
안녕하세요!
2월의 첫 글도 코틀린 개념 정리와 함께 돌아온 개발자 꿈나무 김조현입니다.
이번 글에서는 4장의 내용인 클래스, 객체, 인터페이스에 대해 정리해볼 것입니다.
코틀린에서 인터페이스란?
코틀린 인터페이스 안에는 추상 메서드뿐 아니라 구현이 있는 메서드도 정의할 수 있습니다. 다만 주의할 점은 인터페이스에는 아무런 상태도 들어갈 수 없습니다.
인터페이스를 정의할 때는 interface 키워드를 사용합니다.
interface Clickable {
fun click()
}인터페이스를 상속받는 방법 다음과 같습니다.
- 클래스 선언에서 클래스 이름 뒤에 콜론을 표시한다.
- 그 뒤에 인터페이스 이름을 넣는다.
- 인터페이스에 정의된 추상 메소드를 구현해야한다.
class Button : Clickable {
override fun click() = println("I was clicked")
}
fun main() {
Button().click()
// I was clicked
}코틀린에서 상속이나 구성은 모두 클래스 이름 뒤에 콜론을 붙이고 인터페이스나 클래스 이름을 적는 방식을 사용합니다. 인터페이스를 원하는 만큼 구현할 수 있지만 오직 하나만 확장할 수 있습니다.
상위 클래스나 상위 인터페이스에 있는 프로퍼티나 메소드를 오버라이드할 때는 override 변경자를 사용합니다.
⭐️ 자바와 코틀린의 차이점
@Override 키워드를 선택적으로 사용하는 자바와 달리 코틀린은 override를 반드시 명시해야한다.
override 변경자는 실수로 상위 클래스의 메서드를 오버라이드하는 경우를 방지할 수 있습니다. 실수로 상위 클래스에 정의된 메서드와 같은 메서드를 정의한 경우 해당 메서드를 override로 표시하거나 메서드 이름을 변경하지 않으면 컴파일이 되지 않습니다.
인터페이스의 기능 중 하나는 디폴트 구현을 제공합니다.
interface Clickable {
fun click()
fun showOff() = println("I'm clickable!")
}디폴트 구현을 정의할 경우 새로운 동작을 정의할 수도 있고, 정의를 생략해서 디폴트 구현을 사용할 수도 있습니다.
만약 두 인터페이스를 함께 구현하고 두 인터페이스 모두 디폴트 구현이 존재하며 이름도 같은 메소드가 정의되어 있다면 오버라이드했을 때 어느 쪽도 선택되지 않고 오류를 반환하게 됩니다.
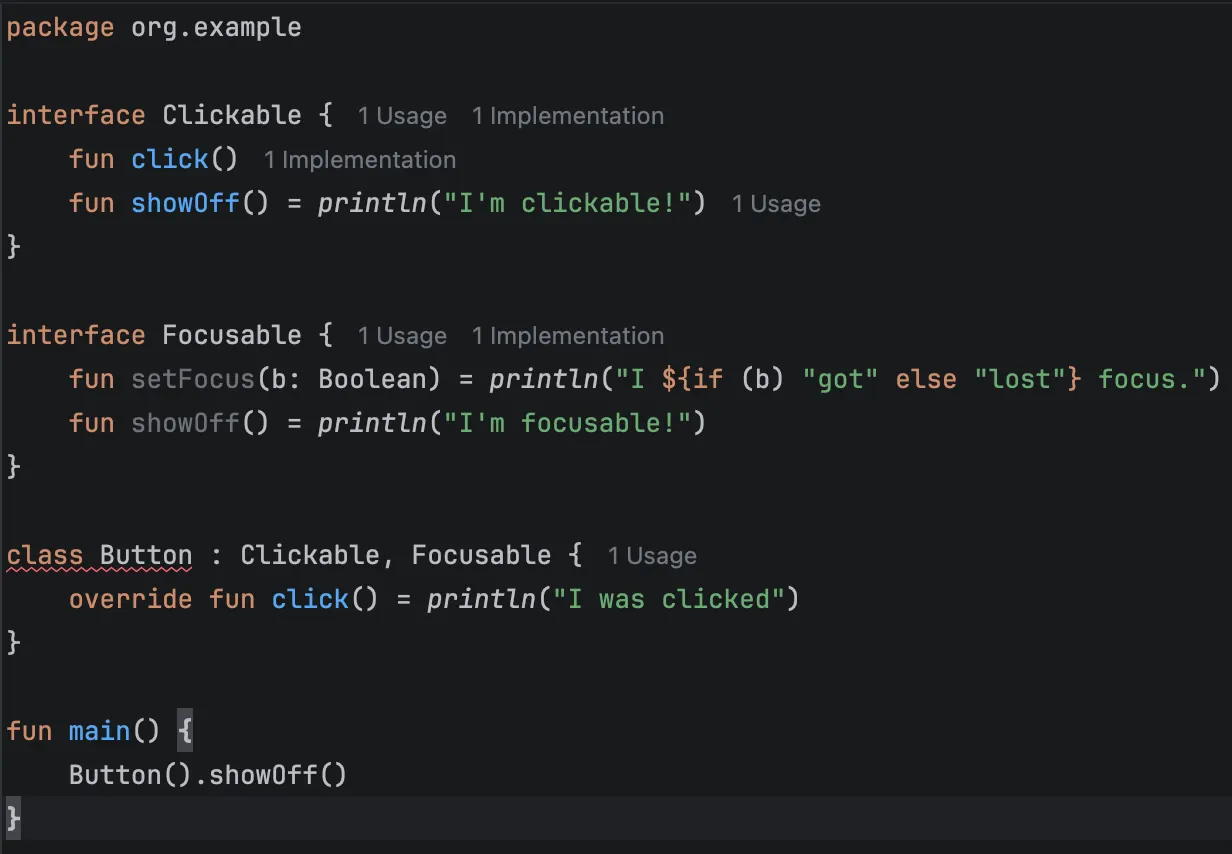

오류를 해결하기 위해서는 하위 클래스에서 명시적으로 새로운 구현을 제공해야 합니다. 상위 타입의 이름을 홀화살괄호(<>) 사이에 넣은 super를 사용하면 어떤 상위 타입의 멤버 메서드를 호출할지 정할 수 있습니다.
