[추천시스템] Representation Learning with Large Language Models for Recommendation
Papers Review

- Published on WWW 2024
- Official code
요약
-
LLM과 추천시스템의 결합을 위한 RLMRec 프레임워크를 제시하였음
-
기존 연구들과 달리 토큰 임베딩에 추천 모델의 임베딩을 합치지 않고 별도의 semantic alignment 방식을 사용함
-
제안된 프레임워크에 대한 이론적 근거를 제시함
Background
Collaborative Filtering
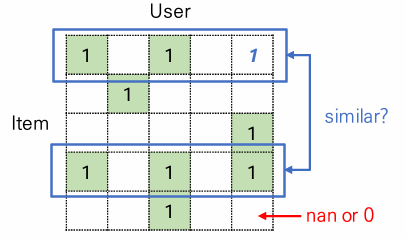
Collaborative Filtering 계열의 추천시스템은 기본적으로 user/item id 기반으로 작동합니다.
간단하고 성능도 좋은 편이지만, 동시에 굉장히 한정된 정보만을 다룬다는 치명적인 단점이 있습니다. 데이터에 노이즈가 끼기도 쉽습니다. 예를 들어 사용자가 상품을 잘못 클릭해서 생긴 false positive를 구분하기 어렵고, 인기 많은 상품이 더 많이 노출되는 popularity bias 같은 문제도 있습니다. 전체 데이터 대비 user-item 간 interaction의 비율도 상당히 낮아서 (보통 0.01~3% 전후) 아주 적은 양의 데이터를 보고 예측을 해야 한다는 문제도 있죠. 결과적으로 데이터 품질에 따라 모델 성능이 크게 변동합니다.
최근에는 LLM을 이용해서 부족한 additional information을 보충하는 연구(LLMRec (WSDM 24), CLLMRec, LLaRA (SIGIR 24) 등)들이 많이 늘어났는데 이런 연구들은 기본적으로 LLM이 추천에 필요한 어떤 정보를 가지고 있을 것이라는 전제를 깔고 있습니다. 이런 논문이나 요런 연구에서 시사하듯이 LLM에는 일종의 commonsense가 있고, 그 안에 추천과 관련된 '유용한 정보'가 있을 거란 기대죠.
LLM+RecSys?
이처럼 LLM을 활용하여 추천시스템을 개선하는 연구에는 몇 가지 문제가 있습니다.
첫 번째는 두 도메인에서 사용하는 데이터 포맷이 상당히 다르다는 점입니다. Id-based interaction matrix를 자연어로 표현하든 아니면 그 반대든, 정보량을 유지하면서 상호 변환하는 게 말처럼 쉽지가 않습니다. CLIP dataset처럼 도메인끼리 1:1 매핑된 데이터셋도 없거니와 유저들의 취향이라는 게 제각각이라서 그런 데이터셋을 만드는 것도 굉장히 어렵습니다. 그래서 보통 프롬프트를 이용하여 추천 도메인의 지식을 주입합니다. 예를 들면 QA 형식의 프롬프트를 써서 상품 추천 문제를 QA 문제로 바꾸는 방법이 있습니다.
두 번째는 LLM을 기존 추천시스템에 접목시키는 것 자체가 상당히 비효율적이라는 것입니다. 예를 들어 LLM을 사용자화(personalize)하는 건 비용이 아주 많이 듭니다. LLaMA2-13B 기준으로 800토큰 정도의 입력을 받아서 상품을 추천해주는데 3.6초 정도 걸리는데, 실 서비스에서 다루는 유저 숫자와 DB 크기에서는 응답하는데 걸리는 시간이 엄청나게 늘어나겠죠? LLM마다 입력 가능한 토큰의 길이에도 제한이 있어서 user와 관련된 모든 정보를 다 보면서 global user dependency를 모델링하는 것도 어렵습니다.
마지막으로 hallucination도 굉장히 중요한 문제입니다. 앞서 'LLM이 아무튼 추천에 필요한 어떤 정보를 가지고 있을 것'이라고 했는데, 정작 원하는 정보가 어떤 것인지도 모르는데 할루시네이션인지 아닌지 구분은 어떻게 할까요?
Method
저자들은 할루시네이션을 어느 정도 방지하기 위해 우선 LightGCN을 이용해서 user별로 50개의 item을 추려낸 후 LLM이 reranking하는 방법을 사용했습니다. 일종의 prior를 설정해준다고 생각하면 됩니다.

