
안녕하세요!
kotlin in action 개념 정리로 다시 돌아온 코틀린 고수가 되고싶은 김조현입니다.
3장에서는 모든 프로그램의 핵심이라고 할 수 있는 컬렉션과 함수의 개념에 대해 살펴볼 것입니다.
컬렉션에 대하여
컬렉션이란 list, map, set 등과 같이 여러 원소들을 그룹화하여 관리하는 자료구조를 의미합니다.
list, map, set 등은 모두 코틀린에서 setOf, mapOf, listOf 등을 사용하여 만들 수 있습니다.
fun main() {
val set = setOf(1, 3, 195)
val list = listOf(1, 3, 195)
val map = mapOf(1 to "one", 3 to "three", 195 to "one-nine-five")
println(set.javaClass)
// class java.util.LinkedHashSet
println(list.javaClass)
// class java.util.Arrays$ArrayList
println(map.javaClass)
// class java.util.LinkedHashMap
}코틀린의 컬렉션은 자바의 표준 컬렉션 클래스를 사용합니다. 이는 코틀린 컬랙션에 .javaClass 를 호출해보면 자바 표준 컬렉션 클래스를 반환하는 것으로 확인할 수 있습니다.
이러한 특징 덕분에 자바와 잘 호환되서 서로 변환할 필요가 없습니다. 또한 코틀린에서는 자바보다 컬렉션을 활용한 더 많은 기능들을 사용할 수 있습니다.
fun main() {
val strings = listOf("first", "second", "fourteenth")
strings.last()
// fourteenth
println(strings.shuffled())
// [fourteenth, second, first]
val numbers = setOf(1, 14, 2)
println(numbers.sum())
// 17
}함수를 호출하기 쉽게 만들기?
위에서 shuffled(), sum() 등 같이 메소드를 사용해서 컬렉션을 다루기 위해서는 메소드를 어떤 식으로 만드는지 알 필요가 있습니다.
fun main() {
val list = listOf(1, 2, 3)
println(list)
// [1, 2, 3]
}리스트를 생성한 후에 출력해본다면 [1, 2, 3]이 반환되는 것을 볼 수 있습니다. 이렇게 나타나는 이유는 자바 컬렉션에서 기본으로 구현된 toString 덕분입니다.
하지만 콤마로 구분하고 대괄호에 묶어 반환하는 방식이 원하는 방식이 아닐 수도 있습니다. 이럴 때에 함수를 직접 구현하여 해결할 수 있습니다.
kotlin의 joinToString의 기능을 요약하여 구현한 함수입니다. 이 함수는 컬렉션의 출력 방식을 커스텀 할 수 있는 기능을 가집니다. 컬렉션과 구분자, 접두사와 접미사를 파라미터로 받아서 toString으로 출력하는 함수입니다.
이 함수는 컬랙션을 제네릭으로 받기에 어떤 타입의 값을 원소로 하는 컬렉션이든 모두 처리할 수 있습니다. 제네릭은 다른 장에서 깊게 다뤄보겠습니다.
fun <T> joinToString(
collection: Collection<T>,
separator: String,
prefix: String,
postfix: String
): String {
val result = StringBuilder(prefix)
for ((index, element) in collection.withIndex()) {
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}
fun main() {
val list = listOf(1, 2, 3)
println(joinToString(list, "; ", "(", ")"))
// (1; 2; 3)
}이 함수를 선언할 때에는 모든 파라미터를 받도록 해야합니다. 만약 joinToString(collection, " ", " ", ".") 처럼 함수를 호출하게 된다면 어떤게 구분자인지, 접두사인지 한 번에 파악할 수 있을까요?
물론 함수를 외우고 있다면 가능하겠지만, 일반적으로 모든 함수를 외우기는 쉽지 않기 때문에 어떤 파라미터인지 확인하기가 힘듭니다.
코틀린은 이름 붙은 인자와 디폴트 파라미터 값으로 가독성 문제를 해결하였습니다.
이름 붙인 인자?
코틀린은 이름 붙인 인자를 사용해 이런 가독성 문제를 해결했습니다.
