wecode TIL 18 (Nov 5)
- 처음에 오리진 에서(리파지토리가서 코드 누르고 HTTPS 복사하고) 명령어 @ GIT CLONE 복사한 주소
- git branch 라고 명령어를 치면, 내가 해당하는건 별 표시 뜨고, 내가 지금 어디 브랜치인지 알려준다.. (내가 어디 브랜치에 있는지 자주 확인해주는 습관을 가지는게 좋다.
- 그러면 이제 로컬에 마스터(메인)이 생겼다, 이제 여기 기준으로 feature/branch 를 만들어준다 (feature/브랜치 이름 <<feature는 컨밴션 개념 ,,, git branch 이름 (ex. git branch feature/noah14) (feature/ 앞에 붙히는게 컨밴션,,?!)
- 깃이 무엇을 관리 하는 프로그램인가! 버젼관리
- git checkout feature/noah14 라고 뜬다.
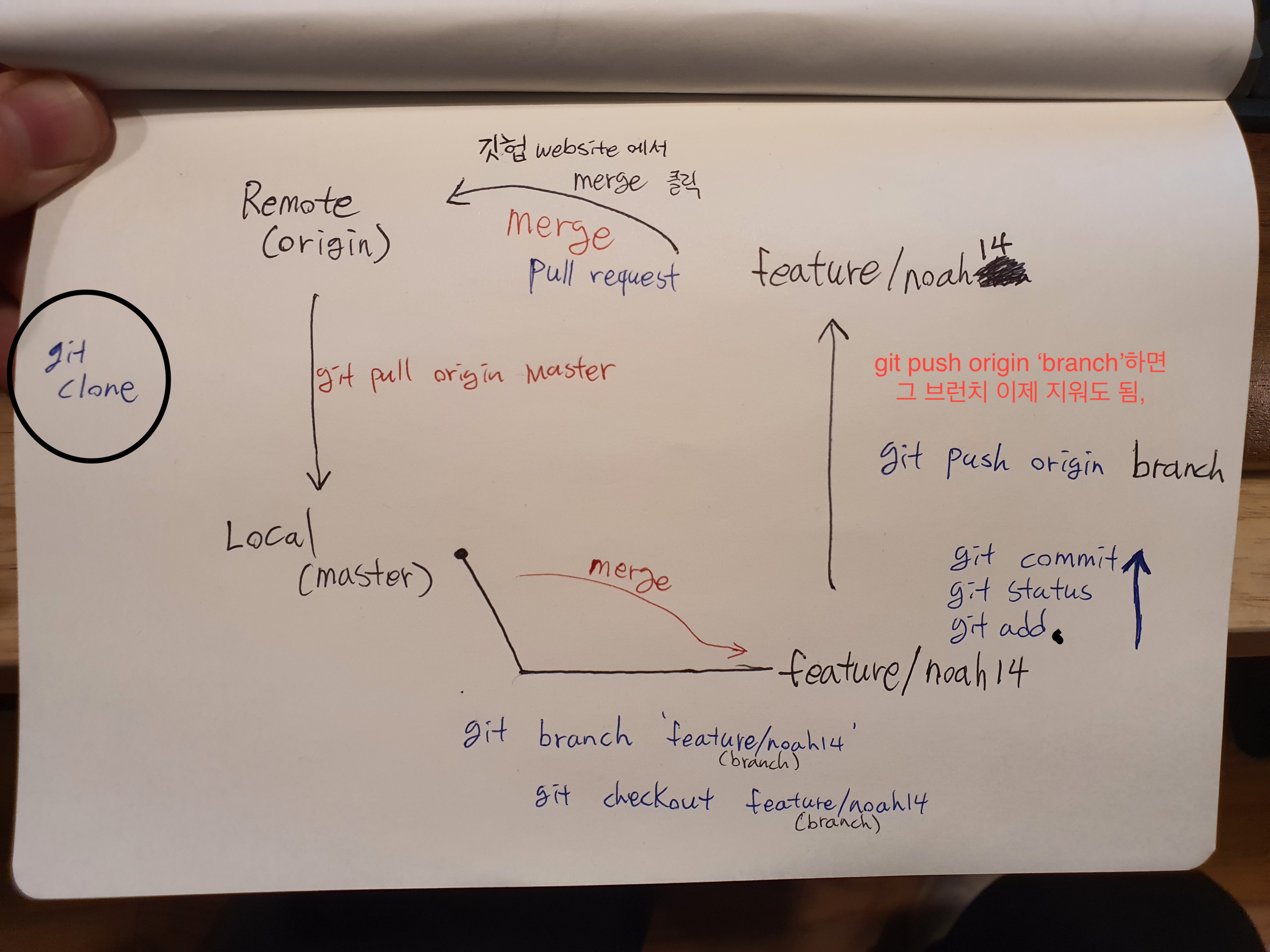
- 내 브랜치에서 내 폴더를 만들고, 거기다 작업하고
- git add. ( .은 여기있는거 싹다)
- git status ( 뭐가 바뀌는지 확인)
- git commit 하고
- git push origin 브랜치이름,,,, 하면 내 브랜치가 github으로 올라간다.