그 다음, 위와 같은 프롬프트를 LLM(gpt 3.5 turbo)에게 주고 각 item마다 profile을 생성합니다. 마지막으로 생성된 profile data를 이용해서 주어진 50개의 candidates 중 top10 & 20을 rerank하여 최종적인 추천을 출력합니다.
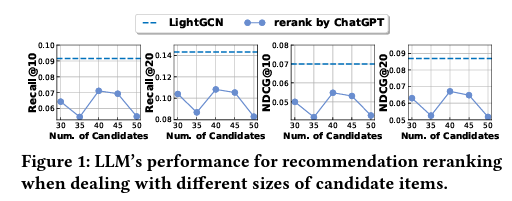
그러나 실험 결과를 보면 chatgpt가 생성한 추천이 LightGCN 대비 일관적으로 더 낮은 성능을 보입니다. 즉, LLM을 순정 상태로 사용하는 건 현실적으로 메리트가 없습니다.
RLMRec
저자들은 이러한 문제들을 해결하기 위해 의미적(semantic) 관점에서 LLM과 추천시스템의 cross-view alignment를 수행하는 RLMRec 프레임워크를 제안했습니다.
Collaborative Filtering
우선 collaborative filtering을 수식으로 표현해 보겠습니다.
는 user들의 집합, 는 item들의 집합입니다. User-item interaction data를 라고 하면 각각의 initial embedding은 로 나타낼 수 있습니다. 그러면 학습 목표는 추천 모델을 이용해서 최적의 representation 를 얻는 것이 되겠죠.
는 posterior, 는 prior, 는 likelihood입니다. 를 모르니까 를 최대화(MLE)하면 되는데, 문제는 가 false positive, popularity bias와 같은 noise의 영향을 받았거나 받았을 확률이 높다는 겁니다.
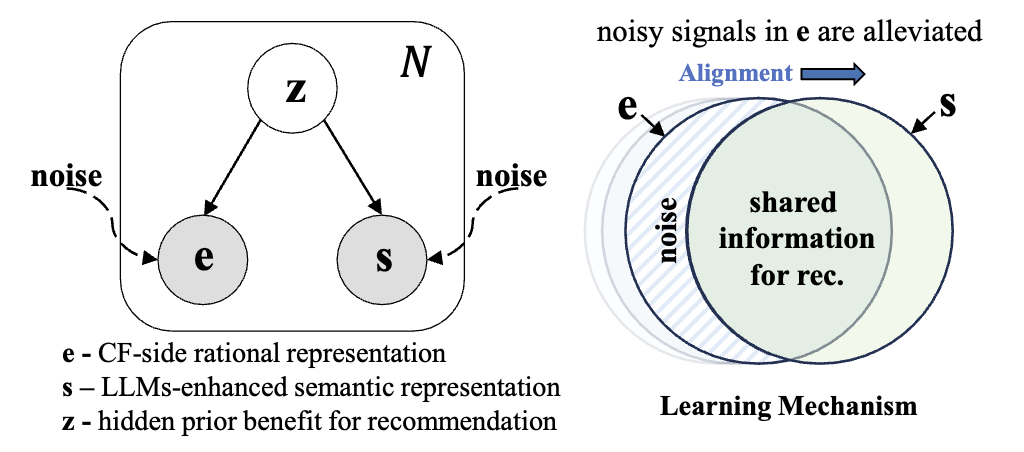
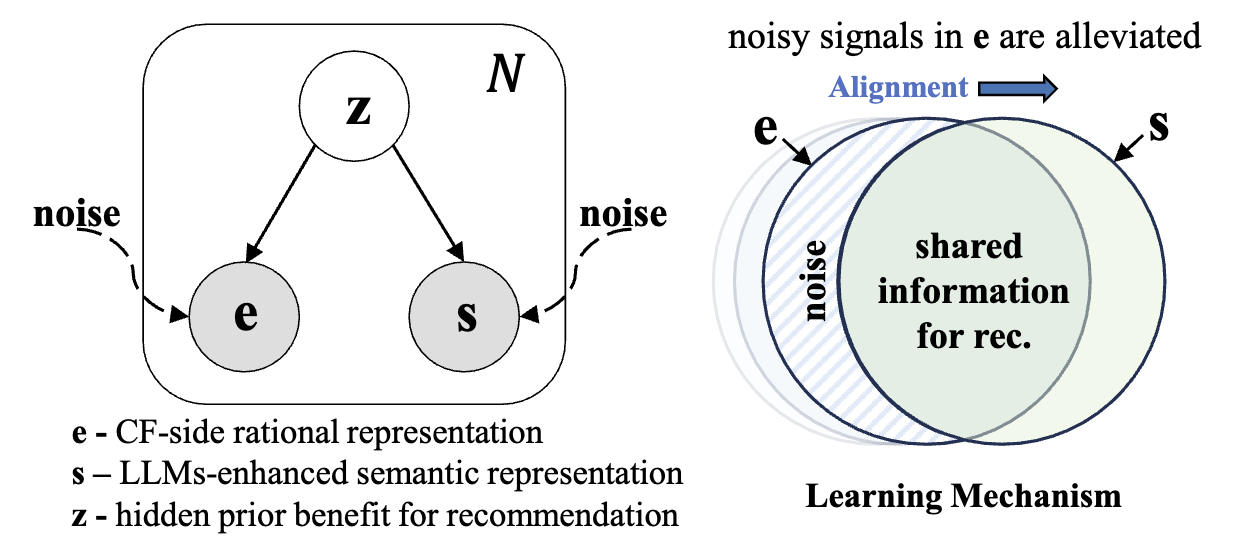
그래서 논문에서는 위 그림과 같이 noise의 영향을 받지 않는 어떤 hidden prior 가 있다는 가정 하에 true positive 를 찾는 것을 목표로 합니다.
Employ LLMs
주어진 데이터만으로는 노이즈를 구분할 수 없기 때문에 추가적인 정보가 반드시 필요합니다. 예를 들어 user/item profile과 같은 textual information을 사용하면 user preference를 모델링하는데 도움이 됩니다.
Language model을 이용하면 이런 textual information의 의미적인 정보를 포함한 representation 로 바꿀 수 있습니다. 쉽게 말해 LLM을 이용해서 textual information을 임베딩 벡터로 바꿔주는 겁니다.
