Pod 수동 스케줄링 : Scheduler를 사용하지 않고 Pod를 특정 노드에 수동으로 할당 (권장되진 않음)
- Pod YAML 파일에 spec.nodename 필드 지정하는 방법
- 이 방법은 Pod를 처음 생성할 때만 가능하며, 이미 생성된 파드의 nodename은 수정 못 함
- Binding 객체를 통한 방법
- 이미 생성된 Pod를 Node에 할당 가능
- Scheduler도 이 방식으로 Pod를 Node에 할당
apiVersion: v1
kind: Binding
metadata:
name: nginx
target:
apiVersion: v1
kind: Node
name: node02Label과 Selector
- Label : key - value 형식의 쌍으로, 객체(리소스)의 특성을 정의하는 메타데이터
- Selector : Label을 기반으로 특정 조건에 맞는 객체를 필터링하거나 선택하는 데 사용
- Label을 이용한 k8s 객체 조회
kubectl get pods -l app=nginx,env=production- Selector를 통한 객체 간의 연결
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx # <-- 파드에 라벨을 붙임
tier: frontend
spec:
containers:
- name: nginx
image: nginx:1.14.2apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx # <-- 'app: nginx' 라벨을 가진 파드로 트래픽을 전달
ports:
- protocol: TCP
port: 80
targetPort: 80apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
spec:
replicas: 3
selector:
matchLabels:
app: nginx # <-- 'app: nginx' 라벨을 가진 파드를 찾음
template:
metadata:
labels:
app: nginx # <-- 파드 템플릿에 라벨을 정의
spec:
containers:
- name: nginx
image: nginxAnnotation
- Label과 달리 객체 필터링에 사용되지는 않고 단순히 정보 전달 목적의 메타 데이터값을 저장
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-with-annotations
labels:
app: nginx
annotations:
kubernetes.io/change-cause: "Initial deployment for version 1.0"
deployment.website.com/build-date: "2023-10-27"
deployment.website.com/commit-sha: "a1b2c3d4e5f6g7h8"
spec:
containers:
- name: nginx
image: nginx:latestTaint와 Toleration
- Taint : Node에 설정되어 특정 Pod들이 그 Node에 스케줄링되는 것을 막음
- NoSchedule : Taint를 허용하지 않는 Pod는 해당 Node에 절대 스케줄링되지 않음
- PreferNoSchedule : Scheduler가 해당 Node를 피하려고 노력하지만, 반드시 피하는 것은 아님
- NoExecute : Taint를 허용하지 않는 Pod라면 해당 Node에 스케줄링되지 않을 뿐 아니라 이미 실행 중인 Pod도 Node에서 즉시 제거됨
kubectl taint nodes node1 app=blue:NoSchedule- Toleration : Pod에 설정되어 Taint된 Node에도 스케줄링될 수 있도록 허용
apiVersion: v1
kind: Pod
metadata:
name: special-pod
spec:
containers:
- name: my-container
image: nginx
tolerations:
- key: "app"
operator: "Equal"
value: "blue"
effect: "NoSchedule"- Taint와 Toleration은 Pod가 어떤 노드에 갈 수 있는지를 제한하지만, 특정 노드로 가도록 강제하지는 못함
- Master Node도 기본적으로 Taint가 설정되어 있기 때문에 일반 Pod들이 스케줄링되지 않는 것임
Node Selector
- Node에 지정된 Label을 사용해 Pod가 특정 Node에만 배치되도록 지정하는 기능
kubectl label nodes <노드이름> disktype=ssdapiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
nodeSelector:
disktype: ssd
containers:
- name: my-container
image: my-image- k8s Scheduler는 nodeSelector에 지정된 Label을 가진 Node에만 Pod를 스케줄링. 조건에 맞는 Node가 없다면 Pod는 Pending 상태로 남아있음.
- ‘OR’이나 ‘IN’ 같은 논리 조건 표현이 불가능. 반드시 특정 Node에 배치해야 하는 상황이 아닌 특정 Node에 배치하는 것을 선호하기만 하는 상황에서는 부적합함.
