Java Collection Framework(JCF)란
컬렉션은 다수의 데이터, 프레임워크는 표준화된 프로그래밍 방식을 의미합니다. 따라서 컬렉션 프레임워크란 데이터 그룹을을 저장하는 클래스들을 표준화한 설계입니다.
쉽게 말해 자료구조와 데이터를 처리하는 알고리즘을 클래스로 구현해 놓은 것이 Java Collection Framework(JCF) 입니다. 따라서, 직접 자료구조를 구현하지 않고 프레임워크를 가져와서 사용하면 됩니다.
장점
- 객체지향적 설계(인터페이스, 다형성)를 통해 표준화되어 있어서 사용에 편리하고 재사용성이 높다.
- JVM 최적화된 고성능 구현으로 프로그램 성능 향상
- 상호 운용성 (상위 인터페이스 타입으로 업캐스팅해서 사용)
- 컬렉션을 조합하여 새로운 알고리즘을 만들어낼 수 있다.
주의점
컬렉션 프레임워크에 사용 가능한 데이터는 Object(객체)입니다다. 따라서 int, double, long 등의 primitive type은 사용이 불가능합니다. Wrapper 타입으로 변환해서 박싱해서 저장해야 합니다. null도 저장이 가능합니다.
JCF의 계층 구조
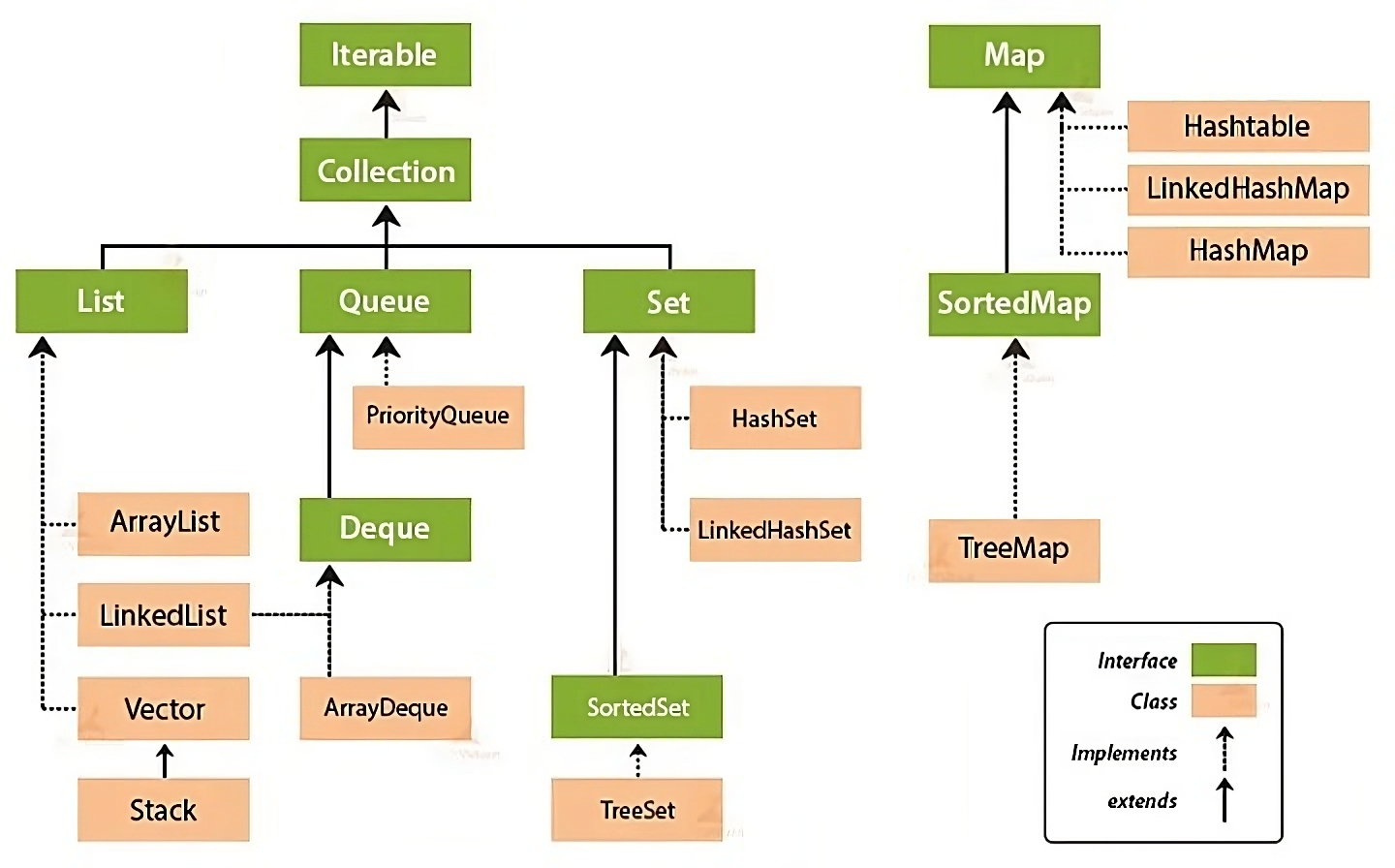
컬렉션 프레임워크는 크게 Collection 인터페이스와 Map 인터페이스로 나뉩니다.
List, Set, Queue의 구현 클래스들은 공통 부분이 많기에 Collcetion 인터페이스로 정의되어 있습니다.
Map 인터페이스는 두 개의 데이터를 한 쌍으로 관리하기 때문에 Collection 프레임워크와 분리되어 있습니다.
💡 Vector, Stack, HashTable 등은 컬렉션 프레임워크가 아닙니다. JCF가 만들어지기 전부터 존재해왔기 때문에 네이밍 규칙도 맞지 않습니다. 또한, 기존 코드 호환을 위해 남겨진 클래스들이므로 사용하지 않는 것이 좋습니다.
Iterable 인터페이스
컬렉션 인터페이스들의 최상위 인터페이스이자, Iterator 객체를 관리하는 인터페이스입니다.
| 메소드 | 설명 |
|---|---|
default void forEach(Consumer<? super T> action) | 람다 전용 메소드 |
Iterator<T> iterator() | Iterator |