중요한 건 LLM이 생성한 와 추천 모델이 생성한 사이에는 user-item interaction에 대한 공통적인 정보가 있다는 점입니다. 그리고 이 공통적인 정보는 앞서 설정한 hidden prior 와 연관이 있습니다. 만약 둘 사이에 공통되는 정보가 있다면 그건 추천에 도움이 되는 (즉, 에서 생성된) 정보일 가능성이 높겠죠. 이를 수식으로 표현하면 다음과 같습니다.
다시 말해, LLM이 생성한 임베딩 를 이용하여 를 최대화시키는 를 찾는 과정에서 가 에 포함된 semantic information까지 반영할 수 있게 됩니다.
보통 log-likelihood를 사용하므로 식 (1)에 로그를 씌우고, 식을 조금 변형합니다.
User/item profile은 고정된 값이므로 를 상수로 취급하면 최적화 과정에서 는 무시할 수 있고, 에 대해 적분해서 의 영향력을 제거하면 다음과 같습니다.
따라서 식 (1)은 다시 아래와 같이 전개할 수 있습니다.
식 (2)는 상호 정보량(Mutual Information)의 정의와 동일합니다. 즉, LLM이 생성한 임베딩 를 이용하여 를 최대화시키는 를 찾는 과정은 와 의 상호 정보량을 최대화시키는 것과 같습니다.
Maximize Mutual Information
를 각각 개의 data samples라고 하면 이고 과 같이 쓸 수 있습니다.
상호 정보량의 성질에 따라 이므로 아래 등식이 성립합니다.
식을 조금 더 변형해보면 다음과 같이 쓸 수 있습니다.
여기서 라고 놓고 일 때를 생각해보면 더 이상 추천 모델의 임베딩만으로 LLM의 profile을 개선할 수 없으므로 최적화가 완료된 것과 같습니다.
이고 이므로 입니다. 그러면 자연스럽게 이 성립합니다.
이에 따라 식 (3)을 아래와 같이 쓸 수 있습니다.
이제 negative samples 의 영향력을 고려하면 다음과 같이 전개됩니다.
Contrastive Predictive Coding (CPC)에서 유사도 함수 라는 점을 이용하면 식 (4)는 결국 아래와 같이 InfoNCE loss의 꼴로 바꿀 수 있습니다.
즉, LLM이 생성한 정보 를 반영하여 최적의 representation 를 얻는 것은
추천 모델이 생성한 임베딩 와 LLM이 생성한 임베딩 간의 상호정보량 를 최대화
두 임베딩 간의 infoNCE loss를 최소화
하는 것과 같습니다.
