
(이미지 출처: https://www.width.ai/post/gpt-3-course-info-extraction)
모든 Paper review는 제가 공부하고 남기는 기록입니다.
잘못된 내용이나 추가 의견이 있으시면 언제든 자유롭게 댓글 남겨주세요.Published: NeurIPS, 2022
Paper: https://arxiv.org/abs/2205.11916
0. Abstract
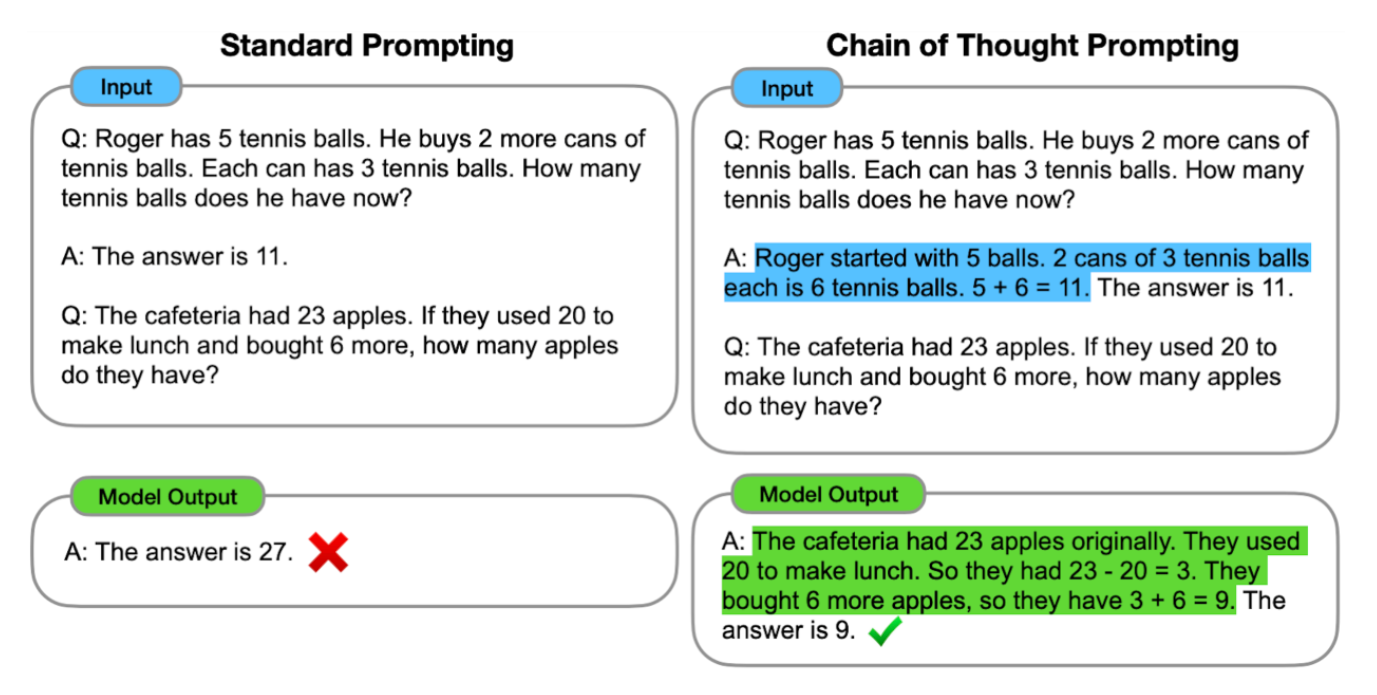
- 사전학습을 시킨 Large Language Model (LLM) 들은 특정 과제에 특화된 few-shot learning을 통해서 쓰이고 있습니다.
-
특히, Chain of Thought Prompting (
CoT) 기술은 arithmetic reasoning과 symbolic reasoning 양쪽 모두에서 SOTA를 달성한 바 있습니다.또한 CoT Prompting을 이용하면 이전까지 잘 해결하지 못했던 system-2 task, 그러니까 위와 같은 초등학교 수준의 계산 문제의 답을 추론하는 문제들도 해결할 수 있었습니다.
-
이는 대부분 few-shot learning의 성과로 여겨졌지만, 본 논문에서는 프롬프트에 "Let’s think step by step"이라는 문장을 추가하기만 해도 꽤 괜찮은 수준의 zero shot learning이 가능하다는 것을 발견했습니다.
