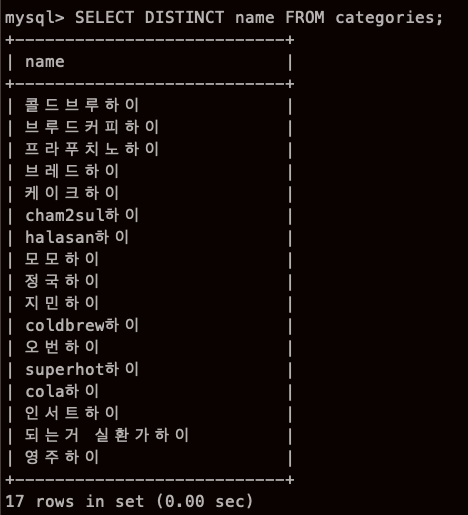
오번하이가 중복이였는데 없어졌다.
그런데.. 이번에 DISTINCT name으로 지정했는데, 전체를 하면 어떻게 될까
menu-id는 중복이 많은데
결과 : 아무일도 일어나지 않았다
중복제거한뒤 갯수 구하기!
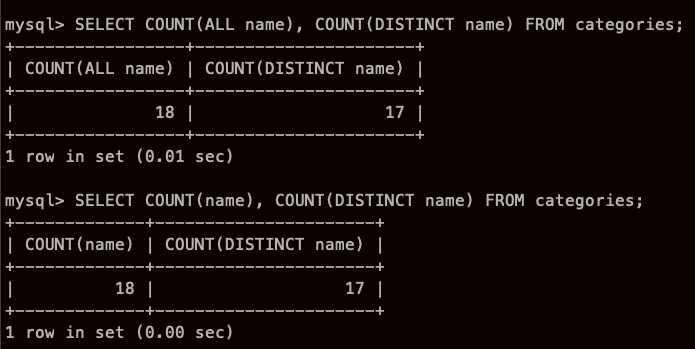
이렇게 하면 name 전체 갯수와 중복제거된 name 갯수가 나온다.
책에는 ALL name 이라고 되어있었는데,
ALL 없어도 다 나오지 않나? 라는 생각에 해보았더니 잘 나왔다!

내가 실험을 잘했다 생각했는데
예제 바로 밑에 이런 글이 있었다.. ㅎㅎ( 좀 읽자 재훈아)
COUNT이외의 집계함수
- AVG()를 할때 여기서 NULL 값은 무시한다
만약 NULL 을 0으로 계산하고 평균을 구하고 싶다면 CASE를 사용해 NULL을 0으로 바꿔서 사용하면 된다.
example
SELECT AVG(CASE WHEN menu_id IS NULL THEN 0 ELSE menu_id END) FROM categories;
만약 NULL 들이 0 으로 들어가서 평균의 계산에 들어간다면, 그냥AVG()보다 값이 낮을것이다.
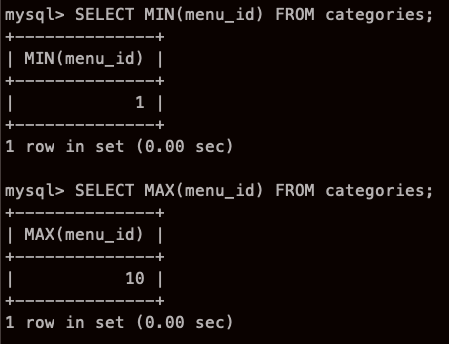
GROUP BY
SELECT * FROM 테이블 GROUP BY 열1,열2
- GROUP BY 구에 열을 지정하여 그룹화하면 지정된 열의 값이 같은 행이 하나의 그룹으로 묶인다.
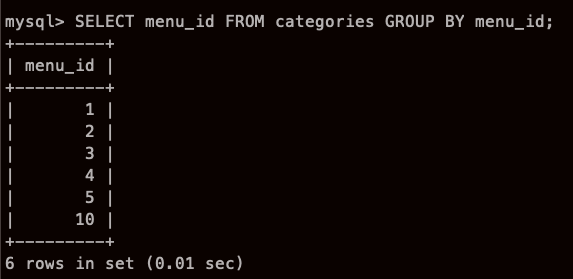
??? DISTINCT랑 비슷한거 같은데? 중복 없앤것이 아닌가?
어떤 차이가 있나?
- 사실 GROUP BY 는 집계함수와 같이 사용하지 않으면 별 의미가 없다.
그러니까
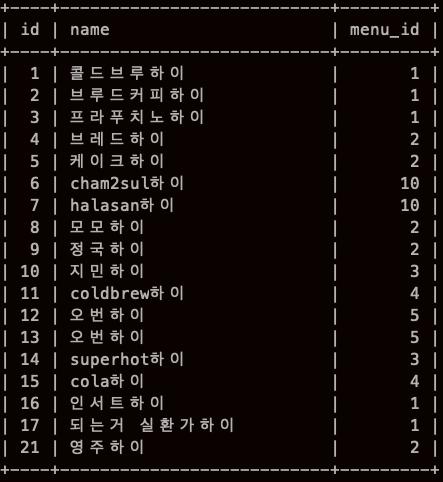
여기서 GROUP BY 를 안하면
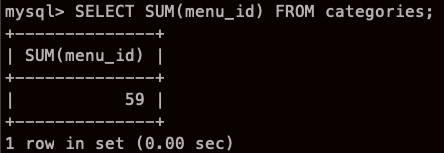
menu_id 가 다 합쳐지고
GROUP BY를 하면
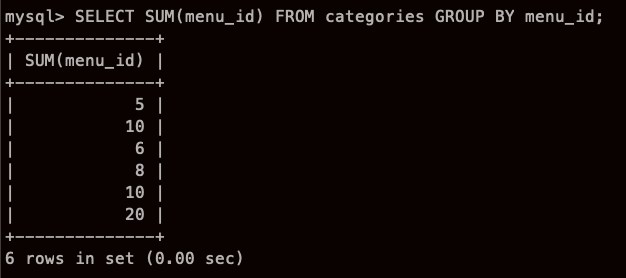
menu_id 가 1 인것이 5개 , 2인것이 5개 (그래서 10) ... 이런식,,
좀 보기 어려운가? 그렇다면
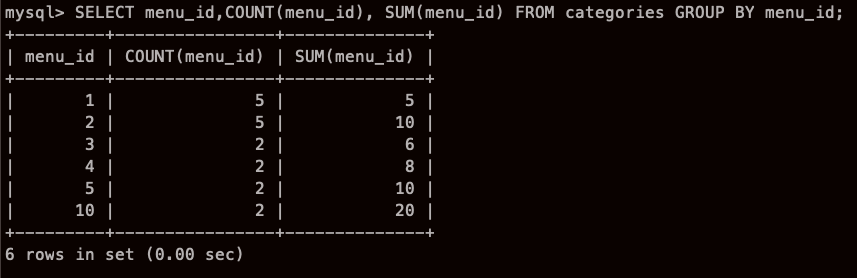
실제로 GROUP BY를 사용하는 경우
예를들면 각 점포의 일별 매출 데이터가
중앙 판매 관리시스템에 전송되어 점포별 매출실적을 집계해
어떤 점포가 매출이 올라가는지, 어떤 상품이 인기가 있는지
등을 분석할 때 사용된다.
여기에서 점포별, 상품별, 월별, 일별 등 특정 단위로 집계
매출실적을 조사하는 동시에 SUM 집계함수로 합계를 낼 수 있으며,
COUNT로 건수를 집계하는 경우도 있다.
HAVING 조건 지정
집계함수는 WHERE 구의 조건식에서 사용할 수 없다.
SELECT COUNT(menu_id) FROM categories WHERE COUNT(menu_id)=1 GROUP BY menu_id;
는 에러발생 ~
이유는 내부처리 순서에 있다.
- WHERE -> GROUP BY -> SELECT -> ORDER BY
그래서 WHERE COUNT(menu_id)=1 은
메뉴아이디의 갯수가 1일때 라는 조건인데, 저 조건이 아직 처리가 안되서 성립이 안된다.
그렇다면?
HAVING 을 사용하면 집계함수를 사용해서 조건식을 지정할 수 있다.
HAVING 은 GROUP BY 의 뒤에 기술하며 WHERE구와 동일하게 조건식을 지정할 수 있다.
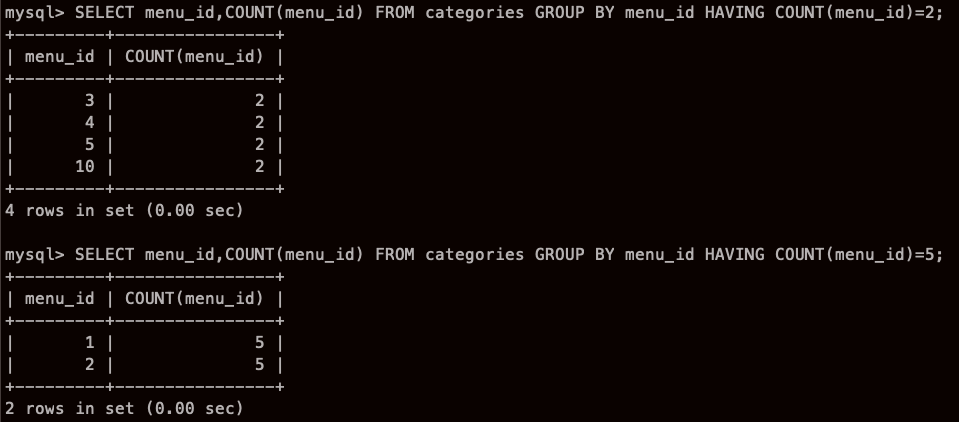
그러니까 해석하면
menu_id 를 GROUP BY로 묶었고 그래서 menu_id 가 3,4,5,10 은 2개 씩 있는데
조건문이 2개씩 있는 것들을 가져와라~
내부처리 순서
- WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
(하지만 SELECT 보다 먼저 처리되서 별명alias는 못붙힌다)