User/Item profiling
하지만 우리는 아직 를 얻는 방법을 모릅니다. 즉, 를 얻기 위해 각각의 user-item interaction을 효과적으로 설명하는 프롬프트를 획득할 방법이 필요합니다.
논문에서 제안한 방법은 생각보다 간단한데, 바로 각 user와 item에 대해 profile을 reasoning하도록 설계한 시스템 프롬프트 를 사용하는 것입니다.

우선 item profile부터 생성합니다. Instruction 부분을 보면 주어진 item들을 기반으로 해당 상품을 좋아할만한 사용자들을 프로파일링하도록 설계돼 있습니다.

이후 프롬프트를 투입하여 위와 같은 item profile을 얻습니다. User 데이터에 대해서도 동일한 과정을 거쳐 user profile을 뽑아낸 후, 생성된 generated prompts 를 시스템 프롬프트와 함께 LLM에 입력하면 최종 profiles 을 얻습니다.
Item prompt construction
User/item 프로필을 얻기 위해 프롬프트 를 설계하는 방법을 살펴보겠습니다. 논문에서는 item에 관한 정보를 4가지로 나누어 사용합니다.
- : title
- : description (영화 줄거리, 상품 설명, 음악 설명 등)
- : dataset-specific attributes (장르, 감독, 출연진 / 브랜드, 색상 등)
- : user 명의 리뷰
상기한 4가지 종류의 정보를 기반으로 item prompt를 생성합니다.
를 각 아이템에 개별적으로 적용하여 하나의 문자열로 병합합니다. 예를 들어 item에 대한 설명 가 없다면 중에서 랜덤하게 하나를 뽑아 넣습니다. 결과적으로 LLM 입장에서는 item에 대한 다양한 관점의 정보들을 고려할 수 있게 됩니다.
User prompt construction
Item profile이 생성되었다면 이제 user profile을 생성할 차례입니다.
User 와 상호작용이 있는 item들을 라고 하면, 를 uniform하게 뽑아서 각각의 item 에 대해 textual attribute들을 concat하여 를 생성합니다. 즉, user 에 대한 prompt는 다음과 같이 나타낼 수 있습니다.
마지막으로 생성된 각각의 프롬프트 를 json 포맷으로 정리한 다음 text embedding model(e.g. text-embedding-ada-002)에 넣어 semantic embedding 를 얻습니다.
Density ratio modeling
다시 식 (5)로 돌아가 봅시다.
여기서 는 간의 similarity score를 출력하는 함수입니다. 논문에서는 크게 두 가지를 제안합니다.
Contrastive Alignment
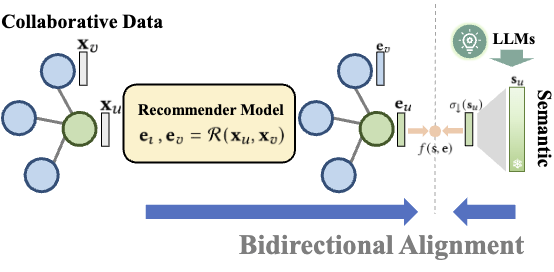
첫 번째 방법은 contrastive alignment입니다.
우선 MLP 에 를 넣어서 와 차원 크기를 맞추고, 주어진 쌍에 대해 코사인 유사도를 계산합니다. 학습이 진행되면 배치 내 positive pair 간의 유사도가 높아지게 되고, 이는 번째 sample에 대해 semantic alignment를 수행하는 것과 같습니다.
이 방법을 적용한 프레임워크를 RLMRec-Con으로 지칭합니다.
Generative Alignment
두 번째 방법은 generative alignment입니다. MAE(Masked AutoEncoder)를 이용해서 번째 user에 대해 semantic alignment를 수행하는 방법입니다. 수식으로 표현하면 다음과 같습니다.
본문에는 라고 적혀있지만 맥락상 를 가리키는 것으로 보겠습니다.
는 마스킹이 적용된 번째 sample의 초기 임베딩 벡터입니다. 논문에서는 그래프 기반 추천모델을 사용했기 때문에 edge의 값을 무작위로 제거하는 edge masking 방식과 랜덤 노드의 값을 0으로 바꿔주는 node masking 방식을 사용했습니다.
이 방법을 적용한 프레임워크를 RLMRec-Gen으로 지칭합니다.