10.1 git pull request를 해야하는데 명령어가 헷갈린다. - github에서 merge를 해주면 내 로컬 브랜치는 이제 존재 이유가 없어서 지워도 된다 (나중에 헷갈리니까 지우자)
- 오리진에서 머지된것을 받고 싶을때 git pull origin master, 오리진에서 마스터로 땡긴다.
- 땡겨진 제일 최신 코드들이 내 로컬에 잇고 그것에서 작업 그리고
- 중요 개념... 내 feature/noah14 (로컬)에 있는걸 내 로컬 마스터로 가져오진 않는다.
- 피쳐를 푸쉬해서 위로 올리고, 머지하고, pull origin master 해서 로컬 마스터로 가져온다. (한바퀴 도는,,)
- 많은 작업같지만, 변동사항만 트래킹해서 옮긴다.
스타벅스 crawling,, web,, scrape..
파리바게트 포기,,대신 커피빈!!
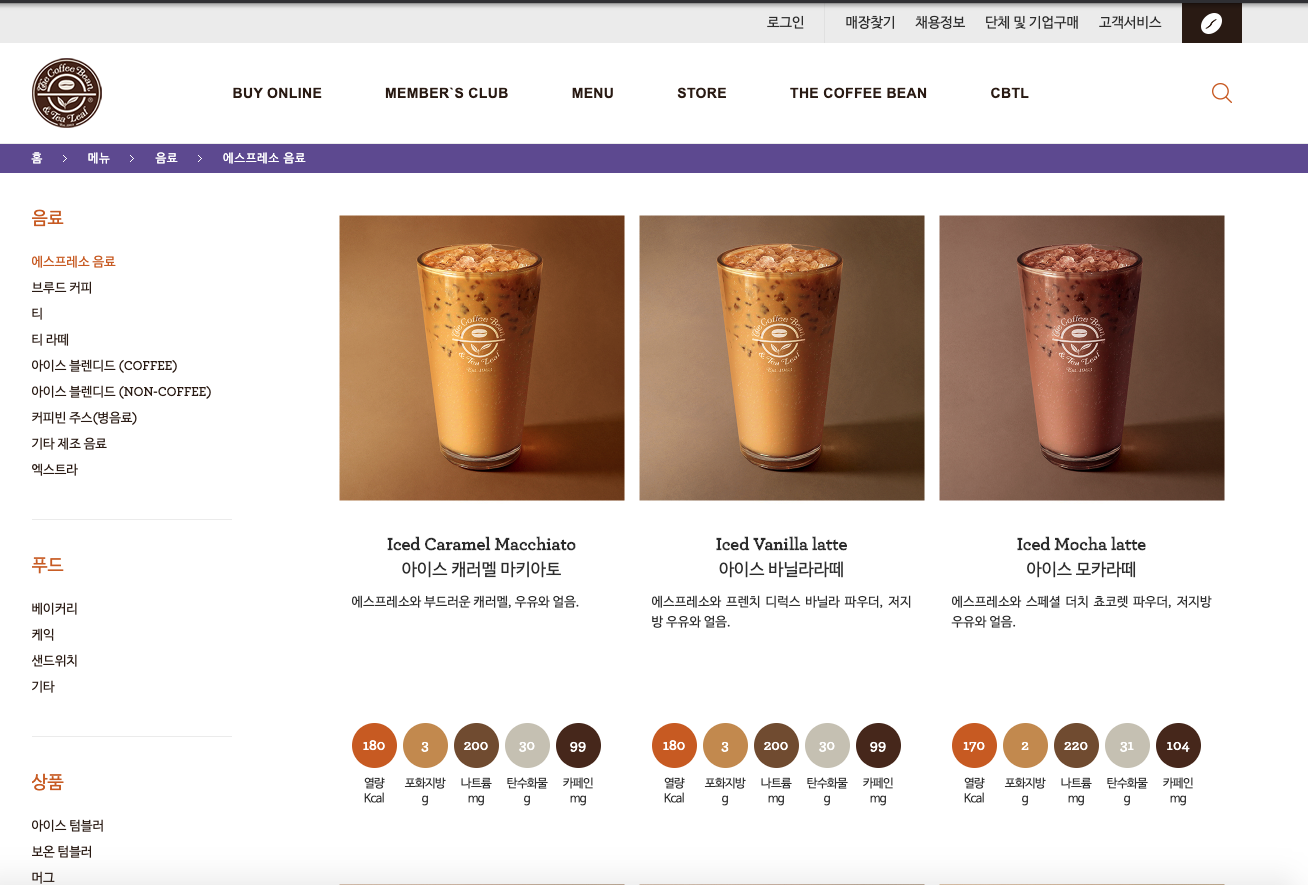
하고싶은거! 미션!
