
📌 문자열, 예외, 제네릭
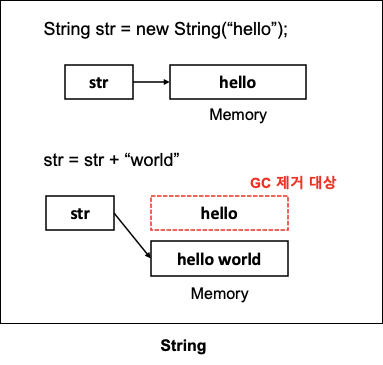
String literal과 new String(””)
String literal은 특별하게 String Constant Pool이라는 메모리 영역에 저장됩니다. (String Pool도 힙 영역이긴 함) 따라서 ==으로 비교하여도 true 결과가 반환됩니다.
new String()의 경우 다른 객체 생성과 동일하게 Heap 영역에 저장됩니다. 또한, 리터럴은 동일한 문자열의 경우 참조를 재사용하지만, new String()은 항상 객체를 생성합니다.
따라서, 문자열의 경우 리터럴을 사용하는 것이 성능상 이점이 많습니다.
String, StringBuilder, StringBuffer
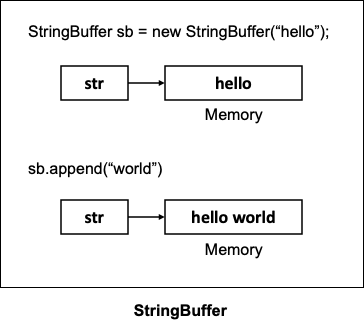
String은 불변하고 StringBuilder와 StringBuffer는 가변합니다. String은 불변 객체이므로 문자열 연산(+, concat(), trim(), toUpperCase() 등)을 하게 되면 기존 객체가 수정되는 것이 아니라 새로운 String 객체를 생성해서 리턴하므로 많은 연산에는 적합하지 않습니다.
주의! 문자열에 덧셈(+) 연산을 사용하면 컴파일 단계에서 내부적으로 최적화가 이루어지는데, jdk5에서는 StringBuilder로, jdk9부터는 StringConcatFactory를 통해 이루어집니다. 연산 후 String으로 반환되기 때문에 간단한 연산에서는 가독성이 좋은 + 연산을 쓰는 것이 좋겠습니다.
String을 불변으로 설정한 이유
1. 캐싱: String pool에 리터럴 문자열 하나만 저장하여 재사용함으로써 Heap 메모리 공간 최소화