근데 MySQL은 융통성이 있어서 별명을 사용할 수 있다.
복수열의 그룹화 주의사항
SELECT id, name, menu_id FROM categories GROUP BY name;
name은 GROUP BY지정했지만
id, menu_id는 지정안해서 에러가 난다.
이때 집계함수를 사용하면 집합은 사나의 값으로 계산되서 그룹마다 하나의 행 계산 가능
SELECT MIN(id), name, SUM(menu_id) FROM categories GROUP BY name;
- GROUP BY 에서 지정한 열 이외에 열은 집계함수 안쓰면 SELECT에서 사용 못함!
만약 이러면 가능
SELECT id, name FROM categories GROUP BY id, name;
그리고 정렬을 하고 싶다면
SELECT MIN(id), name, SUM(menu_id) FROM categories GROUP BY name ORDER BY SUM(menu_id);
서브쿼리
(올게 왔다..)
서브쿼리는 SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의를 의미
(SLECET 명령) << 이게 SYNTAX
간단히 명령이라 적었지만 , SELECT, FROM, WHERE 등 사용 가능
DELETE 의 WHERE 에서 서브쿼리 사용하기
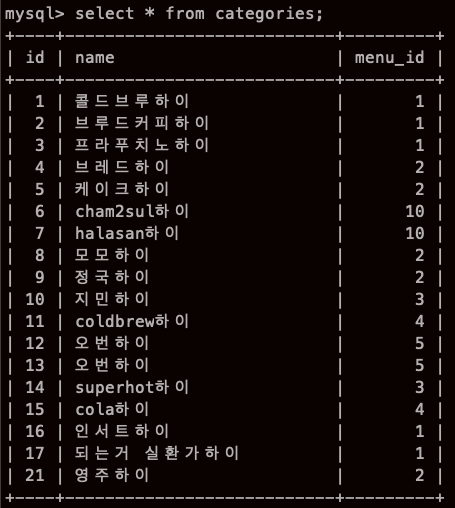
자 여기서 menu_id 가 큰것을 지우고 싶다
그럼 delete 하면 되겠지 저기 10 이 보이니까
만약 너무 데이터가 많아서 몇인지 모르면 어떡할까
SELECT MAX(menu_id) FROM categories; 로 찾고 지우겠지?
근데 이걸 한방에 합치는게 서브쿼리
실습을 하려고 했는데

????????????????
- MySQL은 데이터를 추가하거나 갱신할 경우 동인한 테이블을 서브쿼리에서 사용할 수 없도록 되어 있기 때문... 에러 발생않고 실행하려면 인라인 뷰로 임시 테이블을 만들도록 처리하면 된다.
DELETE FROM categories WHERE id = (SELECT id FROM (SELECT MIN(id) as a FROM categories) as x);
이렇게 해볼려고 했는데, 다른 테이블과 엮여 있어서 불가능..실습 실패,
스칼라 값

이렇게 하나의 값으로만 반환하면 이것을 단일 값이라고도 부르지만
스칼라 값을 반환한다~ 라고 한다.
스칼라 값이 왜 특별하냐면,서브쿼리로서 사용하기 쉽기 때문!
왜냐면
- 통상적으로 특정한 두 가지가 서로 동일한지 여부를 비교할 때는 서올 단일한 값으로 비교합니다.
즉 WHERE구에서 스칼라 값을 반환하는 서브쿼리는 = 연산자로 비교할 수 있다는 뜻!!
스칼라 값을 반환하는 서브쿼리를 특별히 '스칼라 서브쿼리'라고 부르기도 하는데,
앞서 HAVING을 설명할 때 '집계함수는 WHERE에서는 사용할 수 없다'
라고 설명했지만 스칼라 서브쿼리라면 WHERE에서 사용할수 있으므로
집계함수를 사용해 집계한 결과를 조건식으로 사용할 수 있다.
SELECT 에서 서브쿼리 사용하기
문법적으로 서브쿼리는 '하나의 항목'으로 취급,
하지만! 문법적으로는 문제 없지만 실행하면 에러가 자주 발생한다.
이는 스칼라 값의 반환 여부에 따라 생기는 현상.
- 그래서 서브쿼리를 사용할 때는 스칼라 서브쿼리로 되어있는지 확인해야한다.
마찬가지로 SELECT에서 서브쿼리를 지정할 때는 스칼라 서브쿼리가 필요
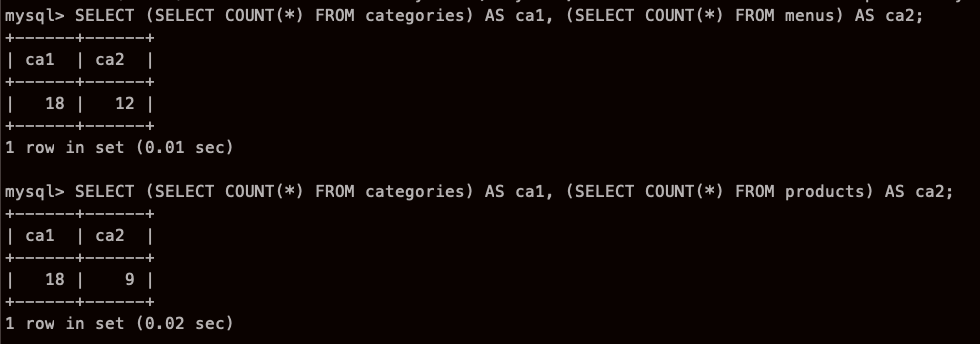
이것이 카테고리 행 개수와 , 다른 테입즐 행개수를 각 서브쿼리로 구하는 것
여기서 한가지 주의할 점!!
서브쿼리가 아닌 상부의 SELECT 명령에는 FROM 구가 없다.
MySQL에서는 실제로 FROM구를 생략할 수 있다.
SET 에서 서브쿼리 사용하기

