
Published in KDD 2019
[요약]
-
Vision 분야에서 사용하는 Spectral Residual 방법론을 도입하여 이상치와 정상 데이터를 구분하고, 이를 CNN 기반 모델로 탐지하는 SRCNN 방법론을 제안했습니다. 이는 기존 대비 20% 이상의 매우 큰 성능 향상을 보였습니다.
-
SRCNN은 다양한 형태의 시계열 데이터에 쉽게 적용할 수 있습니다. 또한 연산 속도가 빠르고 가벼워서 온라인 서비스에 쉽게 적용할 수 있습니다.
[서론]
Abstract
어느 정도 규모가 있는 기업들은 제공하는 서비스/제품에 대해 다양한 모니터링이 필요합니다. MS의 경우 시계열 기반 이상탐지 모델을 사용합니다. 논문에서 설명하는 파이프라인에는 크게 3가지 모듈이 있습니다.
1) 데이터 수집 & 입력
2) 실험용 플랫폼
3) 온라인 처리 모듈
본 논문에서 제안하는 이상탐지 방법은 Spectral Residual Convolution Neural Network (SRCNN)입니다. 2014년도 논문인 Super Resolution CNN (SRCNN)하고는 다른 방법론입니다.
1. Introduction
이상탐지(anomaly detection)라는 말 때문에 error를 잡는 것만 생각하기 쉽지만, 이상탐지 모델은 error 뿐만 아니라 rare한 event나 item을 찾아내는 데도 사용합니다.
MS의 경우 Bing, Office, Azure에서 발생하는 수백만 개의 metric을 모니터링하고 처리하기 위해 자체적인 이상탐지 모델을 개발했습니다. 그런데 이러한 Industrial model을 개발하고 사용하기 위해서는 몇 가지 문제가 있습니다.
1) Lack of Labels
기본적으로 한 개의 비즈니스 시나리오에 맞춘 이상탐지 모델을 사용하려면 수백만 개의 시계열 데이터를 동시에 처리해야 합니다. 개발자 입장에서 이러한 데이터에 수동으로 라벨을 붙이는 것은 절대 쉬운 일이 아닙니다. 게다가 시계열 데이터는 끊임없이 변하기 때문에 처음 보는 데이터에 대해서도 이상 여부를 알 수 있어야 합니다. 따라서 지도학습 방법은 적합하지 않습니다.
2) Generalization
회사는 보통 여러 가지 제품을 제공합니다. 따라서 들어오는 데이터 또한 여러 종류가 있습니다. 예를 들어 다음과 같은 여러 패턴이 존재합니다.
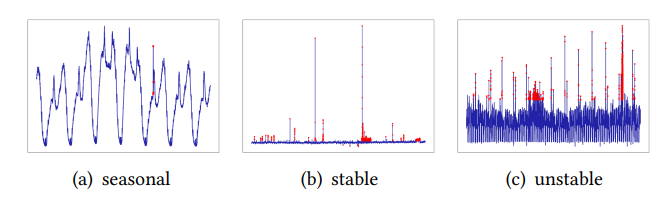
문제는 다양한 패턴의 데이터를 처리할 수 있는 generalized model이 존재하지 않는다는 것입니다. 일부에서 좋은 성능을 내는 모델은 다른 패턴에서 급격한 성능 저하가 일어나기 일쑤죠.
3) Efficiency
비즈니스에서는 시간이 생명입니다. 수백만 개 이상의 데이터를 real time 안에 처리해야 하죠. 높은 정확도를 보이는 모델이라도 시간 복잡도가 크다면 온라인 서빙용으로는 적합하지 않습니다.
이러한 문제들에 대해, 논문에서는 Spectral Residual Approach (2007)를 기반으로 새로운 방법론을 제안합니다.
Spectral Residual은 원래 vision쪽에서 detection task를 위해 제안된 개념입니다.
이미지 스펙트럼에 로그를 취한 값이 위 그림처럼 공통적인 경향을 나타낸다는 점에서 착안하여, 이미지에서 예측가능한 주파수 정보를 제거한 나머지 주파수 정보를 가지고 푸리에 역변환을 통해 Visual Saliency Map을 얻는 방법입니다.