Node Affinity
- node selector보다 더 자세한 조건으로 Pod를 특정 Node에 배치시키는 기능.
apiVersion: v1
kind: Pod
metadata:
name: my-pod-with-affinity
spec:
# Node Affinity 규칙을 정의합니다.
affinity:
nodeAffinity:
# 필수 규칙: 스케줄링 시 반드시 일치하는 노드가 필요합니다.
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: my-container
image: nginx- requiredDuringSchedulingIgnoredDuringExecution : Pod가 반드시 조건에 맞는 노드에 스케줄링되어야 함을 의미. 만약 조건에 맞는 노드가 없으면 Pod는 Pending 상태로 남음
- preferredDuringSchedulingIgnoredDuringExecution: Pod가 조건에 맞는 노드에 스케줄링되는 것을 선호하지만, 만약 그런 노드가 없으면 다른 노드에 스케줄링될 수 있음을 의미
- In, NotIn, Exists, DoesNotExist 등 다양한 연산자를 사용하여 복잡한 규칙을 정의 가능
Taint & Toleration과 Node Affinity 를 같이 사용하여 특정 Node를 특정 Pod 전용으로 만들기
- Taint & Toleration만 사용시 한계 : Taint & Toleration은 다른 Pod를 막는 역할은 하지만, 우리 Pod가 '반드시 우리 노드로 가야 한다'고 강제하지는 않음. 따라서 다른 팀이 사용하는, Taint가 설정되지 않은 노드에 우리 Pod가 배치될 수 있음.
- Node Affinity만 사용시 한계 : Node Affinity는 '우리 Pod를 우리 노드로 보내는' 역할은 하지만, 다른 팀의 Pod가 해당 노드로 들어오는 것을 막지 못함. 다른 팀 Pod에 nodeAffinity 규칙이 없거나 해당 노드에 배치될 조건이 충족되면 우리 노드에 들어올 수 있음.
- 두 개념을 같이 사용하면 다른 팀 Pod는 Taint 때문에 우리 Node에 들어올 수 없고, 우리 Pod는 Node Affinity 규칙 때문에 다른 Node로 가지 않고 전용 Node에만 배치됨.
Resource Requests & Resource Limits
- Resource Requests : Pod가 실행되기 위해 최소한으로 필요로 하는 CPU와 메모리 양 지정
- Resource Limits : Pod가 최대로 사용할 수 있는 CPU와 메모리 양 제한
- cpu가 한도를 초과해서 사용되면 throttling이 일어나 계속 실행되지만, 메모리가 한도를 초과해서 사용되면 Out of Memory로 종료됨.
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"- Resource 설정 시나리오별 작동 방식
- Requests와 Limits 모두 없음: Pod가 노드의 모든 자원을 사용할 수 있어 다른 Pod나 프로세스에 영향을 줄 수 있음
- Requests는 없고 Limits만 있음: Kubernetes가 자동으로 Requests를 Limits와 동일하게 설정
- Requests와 Limits 모두 설정: Pod는 요청량(requests)만큼 자원을 보장받고, 한도(limits)까지 자원을 사용
- Requests만 설정하고 Limits는 없음: Pod는 요청량만큼 자원을 보장받음. 노드에 여유 자원이 있는 한 최대한 많은 자원을 사용할 수 있습니다. 이는 CPU에는 이상적이지만, 메모리에는 위험할 수 있음. 메모리의 경우 Pod가 무한정 사용하다가 다른 Pod의 자원을 침해할 수 있으며, 이럴 경우 Pod를 종료시키는 방법 외에는 대안이 없음
- LimitRange : 특정 namespace에서 만들어지는 Pod의 기본 Resource Requests & Resource Limits를 지정
apiVersion: v1
kind: LimitRange
metadata:
name: limit-range-example
namespace: test-limit-range # 생략시 default 네임스페이스
spec:
limits:
- default: # 기본 Limit
cpu: 500m
memory: 512Mi
defaultRequest: # 기본 Request
cpu: 200m
memory: 256Mi
max: # namespace에서 설정할 수 있는 최대 리소스
cpu: 1
memory: 1Gi
min: # namespace에서 설정할 수 있는 최소 리소스
cpu: 100m
memory: 128Mi
type: Container- Resource Quota : namespace 전체가 사용할 수 있는 CPU와 메모리 총량을 제한.