왜 에러나지.. 아무튼
SET에서 서브쿼리를 사용할 경우에도 스칼라값을 반환하도록 스칼라 서브쿼리를 지정할 필요가 있다.
위처럼 이런 명령도 가능하다 라는것을 보여주는 예제이다 보니
실질적으로는 별로 쓰이지 않는 UPDATE 명령이 되어버렸다.
FROM 에서 서브쿼리 사용하기
지금까지는 FROM에서 테이블 지정만 했지만 FROM에 테이블 이외의 것도 지정 가능
- FROM에서는 스칼라 값을 반환하지 않아도 된다.( 스칼라 값이여도 상관은 없다)
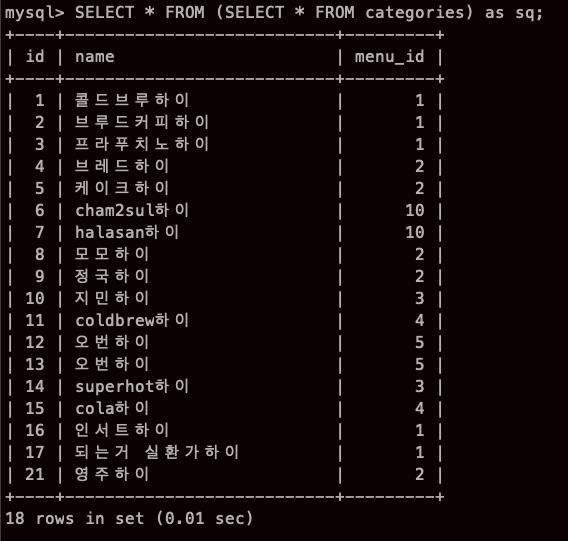
이렇게 서브쿼리로 FROM에서도 쓸 수 있다
(별명도 붙힐 수 있다)
INSERT 명령과 서브쿼리
2가지 방법
- VALUES의 일부로 서브쿼리를 사용하는 경우
- VALUES 대신, SELECT 명령을 사용하는 경우
(내 예제 테이블이 알맞지 않아서 책 예제를 썼다)
541 테이블에 (이미 a 랑 b 라는 칼럼이 있었고)
51테이블 행 갯수와, 54테이블 행 갯수를 INSERT 한것

(괄호가 없어서 서브쿼리라고 부르기 어려울 수도 있다)
아니 근데? 진짜 이거 그냥 INSERT 문법 아닌가? 결과가 같은데?

그 다음장에 이렇게 써있다.
- 흔히 INSERT SELECT 라 불리는 명령
- INSERT INTO sample541 VALUES (1,2) 와 같다!!
- SELECT가 반환하는 열 수와 자료형이 INSERT할 테이블과 일치하기마 하면 된다 << 제일 중요!
INSERT SELECT명령은 SELECT 명령의 결과를 INSERT INTO 테이블로 전부 추가
이 때문에 데이터의 복사나 이동을 할 때 자주 사용하는 명령
열 구성이 같은 테이블은 이렇게 행을 복사 할수 있다
- INSERT INTO sample542 SELECT * FROM sample543;
상관 서브커리
이건 무슨 상관..?
EXISTS (SELECT명령)
EXIST
서브쿼리를 사용해 검색할때 '데이터가 존재하는지 아닌지' 판별하기 위해 조건을 지정할 수 있다.
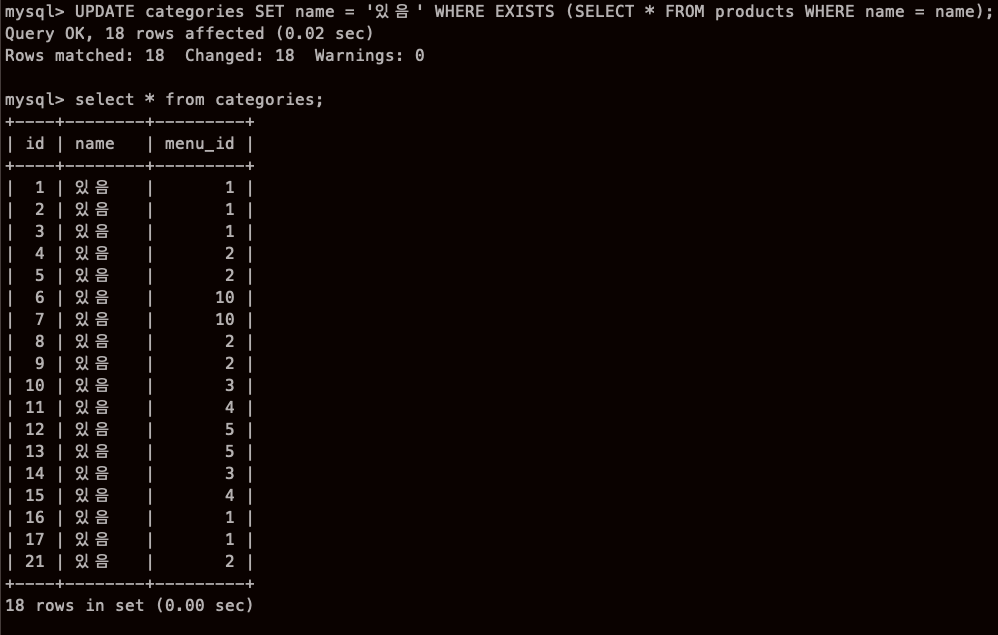
맙소사,, 내가 무슨 짓을 저지른 거야...
뭘 잘못한거지... 아 이름이 이름이 다 있어서 ,,, 그런가..?
다시다시
여기 프로덕트
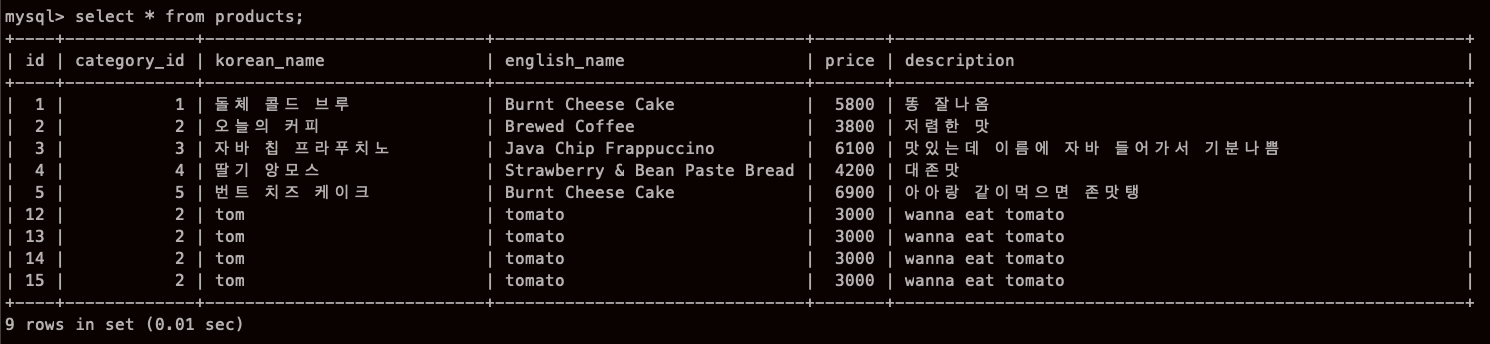
여기 카테고리