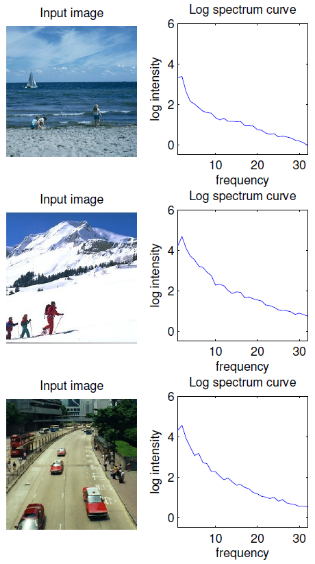
시계열 데이터 기반 anomaly detection은 visual saliency detection과 비슷한 task라고 할 수 있습니다. 왜냐하면 일반적으로 시계열 데이터에서 나타나는 anomaly part는 시각적으로 가장 눈에 띄는 부분이기 때문입니다.
논문에서는 SR을 거친 output에 바로 CNN을 취해줌으로써 unsupervised, supervised 양쪽 측면에서 모두 좋은 성능을 얻고자 했습니다. CNN의 효율적인 학습을 위해서는 label 정보가 필요한데, SR을 통해 생성한 데이터에서는 anomaly part가 두드러지기 때문에 정상 데이터와 비교하여 CNN을 효율적으로 학습시킬 수 있습니다. 또한 SR은 unsupervised learning을 통해 데이터를 가공하므로, 전체 학습 프로세스에 사람이 개입할 필요도 없습니다. 즉, labeling 작업을 자동화한 것과 같습니다.
2. System Overview
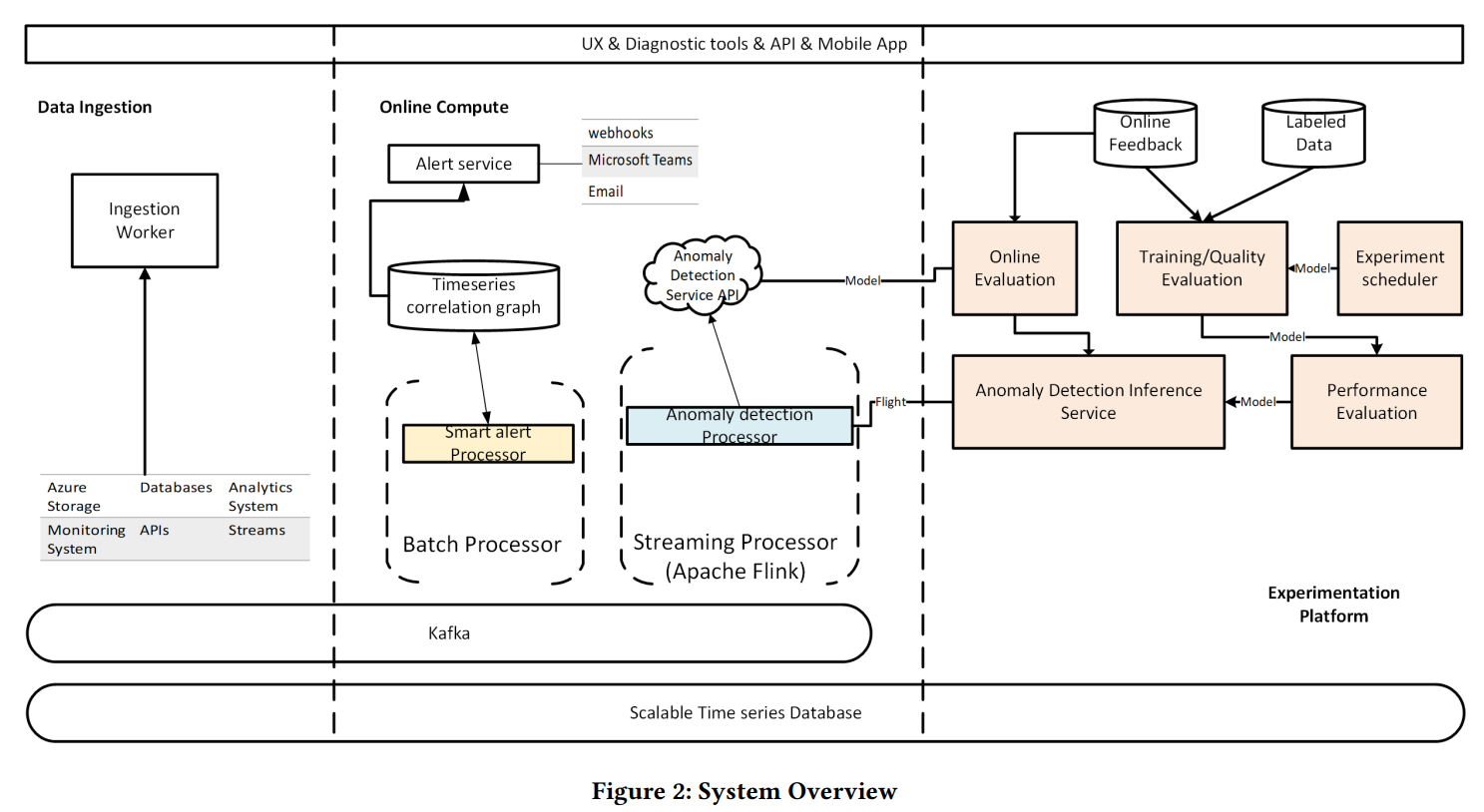
논문에서는 본격적인 methodology를 설명하기 전에 pipeline을 먼저 소개합니다. 앞서 언급한 것처럼 3개의 모듈로 구분할 수 있습니다.
2.1 Data Integration