여러 logical 문제들을 기준으로 평가 결과 기존의 제로샷 러닝보다 훨씬 나은 결과를 보였습니다. (MultiArith accuracy의 경우 17.8%에서 78.7%까지 상승)
1. Introduction
- 매번 모델을 특정 task에 특화시키는 대신, 약간의 예시를 주거나(few-shot), 예시를 주지 않아도 문제를 설명하고 답을 구하도록 지시를 주는(zero-shot) 행위를 prompting이라 합니다. LLM은 prompting을 통해 위에서 살펴본 것처럼 다양한 문제를 해결할 수 있었습니다.

-
직관적이고 단순한 system-1 문제들에서 few shot, 또는 zero-shot learning을 통해 매우 훌륭한 성능을 보여줬던 것과 달리, 100B 이상의 파라미터를 보유한 모델도 system-2 문제를 쉽게 해결하지 못했습니다.
-
이를 설명하기 위해 Chain of Thought 개념이 제시되었습니다. 질답을 포괄적으로 제시하는(a) 대신, 단계별로 과정을 나눠 제시하는(b) 기법입니다. CoT가 5400억개의 패러미터를 가진 PaLM 모델과 결합되었을 때, 압도적인 성능 향상을 보였습니다. (GSM8K 17.9% -> 58.1%)
-
본 논문에서는
Let's think step by step이라는 문장을 사용하면, 기존 방식(b)처럼 문제마다 설명을 따로 할 필요가 없다는 것을 발견했습니다. 또한 이 방법은 실험에 사용한 모든 문제에 대해 적용할 수 있었습니다.
2. Background
Large language models and prompting
-
language model은 기본적으로 텍스트의 확률분포에 대한 모델입니다.
LLM은 초대량의 데이터를 학습한 pre-trained 모델로, NLP 분야에서 대부분의 downstream task에 있어 과거의 fine-tuning 기법 대비 훌륭한 성능을 발휘했습니다.
이런 고성능은 문제에 대한 상세하고 구체적인 가이드라인을 제공하는 prompt 에서 나오는데, 구체적인 문제 풀이 과정의 예시를 제공하는 것을 few-shot prompt, 문제와 해답 템플릿만을 제공하는 것을 zero-shot prompt 라고 합니다.
Chain of thought prompting
-
Multi-step arithmetic 이나 logical reasoning 등의 문제는 LLM으로 잘 해결되지 않는 대표적인 것들이었습니다.
-
Chain of Thought, CoT는 few shot prompting의 일종으로, 한 개의 답을 단계별로 차근차근 나눠 예시를 제공하는 것입니다. 이 기법은 특히 PaLM처럼 초대형 언어 모델과 결합했을 때, 앞서 언급한 어려운 문제들에 대해 엄청난 성능 향상을 가져왔습니다.
3. Zero shot Chain of Thought
-
본 논문에서는
Zero-shot Chain of Thought기법을 제시합니다. 기존의 few shot prompting은 문제별로 구체적인 예시를 제공해야 하지만, Zero-shot CoT는 그럴 필요가 없습니다.zero-shot CoT 를 사용하면 한 개의 템플릿만으로 광범위하게 응용할 수 있습니다. zero-shot CoT로 모델의 단계적 추론을 이끌어낼 수 있습니다.
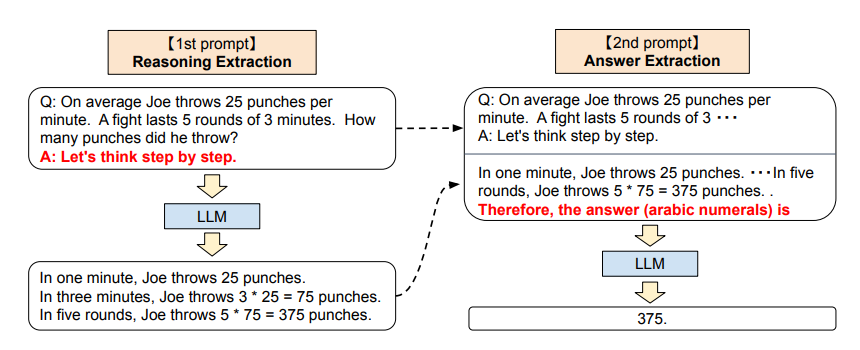
Two-stage prompting
-
Zero-shot CoT는 위 그림처럼 prompting을 두 번 사용한다는 점에서 조금 미묘한 부분이 있습니다.