자동으로 저 페이지를 켜고
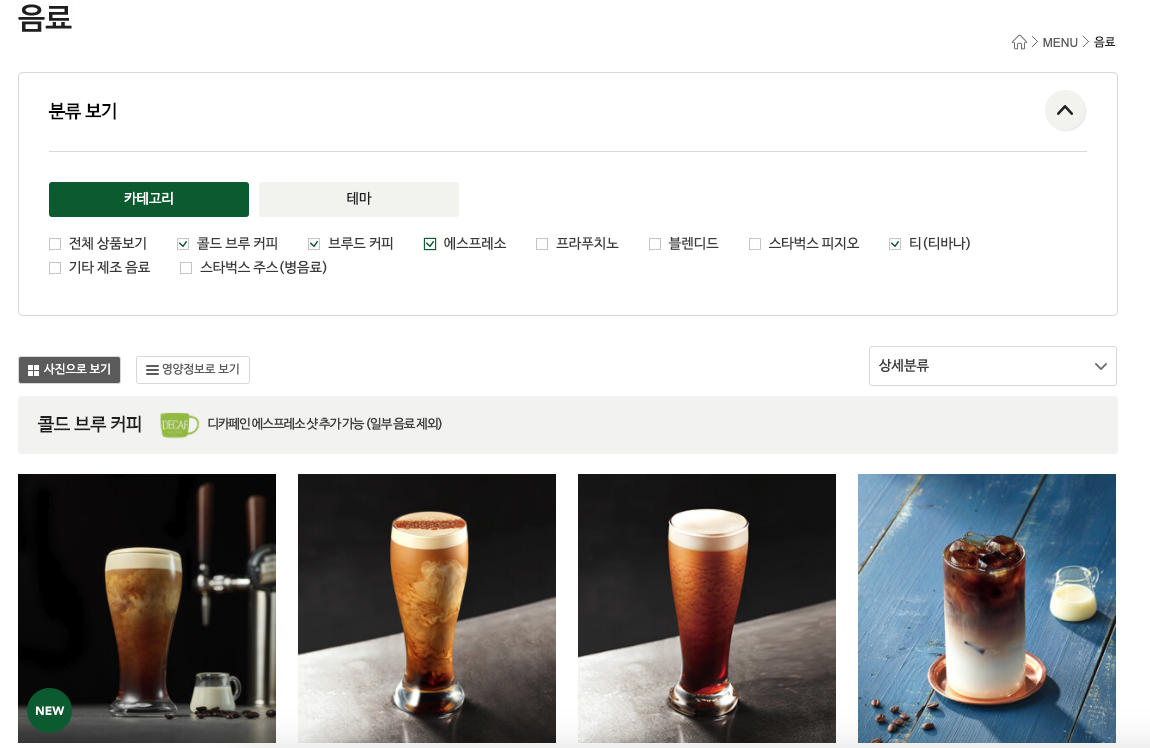
음료 페이지에서 왼쪽 bar의 카테고리를 하나하나 클릭하고 들어가서
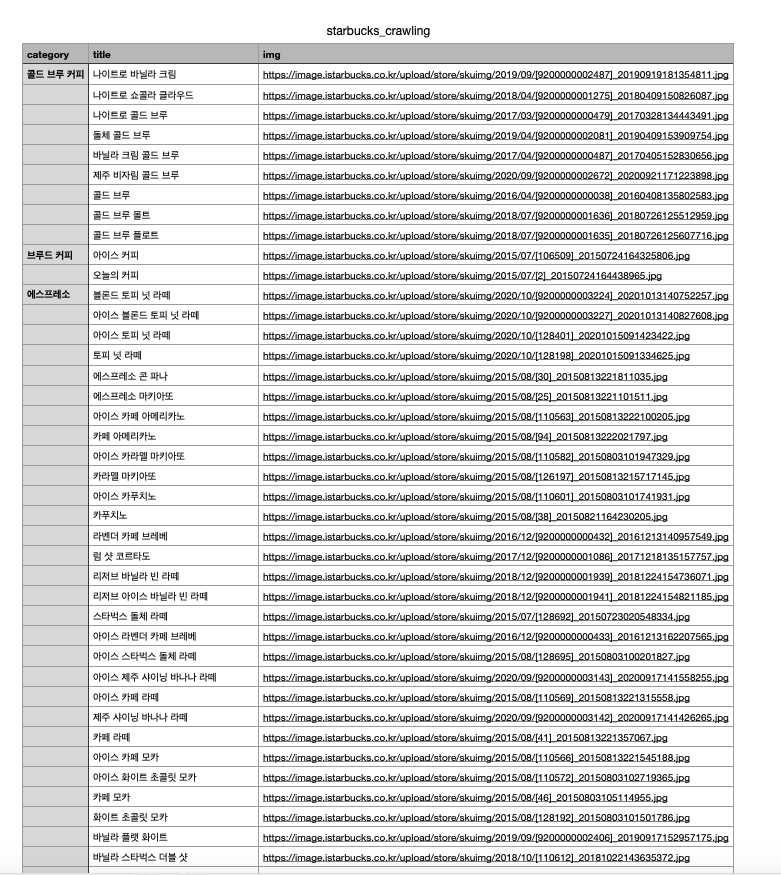
음료 카테고리 이름과, 사진 과 이름을 다 긁어와서 csv 파일로 정리 하는 것.

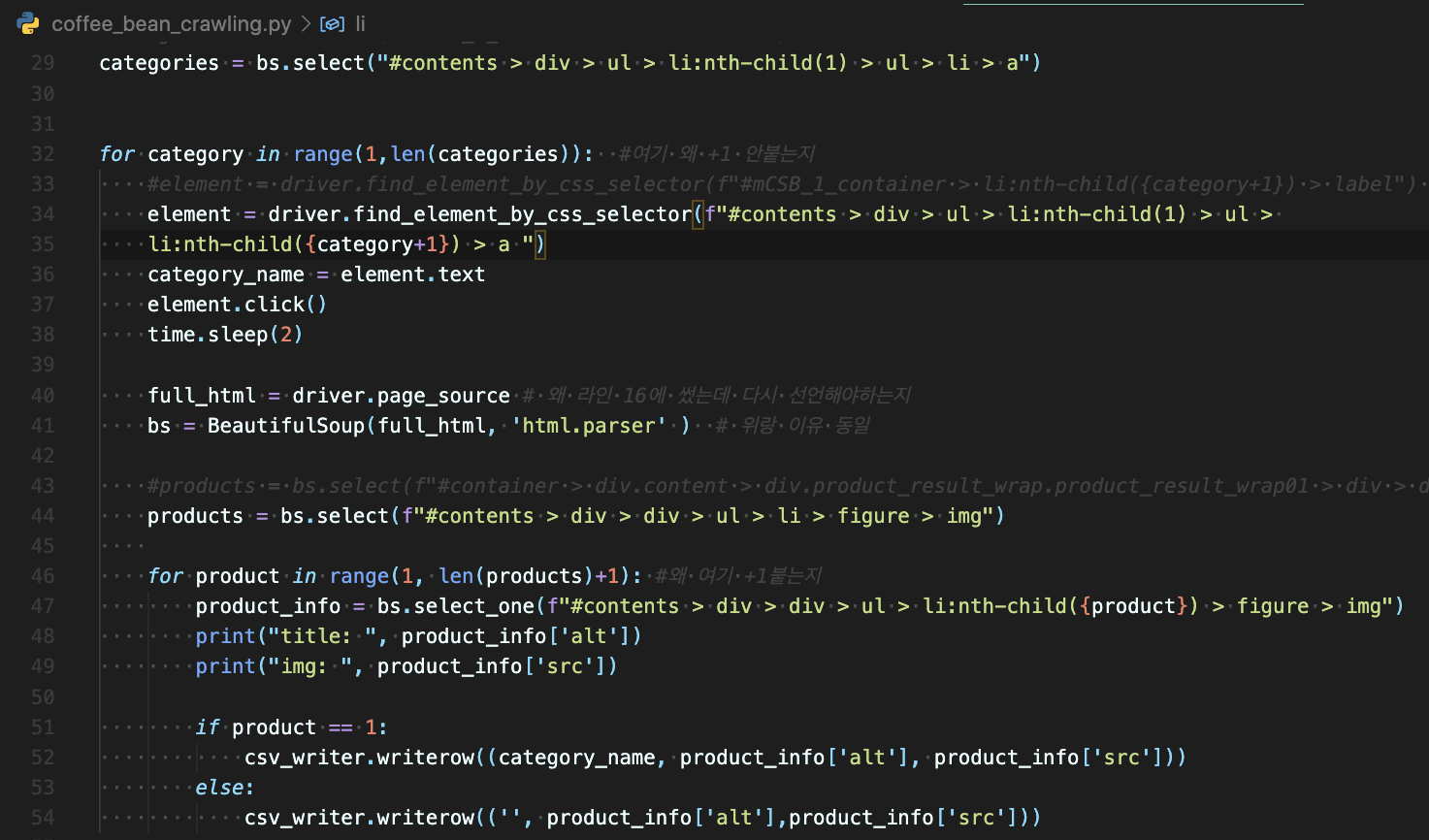
라인 1~6 필요한 class 와 method를 위해 import해야하는 것
라인 8~11은 나중에 하지만 앞쪽에 써줬다. 내가 긁어 오는 것을 csv파일로 만들고 거기에 넣어주는 것
라인 17 공부해야함 https://haloaround.tistory.com/215
- 웹 드라이버 절대경로로 호출
executable_path 를 직접 지정해준다. 웹 드라이버가 어느 경로에 위치하던 상관없이, 매 프로젝트에서 불러오면 된다.