interface Focusable {
fun setFocus(b: Boolean) = println("I ${if (b) "got" else "lost"} focus.")
fun showOff() = println("I'm focusable!")
}
class Button : Clickable, Focusable {
override fun click() = println("I was clicked")
override fun showOff() {
super<Clickable>.showOff()
}
}
fun main() {
val button = Button()
button.click()
// I was clicked
button.setFocus(true)
// I got focus.
button.showOff()
// I'm clickable!
}위의 코드는 Clickable의 showOff()를 호출하게 됩니다.
만약 디폴트 메소드 구현이 되어있는 코틀린 인터페이스를 자바 클래스에서 상속해 구현하고 싶다면 코틀린에서 메서드 본문을 제공하는 메서드를 포함하는 모든 메서드에 대한 본문을 작성해야합니다. 자바에서는 디폰트 메소드를 제공하지 않기 때문입니다.
class JavaButton implements Clickable {
@Override
public void click() {
System.out.println("I was clicked");
}
@Override
public void showOff() {
System.out.println("I'm showing off");
}
}open, final, abstract 변경자에 대하여
코틀린에서 모든 클래스와 메서드는 기본적으로 final입니다. 이는 코틀린의 코드가 기본적으로 다른 클래스가 상속할 수 없으며, 오버라이드도 할 수 없다는 의미입니다.
반대로 자바는 final을 명시적으로 지정하지 않는 한 모든 클래스를 다른 클래스가 상속할 수 있고, 모든 메서드를 하위 클래스에서 오버라이드 할 수 있습니다.
코틀린에서 이런 자바의 방법을 사용하지 않은 이유는 취약한 기반 클래스라는 문제를 일으키기 떄문입니다.
취약한 기반 클래스는 기반 클래스 구현을 변경함으로써 하위 클래스가 잘못된 동작을 하게 되는 경우를 뜻합니다. 즉, 기반 클래스를 변경하는 경우 하위 클래스의 동작이 예기치 않게 바뀔 수도 있다는 것입니다.
또한 기본 상태를 final로 함으로써 얻을 수 있는 큰 이점은 다양한 경우에 스마트 캐스트가 가능합니다.
스마트 캐스트는 타입 검사 뒤에 변경될 수 없는 변수에만 적용할 수 있기 때문에 프로퍼티가 final이 아니라면 객체의 타입이 바뀔 수도 있기 때문에 스마트 캐스트의 요구사항을 깰 수도 있습니다.
기본값이 final인 코틀린에서 어떤 클래스의 상속을 허용하려면 open 변경자를 붙여야 합니다.클래스뿐만 아니라 메소드나 프로퍼티 앞에도 open 변경자를 붙여야 합니다.
open class RichButton : Clickable {
fun disable() { /* ... */ }
open fun animate() { /* ... */ }
override fun click() { /* ... */ }
}
class ThemeButton : RichButton() {
override fun animate() { /* ... */ }
override fun click() { /* ... */ }
override fun showOff() { /* ... */ }
}disable 메소드는 키워드를 붙이지 않았기에 기본값이 final이 적용됩니다. 그래서 disable 메소드는 오버라이드할 수 없습니다.
animate 메소드는 open을 사용해 명시적으로 공개했기 때문에 오버라이드할 수 있습니다.
click 메소드도 키워드를 붙이지 않았지만 오버라이드 한 메소드는 명시적으로 기본값으로 열려있기 때문에 오버라이드 할 수 있으며, showOff 메소드는 RichButton이 오버라이드하지 않았지만 Clickable에서 오버라이드 할 수 있습니다.
open class RichButton : Clickable {
final override fun click() { /* ... */ }
}click과 showOff처럼 기반 클래스나 인터페이스의 멤버를 오버라이드한 경우에는 기본적으로 open으로 간주됩니다. 그렇기 때문에 오버라이드 된 메소드에 대해 오버라이드를 막기 위해 final을 붙이는 것은 쓸데없는 중복이 아니다.
abstract를 사용해 추상클래스를 선언할 수 있습니다. 추상 클래스는 인스턴스화할 수 없다는 특징이 있습니다. 추상 멤버는 항상 열려있기 때문에 open 변경자를 명시할 필요가 없습니다. 이는 인터페이스 멤버 앞에 open을 명시하지 않는 것과 같은 개념입니다.
abstract class Animate {
abstract val animationSpeed: Double
val keyframes: Int = 20
open val frames: Int = 60
abstract fun animate()
open fun stopAnimating() { /* ... */ }
fun animateTwice() { /* ... */ }
}추상 프로퍼티와 추상 함수는 하위 클래스에서 반드시 제공해야합니다. 추상 클래스의 프로퍼티와 함수는 기본적으로 열려있지 않기 때문에 open을 사용해 열 수 있습니다.