이는 위 그림의 오른쪽에서 볼 수 있듯이 원하는 포맷으로 답을 추출하기 위해
The answer isprompting을 사용하기 때문입니다. CoT, 또는 standard few-shot learning는 개별 문제에 대한 구체적인 예시를 사용하기 때문에 답안 추출 단계가 필요없습니다. -
즉 few-shot learning은 엔지니어가 직접 문제별로 포맷팅을 해야 하는 반면, zero-shot CoT는 human-engineering이 필요없는 대신 inference 과정이 두 번 필요합니다.
1st prompt: reasoning extraction
- 먼저
Q:[X], A:[Z]템플릿을 사용하여 input questionx를 prompt로 변환합니다. Z 부분에는 문제마다 구체적인 예시를 넣을 수 있습니다. ('Let's think step by step' 이라던가) 해당 프롬프트를 언어 모델에 넣으면 결과 문장 z가 나오는데, 어느 디코딩 기법을 사용해도 상관없지만 본 논문에서는 단순성을 위해 Greedy decoding을 사용했습니다.
2nd prompt: answer extraction
-
두 번째 단계에서는 프롬프트화된 문장
x'와 언어 모델로 변환한 결과 문장 z를 함께 사용합니다. 구체적으로는[x'] [Z] [A]형태의 프롬프트로 병합합니다. A는 정답을 추출하기 위한 트리거 문장이고 Z는 첫 프롬프트에서 추출된 결과 문장입니다.이 단계에서 자가증강(self augmented)이 이뤄집니다. 동일한 언어모델에서 추출한 결과 문장을 뒷 프롬프트에서 사용하기 때문입니다. 본 논문에서는 문제에 따라 트리거 문장에 약간씩 변형을 주어 사용했습니다.
-
두 번째 프롬프트를 언어 모델에 집어넣으면 최종적으로 얻고자 하는 결과 문장
y를 얻을 수 있습니다.
4. Experiment
4-1. Tasks and datasets
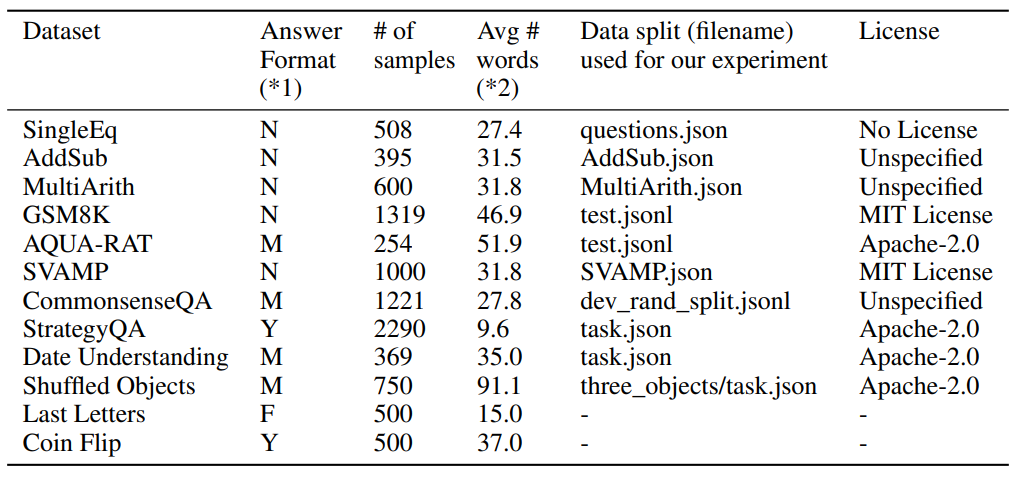
- 본 논문에서는 4개 카테고리로 분류할 수 있는 12개의 데이터셋을 사용했습니다.