다양한 서비스에서 생성되는 유저 데이터들을 모아서 처리하는 일을 합니다. Ingestion worker라는 모듈을 통해 얼마나 자주(minute/hour/day) 데이터를 업데이트할지를 결정합니다. 일반적으로 초당 약 10,000개 ~ 100,000개의 데이터 포인트를 처리합니다. infulxDB와 Kafka를 사용합니다.
2.2 Online Compute
각각의 데이터를 처리하는 부분입니다. 이상치 탐지를 위한 sliding window가 필요한데, 이를 위해 Kafka와 연동하기 쉬운 Flink를 사용합니다. Anomaly detector 모듈이 각 시계열 데이터마다 이상치를 탐지하고, Smart alert processor 유닛이 서로 다른 시계열에서 발생한 각각의 이상치를 서로 연결해서 report를 생성합니다.
2.3 Experimentation Platform
이상치 탐지 모델의 퍼포먼스를 평가하기 위한 가상환경입니다. 비즈니스에 바로 적용하기 전에 실험해보는 공간이라고 생각하면 됩니다. Azure Machine Learning 서비스 위에 구현돼 있습니다.
human editor들이 진짜 anomaly point와 가짜 anomaly point를 라벨링한 데이터를 가지고 모델을 평가하며, 모델이 충분히 쓸만하다고 판단되면 K8s 호스팅으로 옮겨 실제 서빙을 시작합니다.