가시성 변경자란?
가시성 변경자는 코드 기반에 있는 선언에 대한 클래스 외부 접근을 제어하는 기능입니다. 가시성 변경자는 public, protected, private 변경자를 제공하며 각각 기능들을 가지고 있으며 코틀린에서 기본 선언자는 public입니다.
- public 선언은 누구나 볼 수 있다.
- protected 선언은 하위 클래스에서만 볼 수 있다.
- private 선언은 그 선언이 포함된 클래스 안에서만 볼 수 있다.
자바의 기본 가시성인 package-private라는 가시성 개념이 코틀린에는 없다.
모듈 안으로만 한정된 가시성을 위해 코틀린은 internal이라는 가시성을 제공하며 internal 가시성의 장점은 모듈 구현에 대해 진정한 캡슐화를 제공합니다.
모듈은 함께 컴파일되는 코틀린 파일의 집합을 의미합니다.
internal open class TalkativeButton {
private fun yell() = println("Hey!")
protected fun whisper() = println("Let's talk!")
}
fun TalkativeButton.giveSpeech() {
yell()
whisper()
}각 객체나 클래스를 참조하기 위해서는 가시성 변경자를 잘 따라야합니다.
어떤 클래스의 기반 타입 목록에 들어있는 타입이나 제네릭 클래스의 타입 파라미터에 들어있는 타입의 가시성은 그 클래스 자신의 가시성과 같거나 더 높아야하고, 메서드의 시그니처에 사용된 모든 타입의 가시성은 그 메서드의 가시성과 같거나 더 높아야합니다.
즉, giveSpeech는 public 함수로 가시성이 더 낮은 internal 타입인 TalkativeButton을 참조할 수 없습니다. 그리고 private와 protected 메소드도 public에서 호출할 수 없어 오류가 발생합니다.
이 컴파일 오류를 해결하기 위해서는 giveSpeech 확장 함수의 가시성을 internal로 바꾸거나 TalkativeButton 클래스의 가시성을 public으로 바꾸는 식으로 가시성을 맞춰줘야 합니다.
⭐️ 자바와 코틀린의 차이점
- 자바에서는 같은 패키지 안에서 protected 멤버에 접근할 수 있지만, 코틀린에서는 그 클래스나 그 클래스를 상속한 클래스 안에서만 접근할 수 있다.
- 자바와 다르게 코틀린에서는 외부 클래스가 내부 클래스나 내포된 클래스의 private에 접근할 수 없다.
코틀린에서 protected 멤버의 접근이 제한되기 때문에 위 코드에서 whisper 메소드가 호출될 수 없는 것입니다.
중첩 클래스와 내포 클래스는?
중첩 클래스란 클래스 안에 다른 클래스를 선언하는 것입니다.
자바처럼 코틀린에서도 클래스 안에 다른 클래스를 선언할 수 있습니다. 하지만 자바와 달리 내포 클래스는 명시적으로 요청하지 않는 한 바깥쪽 클래스 인스턴스에 대한 접근 권한이 없습니다.
자바는 기본적으로 클래스 안에 클래스를 생성하면 내부 클래스로 선언하기 때문에 바깥쪽 참조를 끊기 위해서는 static으로 선언해야합니다.
코틀린의 기본 중첩 클래스는 자바의 static 내포 클래스와 같습니다.
class Outer {
private val bar: Int = 1
class Nested {
fun foo() = bar
}
}
fun main() {
println(Outer.Nested().foo())
// 오류
}위 코드는 오류를 반환합니다. 이유는 위에서 설명한 것처럼 코틀린에서 중첩 클래스의 경우는 바깥 필드에 있는 멤버에 접근할 수 없기 때문에 bar 값을 가져오지 못하는 것입니다.
바깥쪽 클래스에 대한 참조를 포함하게 만들려면 내부의 클래스 앞에 inner 변경자를 붙이면 됩니다.
class Outer {
private val bar: Int = 1
inner class Nested {
fun foo() = bar
}
}
fun main() {
println(Outer().Nested().foo())
// 1
}책에는 나오지 않지만 개인적으로 이 두 코드를 비교해보면서 "Outer를 선언할 때 괄호의 유무 차이가 생기는 이유는 뭘까?" 라는 의문이 들었습니다.
inner가 없는 일반 중첩 클래스의 경우는 바깥 클래스를 참조하지 않기 때문에 객체를 만드는 것이 아니라 클래스의 경로를 지정한 것입니다. 객체를 선언한 것이 아니기 때문에 괄호 없이 클래스명을 앞에 명시해준 것입니다.
반대로 내포 클래스는 inner class가 Outer 클래스에 소속되어 있는 클래스이기 때문에 Nested를 접근하기 위해서는 Outer 객체를 선언해줘야하기 때문에 괄호가 붙는 것입니다.
바깥쪽 클래스의 인스턴스를 가리키는 참조 방법은 내부 클래스 안에서 바깥쪽 클래스 이름을 this@Outer과 같이 사용하면 됩니다.
class Outer {
inner class Inner {
fun getOuterReference(): Outer = this@Outer
}
}봉인된 클래스란?
interface Expr
class Num(val value: Int) : Expr
class Sum(val left: Expr, val right: Expr): Expr
fun eval(e: Expr): Int {
when (e) {
is Num -> e.value
is Sum -> eval(e.right) + eval(e.left)
else ->
throw IllegalArgumentException("Unknown expression")
}
}앞에서도 사용했던 이 코드에서는 when을 사용하기 위해서는 Num, Sum 외의 객체를 처리가히 위해 else 분기를 반드시 넣어줘야합니다.