4-2. Models
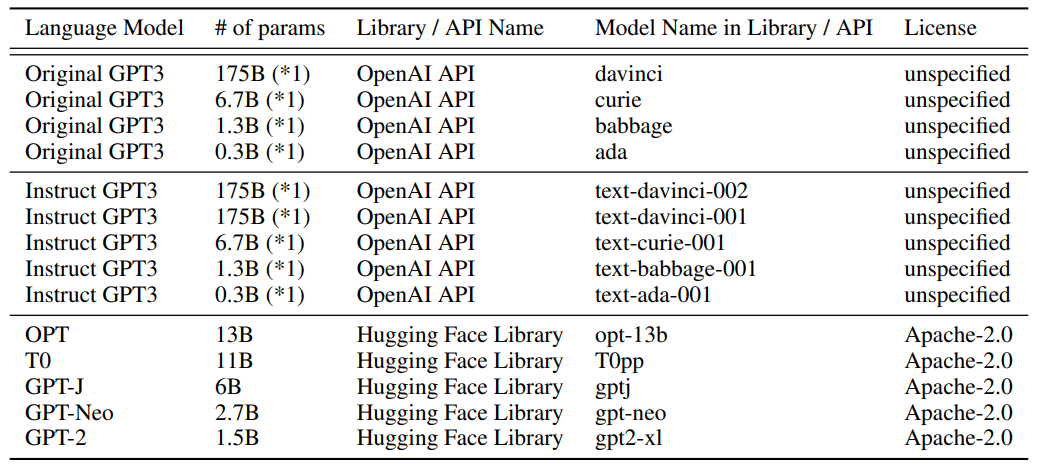
- 본 논문에서는 총 13개의 모델을 사용했고, 디폴트로
text-davinci-002를 선택했습니다.
4-3. Baselines


-
논문에서는 자체 CoT의 성능을 평가하기 위해 일반 zero shot prompting과 비교했습니다.
위가 일반 zero shot, 아래가 논문에서 제시한 zero shot CoT입니다.더 의미있는 평가를 위해 few shot prompting과도 비교했으며, 기존의 in-context example을 그대로 사용했습니다.
-
전 과정에서 greedy decoding을 채택했기 때문에 zero shot prompting에서는 재현성이 확보되지만, few shot prompting에서는 in-context example의 순서가 결과에 영향을 미칠 수 있습니다. 따라서 공정한 비교를 위해 모든 실험 과정에서 고정된 seed를 사용하여 한 번씩만 실험했습니다. (CoT prompting은 예시 순서가 바뀌어도 결과에 큰 변화가 없습니다.)
4-4. Answer cleansing

- 최종적으로 답안 포맷에 맞는 내용만 추출합니다. 예를 들어서
375 or 376이라는 답안을 생성하면 먼저 제시한375를 최종 답안으로 채택하는 식입니다.
4-5. Results
Zero-shot-CoT vs. Zero-shot
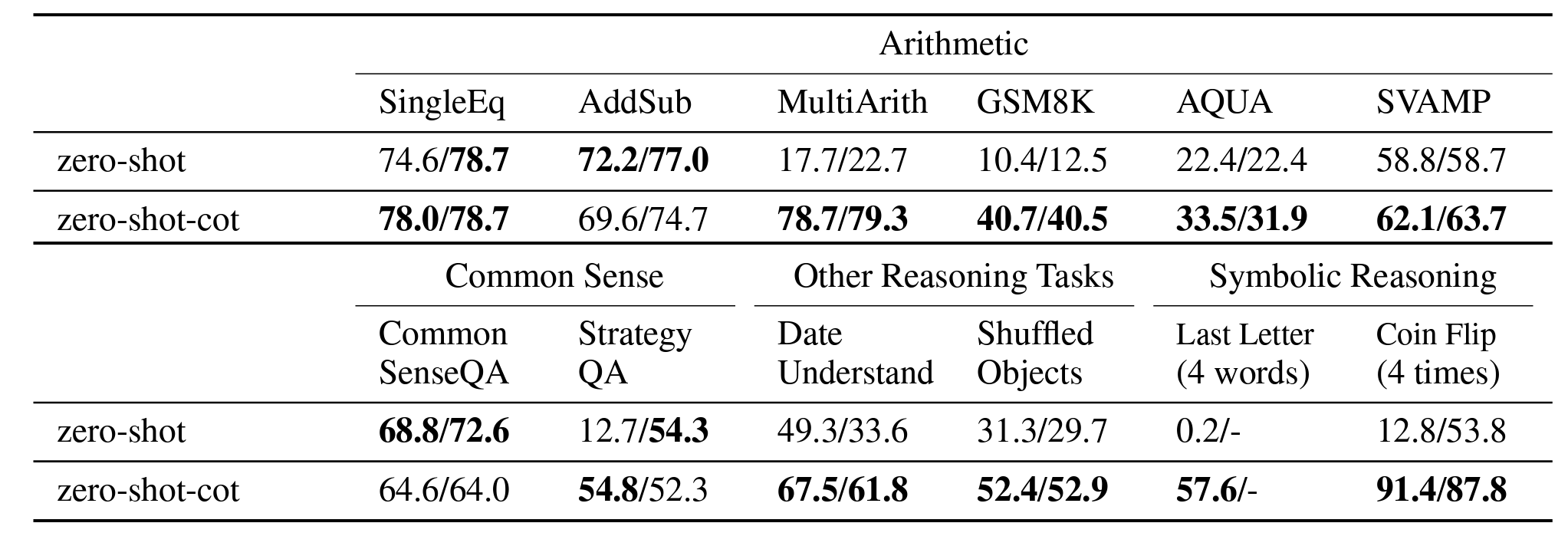
-
위 표를 보면 논문에서 제시한 zero shot CoT 기법을 사용한 결과, 6개 중 4개의 arithmetic tasks를 포함한 나머지 문제 전부에서 상당한 성능 향상이 이루어진 것을 확인할 수 있습니다.