apiVersion: v1
kind: ReesourceQuota
metadata:
name: my-resource-quota
spec:
hard:
requests.cpu: 4
requests.memory: 4Gi
limits.cpu: 10
limits.memory: 10GiDaemonSet
- ReplicaSet과 유사하게 여러 개의 Pod를 배포하지만, Pod가 모든 Node에 하나씩만 존재하도록 보장하는 k8s 리소스
- 모니터링이나 로그 수집 목적의 파드를 배포할 때 주로 사용
- kube-proxy도 DaemonSet으로 관리됨
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: monitoring-daemon
spec:
selector:
matchLabels:
app: monitoring
template:
metadata:
labels:
app: monitoring
spec:
containers:
- name: my-container
image: nginxStatic Pod
- kubelet이 kube-api-server의 개입 없이 직접 관리하는 Pod. 즉 master node의 구성요소들이 없어도 독립적으로 실행될 수 있음
- kubelet을 실행할 때 지정한 디렉토리 경로에 Pod 정의 파일을 배치하면, kubelet이 주기적으로 확인하여 Pod를 생성&변경&삭제함
- Static Pod가 생성되면 미러 객체가 생성되어 kubectl로 조회는 할 수 있지만, kubectl로 수정&삭제는 불가능
Priority Class
- Pod에 스케줄링 우선순위를 부여하는 k8s 리소스
- 중요한 Pod가 낮은 우선순위의 Pod보다 먼저 스케줄링되도록 보장
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods."apiVersion: v1
kind: Pod
metadata:
name: my-high-priority-pod
spec:
containers:
- name: my-container
image: nginx
priorityClassName: high-priority # <-- 여기에 priority class 이름을 지정- Preemption Policy 필드
- PreemptLowerPriority : 기본값이며, 이는 낮은 우선순위의 Pod를 제거하여 공간을 확보함
- Never : 해당 Pod는 다른 Pod를 선점(preempt)하지 않고, 스케줄링 큐에서 대기함. 하지만 대기 중인 다른 낮은 우선순위 Pod보다는 먼저 스케줄링됨
Custom Scheduler
- k8s에서는 기본 scheduler가 있지만, 특정 상황에서는 부가적인 스케줄링 조건을 추가하기 위해 Custom Scheduler가 필요할 수 있음
- Pod & Deployment 형태로 배포되는 것이 권장됨.
- Custom Scheduler를 사용하려는 Pod에 schedulerName으로 지정
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
schedulerName: my-custom-scheduler # <-- 스케줄러 이름 지정
containers:
- name: my-container
image: nginx- 스케줄링 동작 과정
- 스케줄링 큐 (Scheduling Queue)
- 새로 생성된 파드는 스케줄링 큐에 들어감
- 우선순위(Priority)에 따라 정렬. 우선순위가 높은 파드가 먼저 처리.
- Priority Sort 플러그인이 이 정렬 작업을 수행
- 필터링 (Filtering)
- 파드를 실행할 수 없는 노드들을 걸러내는 단계
- Node Resources Fit: 파드의 리소스(CPU, 메모리) 요구사항을 충족하지 못하는 노드를 제외
- Node Name: 파드 스펙에 nodeName이 지정된 경우, 해당 노드만 남기고 나머지를 제외
- Node Unschedulable: 스케줄링 불가능(Unschedulable) 플래그가 설정된 노드를 제외
- 스코어링 (Scoring)
- 필터링을 통과한 노드들에 점수를 매기는 단계