왜냐하면 컴파일러가 타입을 검사할 때 하위 객체가 얼마나 있는지 모르기 때문에 반드시 else를 강요하는 것입니다. 하지만 else를 사용하면 새로운 클래스가 생겼을 때 새로운 클래스에 대해 분기를 처리했는지 제대로 검사할 수 없다는 단점이 있습니다.
이를 해결하기 위해서는 sealed 변경자를 사용해 봉인된 클래스를 사용하면 됩니다.
sealed클래스는 직접적인 하위 패키지들은 반드시 컴파일 시점에 알려야하며, 봉인된 클래스가 정의된 패키지와 같은 패키지에 속해야하며, 모든 하위 클래스가 같은 모듈에 위치해야 한다.
이 말은 위에서 말했던 컴파일러의 타입 검사를 명확하게 해줄 수 있게 도와주는 것입니다. 그렇기 때문에 sealed 클래스를 사용하면 when에서 sealed 클래스의 모든 하위 클래스를 처리한다면 디폴트 분기를 작성하지 않아도 됩니다.
또한 sealed 변경자는 클래스가 추상 클래스임을 명시하기에 봉인된 클래스에 abstract를 붙일 필요가 없습니다.
봉인된 클래스와 마찬가지로 봉인된 인터페이스도 동일한 규칙을 따릅니다.
sealed interface Toggleable {
fun toggle()
}
class LightSwitch: Toggleable {
override fun toggle() = println("Lights!")
}
class Camera: Toggleable {
override fun toggle() = println("Camera!")
}뻔하지 않은 생성자나 프로퍼티를 갖는 클래스 선언은?
class User(val nickname: String)2장에서 클래스를 선언할 때 위와 같이 선언했습니다. 클래스 이름 뒤에 오는 괄호로 둘러싸인 코드를 주 생성자라고 합니다.
public class User {
private final String nickname;
public User(String nickname) {
this.nickname = nickname;
}
public String getNickname() {
return nickname;
}
}자바처럼 생성자를 따로 선언하지 않고 코틀린에서 클래스의 선언에서 중괄호를 갖지 않고 val 선언만 존재할 수 있는 이유는 무엇일까요?
코틀린에서 클래스를 생성할 때 constructor, init 키워드를 사용합니다.
constructor는 주 생성자 또는 부 생성자를 정의할 때 사용합니다.
init은 초기화 블록을 시작하는 키워드로 초기화 블록에는 클래스의 객체가 만들어질 때 실행될 초기화 코드를 넣습니다.
class User constructor(_nickname: String) {
val nickname: String
init {
nickname = _nickname
}
}클래스 코드를 constructor와 init 블록을 사용해서 생성합니다. 밑줄(_)은 프로퍼티와 생성자 파라미터를 구분해주는 역할을 하며, 밑줄 대신 this.nickname = nickname을 사용해도 됩니다.
이 코드를 맨 앞의 코드와 같이 줄일 수 있는 이유 중 하나는 nickname 프로퍼티를 초기화하는 코드를 프로퍼티 선언에 포함시킬 수 있기 때문에 초기화 코드를 초기화 블록에 넣지 않아도 되는 것입니다.
또한 주 생성자 앞에 별다른 어노테이션이나 가시성 변경자가 없다면 constructor를 생략해도 되기 때문에 위 코드는 constructor, init 블록을 생략할 수 있어 val 키워드만 사용하여 클래스를 선언할 수 있게 됩니다.
생성자 파라미터에도 기본값을 정의할 수 있습니다.
클래스의 인스턴스를 만들 때는 자바와 다르게 new와 같은 추가 키워드 없이 생성자를 직접 호출하면 됩니다.
class User(val nickname: String, val isSubscribed: Boolean = true)
fun main() {
val person1 = User("김조현")
println(person1.nickname)
// 김조현
}만약 기반 클래스의 생성자가 인자를 받아야 한다면 클래스의 주 생성자에서 기반 생성자를 호출해야합니다. 기반 클래스를 초기화하려면 기반 클래스 이름 뒤에 괄호를 치고 생성자 인자를 넘기면 됩니다.
open class User(val nickname: String) { /* ... */ }
class SocialUser(nickname: String) : User(nickname) { /* ... */ }그러면 생성자를 선언하지 않는다면 기반 클래스 이름 뒤에 괄호를 생략해도 되는 것일까요?
정답은 괄호를 생략할 수 없습니다.
만약 별도의 생성자를 정의하지 않으면 컴파일러가 자동으로 아무 일도 하지 않는 인자가 없는 디폴트 생성자를 만들어줍니다. 생성자가 없더라도 컴파일러가 생성한 디폴트 생성자가 있기 때문에 상속할 때는 빈 괄호가 필요합니다.
그치만 인터페이스는 생성자가 없기 때문에 이름 뒤에 괄호를 붙이지 않습니다.
open class Button
class RadioButton: Button()어떤 클래스를 클래스 외부에서 인스턴스화하지 못하게 막고 싶다면 생성자를 private로 만들면 된다.