SingleEq나AddSub등의 다단계 추론이 필요하지 않은 문제에서는 기존의 zero shot 학습과 별 차이 없는 결과를 내고 있습니다.(왼쪽 값은 문제마다 튜닝된 answer prompting 결과이고, 오른쪽 값은
the answer isprompting 결과입니다. 자세한 템플릿은 위쪽 Baselines을 참고)
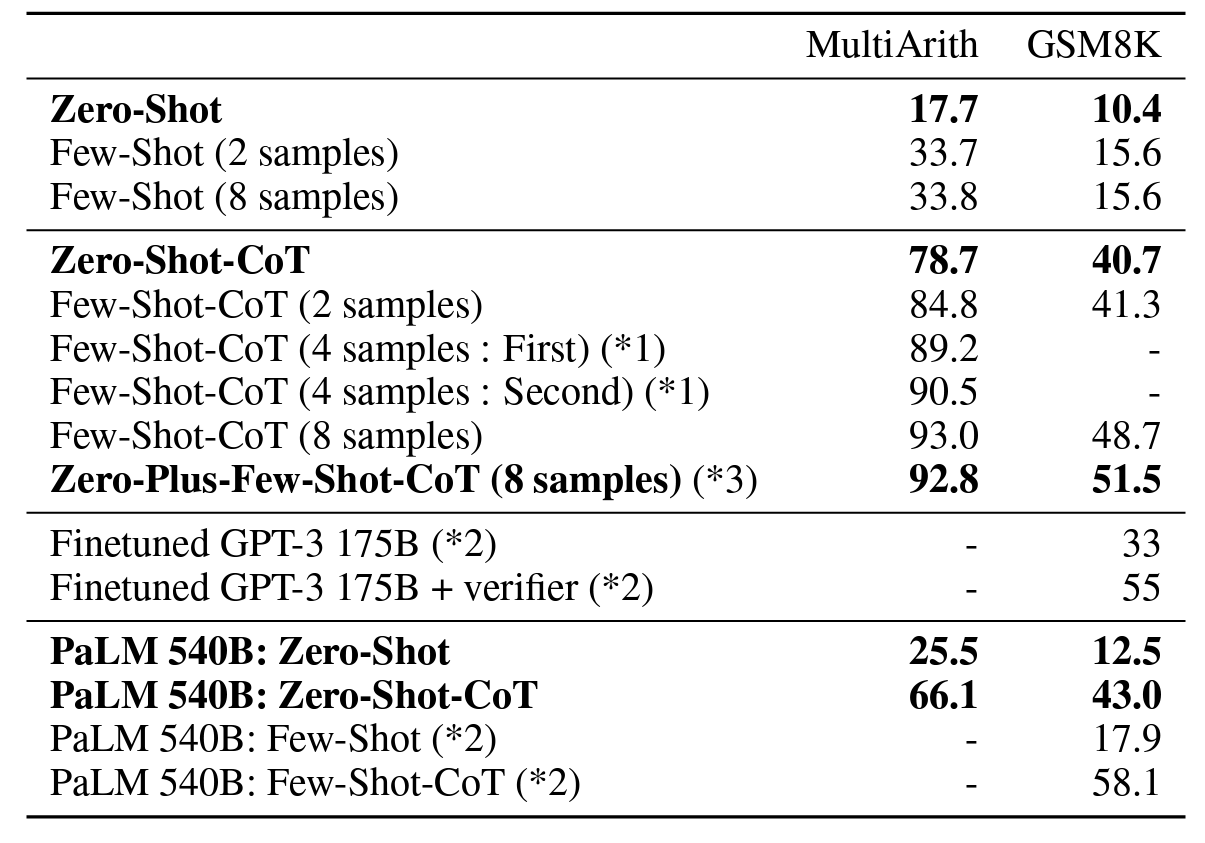
-
위 표는
MultiArith와GSM8K두 태스크를 비교한 것입니다.샘플의 개수에 따라 결과가 변하는 것을 볼 수 있습니다. 논문에서는 에
Let's think step by stepprompting을 사용하였습니다. -
CommonSense의 경우에는 성능의 개선이 이뤄지지 않았습니다. Lambda(135B) + few shot learning을 사용한 선행 연구에서도 해당 태스크에 대한 성능 개선이 이뤄지지 않았지만, PaLM(540B)을 사용하여StrategyQA태스크를 수행했을 경우에는 성능이 높아지는 것을 확인한 바 있습니다.

