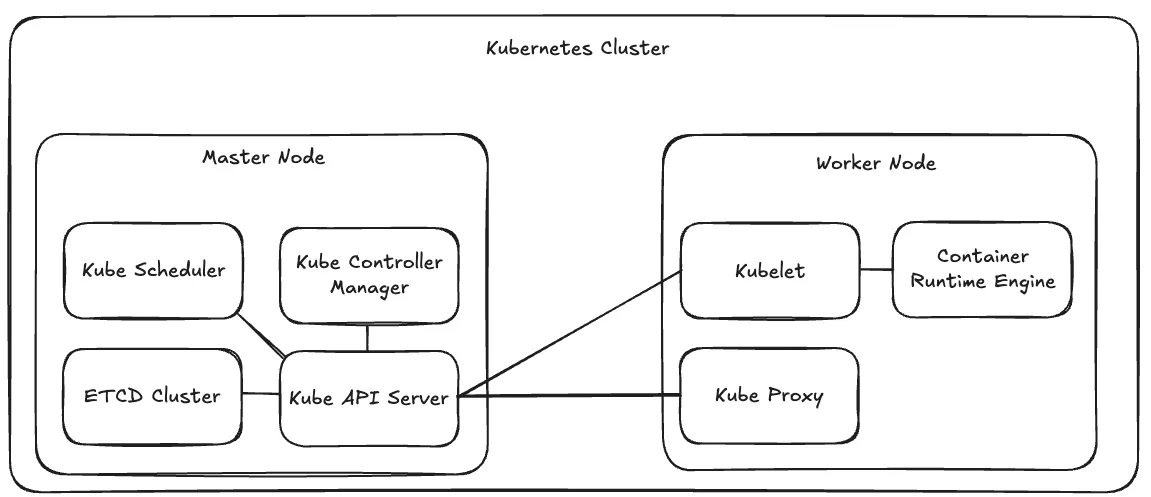
Master Node의 구성 요소
- Kube Scheduler : 컨테이너의 리소스 요구 사항이나 노드의 용량 등을 고려하여 컨테이너를 배치할 노드를 결정.
- Kube Controller Manager : 여러 개의 Controller( 특정한 목적을 위해 Kubernetes의 다양한 Component들을 모니터링하고 원하는 상태를 유지하도록 만드는 프로세스 )를 묶어 놓은 단일 프로세스.
- Node Controller : 노드 추가/삭제 처리.
- Replication Controller : 항상 지정된 수의 컨테이너가 실행되도록 보장.
- 이 외에도 다양한 Controller가 존재.
- ETCD Cluster : 클러스터의 모든 정보를 저장하는 고가용성 Key-Value 데이터베이스. 어떤 컨테이너가 어떤 노드에 있는지, 언제 실행됐는지 등 모든 상태 정보를 기록.
- kubectl get 명령어로 볼 수 있는 모든 정보가 ETCD에 저장됨.
- 클러스터에 변경사항이 발생하면, 이 정보가 먼저 ETCD에 업데이트되어야만 변경이 완료된 것으로 간주됨.
- 마스터 노드가 여러 개 있는 상황에서는 각 노드에 분산되어 있는 ETCD 인스턴스가 서로 연결되어 데이터를 동기화함.
- Kube API Server : 모든 클러스터 작업의 오케스트레이션을 담당. 외부 사용자나 다른 컨트롤러, 워커 노드와 통신하며 클러스터 상태를 모니터링하고 필요한 변경 사항을 적용.
- 클러스터의 상태 정보를 저장하는 ETCD와 직접 통신하는 유일한 Component.
Worker Node의 구성 요소 ( 물론 Master Node에도 설치되는 요소들 )
- Kubelet : Kube API Server의 명령을 받아 컨테이너를 실행하거나 제거. 또한 주기적으로 노드와 컨테이너의 상태를 Kube API Server에 전달.
- Kubernetes를 설치하기 위해 사용하는 kubeadm같은 도구들을 다른 Component와 달리 Kubelet은 자동으로 설치하지 않음. 각 Worker Node에 수동으로 설치해야 함.