Objective function
전체 프레임워크의 optimization function을 정리하면 다음과 같습니다.
추천모델 과 LLM은 어떤 모델을 사용해도 상관없습니다.
Experiment
Datasets & Settings
- Amazon-Books (도서류 별점 및 리뷰)
- Yelp (다양한 상점/가게에 대한 리뷰)
- Steam (스팀 플랫폼 리뷰)
위 데이터셋들에 대해 3점 미만은 잘라내고, k 미만의 차수를 가진 엣지를 제거하도록 k-core filtering을 적용한 후 {train:val:test = 3:1:1} 비율로 분할하여 사용했습니다.
- Chatgpt3.5 turbo 사용
- batch size = 4096
- representation
- learning rate
하이퍼파라미터 세팅은 위와 같습니다.
Performance Comparison
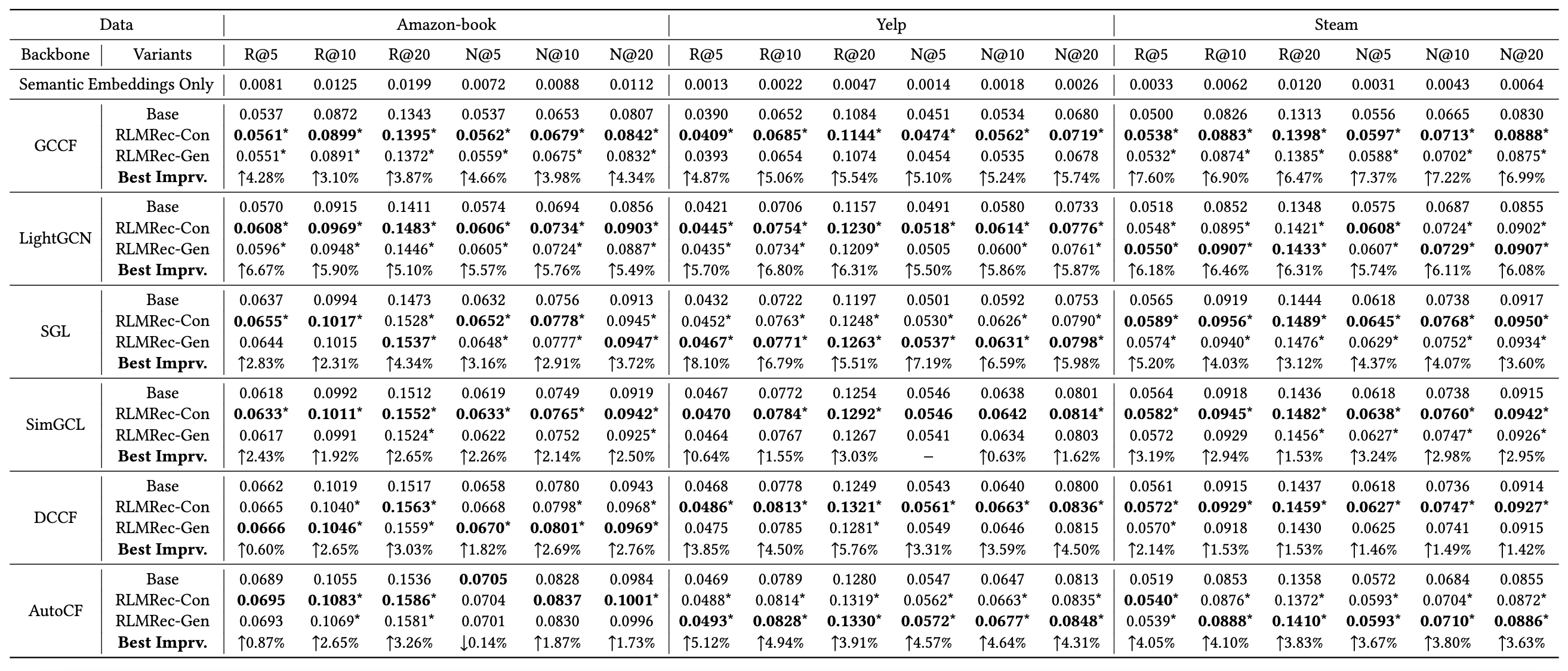
전체적으로 베이스라인 대비 성능이 좋은 편이긴 합니다만 여타 SOTA급의 복잡한 추천 알고리즘들과 비교한 결과가 없는 부분은 아쉽습니다.