2. 보안: User, Pw 등의 문자열이 참조를 통해 변경이 가능하다면 보안에 취약하기 때문
3. 동기화: 불변하면 스레드 안전성이 보장된다.
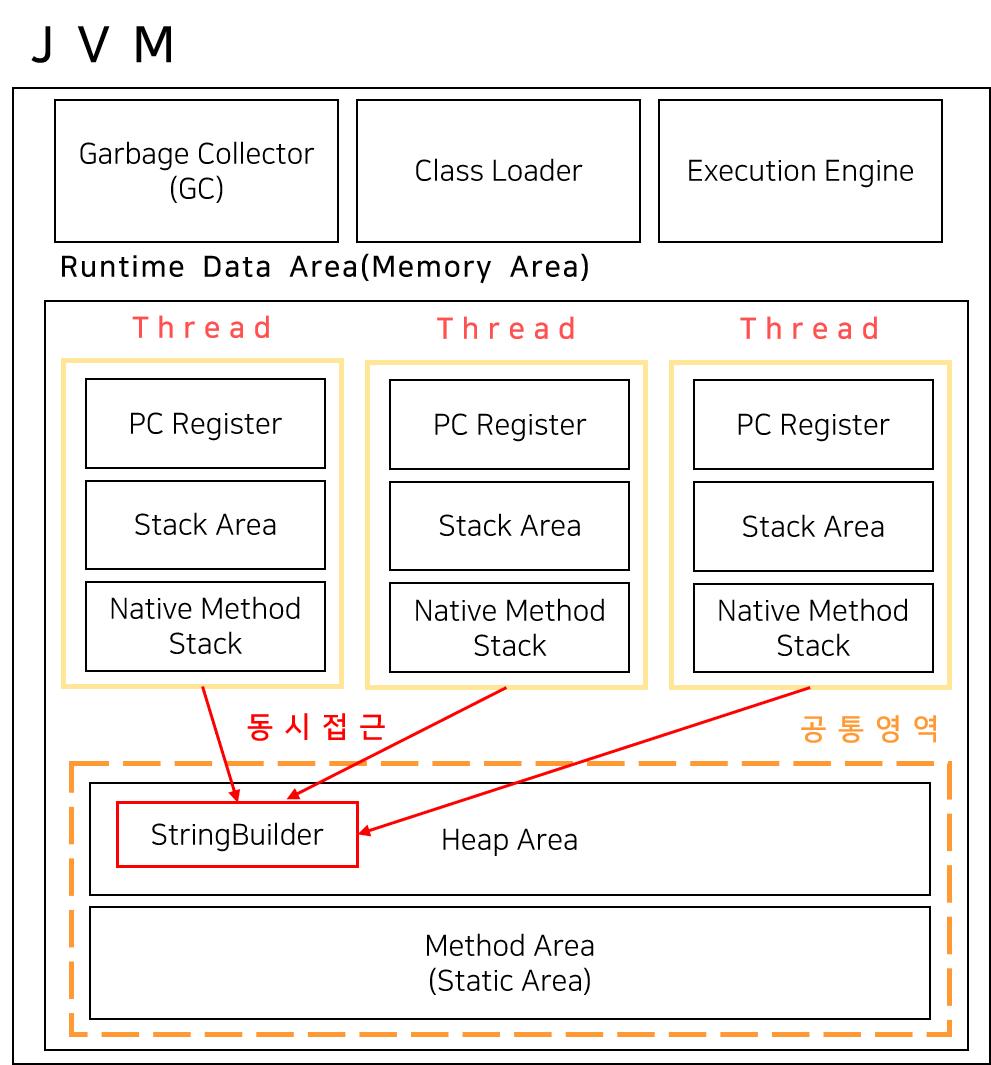
StringBuilder, StringBuffer는 초기에 내부 버퍼를 두고 동적으로 크기를 변해가면서 문자열을 저장해두고 연산(append() delete() 등)을 수행합니다. 따라서 문자열 연산이 많을 때는 String보다 StringBuilder, StringBuffer를 사용하는 것이 좋습니다.
둘의 차이는 Thread-safe 뿐입니다.
1. StringBuffer: 안전. synchroized 키워드를 통한 동기화를 지원하기 때문.
2. StringBuilder: 안전 X. 쓰레드 안정성이 없기 때문에 성능이 좋음. 만약 StringBuilder sb = new StringBuilder();를 선언하고 여러 스레드에서 append()를 해야 하는 경우에는 StringBuffer를 사용해서 스레드 안전성을 보장받는 것이 좋다.
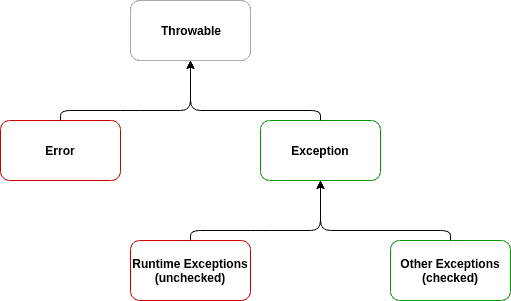
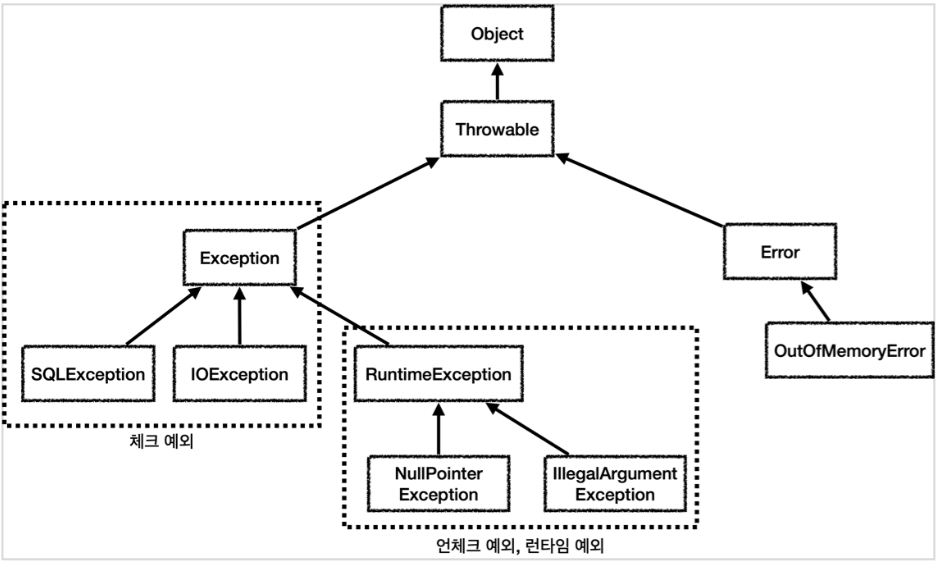
Exception과 Error
Exception은 예측 가능한 오류를 의미하기 때문에 try-catch를 통해 exception handling이 가능하지만, Error는 OOM, StackOverflow 혹은 시스템 레벨의 중대한 오류를 의미합니다.
 |  |
|---|
Error, Exception 모두 Throwable을 상속받고 있습니다. Throwable의 역할은 오류 메시지를 담는 것이고,
getMessage(),printStackTrace()메소드가 정의되어 있습니다.