3. Applications
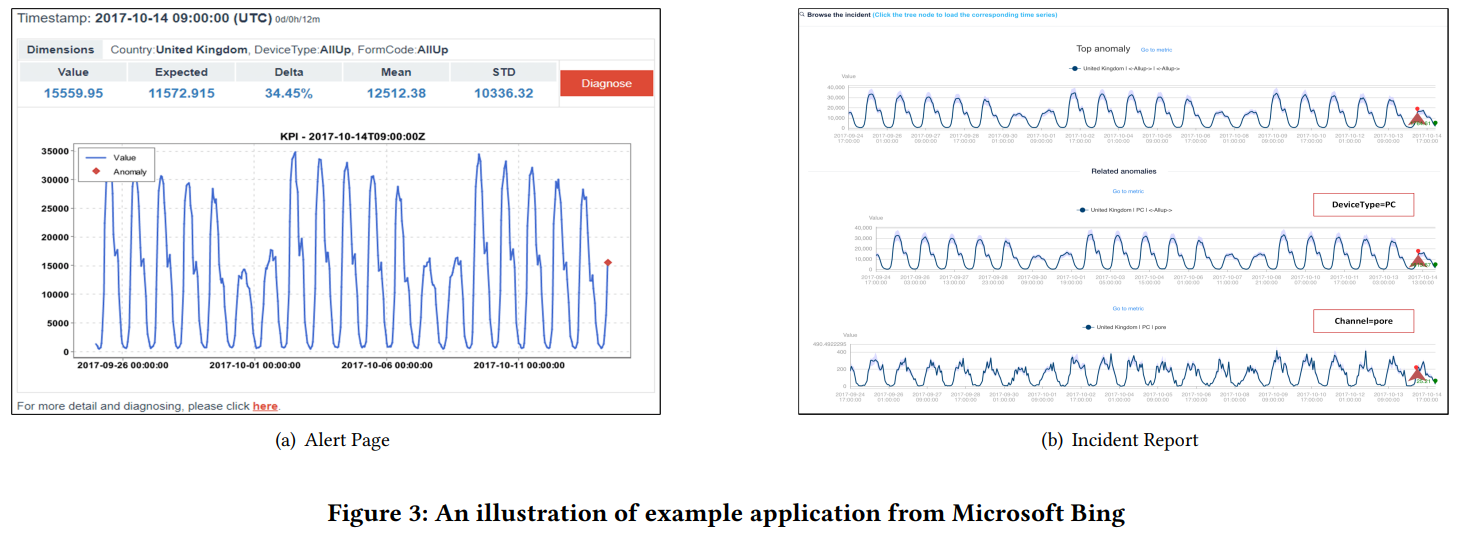
실제 적용 케이스를 보여줍니다. (a)는 email alert, (b)는 incident report입니다.
[본론]
4. Methodology
이제부터가 진짜 본론입니다. 논문에서는 시계열 이상탐지라는 task를 다음과 같이 정의합니다.

즉, 주어진 데이터 포인트 에 대해 anomaly 여부를 나타내는 를 얻는 것이 목적입니다. 기존의 SR 관련 연구에서는 대량의 labeled data를 가지고 CNN을 활용하는 경우가 많았는데, 앞서 언급한 것과 같이 워낙 대량의 raw data를 다뤄야 하다 보니 일일이 labeling 작업을 하기가 어렵습니다.
4.1 SR (Spectral Residual)
Spectral Residual 기법은 크게 3가지 단계로 구분됩니다.
1) log amplitude spectrum을 얻기 위한 푸리에 변환
2) spectral residual 계산
3) 푸리에 역변환을 통한 시퀀스 복원
오토인코더 구조와 비슷합니다. 수학적으로 정의하면 다음과 같습니다.
주어진 시퀀스 벡터 에 대해,
: amplitude spectrum of
: phase spectrum of
: log representation of
: average spectrum of
: Spectral Residual
: saliency map
는 각각 푸리에 변환과 푸리에 역변환이며, 는 다음과 같은 크기의 정사각행렬입니다.
즉, 시퀀스 벡터에 FT를 적용하여 얻은 amplitude spectrum에 log를 씌워서 spectral map을 얻습니다. 이렇게 얻은 원본 spectral map에서 convolution filter를 적용해서 얻은 공통적인 데이터를 제거하면 spectral residual 정보만 남게 됩니다. 이후 log scaling을 풀어주고, phase spectrum을 더해서 푸리에 역변환을 수행하면 시퀀스를 복원할 수 있는데 이렇게 복원된 시퀀스 를 salience map이라고 합니다.
