Apache Hive도 0.13버전 이후로 Transaction을 지원했습니다! RDB의 트랜잭션과는 다르지만 실 데이터 파일과 메타데이터 파일이 있는 점에서는 큰 구조는 일반적인 Open Table Format과 비슷하다고 느껴졌습니다.
ACID
트랜잭션과 함께라면 항상 짝꿍으로 함께 등장하는 개념입니다.
Atomicity : 트랜잭션은 "모두 또는 아무것도"라는 원칙을 따릅니다. 트랜잭션 내의 모든 작업이 성공적으로 완료되어야만 데이터베이스에 반영되며, 하나라도 실패하면 모든 작업이 취소되어 이전 상태로 되돌아가며 이 특성을 통해 일관성을 유지합니다.
Consistency : 트랜잭션이 완료되면 데이터베이스는 일관된 상태를 유지해야 합니다. 즉, 트랜잭션이 시작되기 전과 후의 데이터 상태가 규칙과 제약 조건을 만족해야 합니다. 일관성은 데이터의 무결성을 보장하는 데 필수적입니다.
Isolation : 동시에 실행되는 트랜잭션은 서로에게 영향을 미치지 않아야 합니다. 각 트랜잭션은 독립적으로 실행되며, 다른 트랜잭션의 중간 결과를 볼 수 없습니다.
Durability : 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 저장되어야 하며, 시스템 장애가 발생하더라도 데이터가 손실되지 않아야 합니다. 이를 통해 데이터베이스가 안정적으로 데이터를 유지할 수 있도록 보장합니다.
파일은 어떻게 저장되나요?
기본적으로 HDFS는 한번 생성된 파일에 대해 변경 및 수정이 불가능하다는 특징이 있어 데이터를 실제로 수정하는 RDB에서의 트랜잭션과 다르게 Hive 트랜잭션에서는 Delta File과 Base File를 이용하여 트랜잭션을 지원하고 있습니다. Base File에는 실 데이터를, Delta File에는 데이터에 대한 수정 혹은 변경 작업을 기록하여 데이터를 읽을 시 Delta File을 읽어 변경 내용을 적용하여 읽게 됩니다.
아래와 같이 Delta File은 폴더 형식으로 생성되며 각 폴더 아래는 bucket_XXXXX 형식으로 된 Base File이 존재합니다.
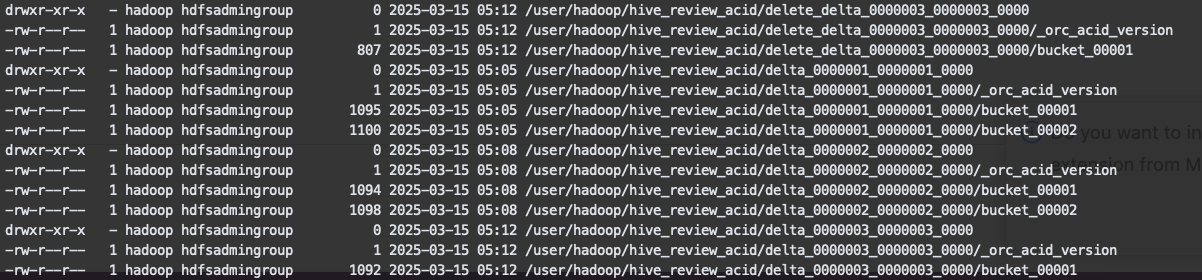
그렇다면 많은 트랜잭션이 일어나게 될 경우 Delta File이 늘어나게 되고 쿼리 성능에 영향을 미치게 되겠습니다. 다른 Open Table Format에서도 성능 향상을 위하여 Compaction 잡을 실행하듯이 Hive 트랜잭션에서는 성능을 관리하기 위해 백그라운드 프로세스로 Compactor라는 작업이 돌게 됩니다.
Compactor의 작업에도 종류가 있습니다.
- Delta File의 compacting을 담당하는 Minor Compaction
- Base File과 Delta File을 합쳐 새로운 Base File을 만드는 Major Compaction
제약 조건들
Hive 트랜잭션에는 여러가지 제약 조건들이 있습니다.