마스킹을 적용한 RLMRec-Gen보다 단순히 contrastive learning을 적용한 RLMRec-Con이 (marginal 하지만) 평균적으로 더 나은 성능을 보이는데, 이는 학습 과정에서 추천 모델 에서 추출한 임베딩 를 기준으로 삼기 때문에 마스킹을 적용하면 불필요한 노이즈가 생기는 것으로 추측됩니다.
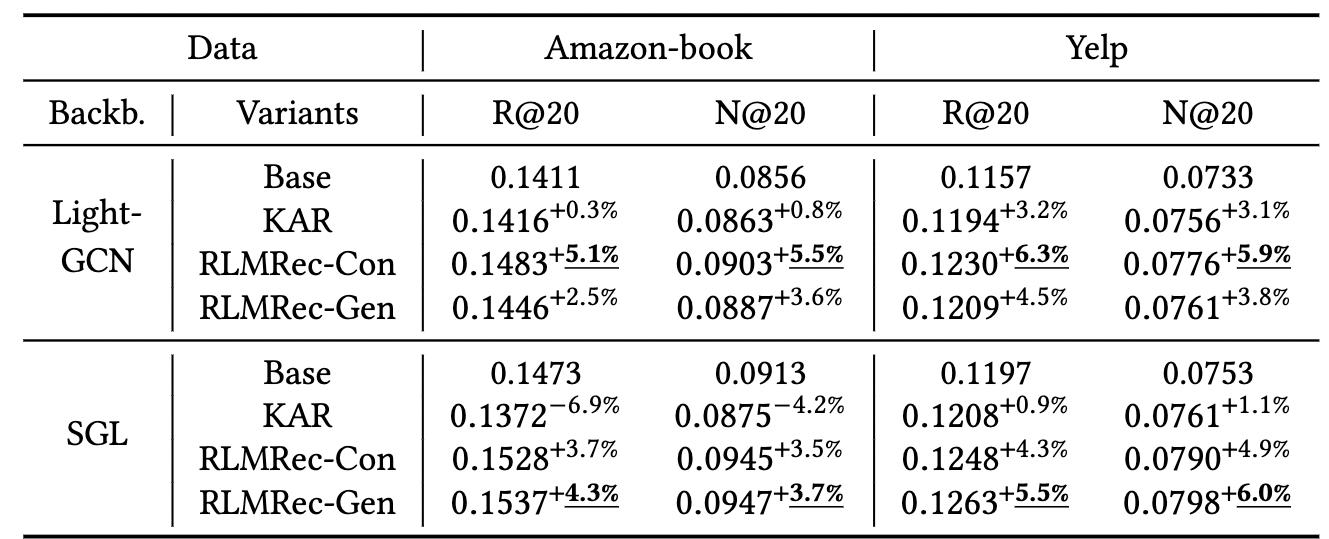
최근 연구들 중에 RLMRec과 비슷하게 LLM이 생성한 user, item description을 이용하여 MLP들로 이루어진 MoE 구조를 적용한 KAR이라는 프레임워크가 있습니다. 논문에서 비교 실험을 진행한 결과 큰 차이는 아니지만 RLMRec보다는 더 낮은 성능을 보여줬는데요.
저자들에 따르면 KAR은 생성된 description들을 representation으로 변환하여 input으로 사용하지만 이는 엄밀히 말해 user behavior modeling에 적합한 feature가 아니며, LLM의 특성으로 인해 불필요한 노이즈가 개입할 수 있다고 합니다 (사실 그건 RLMRec도 마찬가지 아닌가 싶지만...).
Semantic Embeddings
또 다른 실험 관찰 포인트는 text embedding model에 따른 변화입니다. Text embedding model을 이용하여 LLM이 생성한 최종 프로파일 를 semantic embedding 로 변환하기 때문에 어떤 임베딩 모델을 사용하느냐에 따라 성능이 달라지겠죠?