자바의 경우는 아래와 같은 식으로 주석을 사용해 파라미터의 이름을 명시하도록 요구합니다.
joinToString(collection, /* separator */ " ", /* prefix */ " ", /* postfix */ ".")이런 방법은 너무 번거로우며 코드를 작성할 때도 힘듭니다. 코틀린은 아래와 같이 선언합니다.
joinToString(collection, separator = " ", prefix = " ", postfix = ".")확실히 자바보다 더 좋아보이지 않나요? 이름 붙인 인자를 사용했을 때 장점은 파라미터의 이름을 한 번에 파악할 수 있다는 점도 있지만, 순서가 바뀌어도 상관이 없다는 장점도 가집니다.
디폴트 파라미터 값
코틀린에서는 함수 선언에서 파라미터의 기본값을 지정할 수 있습니다. 이를 디폴트 파라미터 값이라고 부릅니다.
디폴트 파라미터 값을 선언했을 때는 그 인자를 생략할 수 있다는 장점이 있습니다. 파라미터 뒤에 디폴트 값을 선언하는 것으로 디폴트 파라미터를 정의할 수 있습니다.
fun <T> joinToString(
collection: Collection<T>,
separator: String = ", ",
prefix: String = "",
postfix: String = ""
): String 하지만 생략할 때는 주의해야할 점이 있습니다.
이름을 명시하지 않고 사용하는 일반 호출 문법으로 함수를 선언할 때는 파라미터의 순서에 맞게 인자를 지정해야하며, 생략을 할 때는 연속적인 생략만 가능합니다.
fun main() {
joinToString(list, ", ", "", "")
// 1, 2, 3
joinToString(list)
// 1, 2, 3
joinToString(list, "; ")
// 1; 2; 3
}이름 붙인 인자를 사용할 경우에는 순서와 상관없이 생략할 수 있으며, 파라미터의 순서가 바뀌어도 상관이 없습니다.
fun main() {
joinToString(list, postfix = "#", prefix = ")")
// )1, 2, 3#
}
// 구분자를 생략했으며, 파라미터의 순서가 바뀌어도 상관이 없다.다만 자바와 코틀린을 함께 사용하는 프로젝트에 있는 자바 코드에서는 모든 파라미터에 대한 생성자를 생성해야합니다. 왜냐하면 자바에는 디폴트 파라미터라는 개념이 없기 때문입니다.
이를 간편하게 할 수 있는 방법은 @JvmOverloads 어노테이션을 사용하는 것입니다.
이 어노테이션을 사용하면 자동으로 파라미터를 하나씩 생략하여 오버로딩한 자바 메소드를 추가해줍니다.
// 코틀린 함수
@JvmOverloads
fun <T> joinToString(
collection: Collection<T>,
separator: String = ", ",
prefix: String = "",
postfix: String = ""
): String // 자바
String joinToString(Collection<T> collection, String separator, String prefix, String postfix);
String joinToString(Collection<T> collection, String separator, String prefix);
String joinToString(Collection<T> collection, String separator);
String joinToString(Collection<T> collection);정적인 유틸리티 클래스 없애기
객체지향 언어인 자바는 모든 코드를 클래스의 메서도로 작성해야 합니다. 그러다보니 특별한 상태나 인스턴스 메서드가 없는 클래스가 생겨나는 문제점이 발생합니다.
코틀린은 함수가 클래스 밖의 소스 파일의 최상위 수준에 배치할 수 있도록 하여 객체지향의 틀에 얽매이지 않고 코드를 작성할 수 있습니다.
그런 문제점이 있음에도 자바가 클래스 안에 메소드를 작성하는 것은 JVM이 클래스 안에 들어있는 코드만을 실행할 수 있기 때문입니다. 그러면 똑같이 JVM에서 실행되지만 클래스에 포함되지 않은 메소드를 코틀린은 어떻게 실행할 수 있는 것일까요?
그 이유는 코틀린 파일을 자바로 변경해보면 알 수 있습니다.
package strings
fun joinToString( /* ... */): String { /* ... */ }package strings;
public class JoinKt {
pubilc static String joinToString( /* ... */) { /* ... */ }
}코틀린 코드의 파일명을 join.kt라고 정했다면 컴파일러가 파일의 이름에 대응하는 이름의 클래스를 생성해줍니다. 그렇기 때문에 코틀린 코드에서 최상위에 위치한 메소드들은 파일 이름에 대응하는 클래스의 정적 메소드가 되는 것입니다.
만약 컴파일러가 디폴트로 만들어주는 이름을 변경하고 싶다면 파일 가장 위에 @file:JvmName(””) 어노테이션을 사용하면 사용자가 클래스명을 변경할 수 있습니다.