이런 기능이 필요한 이유는 나중에 설명할 팩토리 메소드를 구현하기 위해서 입니다.
class Secretive private constructure(private val agentName: String) {}부 생성자도 constructor로 시작하며, 필요에 따라 얼마든지 선언해도 됩니다. 상속을 했을 때는 super() 키워드를 통해 각각에 대응하는 상위 클래스 생성자를 호출합니다.
open class Downloader {
constructor(url: String?) { /* ... */ }
constructor(uri: URI?) { /* ... */ }
}
class MyDownloader: Downloader {
constructor(url: String?) : super(url) { /* ... */ }
constructor(uri: URI?) : super(uri) { /* ... */ }
}this()를 통해 클래스 자신의 다른 생성자를 호출할 수 있습니다. 아래의 코드에서 url 생성자를 호출하면 uri를 받는 자신을 호출하는 동작을 하며 다른 생성자에게 생성을 위임합니다.
클래스에 주 생성자가 없다면 모든 부 생성자는 반드시 상위 클래스를 초기화하거나 다른 생성자에게 생성을 위임해야 합니다.
class MyDownloader: Downloader {
constructor(url: String?) : this(URI(url))
constructor(uri: URI?) : super(uri)
}인터페이스에 선언된 프로퍼티 구현
interface User {
val nickname: String
}위의 User 인터페이스를 구현하는 클래스는 인터페이스의 프로퍼티인 nickname의 값을 얻을 수 있는 방법을 제공해야합니다.
class PrivateUser(override val nickname: String) : User
class SubscribingUser(val email: String) : User {
override val nickname: String
get() = email.substringBefore('@')
}
class SocialUser(val accountId: Int) : User {
override val nickname = getFacebookName(accountId)
}
fun getNameFromSocialNetwork(accountId: Int) = "kodee$accountId"
fun main() {
println(PrivateUser("kodee").nickname)
// kodee
println(SubscribingUser("test@kotlinlang.org").nickname)
// test
println(SocialUser(123).nickname)
// kodee123
}프로퍼티를 설정하는 방법은 값을 저장하는 프로퍼티와 커스텀 접근자에서 매번 값을 계산하는 프로퍼티 2가지 유형이 있습니다.
SocialUser는 초기화 식으로 nickname 값을 초기화하여 실제 필드에 저장되는 첫 번째 유형입니다.
SubscribingUser는 nickname 프로퍼티를 커스텀 게터를 통해 필드에 값을 저장하지 않고 매번 계산해 반환하는 두 번째 유형입니다.
interface EmailUser {
val email: String
val nickname: String
get() = email.substringBefore('@')
}인터페이스는 추상 프로퍼티 뿐만 아니라 게터와 세터가 있는 프로퍼티를 선언할 수도 있습니다.
이 인터페이스에 대해 구현하는 클래스는 추상 프로퍼티인 email을 반드시 오버라이드해야 하고, nickname은 그대로 사용하거나 상속해서 사용할 수 있습니다.
⭐️ 언제 함수 대신 프로퍼티를 사용할까?
- 예외를 던지지 않을 때
- 계산 비용이 적게 들 때
- 객체 상태가 바뀌지 않을 때
접근자의 가시성 변경
get이나 set앞에 private를 선언해서 접근자의 가시성을 변경할 수 있습니다.
class LengthCounter {
var counter: Int = 0
private set
fun addWord(word: String) {
counter += word.length
}
}
fun main() {
val lengthCounter = LengthCounter()
lengthCounter.addWord("Hi!")
println(lengthCounter.counter)
// 3
// lengthCounter.counter = 0
// 오류가 발생한다.
}이 코드에서 counter 프로퍼티는 클래스 밖에서 값을 변경할 수 없고, addWord를 통해서만 값을 변경할 수 있습니다.
만약 값을 불러와 변경하려고 한다면 오류가 발생합니다.
데이터 클래스란?
코틀린의 모든 클래스는 toString, equals, hashCode를 오버라이드 해야합니다. 그치만 이 모든 메소드를 오버라이드하기엔 무척 번거로울테니 이 문제를 해결해줄 수 있는 것이 데이터 클래스입니다.
위의 세 가지 메소드는 무슨 메소드인지? 데이터 클래스가 무엇인지에 대해서는 아래에서 더 자세하게 설명하겠습니다.
toString()는?
toString()은 문자열 표현을 제공하는 메소드입니다.
기본 제공되는 객체의 문자열 표현은 <클래스 이름>@<객체의 주소>와 같이 표현됩니다. 하지만 이런 표현 방법은 정보를 알기 쉽지 않습니다.
이는 유용하지 않기 때문에 toString 메소드를 오버라이드 해서 기본 구현을 바꾸는 것입니다.
class Customer(val name: String, val postalCode: Int) {
override fun toString() = "Customer(name=$name, postalCode=$postalCode)"
}
fun main() {
val customer1 = Customer("Alice", 342562)
println(customer1)
// Customer(name=Alice, postalCode=342562)
}equals()는?
equals()는 객체의 동등성을 검사하는 메소드입니다.
fun main() {
val customer1 = Customer("Alice", 342562)
val customer2 = Customer("Alice", 342562)
println(customer1 == customer2)
// false
}두 객체의 이름과 코드는 같지만 == 연산자를 사용해 비교했을 때는 false가 반환됩니다. 왜 그런것일까요?
이를 위해서는 먼저 == 연산자에 대해 알아봐야 합니다.