Exception 클래스
NullPointerException(null 값인 참조변수를 호출), IOException(입출력 관련 오류), FileNotFoundException(없는 파일 접근) 등이 있습니다.
Checked Exception과 Unchecked Exception
Checked Exception은 컴파일 시점에 예외를 반드시 처리해야 하는 예외이고, Unchecked Exception은 명시적 처리를 하지 않아도 되는 런타임 예외입니다.
Checked Exception은 컴파일 단계에서 안정성을 높이지만 예외처리 로직이 과도하게 많아질 수 있다는 단점이 있습니다. (무작위한 throws가 발생할 수도 있고..)
throw와 throws의 차이
throw는 예외를 직접 발생시킬 때 사용합니다.
if (num > 12) {
throw new RuntimeException("Number is over than 12!");
}throws는 예외를 직접 처리하지 않고, 호출한 부분으로 떠넘기는 방식입니다.
int calculateNumber(int num) throws RuntimeException {
//...
}try~catch~finally 구문에서 finally의 역할
finally는 예외 발생 여부와 관계없이 항상 실행되는 블록입니다. 따라서 IO 리소스 해제, DB 트랜잭션 등 예외가 발생해도 항상 처리해야 하는 부분에 사용됩니다.
Throwable과 Exception의 차이
Throwable은 Exception과 Error의 부모 클래스이므로, Error까지 포함하는 개념입니다.
Error는
참고: 좋은 예외(Exception) 처리 - https://jojoldu.tistory.com/734
제네릭이란
클래스나 메소드에서 사용할 데이터 타입을 런타임(외부)에 지정하는 기법을 의미합니다. 실행될 때 타입을 가져와서 구체적으로 설정됩니다. (primitive type은 불가능하고, reference type만 가능. 또한, 런타임 시점에 타입이 결정되므로 static에서는 사용 불가)
Object는 최상위 클래스이기 때문에 여러 타입으로 사용이 가능하지만, 다시 타입 캐스팅을 해줘야 하고 안전하지 않습니다. 제네릭은 컴파일 시점에 타입체크를 해주기 때문에 안전합니다. 또한, 타입 캐스팅 과정이 필요없기 때문에 성능 이점이 있습니다.
추가로 extends를 통해 타입을 제한할 수도 있습니다.
class FruitBox<T> {
List<T> fruits = new ArrayList<>();
public void add(T fruit) {
fruits.add(fruit);
}
}제네릭을 사용한 경험
API Response 클래스에 사용한 적이 있습니다. 응답 데이터의 경우 엔드포인트마다 다양한 타입이 존재하기 때문에 매번 타입에 맞는 클래스를 만들어주지 않고, 제네릭 클래스 하나로 응답 형식을 통일시켰습니다.
public class ApiResponse<T> {
private int code;
private String message;
private T data;
}📌 람다, 스트림, 어노테이션, 리플렉션
람다란?
람다 표현식은 메소드를 하나의 간결한 식으로 나타낸 코드 블록이고, 익명 함수라고도 불립니다. (함수형 인터페이스를 익명 클래스로 구현하되, 구현부를 람다식으로 짧게 표현한다.)
- 익명: 메소드와 달리 이름이 없다.
- 함수: 메소드처럼 클래스에 종속되지 않기에 함수라 불린다.
- 전달: 람다 표현식을 파라미터로 전달하거나 변수로 저장할 수 있다.
- 간결성: 익명 클래스처럼 간결하다.
// 기존 코드
Comparator<Apple> byWeight = new Comparator<Apple> {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
};
// 람다 코드
Comparator<Apple> byWeight =
(a1, a2) -> a1.getWeight().compareTo(a2.getWeight());
// 간소화된 Comparator 코드
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
}함수형 인터페이스란?
딱 하나의 추상 메소드가 선언된 인터페이스를 말합니다. 따라서, 람다식 파라미터와 리턴타입을 생략해도 메소드의 시그니처를 통해 추론이 가능합니다.
스트림이란?
스트림은 데이터 소스를 추상화하고 자주 사용되는 메소드들을 정의해 놓은 것입니다.
- 연속된 요소: 스트림은 연속된 값을 처리하는 인터페이스를 제공한다. 컬렉션의 주제는 데이터이고, 스트림의 주제는 계산이다.