pseudo코드:
카테고리 테이블 name 과 products 테이블의 korean_name 컬럼이 일치하는 게 있으면
카테고리 테이블에 그 일치하는 행 menu_id 를 3으로 바꿔!
(처음에 다 바껴서 진짜 당황했다)
NOT EXIST
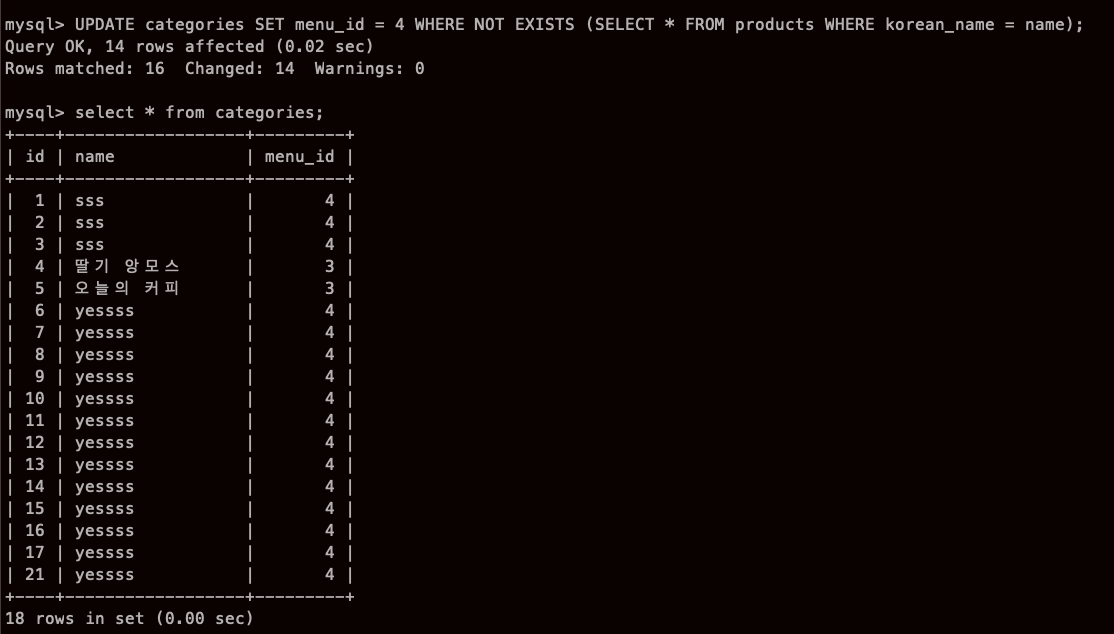
pseudo코드:
카테고리 테이블 name 과 products 테이블의 korean_name 컬럼이 일치하는 게 있으면
카테고리 테이블에 그 일치하는 행 을 제외하고 menu_id 를 4으로 바꿔!
상관 서브쿼리
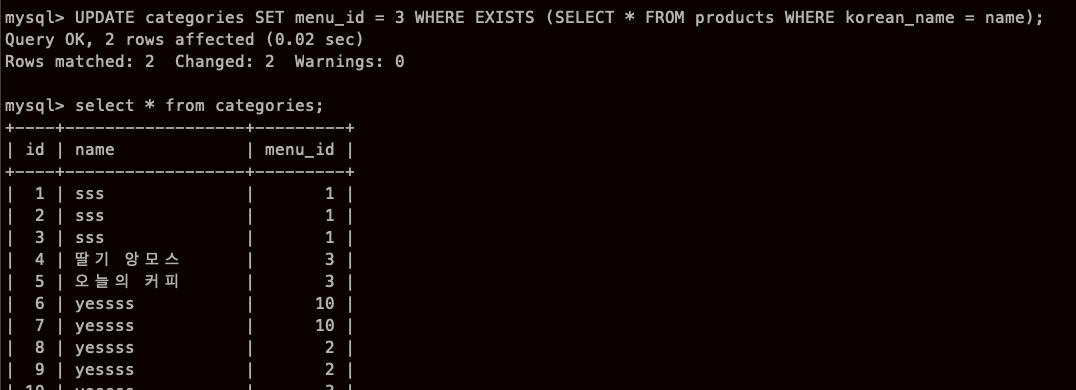
명령어 뒤쪽에 보면 korean_name=name 이라고 되어있는데,
korean_name 은 서브쿼리 안에 products 테이블이라고 명시 되어있기에 알 수 있지만
name은 어디 name인지 모를 수 있는데, 그때 부모 쿼리 (WHERE 앞쪽) 의 컬럼인걸 알수있다.
그래서 상관 서브 쿼리라고 부른다.
근데 만약 이러면?
- UPDATE categories SET menu_id = 4 WHERE NOT EXISTS (SELECT * FROM menus WHERE name = name)
열이 애매하므로 에러가 나지만 MySQL에서는 menus.name= menus.name이 되어서 항상 참이 된다.
그래서 결과적으로 categories 의 모든 행은 바뀐다...
(아 이래서 다 바꼈구나... 이책은 내가 궁금한게 있으면 다 알아서 긁어준다..)
아무튼 그래서 테이블 명을 붙여준다!!
- UPDATE categories SET menu_id = 1 WHERE EXISTS (SELECT * FROM products WHERE products.name = categories.name);
- 위처럼 하면 DB가 열을 헷갈리지 않고 " 아 쟤네 둘이 같은 행에서 menu_id를 1로 바꾸면 되겠군!" 이라고 해석
IN
스텔라 값끼리는 = 연산자를 사용하지
하지만 집합을 비교할 때는 사용할 수 없지
IN 을 사용하면 집합안의 값이 존재하는지를 조사할 수 있다.
- IN 에서는 오른쪽에 집합을 지정
- 왼쪽에 지정된 값과 같은값이 집합안에 존재하면 참을 반환.
- 집합은 상수 리스트를 괄호로 묶어 기술
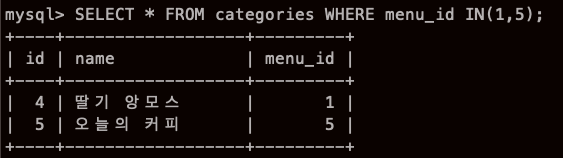
이러면 별거 아닌 것 같지만

조건을 이렇게 여러개 넣어도 깔끔하다!!
IN의 오른쪽을 서브쿼리로 지정하기!