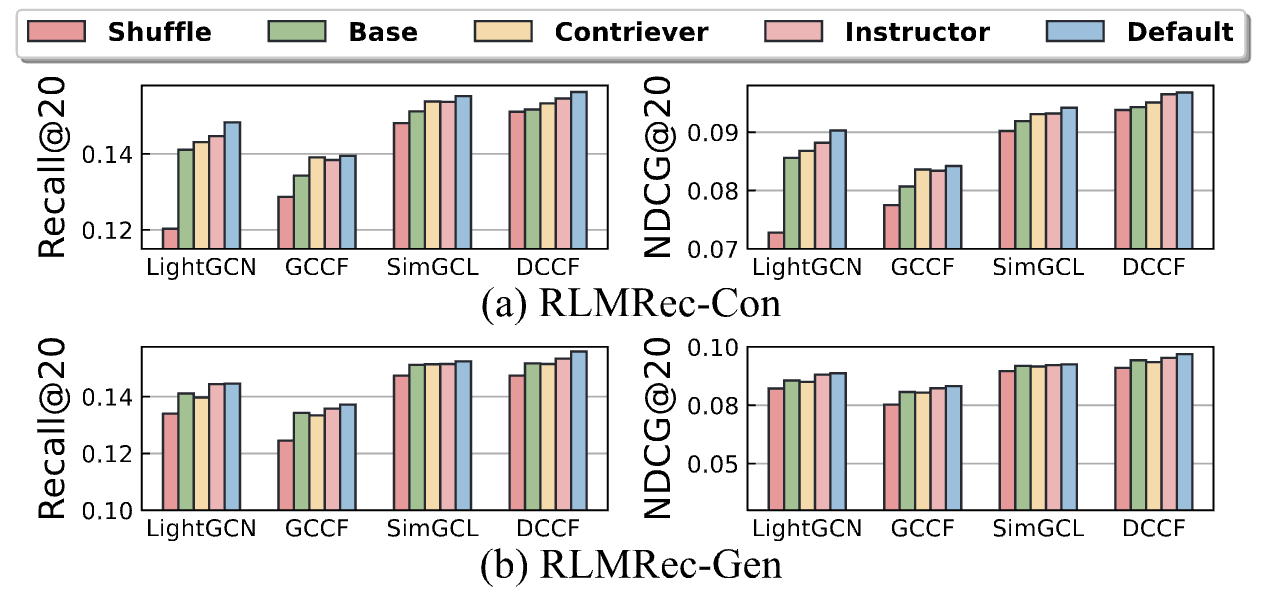
여기서 default는 text-embedding-ada-002 모델(OpenAI에서 제공하는 embedding 모델)을 가리킵니다.
당연하지만 semantic representations을 랜덤하게 섞으면 collaborative-semantic alignment가 흐트러지기 때문에 성능이 급격하게 저하됩니다. 반대로 말하자면 두 signal 간의 semantic alignment가 성능 향상에 큰 영향을 미친다고 할 수 있습니다.
Contriever나 Instructor와 같이 다른 embedding model을 사용해도 baseline은 충분히 넘기 때문에 제안된 프레임워크 내에서 semantic alignment가 잘 이루어지고 있다고 볼 수 있겠습니다.
Performance w.r.t. Noisy data
RLMRec의 학습 개요를 다시 살펴보면, 학습이 진행되면서 contrastive alignment를 통해 noise가 제거되어야 합니다. 즉, 동일한 noise 데이터에 대해 프레임워크 적용 후 base model의 성능이 개선되어야겠죠.
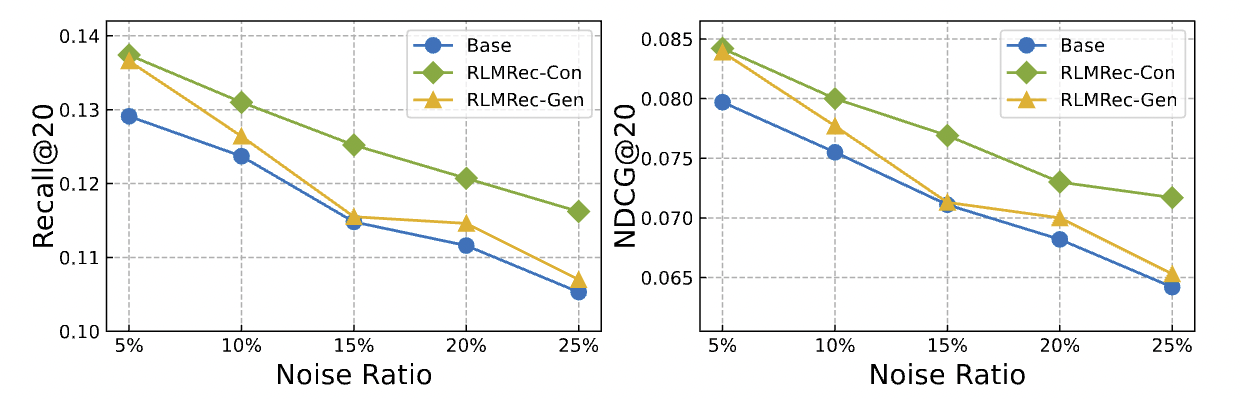
Amazon books 데이터셋에 가상의 interaction을 생성하여 실험한 결과 backbone 모델의 성능이 향상됨을 확인할 수 있습니다. 전체적인 performance는 지속적으로 감소합니다만 이는 백본 모델의 문제이기도 하고, 근본적으로는 추천 데이터셋이 상당히 sparse하기 때문에 false data에 영향을 크게 받기 때문입니다.