default Spliterator<T> spliterator() | 파이프라이닝 관련 메소드 |
Map은 Iterable을 상속받지 않기 때문에, Stream을 사용하거나 Key를 Collection으로 변환한 후 반복문을 사용해야 합니다.
Collection 인터페이스
List, Set, Queue의 상위 인터페이스
다형성을 이용하여 Collection 타입으로만 사용해도 다양한 기능을 사용할 수 있습니다.
| 메소드 | 설명 |
|---|---|
boolean add(Object o)boolean addAll(Collection c) | 객체 또는 객체들을 Collection에 추가 |
boolean contains(Object o)boolean containsAll(Collection c) | 객체 또는 객체들이 Collection에 포함되어 있는지 확인 |
boolean remove(Object o)boolean removeAll(Collection c) | 객체 또는 객체들을 Collection에서 삭제 |
boolean retainAll(Collection c) | 객체들(c)만 남기고 나머지는 Collection에서 삭제. 변화가 있으면 true, 없으면 false 리턴 |
void clear() | 모두 삭제 |
boolean equals(Object o) | 동일한 Collection인지 비교 (hash 기반 컬렉션이면 equals()만 재정의하면 다르다고 판단) |
int hashCode() | Collection의 해시코드를 반환 |
boolean isEmpty() | 빈 Collection인지 확인 |
Iterator iterator() | Collection의 iterator 반환 (Iterable의 기능) |
int size() | Collection에 저장된 객체 개수 반환 |
Object[] toArray() | Collection을 Array로 반환 |
Object[] toArray(Object[] a) | 배열 a에 Collection의 객체를 저장해서 반환 |
add, remove, contains 기능은 있지만 get 메소드는 존재하지 않습니다. 구현 클래스의 자료구조가 제각각이므로 get은 구현 인터페이스에 정의되어 있습니다.