-
zero-shot CoT의 놀라운 점은 추론 과정이 신기할 정도로 사람과 비슷하다는 점입니다.
-
위 표를 보면 생각보다 논리적이거나 (child's room is likely to be in a house), 사람이 할 법한 실수 (그럴싸한 여러 개의 답변을 동시에 채택)를 하는 경우가 포착되었습니다.
-
이는 zero shot CoT가 기존 방식 대비 더 상식적이고 그럴싸한 추론을 할 수 있다는 것을 의미합니다. 문제 안에 관련 내용이 직접적으로 포함돼 있지 않더라도 말이죠.
Comparison with other baselines
-
위 표에서 zero shot과 zero shot CoT 방식의 차이가 극명하게 드러나는 것을 확인했습니다. 이는 해당 문제가 다단계 추론 과정 없이는 해결하기 힘들다는 뜻입니다.
-
zero shot CoT는 주로 GPT-3(175B), PaLM(540B)에서 성능 개선이 확인되었는데, few shot CoT에 비해서는 약간 낮은 성능을 보였습니다. 하지만 문제당 샘플 8개씩 학습한 일반 few shot prompting에 비해서는 훨씬 압도적인 성능을 보이고 있습니다.
Error Analysis
-
CommonSense 추론 과제의 일부 error case를 보면 zero shot CoT가 유연하고 논리적이지만 틀린 추론을 내놓는 경우가 있습니다. 또한 명확하게 답을 하나로 내리기 어려운 경우, 여러 선택지를 최종 답안으로 모두 내놓는 경우도 있었습니다.
-
MultiArith 등의 수학적 추론 문제에서는 few shot CoT와 zero shot CoT의 오답 유형에 확연한 차이가 있었습니다. zero shot CoT는 옳은 추론 결과를 도출하고 나서도 불필요한 추론을 추가하다가 잘못된 결과를 내는 경우가 있었고, 또한 종종 추론을 진행하지 않고 입력된 문장을 되새김질하기만 하는 모습도 확인되었습니다. 반면 few shot CoT는 3중 연산이 포함된 문제에서 Chain of thought을 전개하는데 실패하는 경우가 있었습니다. (e.g. (3+2)*4)
상식적 추론의 목적을 생각하면 이게 더 합리적인 판단일 수도 있습니다.
Does model size matter for zero-shot reasoning?
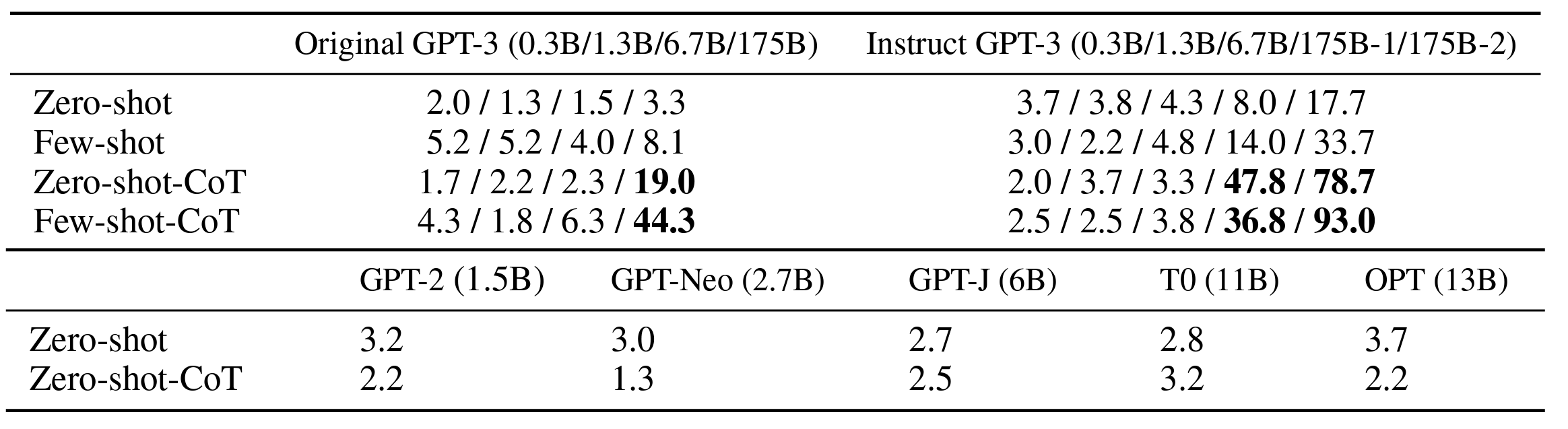
-
위 표는 언어 모델 크기에 따른 MultiArith 성능을 나타낸 것입니다.