자바에서 == 연산자는 참조 비교(주소 비교)를 하는 연산자이고, 동일성(값 비교)을 비교하기 위해서는 equals()를 사용해야합니다.
반면 코틀린에서 == 연산자는 두 객체를 비교하는 방법을 사용하여 값을 비교하려고 합니다. 이 때 == 연산자는 equals를 호출하기 때문에 기본 equals는 주소값을 비교하려고 합니다.
이렇게 주소값만 비교하면 값을 비교하지 못해 같은 내용의 객체더라도 위의 코드처럼 false를 반환하는 것입니다.
참고로 코틀린의 === 연산자는 값을 비교하지 않고 주소만 비교하는 참조 비교하는 연산자입니다. 그러면 == 와 ===는 같은 의미가 아닌가요?
예, 오버라이드하기 전에는 결과적으로 같지만 본질적으로는 다른 의미입니다. 하지만 위처럼 객체 차원에서 비교를 위해서는 값 비교도 함께 이루어져야하는데 이 때 === 연산자는 오버라이드 할 수 없는 동작입니다.
그렇기 때문에 값까지 비교를 하기 위해서는 equals 메소드를 오버라이드하여 == 연산자의 로직을 변경해줘야 하는 것입니다.
class Customer(val name: String, val postalCode: Int) {
override fun equals(other: Any?): Boolean {
if (other == null || other !is Customer)
return false
return name == other.name && postalCode == other.postalCode
}
override fun toString() = "Customer(name=$name, postalCode=$postalCode)"
}
fun main() {
val customer1 = Customer("Alice", 342562)
val customer2 = Customer("Alice", 342562)
println(customer1 == customer2)
// true
}hashCode()는?
하지만 Customer클래스로 더 복잡한 작업을 수행하다보면 제대로 동작하지 않는 경우가 있다고 합니다. 이 때는 아마도 hashCode 정의를 빠뜨려서 그런 것입니다.
자바에서는 equals를 정의할 때 반드시 hashCode도 함께 정의해야 합니다.
fun main() {
val processed = hashSetOf(Customer("김조현", 1234))
println(processed.contains(Customer("김조현", 1234)))
// false
}hashCode는 “equals가 true를 반환하는 두 객체는 반드시 같은 hashCode()를 반환해야 한다.” 라는 규정이 있는데 위의 Customer는 hashCode를 정의하지 않아 이를 어기고 있어 false가 반환되는 것입니다.
HashSet은 객체의 해시 코드를 비교하고 해시 코드가 같은 경우에만 값을 비교합니다. 즉, 해시 코드가 다르기 때문에 값을 비교하는 연산까지 가지도 못한 것입니다.
올바르게 두 해시 값을 비교하기 위해서는 hashCode를 재정의해야합니다.
class Customer(val name: String, val postalCode: Int) {
/* ... */
override fun hashCode(): Int = name.hashCode() * 31 + postalCode
}데이터 클래스가 그래서 무엇인가?
어떤 클래스가 데이터를 저정하는 역할만을 수행한다면 toString, equals, hashCode를 반드시 오버라이드 해야하는데, 이 메소드들을 자동으로 만들어 주는 기능을 가진 클래스가 데이터 클래스입니다.
데이터 클래스를 선언하는 방법은 클래스 앞에 data 변경자를 붙이면 됩니다.
data class Customer(val name: String, val postalCode: Int)
fun main() {
val c1 = Customer("Sam", 11521)
val c2 = Customer("Mart", 15500)
val c3 = Customer("Sam", 11521)
println(c1)
// Customer(name=Sam, postalCode=11521)
println(c1 == c2)
// false
println(c1 == c3)
// true
println(c1.hashCode())
// 2580770
println(c3.hashCode())
// 2580770
}copy()
데이터 클래스 인스턴스는 불변성이 필수적입니다. 그렇지만 데이터 클래스의 객체를 변경해야할 일도 생길 수도 있습니다.
이런 상황일 때 불변성을 깨지 않게 도와주는 메소드가 copy() 입니다.
copy()는 객체를 복사하면서 일부 프로퍼티를 바꿀 수 있게 해주는 메소드입니다. 이를 사용하면 객체를 메모리에서 직접 바꾸는 대신 복사본을 만들고, 복사본은 원본가 다른 생명주기를 가지기 때문에 원본을 참조하는 다른 부분에 전혀 영향을 미치지 않습니다.
클래스에 직접 구현한다면 아래와 같이 구현할 수 있습니다. 하지만 데이터 클래스로 선언하다면 자동으로 제공해주는 메소드 입니다.
class Customer(val name: String, val postalCode: Int) {
/* ... */
fun copy(name: String = this.name,
postalCode: Int = this.postalCode) =
Customer(name, postalCode)
}직접 활용하면 이렇게 객체의 원본을 해치지 않으면서 변경할 수 있습니다.
fun main() {
val kim = Customer("김조현", 4122)
println(kim.copy(postalCode = 2291))
// Customer(name=김조현, postalCode=2291)
}자바에는 레코드라는 코틀린의 데이터 클래스와 비슷한 개념이 있습니다. 하지만 copy와 같은 다른 편의 메소드가 없으며, 더 많은 구조적 제약이 있습니다.
⭐️ 레코드의 구조적 제약
- 모든 프로퍼티가 private이며 final이어야 한다.
- 레코드는 상위 클래스를 확장할 수 없다.
- 클래스 본문 안에서 다른 프로퍼티를 정의할 수 없다.