List 인터페이스
- 순서 유지
- 중복 저장 가능
- 인덱스를 통해 요소 접근
- 리스트 크기가 동적으로 변함
- 요소 사이에 빈 공간이 없기에 삽입/삭제할 때마다 한칸씩 이동한다.
| 메서드 | 설명 |
|---|---|
void add(int index, Object element) boolean addAll(int index, Collection c) | 특정 index에 객체 또는 객체들을 추가 |
Object remove(int index) | 특정 index에 있는 객체를 삭제하고 리턴 |
Object get(int index) | 특정 index의 객체 반환 |
Object set(int index, Object element) | 특정 index에 객체 추가 |
int indexOf(Object o) | 객체 o의 index 반환 |
int lastIndexOf(Object o) | 객체 o의 index 반환 (거꾸로) |
List subList(int fromIndex, int toIndex) | 특정 Range(from ~ to) 객체 반환 |
ListIterator listIterator() ListIterator listIterator(int index) | ListIterator |
void sort(Comparator c) | Comparator를 통해 리스트 정렬 |
ArrayList 클래스
- 배열을 이용하여 만든 리스트 (메모리상 붙어있음)
- 순서 유지 및 중복 허용
- capacity가 자동으로 늘어나거나 줄어들음 (데이터 양에 따라)
- 장점: 단방향 포인터 구조로 순차접근과 조회가 빠르다.
- 단점: 중간 삽입/삭제 느리다. (단, 순차적으로 삽입/삭제는 가장 빠름)
ArrayList는 어떻게 동적으로 늘어나는가?
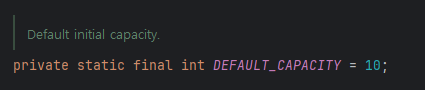
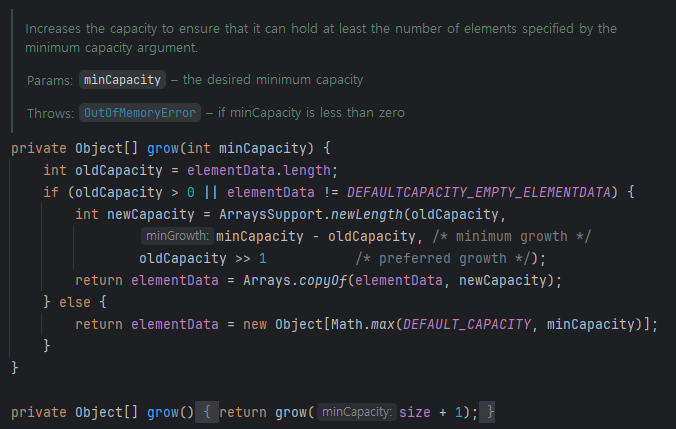
- 초기용량: ArrayList가 비어있다면, 일반적으로 10으로 생성. default 사이즈인 10과 minCapacity(=size+1) 중 큰 값으로 새로운 배열 생성.
- 요소 추가:
add()메소드로 요소를 추가해주다가 리스트 공간보다 더 커질 경우, 배열 크기 확장! - 크기 확장:
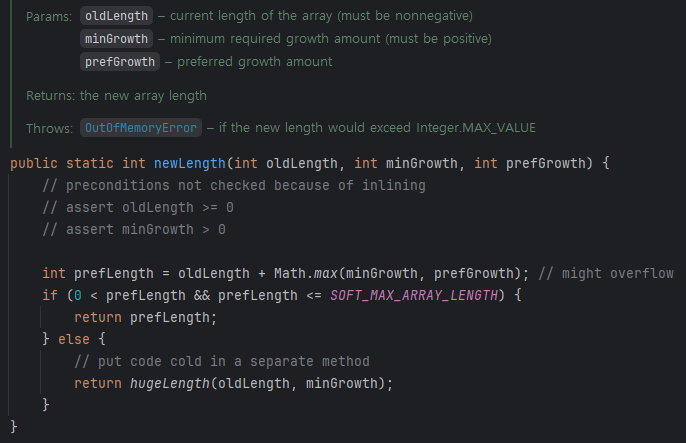
grow()메소드- 추가할 용량 계산 -
ArraysSupport.newLength() - int prefLength = oldLength + Math.max(minGrowth, prefGrowth);
- 일반적으로 prefGrowth로 추가로 늘어날 크기가 정해지는데,
oldCapacity >> 1입니다. oldCapacity >> 1은 모든 2진수 비트를 우측으로 1씩 이동하기 때문에, 2를 나누는 것과 동일합니다. (비트 연산자는 속도가 빠름)- 따라서, 기존 용량에 절반이 추가되므로 1.5배가 됩니다.