데이터베이스 객체
여기서 객체는C++, JAVA에서 사용하는 객체지향 프로그래밍의 '객체'와 혼돈하는 경향이 있는데,
- DB에서는 테이블이나 뷰, 인덱스 등 DB내에 정의하는 모든 것을 일컫는다.
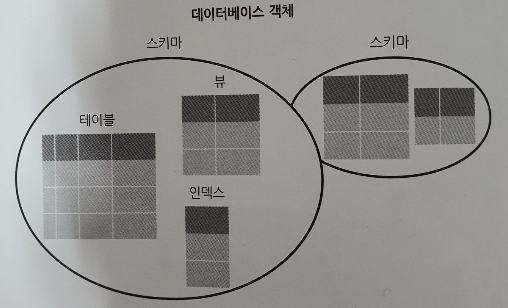
- 객체는 DB내에 실체를 가지는 어떤 것

한편 SELECT 나 INSERT 등은 클라이언트에서 객체를 조작하는 SQL 명령어
그래서 객체가 아니다!!
- 객체는 이름을 가진다. 겹치지 않도록 한다
- 객체 이외에도 테이블의 열 또한 이름을 가진다. 그리고 컬럼에 별명도 붙일 수 있다.
- 열이나 별명은 객체가 아니다
- 이름을 붙일 때에 규칙
- 기존 이름이나 예약어와 중복하지 않는다.
- 숫자로 시작할 수 없다
- 언더스코어 이외의 기호는 사용할 수 없다.
- 한글을 사용할 때는 더블쿼트 (MySQL에서는 백쿼트)로 둘러싼다.
- 시스템 허용 길이를 초과하지 않는다.
스키마 SCHEMA
DB객체는 스키마라는 그릇안에 만들어진다.
객체 이름이 같아도 스키마가 다르면 상관없다.
- 실제로 DB테이블을 작성해서 구축해나가는 작업을 '스키마 설계'라고 부른다.
- MySQL에서는 CREATE DATABASE 명령으로 작성한 'DB'가 스키마가 된다.
테이블과 스키마는 무엇인가를 담는 그릇 역할을 한다는 점에서 비슷하다.
가가가의 그릇안에서는 중복하지 않도록 이름을 지정한다.
이처럼 이름이 충돌하지 않도록 기능하는 그릇을 네임스페이스(namespace)라고 부르기도 한다.
- 결론: 스키마나 테이블은 Namespace이다!
테이블 작성, 삭제, 변경
CREATE TABLE 테이블명(열 정의1, 열정의2,...)
DROP TABLE 테이블명
ALTER TABLE 테이블명 하부 명령
이제까지 배운SELECT, INSERT, DELETE, UPDATE 는 DML에 해당된다.(데이터 조작)
테이블 작성
DDL 은 모두 같은 문법 사용
CREATE TABLE
CREATE VIEW 모두 가능
일단 테이블 먼저 만들어보자
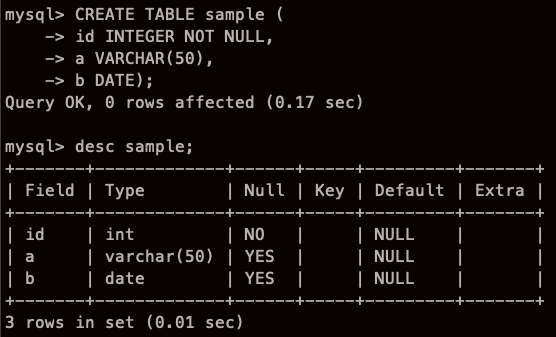
와... 진짜 드디어 sql로만 써서 테이블을 만들었다..
이제까진 파이썬 장고로 models.py에 적고 ORM 이 다 해주면
python manage.py makemigrations , migrate해서 만들었는데...
sql로만 하니까 얼마나 직관적인가..
(근데 오타나면 다시 써야하고, 글씨 색이 안변해서,,
가독력 너무 떨어짐.. 이게 백엔드 갬성인가...)
DROP TABLE sample; 하면 없어지겠지?
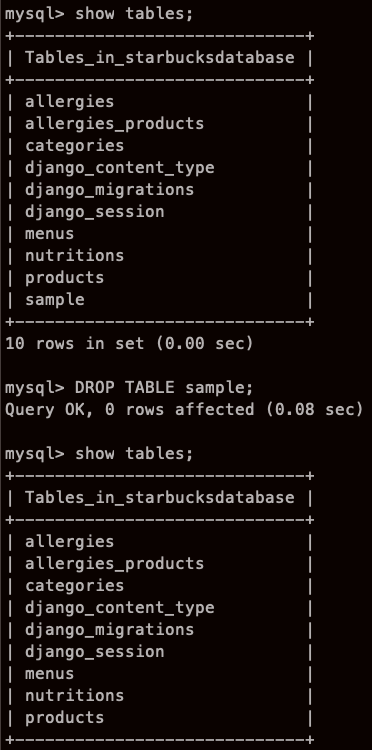

이때 DELETE 에서 WHERE을 안걸면 모든 행을 다 지운다.
그런데 DELETE명령은 행 단위로 여러가지 내부처리가 일어나므로 삭제할 행이 많으면 처리속도가 상당히 늦어서
이럴 땐 TRUNCATE TABLE 테이블명,
행을 지정할수 없어서 무차별적으로 지워서 속도가 빠르다.
테이블 변경
ALTER TABLE로 할 수 있는 일은 크게 2가지
- 열 추가, 삭제, 변경
- 제약 추가, 삭제
열 추가 (Column add)

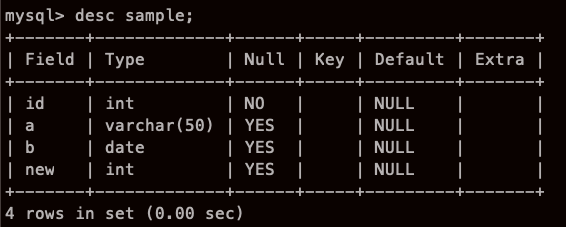
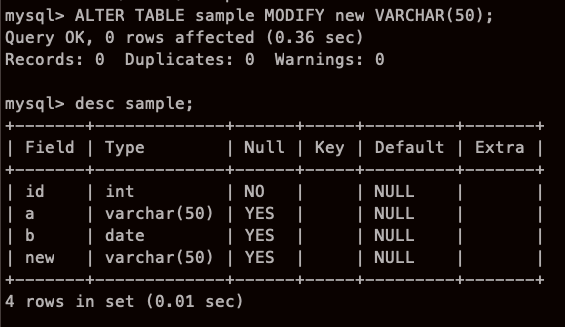
열 속성 변경 (modify)
열 이름은 변경 할 수 없어도 자료형, 기본 값, NOT NULL 은 바꿀 수 있다.