- Container Runtime Engine : 컨테이너를 실행하는 프로세스. Docker, ContainerD, Rocket 등 다양한 엔진을 사용할수 있음.
- Kube Proxy : Kube API Server로부터 받아온 정보로 iptables 규칙을 업데이트하여 해당 노드의 필요한 네트워크 규칙을 설정.
Kube API Server 중심으로 처리되는 Pod 생성 과정
- 사용자가 Pod 생성을 요청하면 Kube API Server는 ETCD에 “아직 Node가 할당되지 않은” Pod를 생성.
- Kube Scheduler는 Kube API Server를 모니터링하다가 Node가 할당되지 않은 Pod를 발견. 적절한 Worker Node를 찾아 어떤 Node에 Pod를 배치할지 정보를 Kube API Server에게 전달
- Kube API Server는 전달받은 정보에 따라 ETCD를 업데이트. 그리고 해당 Worker Node의 Kubelet에게 해당 Pod를 생성하라고 지시.
- Kubelet은 Container Runtime Engine을 통해 Pod를 생성 . 작업이 완료되면 Pod의 상태를 Kube API Server에 보고.
- Kube API Server는 보고받은 최종 상태를 ETCD에 업데이트.
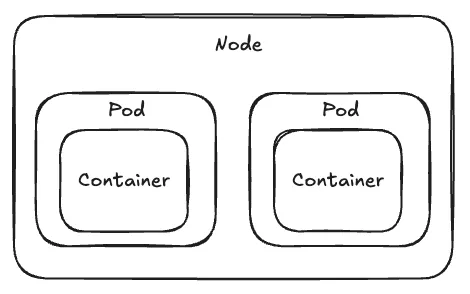
Kubernetes Resource - Pod
- Kubernetes는 Container를 Node에 직접 배포하지 않고 Pod라는 Resource로 한 번 감싸서 배포.
- Kubernetes에서 생성하고 관리할 수 있는 가장 작은 배포 단위.
- 일반적으로 하나의 Pod는 하나의 Container만 가지는 것이 권장됨. 때문에 애플리케이션 Scaling 시에도 Pod의 개수를 조절.
- Pod 정의 YAML 형식
# 1. API 버전: 파드를 생성할 것이므로 'v1'을 사용합니다. apiVersion: v1 # 2. Kind: 생성할 리소스의 종류는 'Pod'입니다. kind: Pod # 3. Metadata: 파드에 대한 부가 정보입니다. metadata: # 파드의 고유한 이름 name: my-app-pod # 파드를 식별하고 그룹화하기 위한 라벨 (key-value 쌍) labels: app: my-app tier: frontend # 4. Spec: 파드의 상세 명세입니다. spec: # 이 파드에서 실행될 컨테이너들의 목록 (리스트/배열 형태) containers: # 리스트의 첫 번째 아이템을 의미하는 '-' - name: nginx-container image: nginx
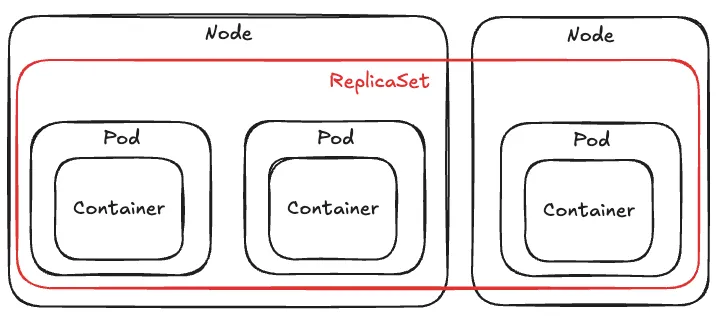
Kubernetes Resource - ReplicaSet
- 고가용성 / LoadBalancing / Scaling 을 위해서는 여러 개의 Pod가 필요함. 이럴 때는 Pod를 개별적으로 정의하기 보다는 지정된 수의 Pod 복제본이 항상 실행되게 하는 ReplicaSet을 정의하여 사용할 수 있음.
- Kubernetes 구버전에서는 ReplicaController를 사용했었음.