- 추가할 용량 계산 -
LinkedList 클래스
- 노드를 연결한 링크드리스트 (메모리에 흩어져있음)
- 장점: 중간 삽입/삭제 빠름
- 단점: 랜덤 요소 접근 느림
- 양방향 포인터 구조
- List와 Queue 인터페이스를 모두 상속받고 있다. 스택/큐 모두 사용 가능
Vector 클래스
ArrayList의 구형 버전 (거의 비슷)- 모든 메소드가 synchronized 되어 있어 Thread-safe 하다.
- 호환성을 위해 남겨두었고, 잘 쓰이지 않는다.
- 동기화가 필요하다면
Collctions.synchronizedList()를 쓰면 되기 때문
Stack과 Queue
Stack은 클래스이고, Queue는 인터페이스입니다.
Stack 클래스
- Last-In-First-Out
- 추가는 push(), 삭제는 pop()
- Stack은 Vector를 상속하기 때문에 쓰지 않는 것이 좋다. (
ArrayDeque사용)
Queue 인터페이스
- First-In-First-Out
- Queue 인터페이스이므로 구현 클래스를 골라 쓰면 된다. (
LinkedList, PriorityQueue, ArrayDeque)
| 메서드 | 설명 |
|---|---|
boolean add(Object o) | Queue에 객체 추가 저장공간 부족 시 IllegalStateException 발생 |
Object remove() | Queue에서 객체를 꺼내 반환 비어있을 경우 NoSuchElementException 발생 |
Object element() | 첫번째 요소 반환 비어있을 경우 NosuchElementException 발생 |
boolean offer(Object o) | Queue에 객체 추가 저장공간 부족 시(저장에 실패할 경우) false 반환 |
Object poll() | 첫 번째 요소 제거 및 반환 비어있을 경우 null을 반환 |
Object peek() | 첫 번째 요소 반환 비어있을 경우 null을 반환 |
PriorityQueue 클래스
- 우선 순위 큐
- 각 요소에 priority가 있어서, 우선 순위가 높은 순으로 정렬된다.
- 우선 순위가 높은 순으로 꺼내간다.
- 기본적으로 최소 우선순위 큐로 동작한다. 따라서,
peek()또는poll()사용시 최솟갑 반환. - 필수로 Comparable 인터페이스를 구현해야 한다, (내부적으로
compareTo()로직에 따라 우선순위를 결정하기 때문) - 저장공간으로 Array를 사용하고, 각 요소는 기본적으로 Min Heap 형태로 저장한다.
- Heap은 완전 이진 트리 형태로, 최대/최소값을 빠르게 찾아내는 데 유용한 자료구조
- 부모-자식 간 정렬은 보장하되, 형제간 정렬은 보장하지 않는다.
- Min Heap(최소 힙)이란, 부모가 작고 자식이 큰 것.
- null 저장 X
Deque 인터페이스
- Deque(Double-Ended Queue)는 양쪽으로 삽입/삭제가 가능한 큐
- 따라서 스택과 큐를 합친 자료구조
- Deque의 조상은 Queue이고, 구현체로는 ArrayDeque와 LinkedList 등이 있다.
ArrayDeque 클래스
- 스택으로는 Stack보다 빠르고, 큐로는 LinkedList보다 빠르다.
- 사이즈 제한 X
- null 저장 X
LinkedList 클래스
위에 적어 놓았습니다.