자바와 상호운용성을 위해 코틀린 data class에 @JvmRecord 어노테이션을 추가하여 사용하고, 이 경우 데이터 클래스를 레코드와 똑같은 제약 사항을 지키도록 수정해야 합니다.
by 키워드 사용
대규모 객체지향 시스템을 설계할 떄 시스템을 취약하게 만드는 문제는 보통 구현 상속에 의해 발생한다.
이는 상위 클래스가 변경되면 그 과정에서 하위 클래스가 정상적으로 동작하지 못하게 되는 문제다.
기본값을 final로 취급하고 상속 클래스의 경우에는 open 변경자를 사용하는 등 하위 클래스와 호환성이 깨지지 않게 조심하고 있지만, 상속을 허용하지 않는 클래스에게 새로운 동작을 추가해야할 때가 있다.
이럴 때 사용하는 방법이 데코레이터 패턴이다. 이 패턴의 핵심은 기존 클래스와 같은 것은 데코레이터가 제공하고 새로 정의해야 하는 기능은 데코레이터의 메소드로 새로 정의하는 것이다.
class DelegatingCollections<T> : Collection<T> {
private val innerList = arrayListOf<T>()
override val size: Int get() = innerList.size
override fun isEmpty(): Boolean = innerList.isEmpty()
override fun contains(element: T): Boolean = innerList.contains(element)
override fun iterator(): Iterator<T> = innerList.iterator()
override fun containsAll(elements: Collection<T>): Boolean =
innerList.containsAll(element)
}이런 방법은 이처럼 준비 코드가 상당히 많이 필요하다는 단점이 있다.
class DelegatingCollection<T>(
innerList: Collection<T> = mutableListOf<T>()
) : Collection<T> by innerList그치만 코틀린은 by 키워드를 통해 간단하게 데코레이터 패턴을 사용할 수 있다.
기본 구현으로 충분한 메소드는 오버라이드를 할 필요가 없다. 하지만 재정의를 하고싶다면 override를 사용하여 위임하지 않고 새로운 구현을 할 수도 있다.
object 키워드
object 키워드를 사용하는 상황은 다음과 같습니다.
- 객체 선언 : 싱글톤을 정의하는 방법
- 동반 객체 : 어떤 클래스와 관련이 있지만 그 클래스의 객체가 필요하지 않은 메서드와 팩토리 메소드를 담을 때 사용
- 객체 식 : 자바의 익명 내부 클래스 대신 사용
object 키워드는 모든 경우 클래스를 정의하는 동시에 인스턴스를 생성한다는 공통점이 있습니다.
각 상황에서 object 키워드가 어떻게 사용되는지 알아보겠습니다.
싱글톤 쉽게 만들기?
싱글톤이란 설명하면 어떤 클래스의 인스턴스가 오직 하나만 존재하도록 보장하고, 어디서든 그 인스턴스에 접근할 수 있도록 하는 디자인 패턴입니다.
코틀린에서는 객체 선언을 활용해서 싱글톤을 만들 수 있습니다.
객체 선언은 object 키워드로 시작하고, 클래스 정의와 그 클래스의 인스턴스를 만들어 변수에 저장하는 모든 작업을 한 문장으로 처리합니다. 클래스와 마찬가지로 객체 선언 안에도 프로퍼티, 메소드, 초기화 블록 등이 들어갈 수 있지만 생성자를 쓸 수 없습니다.
object Payroll {
val allEmployees = arrayListOf<Person>()
fun calculateSalary() {
for (person in allEmployees) {
/* ... */
}
}
}
fun main() {
Payroll.allEmployees.add(Person(/* ... */))
Payroll.calculateSalary()
}변수와 마찬가지로 객체 선언에 사용한 이름 뒤에 마침표를 붙이면 메소드나 프로퍼티에 접근할 수 있고, 객체 선언도 클래스나 인스턴스를 상속할 수 있습니다.
또한 클래스 안에서 객체를 선언하여 내포된 객체를 선언할 수 있습니다.
data class Person(val name: String) {
object NameComparator: Comparator<Person> {
override fun compare(p1: Person, p2: Person): Int =
p1.name.compareTo(p2.name)
}
}
fun main() {
val persons = listOf(Person("Bob"), Person("Alice"))
println(persons.sortedWith(Person.NameComparator))
// [Person(name="Alice), Person(name="Bob")]
}동반 객체란?
클래스의 인스턴스와 관계없이 호출해야 하지만, 클래스 내부 정보에 접근해야 하는 함수가 필요할 때도 클래스에 내포된 객체 선언의 멤버 함수로 정의하여 사용할 수도 있습니다.
companion이라는 표시를 하여 객체 선언을 하면 객체 멤버에 접근할 때 직접 사용할 수 있습니다.
class myClass {
companion object {
fun callMe() {
println("Companion object called")
}
}
}
fun main() {
MyClass.callMe()
// Companion object called
}주의해야할 점은 동반 객체가 자신에 대응하는 클래스에 속하기 때문에 해당 클래스의 인스턴스는 동반 객체의 멤버에 접근할 수 없습니다.
팩토리 메소드란?
class User private constructor(val nickname: String) {
companion object {
fun newSubscribingUser(email: String) =
User(email.substringBefore('@'))
fun newSocialUser(accountId: Int) =
User(getNameFromSocialNetwork(accountId))
}
}
fun main() {
val subscribingUser = User.newSubscribingUser("bob@gmail.com")
val socialUser = User.newSocialUser(4)
println(subscribingUser.nickname)
// bob
}앞에서 배운 주 생성자 비공개와 객체 선언을 활용해서 팩토리 메소드를 만들 수 있습니다.
