Abstract
- 인공신경망은 layer의 수가 깊어질 수록 훈련이 어려워짐
- 본 논문에서는 layer의 수를 매우 많이 쌓아올린 심층 신경망의 학습을 효과적으로 진행하기 위한 Residual learning을 제안
- 기존의 H(x)와 x와의 관계를 학습하는 대신 Residual function을 학습하도록 신경망을 재구성하여 깊이를 크게 증가시키면서도 정확도를 높임
1. Introduction
- 이미지 분류의 성능을 높이고, 난이도 높은 분류 문제를 풀기 위해 layer를 깊게 쌓아올린 모델을 사용하는 추세
- 하지만, layer가 깊어질 수록 기울기 소실/폭발 문제와 성능이 저하되는 문제가 발생
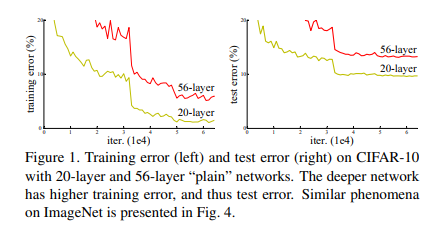
(56-layer 신경망이 20-layer 신경망보다 error가 높다)
- 이 문제를 해결하기 위해 layer가 목표 함수 H(x)를 학습하는 대신 H(x) - x, 즉 목표 함수와 입력값과의 차이(잔차)를 학습하도록 Residual learning을 진행
- Residual learning은 shortcut connection을 통해 구현되는데, 입력값이 layer를 거치지 않고, layer의 결과에 단순히 입력값을 그대로 더해주는 것으로 수행할 수 있음
3. Deep Residual Learning
-
Residual learning은 몇 개의 layer마다 적용하는데, 적용의 기준이 되는 block은 아래와 같이 정의됨
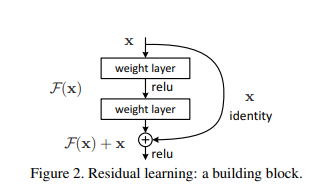
-
구체적으로는 가 되며, 와 의 차원이 동일하지 않으면 더하기 연산을 수행하지 못하기 때문에 더해줄 에 추가적인 선형변환을 수행해야 함
-
본 논문에서 구현된 ResNet은 Convolution layer를 수행할 때마다 특정 구간에서 필터 수를 x2로 늘리기 때문에 필터가 늘어나는 layer 구간부터 선형변환이 필요함. 이때, 적용할 수 있는 방법은 zero padding으로 전부 0으로 매핑시켜서 차원수를 맞추거나, 1x1 Convolution을 적용하여 정보 손실을 줄이는 방향으로 선형 변환하는 2가지 방법이 있음
-
마지막에는 Global Average pooling을 적용하여 각 채널의 2차원 행렬을 하나의 스칼라값으로 변환
4. Experiments
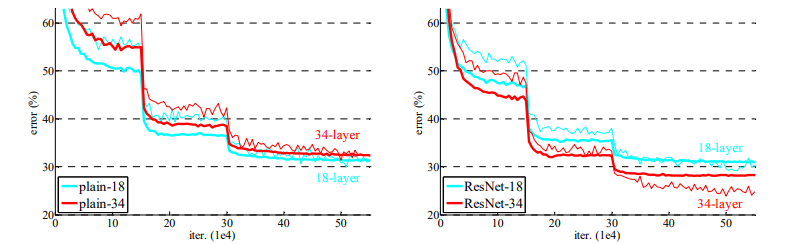
-
ResNet이 일반 신경망보다 일관되게 좋은 성능을 보임
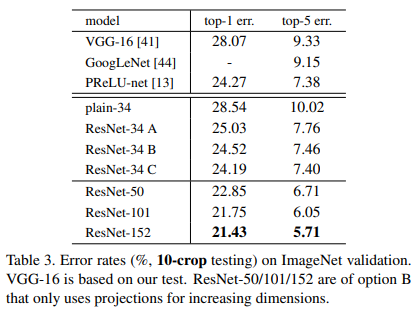
-
ResNet-34 A는 차원수가 늘어날 때 선형변환 방법으로 제로패딩 적용, B는 1x1 Convolution을 적용한 projection connection 적용, C는 모든 Skip connection에서 projection connection을 적용
-
A, B, C중 C가 제일 우수한 성능을 보였으나, 그 성능 차이가 크지 않았고, 메모리 및 시간복잡도 측면에서 C는 불리하므로 다른 실험에서는 C를 적용하지 않음
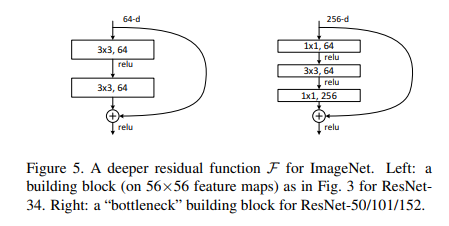
Deeper Bottleneck Architectures
- 하지만, 기존 ResNet구조는 몇 십개의 깊은 layer수와 연산량으로 엄청난 메모리와 시간이 소비됨. 따라서, 효율적인 연산을 위한 Deeper Bottleneck 아키텍처를 제안.
- 핵심은 Input을 1x1 Convolution을 통해 축소시켜 주요 연산이 이루어지는 3x3 Convolution의 연산량을 획기적으로 줄일 수 있음
요약
ResNet은 layer를 깊게 쌓을 수록 오히려 학습이 어려워지는 문제를 해결하기 위해 나온 network이다. ResNet의 핵심은 Skip Connection을 통해 입력 값 x를 직접 전달시킴으로써 다음 layer가 입력값 정보를 직접 참조하게 하여 정보의 손실을 방지한다. 그리고 학습해야 할 목표 함수와 x의 차이(기울기)를 직접 학습하는 대신 목표 함수 H(x)에 x를 뺀 차이(잔차)만큼만 학습을 하여 기울기가 급격하게 소실, 폭발되는 상황을 줄여 layer를 깊게 쌓아도 학습이 잘 되도록 유도하는 아키텍처라고 할 수 있다.