열 이름 변경 (change)

열 삭제
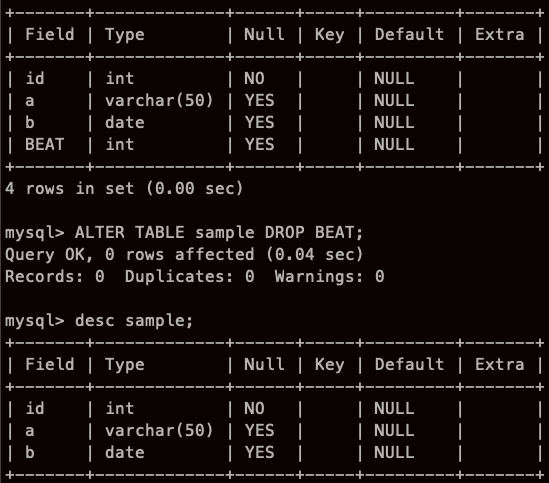
드랍 더 빝!!!!!!!
(이거 너무 하고 싶었...)
제약
테이블 작성시 제약 정의

오.. UNIQUE 넣으니까 그게 Primary Key가 되는건가..
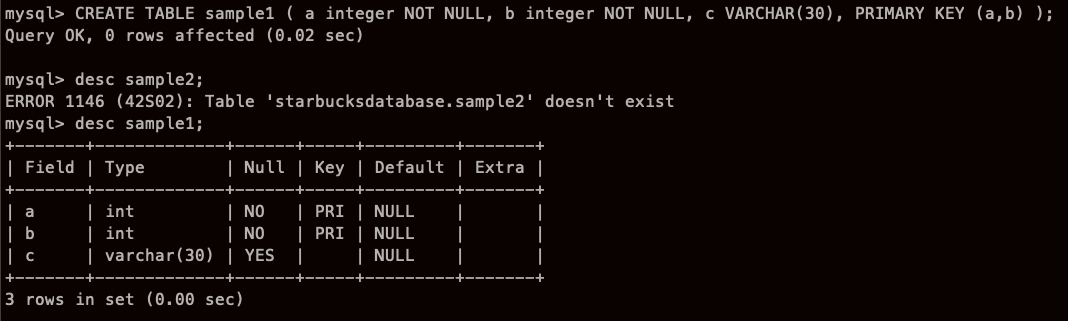
(중간엔 sample2는 오타)
PRIMARY KEY는 뒤에서 정해줘도 된다.
제약에는 이름을 붙일수 있는데
나중에 관리하기 쉬워지므로 가능한 한 이름을 붙이도록 하자
제약 이름은 CONSTRAINT 키워드를 사용해서 지정한다.
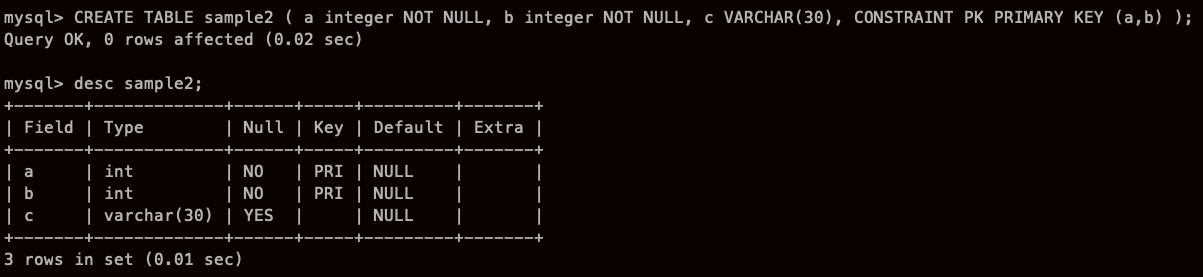
이렇게 해서 보이는 건 아까와 다르지 않은데,, 뭐 나중에 관리 하기 쉽다니까..
제약 추가
열제약과 테이블제약은 조금 다른 방법으로 추가한다.
열 제약 추가
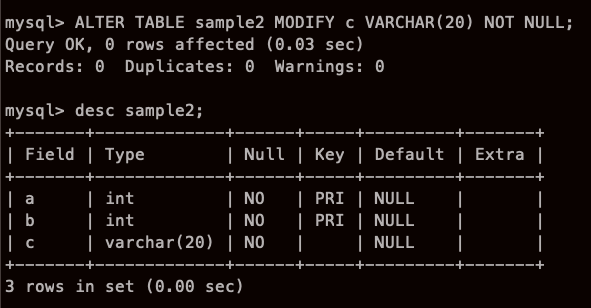
테이블 제약 추가
기본키 제약 추가하기
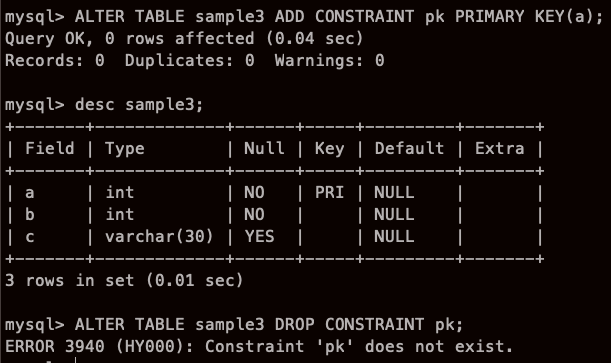
왜 안될까... 방금 설정했는데,,

이렇게는 되네,,어차피 기본키는 테이블당 하나만 설정할 수있어서 제약명을 지정하지 않아도 삭제할 수 있다.
기본키
실험으로 쓸 테이블 생성!
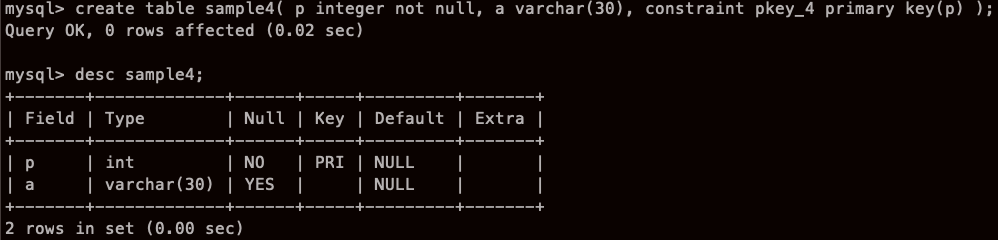
- 기본키로 지정할 열은 NOT NULL 제약이 설정되어 있어야 한다.