- ReplicaSet 정의 YAML 형식
# 1. API 버전: ReplicaSet은 'apps/v1'을 사용합니다. (ReplicationController는 'v1') apiVersion: apps/v1 # 2. Kind: 생성할 리소스는 'ReplicaSet' 입니다. kind: ReplicaSet # 3. Metadata: ReplicaSet 자체의 이름과 라벨을 정의합니다. metadata: name: my-app-replicaset labels: app: my-app tier: frontend # 4. Spec: ReplicaSet의 상세 명세입니다. spec: # 생성하고 유지할 파드의 개수 replicas: 3 # ★★★ ReplicaSet이 관리할 파드를 찾는 기준 (필수 항목) selector: matchLabels: tier: frontend # ★★★ 생성할 파드의 설계도 (Pod Template) template: metadata: # 위 selector의 matchLabels와 일치해야 합니다. labels: tier: frontend spec: containers: - name: nginx image: nginx
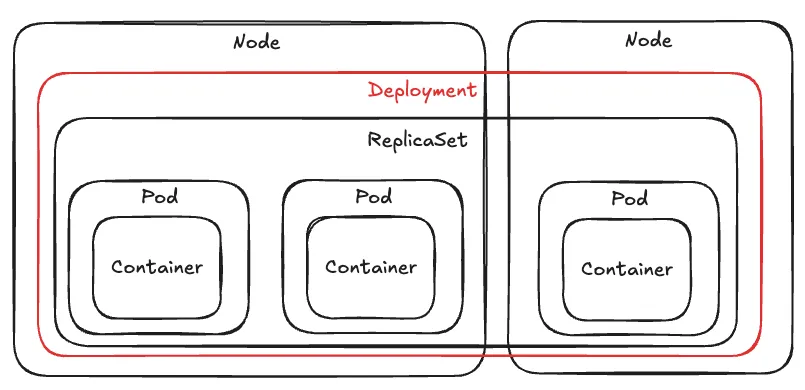
Kubernetes Resource - Deployment
- 단순히 여러 개의 Pod를 실행하는 ReplicaSet의 역할을 넘어 다음과 같은 배포 전략들이 필요할 때는 Deployment를 정의하여 사용할 수 있음.
- Rolling Update : 애플리케이션을 새 버전으로 배포할 때, 모든 Pod를 한 번에 중단하고 교체하는 것이 아니라, 일부 Pod만 순차적으로 교체하여 무중단 배포를 진행.
- Rollback : 새 버전 배포 후 심각한 오류가 발견되었을 때, 이전의 안정적인 버전으로 신속하게 되돌리는 기능.
- Pause & Resume : 진행 중인 Rolling Update를 잠시 멈추고, 필요한 작업을 마친 후 다시 시작할 수 있게 함. 배포 중간에 잠시 멈추고 디버깅하거나 추가 작업을 할 수 있음.
- Deployment, ReplicaSet, Pod는 계층 구조를 가지기 때문에 사용자가 Deployment를 생성하면 ReplicaSet과 Pod들도 자동적으로 생성됨.