Pretraining Scenarios
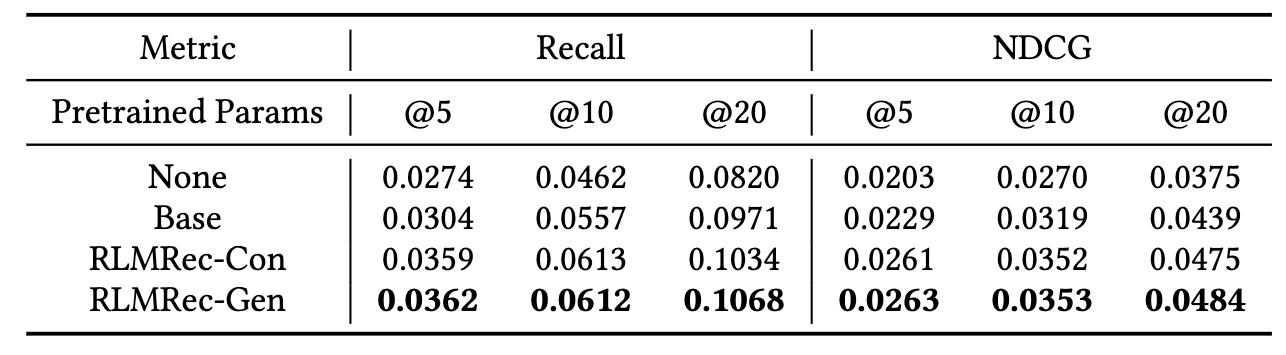
LightGCN을 기반으로 RLMRec을 이용하여 pretrain한 결과입니다. 흥미로운 점은 앞서 performance comparison에서는 RLMRec-Gen을 사용했을 때의 성능이 RLMRec-Con을 적용했을 때보다 낮았는데 pretrain에서는 반대의 경향을 보이고 있습니다. 저자들은 이에 대해 masking이 일종의 regularization으로 작용하여 overfitting을 방지한 것이라고 주장합니다.
Case study

마지막으로 간단한 case study를 하나 살펴보겠습니다.
위 그림에서 과 사이에는 3 hop 이상의 거리가 있습니다. 두 user의 representation 간에 공통점이 별로 없다는 뜻입니다. 물론 이것만으로 두 user의 preference가 유사한지 여부를 완전히 판단할 순 없지만, representation 간의 거리가 멀면 preference도 비슷하지 않을 가능성이 높죠.
그런데 흥미롭게도 실험 결과를 보면 원래 두 user의 representation 간 relevance score는 0.4였으나 semantic alignment를 적용한 후 약 30% 증가한 0.52를 기록하였습니다. 즉, LLM-enhanced semantic alignment를 이용하면 기존 추천모델만으로는 알 수 없는 과 간의 잠재적인 공통점을 찾아낼 수도 있습니다.
Overall review
1. Theoretical background
- LLM과의 결합은 최근에 핫해진 분야이기 때문에 많은 논문에서 이론적 배경이 빈약하지만 본 논문에서는 꽤 논리적인 이론적 배경을 제안했습니다.
2. 추천 모델에 대한 의존성
- 저자들은 할루시네이션에 대응하기 위해 추천 모델의 임베딩을 기준으로 삼습니다. 하지만 이 방법은 에 대한 dependency가 높아진다는 단점이 있습니다. 만약 에 bias가 끼어 있다면 를 학습하는 과정에서 해당 bias가 제거되지 않고 성능을 악화시킬 수 있습니다.
3. Denoising & Hallucination
- RLMRec은 를 최대화하는 방향으로 최적화를 진행합니다. LLM을 이용하여 추천에 관련된 additional information을 최대한 많이 획득하게 유도하면 추천과 관련없는 노이즈도 제거할 수 있습니다.