기본키로 설정된 열이 중ㅂ족하는 데이커 값을 가지면 제약에 위반된다

이것도 안된다!!
인덱스 구조
- 인덱스의 역할은 검색속도의 향상
- 여기서 검색이랑 SELECT 명령에 WHERE 구로 조건을 지정하고 그에 일치하는 행을 찾는 일련의 과정을 말한다. (검색 = 탐색)
- 테이블에 인덱스가 지정되어 있으면 효율적 검색 가능
- WHERE 로 조건이 지정된 SELECT 명령의 처리 속도가 향상된다.
- 목차밖에 없는 책은 없듯이 인덱스만으로는 의미 X
- 인덱스는 테이블에 의존하는 객체
- 테이블을 삭제하면 인덱스도 같이 삭제
DB의 인덱스에 쓰이는 대표적인 검색 알고리즘으로는 '이진 트리'(binary tree)가 있으며 다음으로 '해쉬'가 유명하다
인덱스 작성과 삭제
- CREATE INDEX
- DROP INDEX
MySQL 에서 인덱스는 테이블 내의 객체가 된다.
그래서 테이블내에 이름이 중복되지 않도록 지정해 관리한다.
EXPLAIN
인덱스랑 explain 일단 넘어가자
뷰 VIEW
CREATE VIEW 뷰명 AS SELECT 명령
DROP VIEW 뷰명
뷰 역시 DB 객체중 하나,
반면 SELECT 명령은 객체가 아니지,
하지만! 객체로서 이름을 붙여 관리할 수 있도록 한 것이 뷰!
앞선 예제에서는 서브쿼리 부분이 단순한 SELECT 명령으로 되어 있지만,
실제 업무에서는 WHERE 구로 조건을 지정하거나 GROUP BY 구로 집계하는 등
좀더 복잡한 명령이 많은데
이런 경우 서브쿼리 부분을 뷰로 대체하여 SELECT 명령을 데이터베이스에 등록해 두었다가
나중에 간단히 실행할 수 있다.
즉, 자주 사용하거나 복잡한 SELECT 명령을 뷰로 만들어 편리하게 사용할 수 있는것
-
가상테이블이라고도 불린다.
-
SELECT 명령으로 이루어지는 뷰는 테이블처럼 데이터를 쓰거나 지울 수 있는 저장공간을 가지지 않는다.
-
이 때문에 테이블처럼 취급할 수 있으나 'SELECT'명령에서만 사용 하는 것을 권장
뷰 작성과 삭제
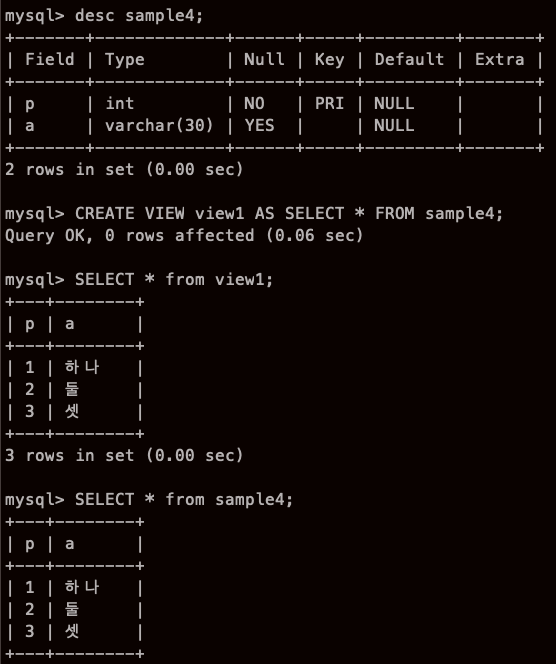
흠,, 아직까진,,, 뷰를 만들어도,,, 그냥 테이블 만든 것과 같은데,,,
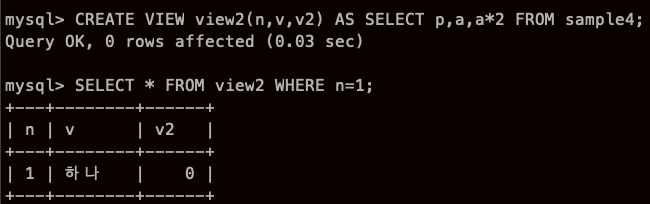
오오오오오오!!!!! 1 이랑 하나 가 들어가져있어,, 열 이름은 뷰의 열인데,,
가상테이블인데 정보는 진짜 테이블에서 땡겨오네,,,
삭제: DROP VIEW 뷰명
뷰의 약점
- 뷰는 데이터베이스 객체로서 저장장치에 저장된다.
- 하지만 테이블과 달리 대량의 저장공간을 필요로 하지 않는다.
- DB에 저장되는 것은 SELECT명령 뿐이기 때문
- 대신,, CPU 자원을 사용한다.
- SELECT 명령은 데이터베이스에서 행을 검색해 클라이언트로 반환하는 명령
- 검색뿐 아니라 ORDER BY 정렬이나 GROUP BY 집계 가능
- 이러한 처리는 계산능력을 필요로 해서 컴퓨터의 CPU를 사용
- 뷰를 참조하면 뷰에 등록되어 있는 SELECT 명령이 실행된다. 실행 결과는 일시적으로 보존되며,
뷰를 참조할 때마다 SELECT 명령이 실행된다.
함수 테이블,
뷰의 또 하나의 약점,
상관 서브쿼리에서 언급한 것처럼, 부모쿼리와 어떤식으로든 연관된 서브쿼리의 경우에는
뷰의 SELECT명령으로 사용할 수 없다.
- 대신 함수 테이블을 쓰면 회피할 수 있다.
함수테이블은 테이블을 결괏값으로 반환해주는 사용자 정의 함수 이다.
함수에는 인수를 지정할 수 있기 때문에 인수의 값에 따라 WHERE 조건을 붙여 결괏값을 바꿀 수 있다.
그에 따라 상관 서브쿼리 처럼 동작할 수 있다.
집합연산
일단 실험용 테이블을 만들었다.
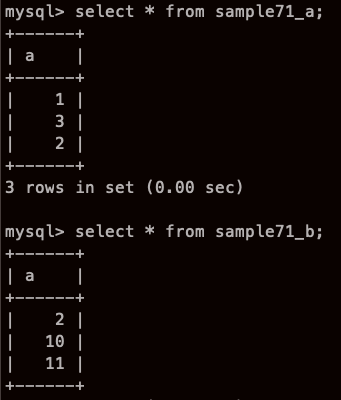
오오.. 합쳐졌어..! 이것이 합집합 (a U b)

UNION 으로 두개의 SELECT명령을 하나로 연계해 질의 결과의 얻을수 있다.!!!
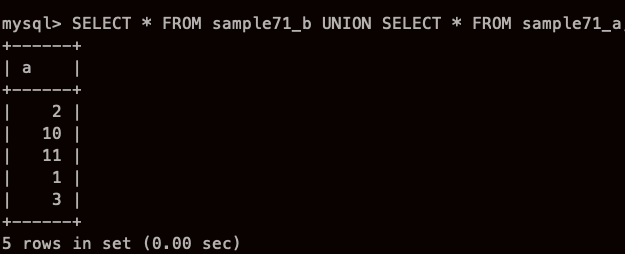
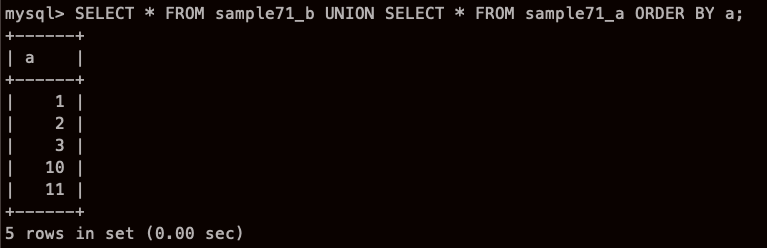
오오 순서 바꿨더니 이렇게 됬다.!!!
ORDER BY 정렬 하고 싶으면 마지막에 넣어라!
UNION ALL
유니온을 쓰게 되면 중복된 2가 없어지는데 DISCTINCT와 같은 현상이 일어나게 된다.
혹시 2가 2개 나오게, 그러니까 중복제거 없이 나오게 하고 싶다면

MySQL은 교집합 X 차집합 X
테이블 결합 JOIN
교차집합(Cross Join)
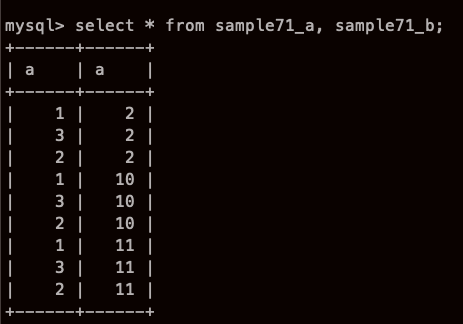
대략 이해가 가나? 너무 알아보기 어려운 예제인가?
근데 순서 바꾸면 어떻게 되지?
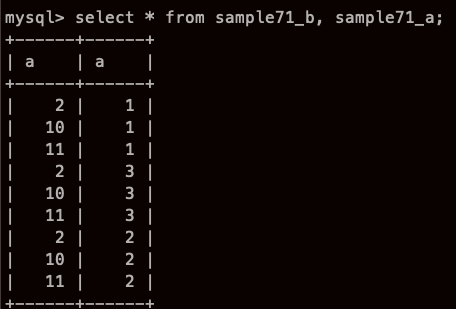
이렇게~
- 근데 내부결합을 더 많이 쓴다고 한다.
내부 결합