CoT 추론 없이 단순히 모델의 크기를 늘리는 것만으로는 성능의 향상이 거의 없는 것을 볼 수 있습니다. 반대로 CoT 추론을 사용할 경우 모델의 크기에 따라 급격하게 성능이 증가합니다.
How does prompt selection affect Zero-shot-CoT?

-
위 표는 다양한 prompt를 시도한 결과입니다.
일반적으로 prompt를 CoT 추론을 강화하는 방향으로 작성할수록 결과가 향상됩니다. 문장에 따라 정확도가 크게 바뀌는데,
Let's think step by step이 가장 좋은 결과를 내는 것을 확인할 수 있습니다.

- 흥미로운 점은 prompt에 따라 결과 뿐 아니라 추론 과정도 상당히 바뀐다는 것입니다.
더 구체적으로 prompt를 작성한다는 의미입니다.
How does prompt selection affect Few-shot-CoT?

-
서로 다른 데이터셋(①
CommonSense - AQUA-RAT, ②CommonSense - MultiArith) 에서 추출한 예시를 사용한 few shot CoT의 성능을 비교한 표입니다. -
서로 다른 범주의 예시를 prompt에 사용하되 답안의 포맷을 고정시켜주면 기존 zero shot 대비 성능을 꽤 많이 향상시킬 수 있습니다. 반대로 답안 포맷을 하나로 고정하지 않을 경우 성능이 상대적으로 덜 증가합니다.
물론 (포맷 고정 여부에 상관없이) 여러 종류의 샘플을 사용하더라도 zero shot CoT보다 성능은 떨어지며, 이는 few shot CoT에서 문제에 최적화된 샘플 엔지니어링이 필수적이라는 뜻으로 해석할 수 있습니다.
5. Discussion and Related Work
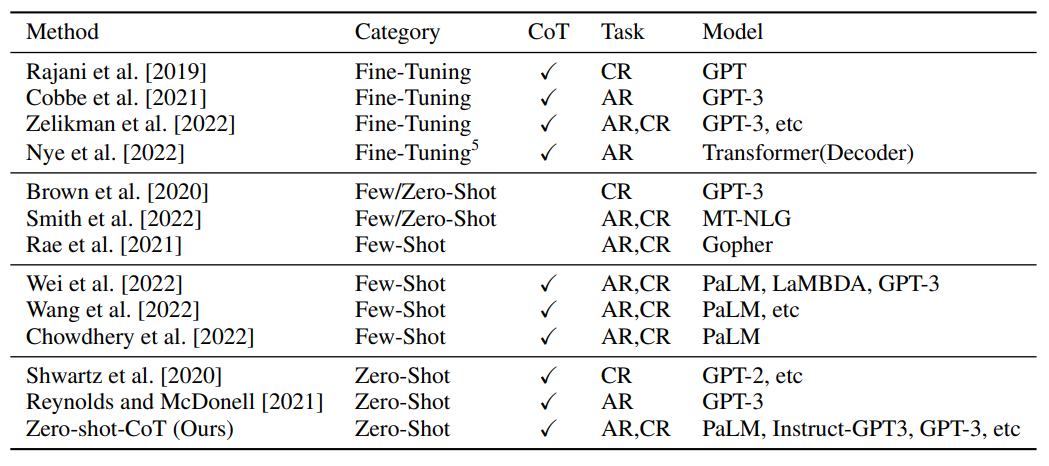
-
위 표는 2022년 5월 기준으로 (LLM을 활용한) 수리/상식 추론 연구 동향을 나타낸 것입니다.
대부분의 연구가 CoT 기법을 사용하고 있으며, AR은 수리 추론(Arithmetic Reasoning), CR은 상식적 추론(Common sense Reasoning)을 의미합니다.