- ACID 세션이 아닌 세션에서는 ACID 테이블에 접근이 불가능합니다.
- Managed Table에서만 ACID를 활용할 수 있습니다.
- Hive와 주로 사용하는 ORC 파일 포맷을 사용해야하며 테이블에 Bucketing을 해야합니다.
- RDB와는 다르게
BEGIN,ROLLBACK,COMMIT등을 지원하지 않습니다.
왜 이런 제약들이 있는지 각각의 배경을 생각해보겠습니다.
(1) Bucketing이 필요한 이유
Bucketing은 파일을 데이터 내 컬럼 값을 기준으로 나누어서 저장하는 것입니다. 트랜잭션 수행 시 버킷팅이 된 파일마다 델타 파일이 생기게 됩니다. 아무래도 버킷팅이 되지 않은 경우보다 더 효율적으로 관리 될 수 있기 때문이라고 추측됩니다.
(2) 위의 내용처럼 Delta File을 만들고 해당 파일에 트랜잭션 내용을 기록하는 방식으로 트랜잭션을 수행합니다. RDB의 경우 실제 데이터의 수정이 일어나지만, Hive에서는 그렇지 않기 때문에 BEGIN, ROLLBACK, COMMIT 등의 커맨드가 필요하지 않습니다. (Auto Commit)
(3) Hive Transaction을 사용하기 위해서는 기본적으로 아래와 같은 Config가 필요합니다.
set hive.support.concurrency=true;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
hive.support.concurrency 를 활성화 할 경우 잠금을 사용하게 되며 트랜잭션을 위해 org.apache.hadoop.hive.ql.lockmgr.DbTxnManager의 클래스를 사용할 수 있게 설정해야 합니다.
잠금
여러 사용자가 동시에 읽거나 쓰는 것을 방지하기 위해서 hive ACID에서도 잠금을 사용합니다. 사용하는 잠금의 종류로는 공유 잠금, 배타적 잠금이 있습니다.
공유잠금 (Shared Lock,S): 여러 트랜잭션이 동시에 데이터를 읽을 수 있도록 허용하나 데이터에 대한 쓰기는 허용하지 않습니다.
배타적 잠금 (Exclusive Lock, X) : 특정 트랜잭션이 데이터를 수정할 때 사용되며, 다른 트랜잭션은 해당 데이터에 대한 읽기 및 쓰기를 할 수 없습니다.
파티셔닝이 되어있지 않은 테이블의 경우 읽기 작업 시 S, 읽기 외의 작업 시 X를 획득합니다. 파티셔닝이 되어있는 테이블의 경우 테이블과 동시에 파티션에 대한 잠금이 동시에 필요하게 되기 때문에 읽기의 경우 테이블에 S, 파티션에 S 잠금을 획득해야하며 이 외의 작업의 경우 테이블에 S 잠금, 파티션에 X 잠금을 획득해야합니다.
위의 hive.txn.manager 를 설정하게 될 경우 잠금 역시 자동으로 설정되게 됩니다. 잠금의 경우 show locks 명령어 입력을 통해 확인할 수 있습니다.
테이블 Properties 설정
테이블 생성시에는 아래와 같이 transactional 값과 transactional_properties 값을 넣어주어야 합니다.
CREATE TABLE `hive_review_acid`(
`customer_id` string,
`product_category` string,
`review_date` date,
`marketplace` string)
CLUSTERED BY (product_category) into 3 BUCKETS
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs:///user/hadoop/hive_review_acid/'
TBLPROPERTIES (
'transactional'='true',
'transactional_properties' ='default'
)
한번 생성된 ACID 테이블은 다시 Non-ACID 테이블로 변경할 수 없습니다.
정리
Hive에서도 ACID를 지원하고 있었는데요, 아무래도 여러가지 제약 조건들 + Managed Table로 생성해야한다는 점, 스키마 유연성의 면에서 Open table format을 사용하는 것이 더 유리하지 않을까 생각이 들었습니다.