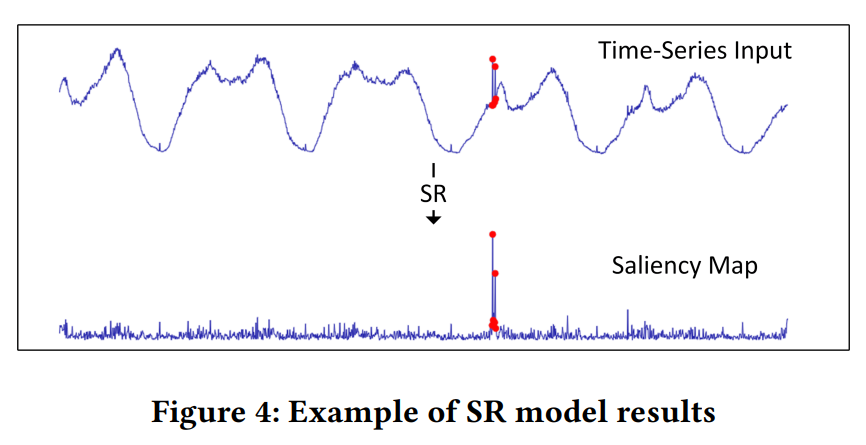
위 그림을 보면 원래 시계열 데이터가 어떤 형태의 salience map으로 변환되는지 볼 수 있습니다. 또한 anomaly point가 원본 데이터보다 salience map에서 더욱 두드러지게 나타나는 것도 알 수 있습니다.
그런데 salience map을 보면 두드러지게 튀어나온 부분 외에도 여러 spike가 존재합니다. 그래서 논문에서는 threshold를 이용하여 anomaly 여부를 판정합니다. 즉, output sequnce 는 다음과 같습니다.
window는 데이터를 훑으면서 FFT를 수행합니다. 즉 anomaly detection은 선형적으로 처리됩니다. 그런데 SR은 target point가 이 window 가운데에 있을 때 더 잘 작동하는 경향이 있습니다. 논문에서는 이 점을 이용하여 이후 몇 개의 estimated points를 input sequence에 추가하여 SR 모델에 투입합니다. 그렇다면 이러한 estimated points는 어떻게 찾을까요?
위 식에서 은 와 사이 직선의 그래디언트입니다. 는 개의 선행 데이터 포인트들의 평균 그래디언트를 나타냅니다. (논문에서는 5개의 pre data points를 고려했습니다.)
위 그림을 보면 조금 더 이해하기 쉽습니다. 선행 데이터 포인트들과 을 이은 직선의 평균 그래디언트가 크다면, 은 anomaly point일 가능성이 높습니다.
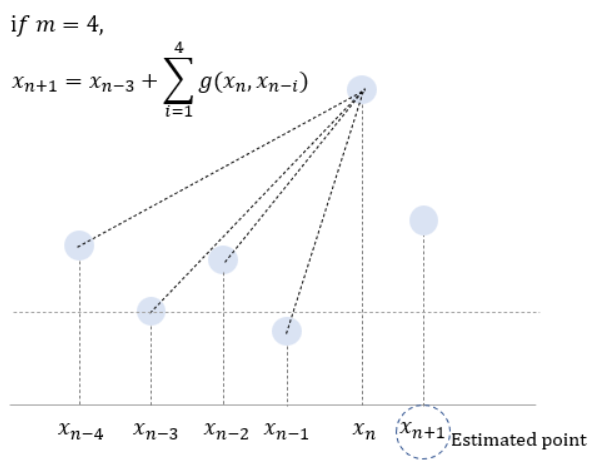
실험 결과 첫 번째 포인트가 매우 큰 영향력을 발휘하는 것을 발견했는데, 이에 따라 개의 포인트를 복사해서 시퀀스 끝에 붙이는 식으로 처리했다고 합니다.
결과적으로 SR 알고리즘은 다음과 같은 3개의 hyperparameter를 갖습니다.
- window size
- estimated point #
- anomaly detection threshold
파라미터별로 정해진 초기값은 없고, empirical하게 결정하면 됩니다.
4.2 SR-CNN
앞서 다룬 SR method를 활용해서 다음과 같이 anomaly detection을 할 수 있습니다.