@file:JvmName("StringFunctions")
package strings
fun joinToString(/* ... */): { /* ... */ }프로퍼티도 메소드와 마찬가지로 파일 최상위 수준에 놓을 수 있으며 정적 필드에 저장됩니다. 같은 필드에 포함된 메소드들은 최상위에 위치한 프로퍼티에 접근할 수 있습니다.
var opCount = 0
fun performOperation() {
opCount++
// ...
}
fun reportOperationCount() {
println(opCount)
}최상위에 상수를 정의하여 이를 활용할 수 있습니다. 상수를 정의할 때는 const변경자를 추가하면 됩니다. 이는 자바의 public static final과 동등합니다.
const val UNIX_LINE_SEPARATOR = "\n"
public static final String UNIX_LINE_SEPARATOR = "\n";확장 함수와 확장 프로퍼티란?
확장 함수와 확장 프로퍼티는 기존 코드와 코틀린 코드를 자연스럽게 통합하는 것이라는 코틀린의 핵심 목표에서 나타나게 된 기능입니다.
확장 함수
확장 함수는 자바 API를 재작서앟지 않고도 편리한 여러 기능을 사용하면 어떨까?라는 아이디어에서 나온 기능입니다.
확장 함수를 사용하는 방법은 함수 이름 앞에 확장할 클래스를 명시하는 것 뿐입니다.
fun String.lastChar(): Char = this.get(this.length - 1)
// fun String.lastChar(): Char = get(length - 1)이 예제는 String 클래스에 확장하는 것입니다. 이 때 확장할 클래스의 이름을 수신 객체 타입이라고 부르며, 확장 함수 호출 시 호출하는 대상이 되는 값을 수신 객체라고 부릅니다. this는 수신 객체를 가리키는 키워드입니다.
또한 일반 함수와 마찬가지로 확장 함수 본문에서도 this를 생략할 수 있습니다.
fun main() {
println("Kotlin".lastChar())
// n
}lastChar() 확장함수를 사용할 때는 String객체에 대해 사용할 수 있는 것입니다. 이 실행 예제에서는 “Kotlin”이 수신 객체가 됩니다.
확장 함수가 클래스에 메소드를 추가하지만, 캡슐화를 깨진 않습니다.
그 이유는 확장 함수는 인스턴스 메소드와 마찬가지로 수신 객체의 프로퍼티는 사용할 수 있지만, 클래스 안에서 정의한 메소드와 달라 내부에서만 사용할 수 있는 비공개 맴버나 보호된 맴버는 사용할 수 없기 때문입니다.
확장 함수를 정의했다고 해도 확장 함수를 사용하려면 다른 클래스나 함수와 마찬가지로 해당 함수를 임포트해야만 합니다. 이는 이름 충돌을 막기 위함입니다.
클래스를 임포트할 때와 같은 구문을 사용해서 개별 함수를 임포트할 수 있습니다. 와일드카드 임포트도 사용할 수 있고, as를 통해 클래스나 함수를 다른 이름으로 부를 수도 있습니다.
이를 활용해서 임포트할 때 확장 함수의 이름을 바꾸는 것이 확장 함수의 이름 충돌을 해결하는 유일한 방법입니다.
import strings.lastChar
val c = "Kotlin".lastChar()import strings.*
val c = "Kotlin".lastChar()import strings.lastChar as last
val c = "Kotlin".last()확장 함수는 정적 메소드와 같은 특정을 가지기 때문에 확장 함수를 하위 클래스에서 오버라이드 할 수 없습니다.
아래의 코드는 일반 객체지향 메소드의 오버라이드를 나타낸 코드입니다.
open class View {
open fun click() = println("View clicked")
}
class Button: View() {
override fun click() = println("Button clicked")
}
fun main() {
val view: View = Button()
view.click()
// Button clicked
}일반 메소드는 실행시점에 정해진 타입을 기준으로 메소드를 호출합니다.
즉 컴파일 검사가 끝났을 때는 View를 가지고 있지만 실행하는 중에 Button이 할당되는 것입니다. 그렇기에 view라는 변수는 Button 타입을 가지게 되어 click을 호출했을 때 Button의 click메소드를 호출하는 것입니다.
