
Elasticsearch란?
Elasticsearch는 오픈소스 검색 및 분석 엔진이다. 대용량의 데이터를 빠르게 저장하고 검색하며 실시간으로 분석할 수 있도록 설계된 도구이다.
단어의 형태소 분석 등을 통해 기존 RDBMS에서 다루기 어려운 full text search 기능이 제공된다.
Elasticsearch가 사용되는 곳
로그 분석: 서버, 애플리케이션 로그 수집 후 검색 및 시각화
검색 엔진: 웹사이트나 앱 내 콘텐츠 검색 기능 구축
보안 분석: 이상 징후 탐지, 보안 로그 분석
데이터 모니터링: 실시간 시스템 상태나 지표 모니터링
Elasticsearch가 검색이 빠른 이유
일반적인 RDBMS에서의 검색은?
- 텍스트를 검색하기 위해서
LIKE연산을 사용한다. - 즉, 패턴 매칭으로 탐색을 하기 때문에 테이블에 저장된
모든 데이터를 탐색하면서주어진 패턴과 일치하는지 따지게 된다.
역 인덱스 (Inverted Index)
- Index
- 흔히 책 앞 부분의 목차로 비유한다.
- DB의 PK처럼 각 챕터의 제목을 나타낸다.
- Inverted Index
- 책 뒷부분의 찾아보기에 비유할 수 있다.
- 특정 키워드가 몇 페이지에 등장했는지 나타낸다.
- Inverted Index는 특정 키워드로 이를 포함하고 있는 문서들에 대한 PK를 맵핑하는 테이블을 사용하며, 이를 활용해 빠른 검색이 가능하도록 해준다.
- 검색엔진에서 Inverted Index 테이블은 주로
BTree,Trie,Hash Table등의 자료구조를 활용하여 구현된다.
Elasticsearch에서의 Inverted Index 방식
- Elasticsearch를 포함한 대부분의 검색엔진에서는 형태소 분석을 통해 문서 내에서 핵심 키워드(
Term)을 추출 → Inverted Index 테이블을 업데이트한다.
형태소 분석은 언어에 대한 깊은 이해와 많은 연산을 필요로 한다. 따라서 이 처리 과정의 효율성과 정확성은 검색 엔진의 성능과도 직결된다. - “apple”이라는 단어를 검색할 때, 일반적인 RDBMS에서는 테이블의 전체 행을 탐색한다. 하지만 Inverted Index의 구조에서는 “apple”이라는 단어가 가리키는 도큐먼트가 무엇인지 확인을 하면 된다.
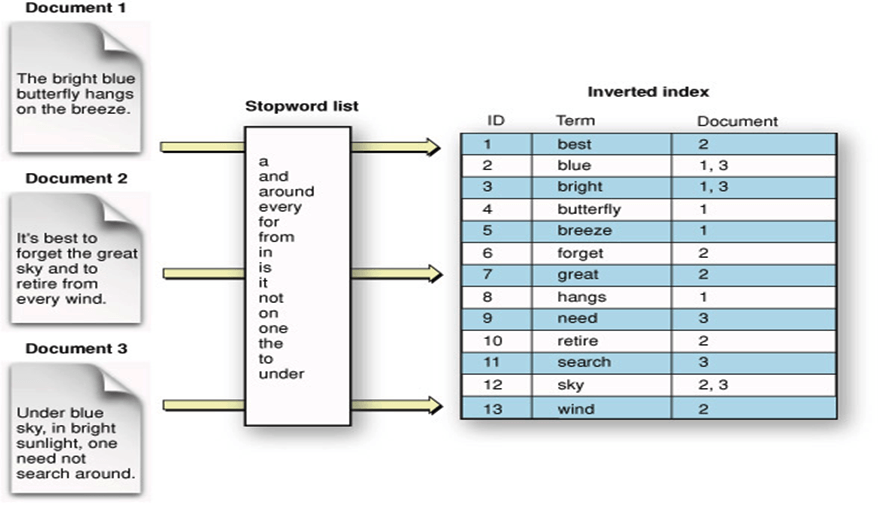
- 이러한 Inverted Index을 활용하면 시간 복잡도가 에 수렴하게 된다.
- Term을 생성해 Inverted Index 작업을 처리하는 데 꽤 오랜 시간이 걸리게 되며, 삽입된 도큐먼트가 검색 가능한 상태가 될 때 까지 약간의 대기 시간이 존재하게 된다. 이를 NRT(near real-time) 이라고 한다.
MySQL Full-Text와 Elasticsearch의 차이점
| 구분 | MySQL Full-Text | Elasticsearch |
|---|---|---|
| 역할 | 기본 검색 기능 | 전문 검색 시스템 |
| 정확도 | 낮음 (단어 일치 위주) | 높음 (의미 분석, 유사도까지) |
| 기능 | 단어 포함 여부만 확인 | 형태소 분석, 유사도 계산, 오타 교정 등 |
| 사용처 | 작은 웹사이트, 단순 검색 | 포털, 쇼핑몰, 대용량 검색 서비스 |
| 속도 | 느려질 수 있음 | 빠르고 확장성 있음 |
참고 사이트
썸네일 생성: Thumbnail Maker

공통 특화 회고는 언제 올라오나요? ㅠㅠ