Set 인터페이스
- 중복 허용하지 않고, 순서를 유지하지 않는 집합
- 순서가 없으므로 get(index)도 없음
HashSet 클래스
- Array와 LinkedList를 결합한 자료구조 형태
- 가장 빠른 조회 속도 (랜덤 접근)
- 순서 예측 X
HashSet이 중복요소를 제거하는 원리
HashMap사용- HashSet은 내부적으로 HashMap 객체를 사용합니다.
- HashMap에서 HashSet의 요소들이 Key로 저장되며, Value에는 동일한 더미 데이터를 사용합니다.
- 더미 데이터:
PRESENT라 불리는 빈 Object. add()에서put()결과가 null이면 새로운 요소가 추가된 것이고,remove()에서remove()결과가PRESENT이면 이전 요소가 잘 삭제된 것을 의미합니다.public boolean add(E e) { return map.put(e, PRESENT)==null; } public boolean remove(Object o) { return map.remove(o)==PRESENT; }
- 더미 데이터:
add()메소드- HashSet의 add()는 HashMap의 put() 메소드를 호출합니다.
- HashMap의 put()은 같은 요소인지 판단할 때, 내부적으로 key값의 hashCode가 같은지 비교합니다. 해시코드가 같으면 key의 동일성(==) 혹은 동등성(equals())을 검사합니다.
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;- 이것이 equals()와 hashCode()를 모두 오버라이딩 해야 하는 중요한 사례!
LinkedHashSet 클래스
- 순서를 가지는 Set
- 추가된 순서를 유지한다.
TreeSet 클래스
- BinarySearchTree 구조
- 순서를 가지진 않지만, 데이터가 정렬되어 저장
EnumSet 추상 클래스
- Enum을 저장하는 Set 컬렉션
EnumSet<UserType> userTypeSet = EnumSet.allOf(UserType.class);- 산술 비트 연산을 사용하여, HashSet보다 빠르고 적은 메모리 사용
- 구현 클래스: RegularEnumSet, JumboEnumSet
Map 인터페이스
- Key와 Value 쌍으로 이루어진 데이터 집합
- Key값은 unique
- 동일한 key, value를 추가하면 기존 데이터는 사라지고 마지막 값만 남는다.
Set entrySet(),Set keySet(),Collection values()
- 순서 X
HashMap 클래스
- Hashtable을 보완한 컬렉션
- Array와 LinkedList가 결합된 Hashing 형태
- 키와 값 모두 null을 허용한다.
- 비동기로 동작하므로, 멀티 쓰레드 환경에서는
ConcurrentHashMap사용
LinkedHashMap 클래스
- HashMap을 상속하되, Entry들끼리 LinkedList를 구성하여 데이터 순서를 보장한다.
TreeMap 클래스
- BinarySearchTree 구조
- SortedMap 인터페이스를 구현하고 있어, Key 값을 기준으로 정렬된다.
- 정렬되어 있으므로, 빠른 범위 검색
- 저장시간이 다소 오래 걸림
- 순서: 숫자 -> 알파벳 대문자 -> 소문자 -> 한글
HashTable 클래스
- 자바 초기에 나온 레거시 클래스
- Key 값을 해시함수를 통해 hashing한 결과를 Array의 인덱스로 사용하여 value를 찾는 방식
- HashMap보다 느리지만, synchronized 지원
- 키와 값 모두 null X
Properties 클래스
- Properties<String, String> 형태로 저장하는 단순 key-value
- 주로 설정파일에 사용된다.
정리
- List 자료구조: 기본 ArrayList, 삽입/삭제가 많다면 LinkedList
- Set 자료구조: 기본 HashSet, 정렬이 필요하다면 TreeSet
- Map 자료구조: 기본 HashMap, 정렬이 필요하다면 TreeMap
- 만약 저장 순서를 유지해야 한다면, LinkedHashMap, LinkedHashSet 사용
- Stack/Queue 자료구조: ArrayDeque 사용
- Stack, Hashtable 클래스는 사용하지 말자! (deprecated)