하지만 확장 함수는 컴파일 시점에 정해진 타입을 기준으로 반환합니다. 컴파일 검사가 끝냈을 때는 View를 가지고 있기 때문에 Button타입을 적용한다 해도 View의 메소드를 호출하는 것입니다.
자바에서도 같은 방식으로 static함수를 결정하기 때문에 같은 결과가 나옵니다.
fun View.showOff() = println("I'm a view!")
fun Button.showOff() = println("I'm a button!")
fun main() {
val view: View = Button()
view.showOff()
// I'm a view!
}즉, 확장 함수는 오버라이드할 수 없습니다.
자바에서도 확장함수를 호출할 수 있는건가?
자바에서도 확장 함수를 정의한 파일의 이름이 StringUtil.kt일 때 메서도를 호출하면서 첫 번째 인자로 수신 객체를 넘기는 방법으로 호출할 수 있습니다.
char c = StringUtilKt.lastChar("Java");확장 프로퍼티
확장 프로퍼티는 프로퍼티 형태의 구문을 가지는 것입니다. 프로퍼티라는 이름으로 불리지만 확장 프로퍼티는 문의 형태를 가지기 때문에 상태를 저장할 방법이 없어 아무 상태도 가지지 않습니다.
그래서 확장 프로퍼티에는 커스텀 접근자를 정의합니다.
val String.lastChar: Char
get() = get(length - 1)앞 절에서는 .lastChar()로 호출했지만 확장 프로퍼티로 선언한다면 .lastChar로 더 짧게 호출할 수 있게 됩니다.
확장 프로퍼티도 확장 함수와 마찬가지로 수신 객체 클래스를 앞에 붙여서 선언합니다.
StringBuilder같은 경우는 문자를 변경할 수 있으므로 var로 만들 수도 있습니다. StringBuilder는 값을 변경할 수 있으므로 게터 뿐만 아니라 세터도 함께 만들 수 있습니다.
var StringBuilder.lastChar: Char
get() = get(length - 1)
set(value: Char) {
this.setCharAt(length - 1, value)
}fun main() {
val sb = StringBUilder("Kotlin?")
println(sb.lastChar)
// ?
sb.lastChar = '!'
println(sb.lastChar)
// !
}코틀린에서는 sb.lastChar처럼 간단하게 호출할 수 있지만, 자바의 경우는 확장 함수와 마찬가지로 StringUtilKt.getLastChar(sb, ‘!’)처럼 게터나 세터처럼 명시적으로 선언하는 정적 함수 형태로 호출해야합니다.
컬렉션 처리
컬렉션을 처리할 때 사용되는 과정에서 사용되는 코틀린 언어의 특징은 아래와 같습니다.
- vararg키워드
- 호출 시 인자 개수가 달라질 수 있는 함수를 정의할 수 있다.
- 중위 함수 호출 구문
- 인자가 하나뿐인 메서드를 간편하게 호출할 수 있다.
- 구조 분해 선언
- 복합적인 값을 분해햐여 여러 변수에 나눠 담을 수 있다.
컬렉션을 만들어내는 함수가 가지는 특징은 인자의 개수를 유동적으로 받을 수 있다는 점입니다. 가변적인 개수의 인자를 받을 때 사용하는 것이 가변 길이 인자(vararg 키워드)입니다.
코틀린에서는 vararg로 선언하지만, 자바에서는 …를 가변 길이 인자로 사용합니다.
fun <T> listOf(vararg values: T): List<T> { /* 구현 */ }리스트를 만들기 위해서는 배열을 명시적으로 풀어 배열의 각 원소가 인자로 전달되게 해야한다. 이런 기능을 담당하는 것이 스프레드 연산자다. 배열 앞에 *를 붙여서 배열의 원소를 한 번에 받을 수 있게 됩니다.
아래의 코드는 array 컬랙션의 원소를 그냥 출력했을 때와 스프레드 연산자를 사용했을 때를 비교해본 코드입니다.