- Node Resources Fit: 파드를 할당한 후 남는 여유 리소스가 많은 노드에 높은 점수를 부여
- Image Locality: 파드가 필요로 하는 이미지를 이미 가지고 있는 노드에 높은 점수를 부여
- 이 단계에서는 노드 할당이 거부되지 않고, 단지 점수만 매겨짐
- 바인딩 (Binding)
- 가장 높은 점수를 받은 노드에 파드를 최종적으로 할당하는 단계
- Default Binder 플러그인이 이 바인딩 작업을 수행
- 스케줄링 큐 (Scheduling Queue)
- 각 스케줄링 단계의 특정 지점( ex: preFilter, filter, postFilter, score… )에 커스텀 코드(플러그인)를 삽입할 수 있음
Scheduler Profiles
- 여러 개의 Scheduler 사용시 각각의 Scheduler 프로세스를 실행해야 하기 때문에 관리가 어렵고, Race Condition이 발생할 수도 있음. 때문에 단일 Scheduler Process 내에서 여러 개의 Scheduler Profile을 구성할 수 있는 기능이 도입됨.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: default-scheduler
- schedulerName: batch-scheduler
plugins:
preFilter:
disabled:
- name: "TaintToleration"
filter:
disabled:
- name: "TaintToleration"
score:
disabled:
- name: "ImageLocality"Admission Controller
-
쿠버네티스 API 서버에서 인증(Authentication) 및 인가(Authorization)를 통과한 요청을 최종적으로 처리하기 전에, 요청을 검증하거나 수정하는 역할
-
RBAC(역할 기반 접근 제어)와 같은 인가(Authorization) 메커니즘은 "어떤 사용자가 어떤 종류의 API 작업(예: 파드 생성, 삭제 등)을 수행할 수 있는가?"를 정의합니다. 하지만 "사용자가 생성하려는 파드에 특정 정책을 적용하는가?"와 같은 더욱 세부적인 제어는 불가능. 이런 상황에 Admission Controller가 필요
-
동작 과정
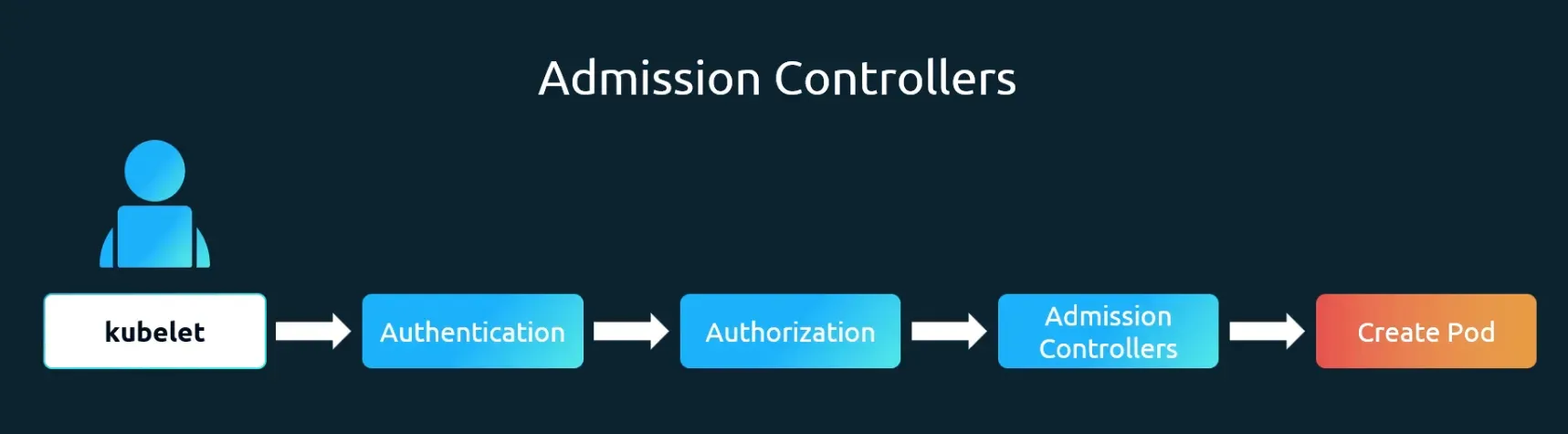
- 요청 접수: kubectl을 통해 API 서버로 요청이 전달
- 인증: 요청을 보낸 사용자가 유효한지 확인
- 인가: 사용자가 해당 작업을 수행할 권한이 있는지 확인
- Admission Controller: 인가 단계를 통과한 요청은 여러 어드미션 컨트롤러 플러그인을 순차적으로 거침
- Validating Admission Controller: 요청의 유효성을 검사. 예를 들어, NamespaceLifeCycle 컨트롤러는 파드가 생성될 네임스페이스가 실제로 존재하는지 확인
- Mutating Admission Controller: 요청 내용을 변경. 예를 들어, DefaultStorageClass 컨트롤러는 PVC에 스토리지 클래스가 지정되지 않았을 때 기본값을 자동으로 추가
- etcd에 저장: 모든 단계를 통과한 요청은 etcd 데이터베이스에 최종적으로 저장
-
내장된 Admission Controller
- AlwaysPullImages : 컨테이너 이미지가 항상 새로운 버전으로 풀(pull)되도록 강제하는 역할
- DefaultStorageClass : Pod가 PVC(PersistentVolumeClaim)를 생성할 때 명시적인 storageClassName을 지정하지 않으면, 자동으로 클러스터에 설정된 기본 스토리지 클래스를 할당
- EventRateLimit : 클러스터에서 생성되는 이벤트의 양을 제한하여 API 서버의 과부하를 방지
- NamespaceLifecycle : 존재하지 않는 네임스페이스에 대한 요청을 거부하고, default, kube-system과 같은 중요한 시스템 네임스페이스가 삭제되는 것을 막음
-
웹훅을 기반으로 한 Custom Admission Controller를 사용할 수도 있음