- Deployment 정의 YAML 형식
# API 버전: ReplicaSet과 동일하게 'apps/v1'을 사용합니다. apiVersion: apps/v1 # ★★★ Kind: 생성할 리소스가 'Deployment'임을 명시합니다. kind: Deployment # Deployment 자체의 이름과 라벨을 정의합니다. metadata: name: my-app-deployment # Deployment의 상세 명세입니다. (ReplicaSet과 구조가 동일) spec: replicas: 3 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - name: nginx image: nginx
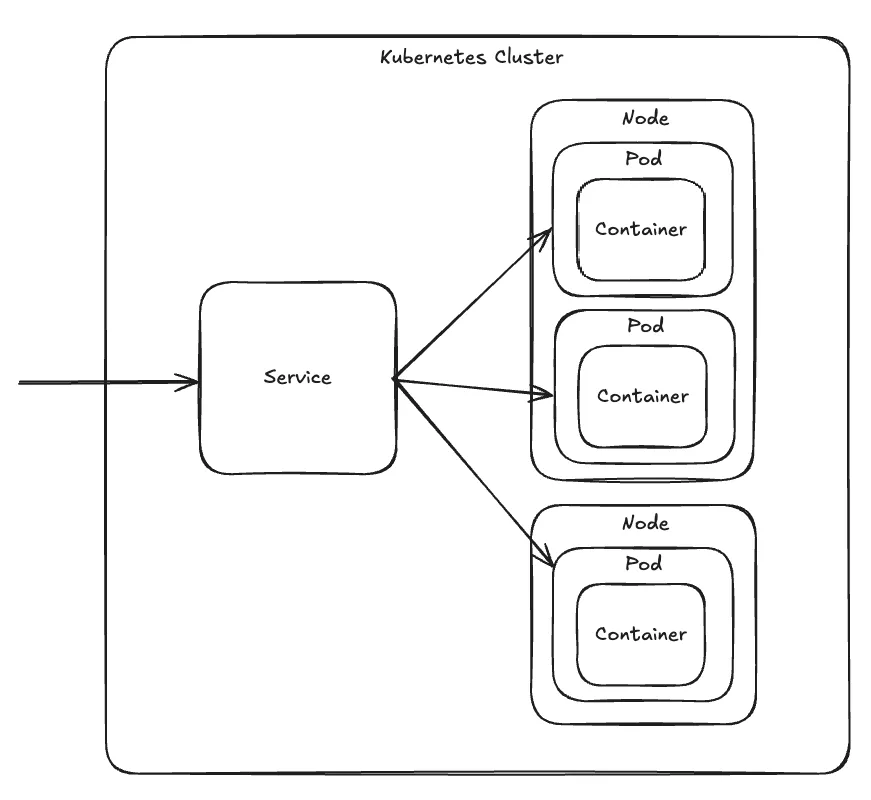
Kubernetes Resource - Service
- Pod IP만 가지고 통신하기에는 다음과 같은 문제점이 있어 Service가 필요함.
- Cluster 내부에서의 통신 : Pod가 재시작되거나 Scaling되면 IP가 바뀌기 때문에 이 IP로 통신하는 것은 불안정함. → ClusterIP 타입의 Service가 필요.
- Cluster 외부에서 들어온 통신 : Pod IP는 클러스터 내부에서 쓰이는 사설 IP이기에 외부에서 접근할 수 없음. → NodePort 또는 LoadBalancer 타입의 Service가 필요.
- 여러 개의 Pod에 트래픽을 자동으로 분산.
- Service는 다음 타입 중에 하나로 정의.
- ClusterIP : Cluster 내부에서만 접근 가능한 Virtual IP를 생성. ( NodePort나 LoadBalancer 타입의 Service도 기본적으로 ClusterIP 타입의 기능은 포함 )
- NodePort : 각 노드(Node)의 특정 포트를 외부에 개방하여, “노드IP:포트” 주소로 파드에 접근할 수 있게 한다.
- LoadBalancer : CSP(NCP, AWS, GCP 등)의 Load Balancer를 자동으로 생성하고 Service에 연결.
- Service가 생성되면 각 Node의 Kube Proxy에 iptables NAT 규칙이 추가되어 패킷을 Service IP → 특정 Pod IP로 변환이 되게 함.