※ 정규식 문자열 앞에 r을 붙여주면 백슬래시()를 이스케이프 시켜주는 Raw String 이라는 뜻.
즉 저 안에 운영체제에 따른 / 또는 이 문자열을 이스케이프 시켜서 경로를 있는 그대로 표시해 주는 역할을 한다.
출처: https://haloaround.tistory.com/215 [IT 공부중]
라인 18은 내가 긁어올 url주소
라인 19 저 주소로 가겠다
라인 22 페이지 소스(html) 다 가져오겠다
라인 24 bs4로 html코드를 분석한다.
라인 26 1초 쉬어주고
라인 29 카테고리s를 변수에 담아준다. 이때 한개를 css selector를 복사해와서, :nth-child(1) 이런걸 워드에 적어서 규칙성을 파악한다 그리고
:nth-child를 지운다 (그래야 전체가 나옴) 그리고
print(len(categories)를 해서 내가 원하는 카테고리 개수가 나오는지 확인!
라인 32 ~ 43
카테고리스 안에 카테고리가 1부터 9까지 돈다 (10이지만 9에서 stop해서,, range문법에 따라)
element라는 변수에 아까 nth-child 순서에 카테고리를 넣어주고,
저걸 element.click()을 이용해 클릭한다.
정리하자면 카테고리 1 눌러라, 그리고 카테고리 2 눌러라 ...
그리고 그 안에 for문이 하나 더 있다. (카테고리 1 눌렀을 때 무엇을 할건지)
위에 products를 선언했다. 이것도 copy css selector를 해서 경로를 찾아주고 nth-child를 없앤다 (복수여야함)
그리고 하나하나 잡아주고
라인 47, 48 처럼 하면 터미널에 정보가 나온다.
라인 50, 만약 프로덕트가 1 이라면 (첫번째라면) 카테고리 이름을, csv 파일에 컬럼을 넣어주고 써준다.