그런데 이 식에서 threshold는 단순히 주어진 데이터를 가지고 실험을 통해 empirical하게 얻는 값입니다. 그래서 위와 같이 anomaly point를 판정하는 것은 상당히 naive한 접근입니다. 왜냐하면 주어진 데이터와 다른 패턴의 데이터가 들어온다면 기존의 threshold는 잘 작동하지 않을 수 있기 때문입니다.
그래서 논문에서는 anomaly injection을 통해 생성한 synthetic data를 활용합니다.
먼저 주어진 시계열 데이터에서 랜덤하게 몇 개의 data points를 뽑습니다. 는 랜덤하게 뽑은 data points들을 평균낸 local average입니다. mean과 var는 현재 sliding window에 속한 모든 데이터 포인트의 평균과 분산입니다.
이렇게 생성한 synthetic data point는 original data point를 대체합니다. 각 point는 anomaly로 레이블링되어 학습에 사용되지만, evaluation에는 사용하지 않습니다.
이상의 과정을 통해 생성한 synthetic time series data를 salience map으로 변환하고, CNN 모델의 input으로 투입합니다. raw data 대신 salience map을 사용하면 별도의 labeling 과정 없이도 detector가 원본 시계열 데이터의 변화를 쉽게 감지할 수 있습니다.
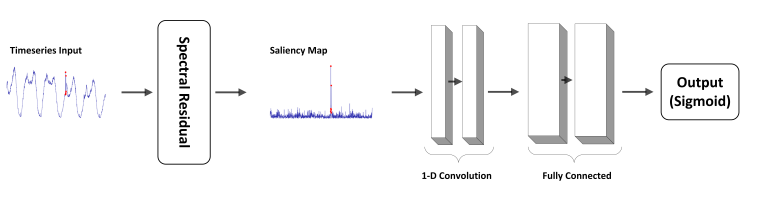
전체 과정은 위 그림과 같습니다. 주어진 시계열 데이터에 synthetic data point를 추가하고, Spectral Residual 기법을 통해 Salience map으로 변환하여 2개의 1D CNN 레이어로 이루어진 detector network에 집어넣습니다. Optimizer는 SGD를 사용했고, normal인지 anomaly인지 구분해야 하므로 Cross Entropy를 loss function으로 사용했습니다.
5. Experiments
5-1. Datasets
KPI, Yahoo, 그리고 MS 내부 데이터를 사용해서 학습했다고 합니다.
5-2. Metrics
논문은 모델을 크게 Accuracy, Generality, Efficiency의 3가지 관점에서 평가합니다.
먼저 Accuracy를 측정하기 위해 f1 score, recall, precision을 사용했습니다. 실제 서비스 운영 시에는 point-wise한 metric은 신경쓰지 않으며, 중요한 것은 적당한 delay threshold 안에서 연속적인 anomaly 발생 시에 알람을 띄우는 것이기 때문에 이에 적합한 evalutation strategy를 채택했다고 합니다.
이러한 연속적인 anomalies는 개별 포인트를 모두 detect하는 것보다 적절한 포인트에서 한 번만 detect하는 것이 더 효율적입니다. 예를 들어, anomaly가 처음 발생하고 나서 시점 이내에 탐지만 가능하다면 잘 탐지한 것으로 인정하는 것입니다.
예를 들어 위와 같은 데이터가 있고, 허용되는 delay는 1이라고 가정해 봅시다. 그리고 point-wise anomaly detection 결과는 두 번째 행과 같이 주어졌을 때, 첫번째 segment는 delay=1이므로 correct가 됩니다. 하지만 두 번째 segment는 delay=2이므로 incorrect로 판정되는 것이죠.
논문에서는 모델의 실제 적용 기준을 분 단위 데이터에 대해서는 , 시간 단위 데이터에는 , 일 단위 데이터는 로 설정했다고 합니다.
Efficiency의 경우 온라인 서비스용 모델은 엄청난 연산량을 짧은 시간 내에 감당해야 하므로 latency가 매우 중요합니다. 그래서 각각의 데이터에 대해 execution time을 비교했습니다.