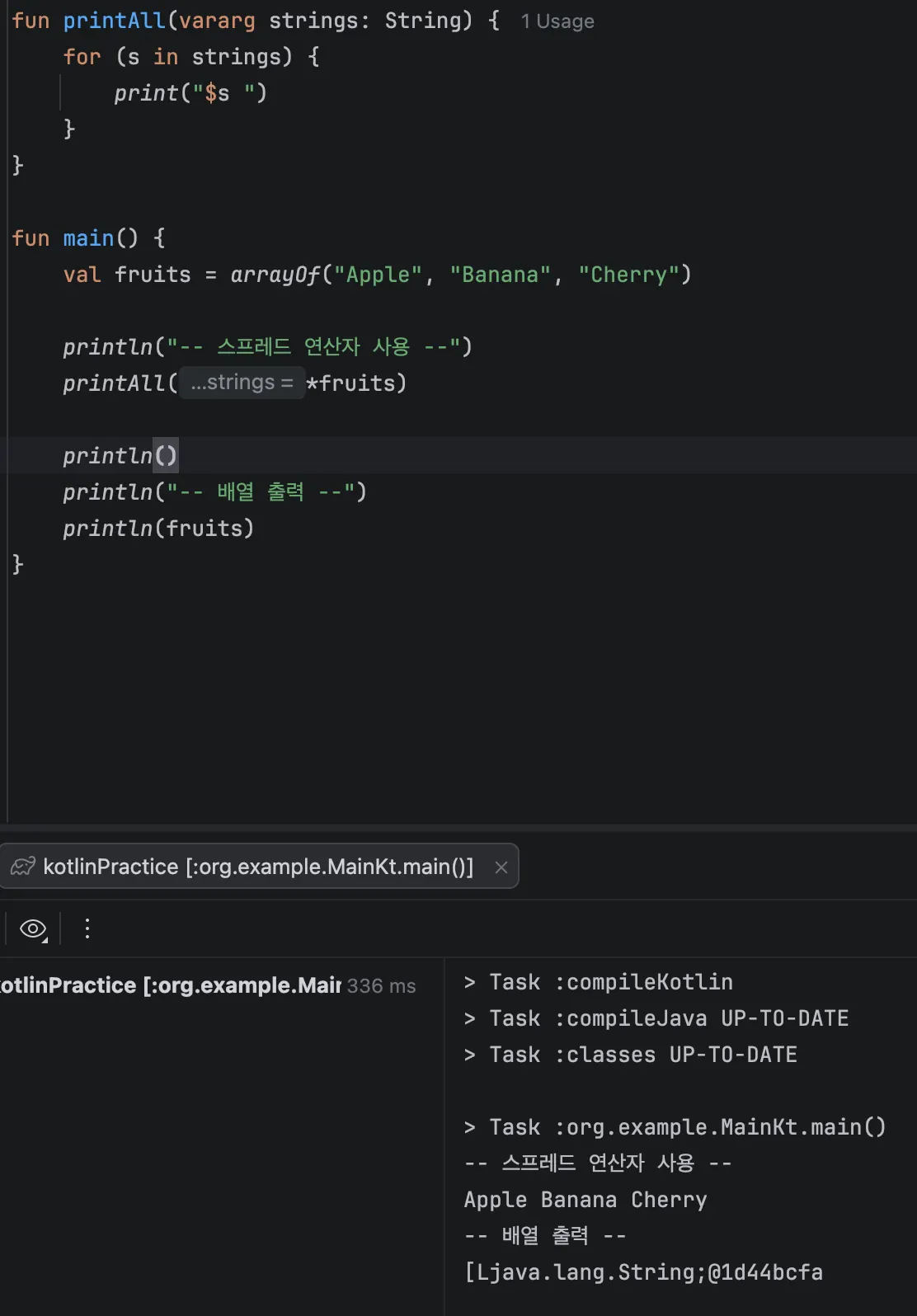
출력 결과를 보면 배열을 출력했을 때는 array 형태로 출력되는 반면에 스프레드 연산자를 사용했을 때는 각 원소가 하나씩 풀어져 printAll() 메소드를 통해 출력된 것을 볼 수 있습니다. 이처럼 스프레드 연산자를 사용하면 배열의 원소를 풀어낼 수 있습니다.
맵을 만들 때는 mapOf 함수를 사용한다는 것을 앞에서 설명했습니다. 이 때 맵의 key와 value를 구분해주는 to는 코틀린 키워드가 아닙니다. 이게 무슨 말이냐면 to는 특별한 방식으로 호출한 일반 메서드인 것입니다.
val map = mapOf(1 to "one", 2 to "two", 3 to "three")이 특별한 방식은 중위 호출이라는 개념입니다. 중위 호출은 수신 객체 뒤에 메서드 이름을 위치시키고, 그 뒤에 유일한 메서드 인자를 넣으면 됩니다.