이렇게 if문을 안써주면 콜드브루가 카테고리인 음료에
콜드브루가 똑같이 적힐것이 아닌가
콜드브루는 한번만 써주어도 된다.
그렇게 돌리면
아 스타벅스의 경우는 마지막에 element.click 이 있다.
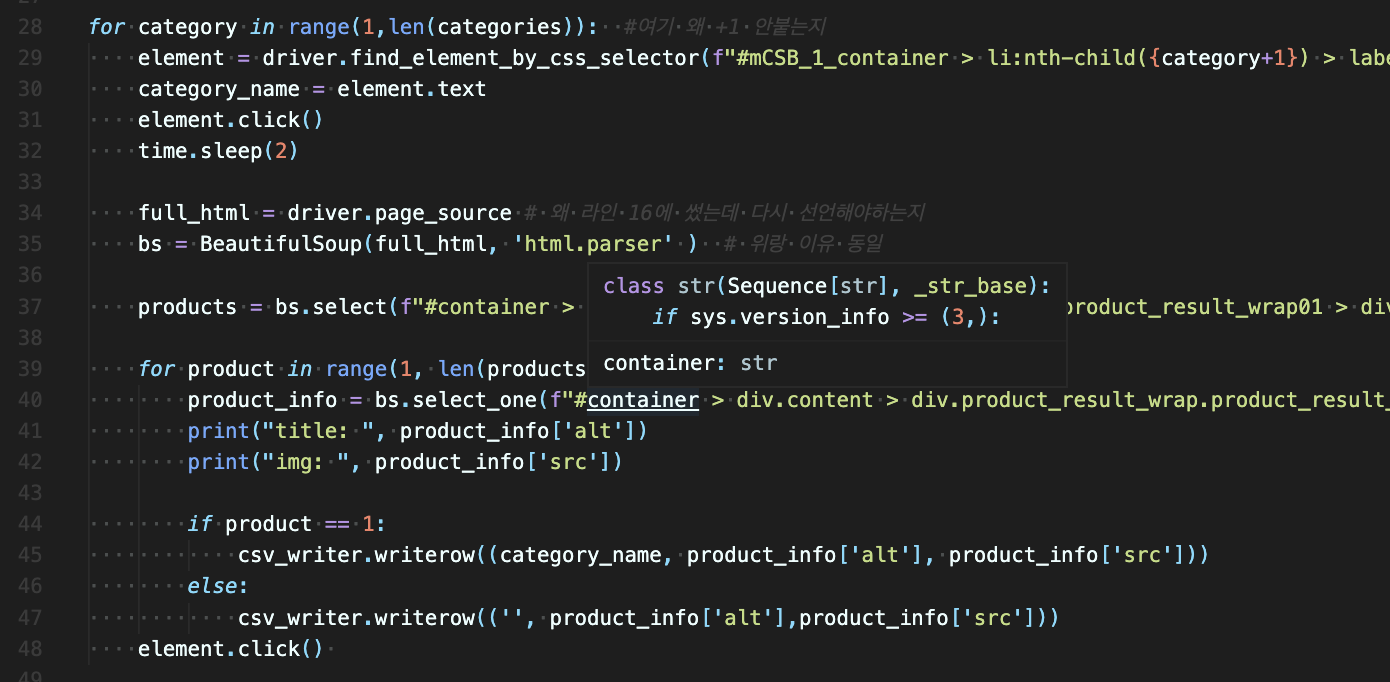
여기 클릭이 있는 이유는 내가 원하는것을 카테고리 1 에서 다 긁어오고 그다음에 한번더 클릭을 해서 checkbox를 풀어줘야 한다. 그렇지 않으면
아래 사진처럼 모든 것이 클릭되는 대 참사가 이러난다.
아래 사진은 csv를 했을때 사진이다.
[Django] westagram endpoint 구현
🚀 학습 목표
- 회원가입과 로그인 과정을 통하여 데이터베이스에 데이터를 저장하고, 불러올 수 있다.
- 포스팅 업로드와 게시물 보여주기, 댓글 달기와 댓글 보여주기를 통해 POST / GET 통신을 처리할 수 있다.
- 기본적인 git flow를 이해하고 github을 통한 코드 리뷰 방식을 이해하고 적극적으로 참여한다.
- 코딩 컨벤션을 지켜, 가독성 높고 협업에 도움이 되는 코드를 작성할 수 있다.