- Service 정의 YAML 형식
-
ClusterIP Service
# 1. API 버전 apiVersion: v1 # 2. Kind: 생성할 리소스는 'Service' 입니다. kind: Service # 3. Metadata: 서비스의 이름을 정의합니다. 이 이름이 내부 DNS 이름이 됩니다. metadata: name: backend-service # 4. Spec: 서비스의 상세 명세입니다. spec: # ★★★ 서비스 타입을 'ClusterIP'로 지정 # 참고: type을 생략하면 기본값이 ClusterIP이므로, 이 줄은 생략 가능합니다. type: ClusterIP # 서비스를 연결할 파드를 찾는 셀렉터 selector: app: backend tier: api # 포트 매핑 정보 ports: - protocol: TCP port: 80 # 서비스 자체가 사용할 포트 targetPort: 8080 # 파드가 실제로 사용하는 포트 -
NodePort Service
# 1. API 버전 apiVersion: v1 # 2. Kind: 생성할 리소스는 'Service' 입니다. kind: Service # 3. Metadata: 서비스의 이름을 정의합니다. metadata: name: my-app-service # 4. Spec: 서비스의 상세 명세입니다. spec: # 서비스의 타입을 'NodePort'로 지정 type: NodePort # ★★★ 서비스를 연결할 파드를 찾는 방법 (필수 항목) selector: app: my-app # 포트 매핑 정보를 정의 (리스트 형태) ports: - protocol: TCP port: 80 # 서비스 자체의 포트 targetPort: 80 # 파드의 포트 nodePort: 30008 # 노드에 외부에 개방될 포트
-
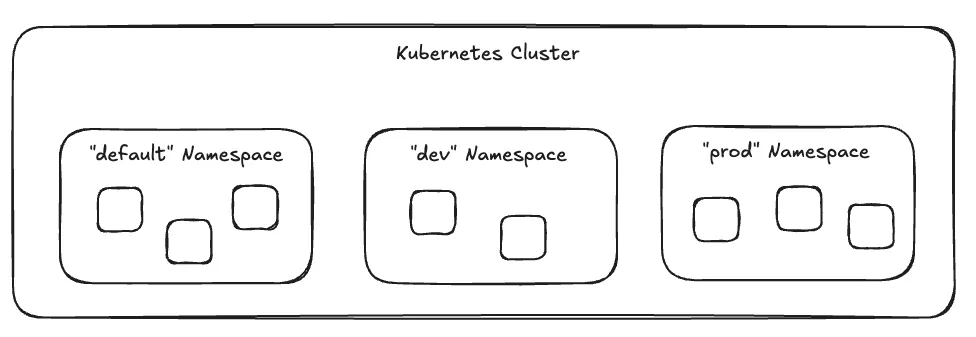
Kubernetes Resource - Namespace
- Kubernetes Cluster를 여러 개의 가상 Cluster 처럼 나누어 사용할 수 있게 해줌.
- 왜 여러 개의 가상 Cluster가 필요할까?
- 환경 분리 : 개발/스테이징/운영 환경 별로 분리를 한다거나, 팀 단위로 환경을 분리.
- 자원 할당 : Namespace 별로 사용할 수 있는 CPU, 메모리, Pod 개수 제한 가능.
- 접근 제어 : Namespace 별로 서로 다른 접근 권한을 부여하여 보안 강화.
- Namespace 내부/외부에 따른 Service 통신의 차이
- 내부 통신 : 같은 Namespace 내의 Service들은 서로의 Service 이름만으로 통신 가능. ( ex: db-service )
- 외부 통신 : 다른 Namespace에 있는 Service와 통신하려면 전체 주소를 사용해야 함. ( ex: <서비스명>.<네임스페이스명>.svc.cluster.local )
- Namespace / ResourceQuota 정의 YAML 형식
apiVersion: v1 kind: Namespace metadata: name: devapiVersion: v1 kind: ResourceQuota metadata: name: compute-quota namespace: dev spec: hard: pods: "10" requests.cpu: "4" requests.memory: 5Gi limits.cpu: "10" limits.memory: 10Gi
Kubernetes Resource 관리 방식 : 명령형 vs 선언형
- 명령형 : “어떻게(How)” 특정 작업을 수행할지 명시적으로 지시하는 방식. 사용자가 직접 명령어 하나하나를 입력하여 원하는 상태를 만듬. ( ex : kubectl run, create, expose, scale, edit )
- 선언형 : '무엇을(What)' 만들지 정의하는 방식. 사용자는 YAML 파일에 최종적으로 원하는 리소스의 상태를 기술하고, 쿠버네티스에게 이 파일을 전달. 쿠버네티스는 현재 상태와 사용자가 정의한 최종 상태를 비교하여 필요한 작업을 알아서 수행. 일반적으로 이 방식이 권장됨. ( ex : kubectl apply )
- 명령형, 선언형 방식을 혼용해서 사용하면 상태 정보가 꼬이 수 있으므로 하나의 방식만 일관되게 사용해야 함.