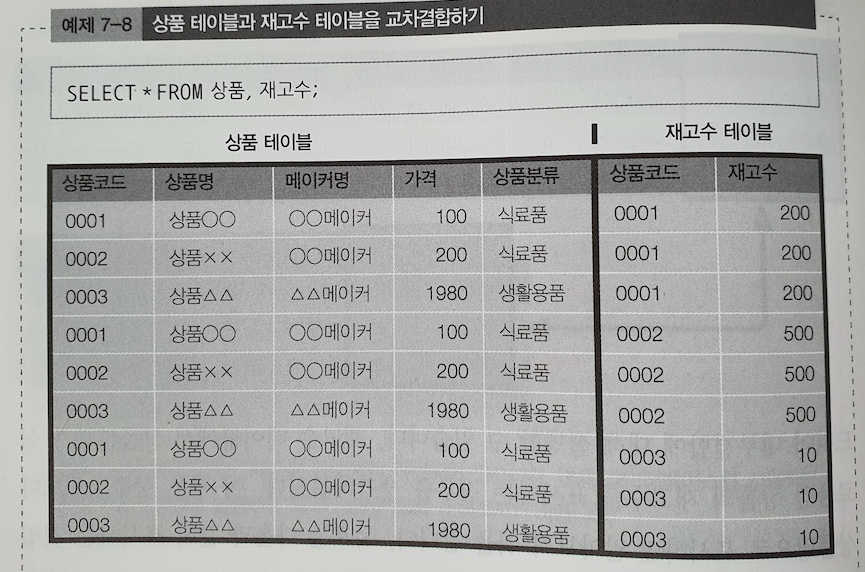
이게 먼저 교차 결합이고!

이렇게 교차결합으로 계산된 곱집합에서 원하는 조합을 검색하는 것을 '내부결합(INNER JOIN)' 이라 부른다.
다음으로는 상품분류가 '식료품'이라는 조건이 필요하다.
이 조건을 WHERE구에 추가해보겠다.
추가할 때는 기존 조건식과 상품분류의 조건식이 모두 참이여야 되니까
AND로 조건식을 연결한다.
또한 상품명과 재고수만 반환하도록 SELECT 구에 열을 지정한다!
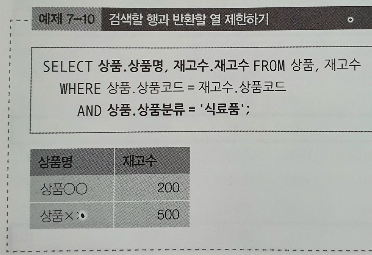
이렇게 하면 상품.상품코드 = 재고수.상품코드 조건에다가 상품.상품분류 가 식료품인
상품.상품명 & 재고수,재고수 만 나오게 된다!
첫번째 조건식은 조건식은 교차결합으로 계산된 곱집합에서 원하는 조합을 검색하는것.
두번째 조건식은 결합조건이 아닌 검색 조건,
여기에서 첫번째 조건식의 조건을 '결합조건'이라고 한다.
INNER JOIN으로 내부결합하기
- FROM 구에 테이블을 복수 지정해 가로방향으로 테이블을 결합할 수 있다.
- 교차결합하면 곱집합으로 계산된다.
- WHERE 조건을 지정해 곱집합에서 필요한 조합만 검색할 수 있다.
지금까지 보여준 예제는 약간 구식이고
이제부터가 최신식!!!!
INNER JOIN 키워드를 사용한 결합방법이 일반적으로 통용됩니다.
지금부터 상품 테이블과 재고수 테이블을 이용한 사례를 INNER JOIN 을 활용해 본다!
SELECT 상품.상품명, 재고수.재고수
FROM 상품 INNER JOIN 재고수
ON 상품.상품코드 = 재고수.상품코드
WHERE 상품.상품분류 = '식료품';
SELECT * FROM 테이블명1 INNER JOIN 테이블명2 ON 결합조건
내부결합을 활용한 데이터 관리
CREATE TABLE 메이커(
메이커코드 CHAR(4) NOT NULL,
메이커명 VARCHAR(30),
PRIMARY KEY (메이커코드)
);
이렇게 메이커 코드가 있는 테이블을 만들고
원래 상품 테이블과 합치면 이렇게
그리고! 상품테이블과 메이커 테이블을 내부결합하기
SELECT S.상품명, M.메이커명
FROM 상품2 S INNER JOIN 메이커 M
ON S.메이커코드 = M.메이커코드;
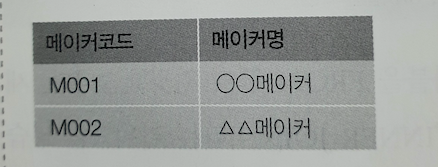
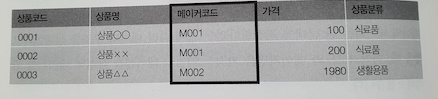

이번에는 테이블 별명도 붙였다.
SELECT 명령에서 복수의 테이블을 다룰 경우 어느 테이블의 열인지
정확하게 지정해야 한다.
이때 테이블명을 매번 지정하는건 노노 그래서 짧게 한글자
앞에 예제에서도 메이커 테이블엔 M 상품테이블엔 S 짧은 별명을 붙였다.
관계형 모델

용어가 좀 다르다.
관계대수에서 자주 사용될것같은 릴레이션의 연산 방법을 몇 가지 규정
왼쪽은 관계형 모델에서 부르는 이름
오른쪽은 SQL에서 쓰는 명령어
-
합집합 UNION
-
차집합 EXCEPT
-
교집합 INTERSECT
-
곱집합 CROSS JOIN
-
선책 WHERE
-
투영 SELECT
-
결합 JOIN (INNER, LEFT, RIGHT)
TRANSACTION
트랜젝션을 사용해서 데이터를 추가한다면 에러가 발생해도 트랜잭션을 롤백해서
종료할 수 있다.
롤백하면 트랜잭션 내에서 행해진 모든 변경사항을 없었던 것으로 할 수있다.
아무런 에러가 발생하지 않는다면 변경사항을 적용하고 트랜잭션을 종료하는데
이때 커밋을 사용한다.
자동커밋
트랜잭션을 사용해서 데이터를 추가할 때는 자동커밋을 꺼야한다.
INSERT 나 UPDATE, DELETE 가 처리될 때마다 트랜잭션은 암묵적으로 자동커밋 상태로
되어있다.
자동커밋을 끌려면 명시적으로 트랜잭션의 시작을 선언할 필요가 있다.
START TRANSACTION
COMMIT
ROLLBACK
- Mysql에서는 START TRANSACTION 이외에 BEGIN 도 쓴다
SQL 첫걸음 끝
책한권 끝냈다..
출처: SQL 첫걸음
아사이 아츠시 지음
박준용 옮김
한빛미디어 출판