팩토리 메소드는 주 생성자를 private로 만들어 클래스 밖에서 선언할 수 없도록 합니다. 팩토리 메소드를 사용할 때는 클래스 이름을 사용해 동반 객체의 메소드를 호출하여 사용합니다.
팩토리 메소드는 목적에 따라 팩토리 메소드의 이름을 정할 수 있고, 팩토리 메소드가 선언된 클래스의 하위 클래스 객체를 반환할 수도 있다는 장점이 있습니다.
동반 객체는 클래스 안에 정의된 일반 객체입니다. 따라서 다른 객체 선언처럼 이름을 붙이거나, 인터페이스를 상속하거나, 객체 안에 확장 함수와 프로퍼티를 정의할 수 있습니다.
클래스의 이름을 통해 동반 객체에 속한 멤버를 참조할 수 있습니다. 이름을 지어주지 않는다면 자동으로 Companion으로 지정됩니다.
class Person(val firstName: String, val lastName: String) {
companion object { }
}
fun Person.Companion.fromJSON(json: String): Person {
/* ... */
}
val p = Person.fromJSON(json)동반 객체에서도 확장 함수를 정의할 수 있습니다. 다른 보통 확장 함수와 마찬가지로 실제 멤버 변수가 아니기 때문에 동반 객체에 대한 확장 함수를 작성하려면 원래 클래스에 동반 객체를 꼭 선언해야 한다는 점을 주의해야 합니다.
객체 식은?
object 키워드는 익명 객체를 정의할 때도 사용합니다. 익명 객체는 자바의 익명 내부 클래스를 대신합니다.
익명 내부 클래스는 자바에서 이름이 없는 일회용 내부 클래스입니다. 클래스의 선언과 객체 생성을 동시에 처리하며, 주로 인터페이스나 추상 클래스의 메서드를 오버라이드하여 단 한 번만 사용되는 객체를 만들 때 사용합니다.
interface MouseListener {
fun onEnter()
fun onClick()
}
fun main() {
Button(object : MouseListener {
override fun onEnter() { /* ... */ }
override fun onClick() { /* ... */ }
})
}코틀린의 객체 식은 클래스를 정의하고 그 클래스에 속한 인스턴스를 생성하지만 마찬가지로 그 클래스나 인스턴스에 이름을 붙이지 않습니다.
val lsitener = object : MouseListener {
override fun onEnter() { /* ... */ }
override fun onClick() { /* ... */ }
}만약 객체에 이름을 붙여야 한다면 변수에 익명 객체를 대입하면 됩니다.
인라인 클래스가 왜 필요한가?
class UsdCent(val amount: Int)
fun addExpense(expense: UsdCent) { }
fun main() {
addExpense(UsdCent(157))
}데이터 클래스가 코드의 가독성을 높이고 잡음을 줄여주는 사실을 알았습니다. 하지만 이 같은 경우에는 함수를 아주 많이 호출하는 경우 생성 후 짧게 사라지는 필요없는 객체를 수없이 많이 만들게 된다는 문제점이 있습니다.
위의 코드가 간단하긴 하지만 addExpense 함수를 호출할 때마다 UsdCent 객체를 생성하고, 프로퍼티를 전부 사용하는 것이 아니라 필요한 프로퍼티만을 사용하기 때문에 나머지 부분은 의미없는 데이터가 되는 것입니다.
이 때 인라인 클래스를 사용하면 성능을 희생시키지 않고 타입 안정성을 얻을 수 있습니다.
인라인 클래스를 사용하는 방법은 value키워드와 @JvmInline 어노테이션을 사용하면 됩니다.
@JvmInline
value class UsdCent(val amount: Int)인라인으로 표시하려면 클래스가 프로퍼티를 하나만 가져야 하며, 그 프로퍼티는 주 생성자에서 초기화돼야 합니다.
인라인 클래스는 클래스 계층에 참여하지 않기 때문에 다른 클래스를 상속할 수도 없고, 다른 클래스가 상속할 수도 없습니다. 그렇지만 인터페이스를 상속하거나, 메소드를 정의하거나, 계산된 프로퍼티를 제공할 수 있습니다.
마무리입니다!
이렇게 이번 글에서는 클래스와 객체, 인터페이스를 중심으로 실제 코드를 작성하면서 많이 사용된 데이터 클래스 등에 관한 개념에 대해 정리해봤습니다.
데이터 클래스를 사용할 때도 단순히 객체끼리 비교를 위해서만 사용했지만 원리를 이해하니 더욱 사용할 수 있는 범위가 늘어나고, 제대로 활용할 수 있을 것 같다고 느꼈습니다.
또한 우테코 과제 중에도 else를 지향하라는 조건을 지키기 위해 정말 많이 고민을 하고 검색해봤지만, 명쾌한 답을 찾지 못해 정말 어쩔 수 없는 경우에 else를 사용했었습니다.
그 때 이번 장에서 배운 봉인된 클래스에 대해 알았다면 확실하게 else를 지향하는 코드를 작성할 수 있지 않았을까.. 라는 생각이 들었습니다.
다음에는 람다 프로그래밍에 대한 정리글과 함께 돌아오겠습니다.
읽어주셔서 감사합니다!🙂↕️