- 소스: 스트림은 컬렉션, 배열, I/O 자원 등의 데이터 제공 소스로부터 데이터를 소비한다.
- 데이터 처리 연산: filter, map, reduce, find, match, sort 등으로 데이터 조작
자바에서 배열, 컬렉션을 다뤄야 하는데 같은 기능이지만 다른 방식으로 다뤄야하는 불편한 점이 있습니다. ( List -> Collections.sort(), Array -> Arrays.sort() )
이러한 문제를 극복하기 위해 데이터 소스(배열, 컬렉션, 파일 데이터 등)에 상관없이 스트림을 이용하면 모두 같은 방식으로 다룰 수 있습니다.
스트림의 특징
1-1. 원본 데이터(소스)를 변경하지 않는다.
1-2. 일회용이다. 한번 사용하고 나면 재사용이 불가능하다.
1-3. 내부 반복으로 처리한다. (forEach는 내부적으로 for문이 사용되는 것)
2. 스트림 연산
스트림 만들기 -> 중간연산 N번 -> 최종연산 1번 (연산은 안해도 상관없긴 함)
중간연산: 반환값이 스트림이므로 체이닝을 통해 계속 적용 가능
최종연산: 결과 도출 (List, Integer, void등 스트림 이외의 결과 반환)
2-1. 지연 연산
2-2. 병렬 스트림 가능 (stream().parallel()): 주의점들을 잘 고려해야 한다. ex) 작업을 나누고 합치는 과정(일명, MapReduce 분산 컴퓨팅 모델과 유사)이 있으므로 소량의 데이터라면 오히려 불리
람다와 스트림은 왜 생겨났을까?
익명 클래스를 사용해서 메소드를 파라미터로 전달하였는데 코드가 길고 가독성이 떨어지는 단점이 있었습니다. 따라서 간결하고 명확한 람다를 통해 이를 해결하였습니다.
또한, 거대한 데이터를 다루는 것이 중요해지면서, 스트림을 도입해서 데이터를 표준화해서 처리할 수 있도록 하였습니다. 이렇게 함수형 프로그래밍 패러다임을 도입하면서 보다 선언적으로 프로그래밍할 수 있는 기반을 마련한 것입니다.
- 참고: https://dwaejinho.tistory.com/entry/Java-Lambda-Stream-%EB%8F%84%EC%9E%85-%EB%B0%B0%EA%B2%BD%EA%B3%BC-%EC%9B%90%EB%A6%AC-%ED%8C%8C%ED%95%B4%EC%B9%98%EA%B8%B0
- https://f-lab.kr/insight/in-depth-analysis-java-8-lambda-expressions
어노테이션이란?
코드 내에 메타데이터를 약속된 형식으로 제공하는 방법입니다. 컴파일이나 런타임 시점에 해석될 수 있는 정보를 제공합니다. 어노테이션 정의 시, @Target, @Retention 등을 지정하여 적용 가능한 대상과 유지기간을 설정할 수 있습니다.
- 참고: https://steady-coding.tistory.com/614
- https://kkminseok.github.io/posts/2023-01-26-Annotation_Ad01/
어노테이션을 왜 사용할까?
코드의 의도를 명확하게 표현할 수 있습니다. 또한, 반복적이고 부가적인 로직을 어노테이션으로 공통 적용하여 AOP를 쉽게 적용할 수 있습니다.
어노테이션은 리플렉션으로 동작한다. 그러면 리플렉션이란?
객체를 통해 클래스의 많은 메타데이터 정보를 분석해내는 기법입니다. 자바 API입니다.
그러면 리플렉션을 활용해서 어노테이션의 메타 데이터를 가져오는 등의 로직을 실제로 구현해 보신 적이 있으신가요?
사용자의 audit 로그를 저장하는 기능에 리플렉션을 사용한 적이 있습니다. 엔티티가 저장, 수정, 삭제될 때의 이벤트를 캐치하여 로그를 남겨야 했습니다. JPA Entity Listener를 통해 이벤트 실행 이후에 변화된 엔티티를 감지해서 DB에 따로 저장을 했습니다.
이때, 거의 모든 엔티티 클래스에 대한 기록을 남겨야 했는데, 구체적인 클래스 타입을 예상하기 어려웠기에 리플렉션을 사용해서 클래스 타입을 동적으로 알아내어 audit 로그를 남길 수 있었습니다.
System.out.println 클래스는 성능이 좋지 않은 이유
System.out.println 은 Stream을 통해 콘솔에 출력해주는 역할을 합니다. 이때, synchronized로 동기화 처리가 되어 있기 때문에 성능이 좋지 않습니다. 만약 이 메소드를 여러 스레드에서 사용하게 된다면 Blocking I/O 처리로 인해 프로그램이 느려집니다.