마지막으로 Generality의 경우 Yahoo dataset을 stable, unstable, seasonal의 3개 그룹으로 나누어 f1-score를 보는 식으로 평가했습니다.
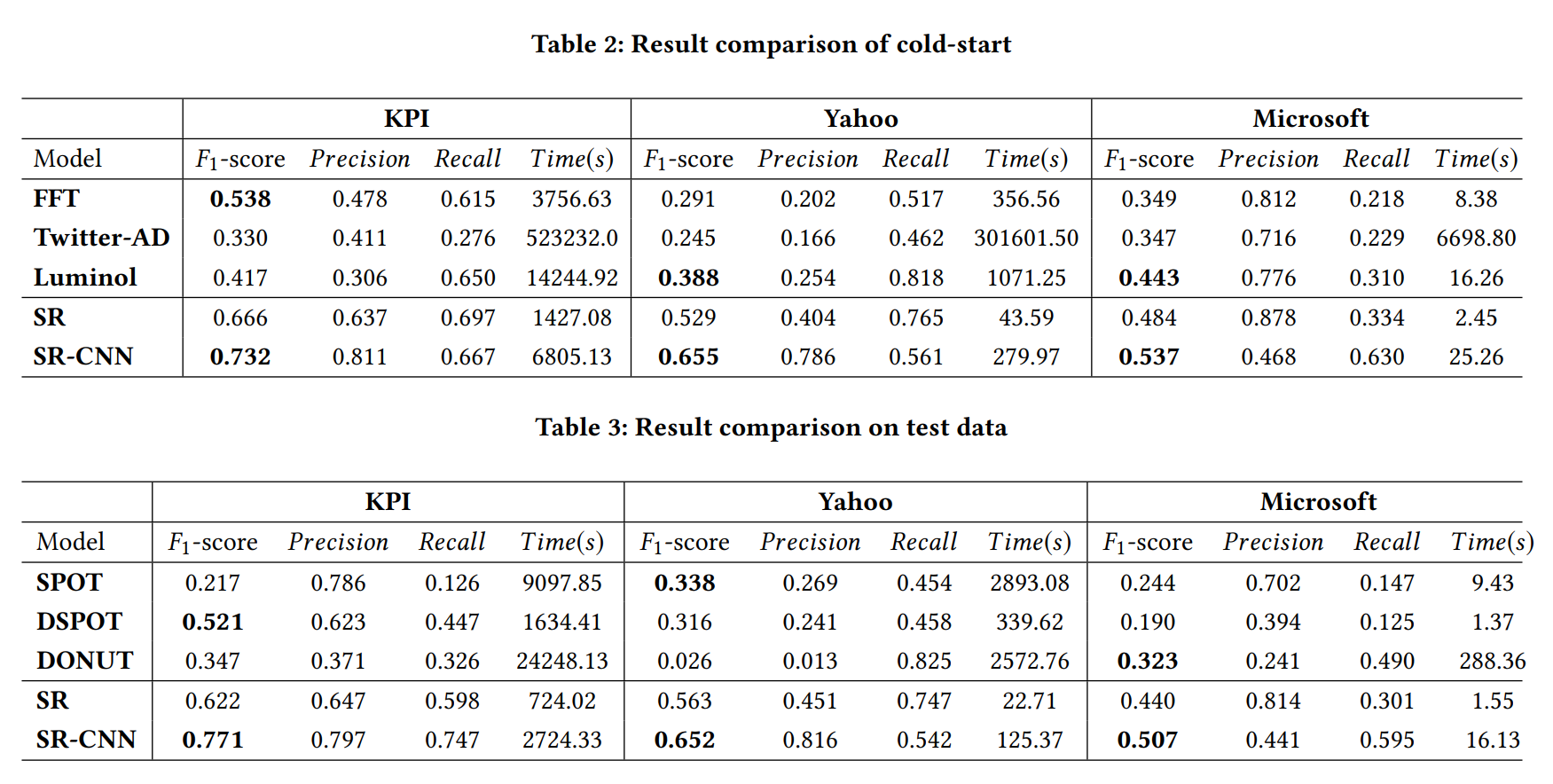
5-3. Results
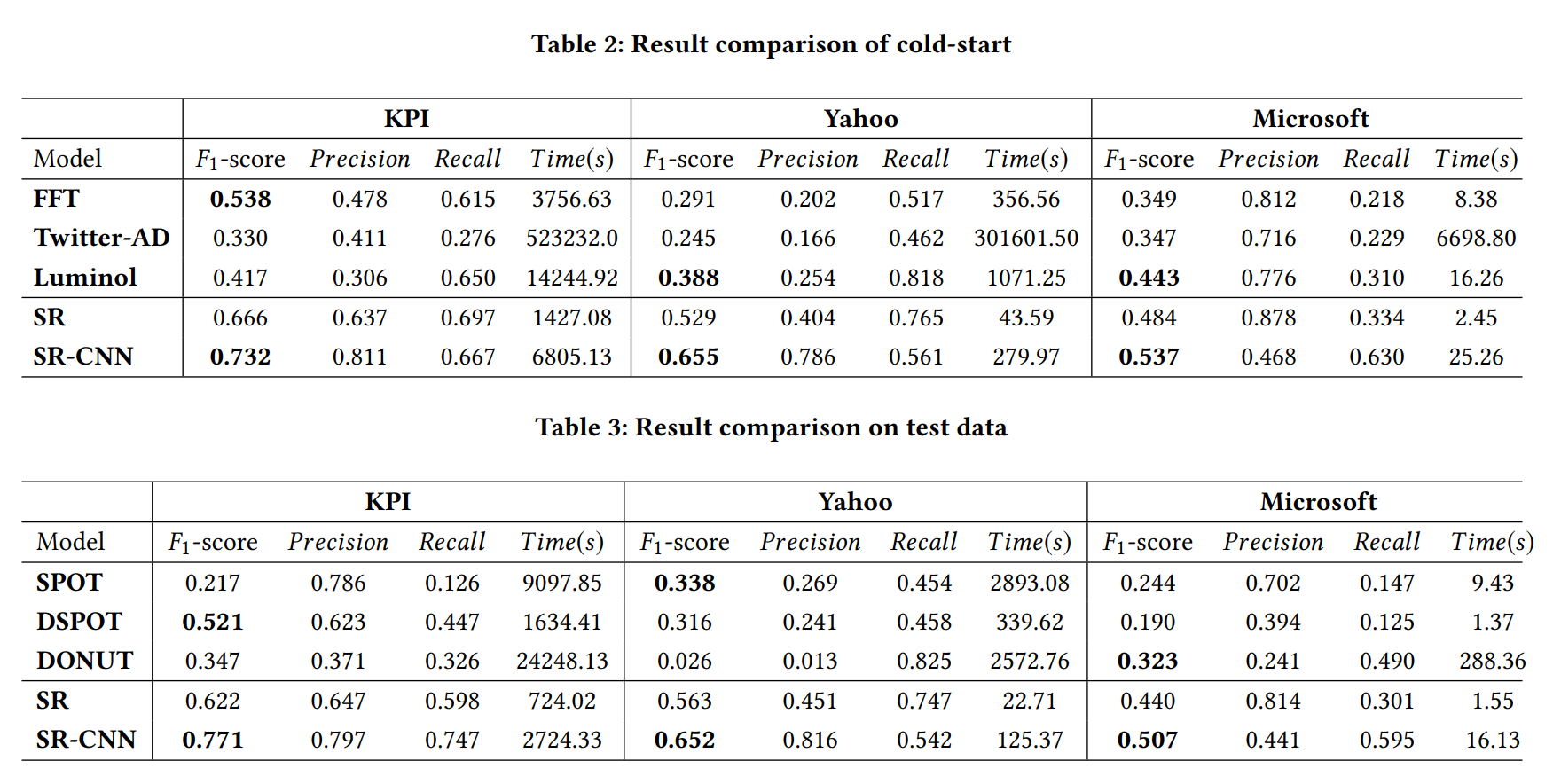
최종 결과는 위와 같습니다.
참고문헌