Reasoning Ability of LLMs
-
몇몇 연구에 따르면 사전 학습 모델은 일반적으로 추론 문제를 잘 풀지 못하지만, fine tuning이나 few shot learning, 단계적 추론(step by step)을 통해서 상당한 수준의 성능 향상을 시킬 수 있습니다.
-
하지만 논문에서는 zero shot prompting에 집중하여 단일 trigger prompt(
Let's think step by step)만으로 LLM의 zero shot 추론 성능을 상당량 끌어올리는데 성공했습니다. 또한 모델의 규모가 커질수록 성능도 함께 상승했습니다. 또한 zero shot CoT는 결과적으로 오답이더라도 논리적이고 납득할 수 있는(understandable) 답안을 생성합니다. -
본 논문의 의의는 주로 few shot learning과 주어진 과제에 특화된 맥락 학습(in-context learning)을 강조한 선행 연구에 비해 사전 학습한 LLM에서 꽤 괜찮은 수준의 zero shot 추론이 가능하다는 것을 밝힌 데 있습니다.
-
zero shot CoT 기법은 추가적인 비용이 드는 fine tuning이나 사람이 직접 문제마다 맞춤형 sample을 제시할 필요가 없고, 모든 형태의 사전학습 LLM에 사용할 수 있습니다.
Zero-shot Abilities of LLMs
-
이미 해당 논문에서 독해, 번역, 요약 등의 system-1 과제에 대해 LLM의 zero shot 성능이 이미 완벽한 수준임이 증명된 바 있습니다. 후속 연구들에서는 fine tuning, instruction tuning을 통해 성능을 끌어올릴 수 있다는 것도 확인되었습니다.
-
본 논문에서는 zero shot CoT를 통해서 기존에 어려움을 겪고 있던 system-2 과제를 해결하는 데 집중하였으며, 기존의 instruction tuning과는 다른 기법입니다. 실제로 순정 GPT-3와 instruction GPT-3 양쪽 모두에서 성능의 향상이 이뤄졌습니다.
From Narrow(task-specific) to Broad(multi-task) Prompting
-
대부분의 prompt는 각 과제에 최적화되어 있습니다. zero shot prompt도 마찬가지입니다. 그런데 이런 기법들은 엄밀히 말해 주어진 과제에만 집중하는 '지역적 최적화'일 뿐입니다.
앞서 살펴봤다시피 zero shot CoT는 다양한 범주의 문제들에 적용할 수 있습니다. 특히 논리적 추론같은 system-2 문제를 비교적 간단히 해결할 수 있을 뿐 아니라 LLM을 활용한 다른 범용적인 문제해결법을 찾는 실마리가 될 수 있습니다.
Limitation and Social Impact
-
LLM은 웹을 포함해 아주 다양한 말뭉치를 학습한 모델입니다. 그래서 수집한 데이터에 포함된 bias 등 자체적인 문제점을 가지고 있습니다.
-
Prompting은 LLM로 추출한 패턴을 여러 과제에 적용하기 위한 방법론이기 때문에 위의 단점을 공유합니다. 따라서 zero shot CoT는 사전학습 LLM의 복잡한 내부 추론 방식을 분석하기 위한 조금 더 '직접적인' 방법이 될 수 있습니다. 또한 LLM의 편향에 대한 조금 더 비편향적인 분석 방법론이 될 수도 있죠.
zero shot CoT는 별도의 instruction이 없으므로 few shot 과정에서 유입될 수 있는 bias 등의 교란요인을 제거하는 것과 같습니다.
과 동일
6. Conclusion
-
본 논문에서 제시한 zero shot CoT는 단일 zero shot prompt를 활용하여 LLM이 다양한 추론 문제를 단계적으로 해결할 수 있도록 합니다.
기존의 few shot 방식은 직접 fine tuning을 하거나 문제마다 최적화된 few shot example을 제시해야 했지만, zero shot CoT는 이러한 자원을 절약할 수 있을 뿐 아니라 system-2 추론 문제들을 해결하기 위한 zero shot 방법론의 베이스라인이 될 수 있습니다.
7. Personal Review
후기
얼마 전 모두의연구소를 통해 네이버 클로바에서 나온 논문 세미나에 참석할 기회가 있었습니다. 그 세미나를 계기로 LLM에 대한 관심이 생겼는데, 마침 이런 흥미로운 논문을 발견하게 되어서 첫 논문 리뷰를 상당히 재미있게 진행한 것 같습니다.