1.to("one")
1 to "one"위는 일반적인 방식으로 함수를 호출한 것과 코드와 중위 호출을 사용한 코드입니다. 이 두 코드는 같은 의미입니다.
중위 호출을 선언하기 위해서는 함수 선언 앞에 infix 키워드를 붙여야합니다.
infix fun Any.to(other: Any) = Pair(this, other)Pair의 내용을 가지고 두 개의 변수를 즉시 초기화할 수도 있는데 이런 기능을 구조 분해 선언이라고 부릅니다.
val (number, name) = 1 to "one"문자열과 정규식
코틀린의 문자열은 자바와 동일합니다. 그렇기에 서로의 코드에서 동일하게 동작할 수 있습니다. 다만 코틀린은 다양한 확장 함수를 통해 다양한 기능을 제공해줍니다.
보통 문자열을 나눌 때는 split 메소드를 사용합니다. 자바는 split메소드로 점을 사용해 문자열을 분리할 수 없습니다. 예를 들면 “12.345-6.A”.split(”.”)의 반환 값이 빈 배열인 것입니다.
왜냐하면 split이 정규식을 구분 문자열로 받아 그 정규식에 따라 문자열을 나누기 때문입니다. 정규식에서 마침표는 모든 문자를 의미하기 때문에 나누지 않게 되어 빈 배열을 반환하게 되는 것입니다.
코틀린은 이 문제를 String과 Regex 타입으로 값을 따로 받아 위처럼 혼동하는 문제를 해결했습니다. 코틀린에서 정규식을 만드는 방법은 문자열.toRegex()를 사용하면 됩니다.
println(“12.345-6.A”.split("\\.|-".toRegex()))
println(“12.345-6.A”.split('.', '-'))
// 두개는 같은 값을 출력한다.아래는 각각 문자열 확장 함수와 정규식 각 두가지 방식으로 전체 경로명을 구분하는 코드입니다.
fun parsePath(path: String) {
val directory = path.substringBeforeLast("/")
val fullName = path.substringAfterLast("/")
val fileName = fullName.substringBeforeLast(".")
val extension = fullName.substringAfterLast(".")
println("Dir: $directory, name: $fileName, ext: $extension")
}
fun main() {
parsePath("/Users/yole/kotlin-book/chapter.adoc")
// Dir: /Users/yole/kotlin-book, name: chapter, ext: adoc
}fun parsePath(path: String) {
val regex = """(.+)/(.+)\.(.+)""".toRegex()
val matchResult = regex.matchEntire(path)
if (matchResult != null) {
val (directory, filename, extension) = matchResult.destructured
println("Dir: $directory, name: $fileName, ext: $extension")
}
}
fun main() {
parsePath("/Users/yole/kotlin-book/chapter.adoc")
// Dir: /Users/yole/kotlin-book, name: chapter, ext: adoc
}정규식을 사용하지 않아도 문자열을 파싱할 수 있다.
이 예제에서 정규식의 조건을 선언할 때 3중따옴표를 사용했습니다. 3중 따옴표는 “””<본문>”””로 사용합니다. 3중 따옴표를 사용해서 정규식을 작성하면 이스케이프를 할 때 더 간단해진다는 장점이 있습니다. 마침표를 사용할 때는 \.로 표현하는 방식을 .로 표기할 수 있게 됩니다.
3중 따옴표는 정규식을 작성할 때 뿐만 아니라 텍스트 문서를 작성할 때도 사용됩니다.
val kotlinLogo =
“””
| //
| //
|/ \
“””.trimIndent()
fun main() {
println(kotlinLogo)
// | //
// | //
// |/ \
}trimIndent는 문자열의 모든 줄에서 가장 짧은 공통 들여쓰기를 찾아 각 줄의 첫 부분에서 제거하고, 공백만으로 이뤄진 첫 번째 줄과 마지막 줄을 제거해주는 역할을 합니다. 3중 따옴표와 trimIndent를 함께 사용하면 여러 줄을 가지는 텍스트를 프로그램에 쉽게 넣을 수 있게 됩니다.
⭐️ 모든 운영체제에서 문제없는 코틀린
파일에서 줄 끝을 표현하기 위해 운영체제마다 서로 다른 문자들을 사용한다. 예를 들어 윈도우는 CRLF를, 리눅스와 맥OS는 LF를 사용한다. 사용한 운영체제와 관계없이 코틀린은 CRLF, CR, LF를 모두 줄 끝으로 취급한다.
파일 경로같은 경우에도 3중 따옴표를 사용하면 아래와 같이 표현할 수 있습니다.
"C:\\Users\\yolo\\kotlin-book"
"""C:\Users\yolo\kotlin-book"""코드를 깔끔하게 다듬기 위한 기술은?
많은 개발자들이 좋은 코드를 만들기 위한 중요한 특징 중 하나가 중복이 없는 코드라고 믿습니다. 심지어 DRY(Don't Repeat Yourself)라는 소프트웨어 개발 원칙도 있습니다.
많은 경우에 긴 메소드를 부분부분 나눠 각 부분을 재활용하는 방법으로 리펙토링을 합니다. 이런 방법은 클래스 안에 작은 메소드가 많이지고 각 메소드 사이의 관계를 파악하기 힘들어서 코드를 이해하기 어려워질 수도 있습니다.
코틀린은 로컬함수라는 더 쉬운 방법으로 코드의 중복 문제를 해결하는 리펙토링을 할 수 있습니다.
로컬 함수란?
로컬함수는 함수에서 추출한 함수를 윈래의 함수 안에 내포시키는 것입니다. 즉, 함수안에 함수를 생성하는 것입니다.
class User(val id: Int, val name: String, val address: String)
fun saveUser(user: User) {
if (user.name.isEmpty()) {
throw IllegalArgumentException(
"Can't save user ${user.id}: empty Name:)
}
if (user.address.isEmpty()) {
throw IllegalArgumentException(
"Can't save user ${user.id}: empty Address:)
}
}
fun main() {
saveUser(User(1, "", ""))
}위의 코드는 saveUser 메소드에서 이름과 주소가 비어있는지 확인하는 로직이 중복됩니다. 로컬 함수를 사용하면 검증하는 로직의 중복을 아래와 같이 줄일 수 있습니다.
class User(val id: Int, val name: String, val address: String)
fun saveUser(user: User) {
fun validate(user: User, value: String, fileName: String) {
if (value.isEmpty()) {
throw IllegalArgumentException(
"Can't save user ${user.id}: empty $fileName:)
}
validate(user, user.name, "Name")
validate(user, user.address, "Address")
}
fun main() {
saveUser(User(1, "", ""))
}saveUser 메소드 안에 validate 메소드를 생성하여 함수 내에서 검증할 수 있도록 만들었습니다. saveUser 메소드 안에서는 로컬 함수를 호출해서 각 필드를 검증합니다.
로직을 줄였지만 그래도 user의 호출이 반복되는 것을 볼 수 있습니다. 로컬 함수는 자신이 속한 바깥 함수의 모든 파라미터와 변수를 사용할 수 있다는 특징을 가지고 있어 바깥 함수와 내부 함수의 중복되는 인자를 줄일 수도 있습니다.
class User(val id: Int, val name: String, val address: String)
fun saveUser(user: User) {
fun validate(value: String, fileName: String) {
if (value.isEmpty()) {
throw IllegalArgumentException(
"Can't save user ${user.id}: empty $fileName:)
}
validate(user.name, "Name")
validate(user.address, "Address")
}
fun main() {
saveUser(User(1, "", ""))
}마무리입니다!
이번 글에서는 함수를 코틀린스럽게 사용하는 방법과 코틀린스러운 함수 리펙토링 방식에 대해 정리해봤습니다.
이 책을 읽으면서 확장 함수와 확장 프로퍼티라는 개념에 대해 알게 되었습니다. 저는 보통 코드를 작성할 때는 파라미터가 없는 함수를 사용했었는데 확장 함수라는 표현법을 보고 확장 함수로 표현해보면 훨씬 코드의 가독성을 올릴 수 있겠구나를 느꼈습니다.
또한 함수 내에서 검증과 같은 로직을 작성할 때에는 중복되는 코드를 if 또는 else로 검증했었습니다. 이런 점도 로컬 함수를 사용하면 어떨까라는 생각을 하며 코틀린에는 편리한 기능이 많이 있다고 느끼게 된 단원이였던것 같습니다.
다음은 객체지향의 표현법인 클래스, 객체, 인터페이스에 대한 정리글로 돌아오겠습니다.
읽어주셔서 감사합니다!🙂↕️
