Abstract
-
BERT는 모든 계층에서 모든 문맥을 양방향으로 모두 고려한 비지도 학습을 통해 단어의 의미를 효과적으로 사전학습한 모델
-
이렇게 학습된 모델은 각 task 목적에 맞게 하나의 output layer를 추가하는 것만으로 QA, Language inference와 같은 여러 task를 잘 수행하는 SOTA모델을 만들 수 있음
1. Introduction
-
기존 언어 모델은 왼쪽에서 오른쪽으로 학습되는 단방향 학습을 수행하는데, self-attention layer에서 각 토큰을 예측하기 위해 그 이전 토큰들의 attention만 계산됨
-
이러한 단방향성에 기반한 학습 방법은 문장의 의미를 파악하거나, QA와 같이 문맥 전부를 고려해야 하는 작업에서는 매우 부정적인 영향을 미칠 수 있음
-
따라서, BERT는 입력 토큰의 일부를 랜덤으로 masking하고, 주변의 토큰 정보만으로 본래 masking된 token이 무엇인지 예측하는 것을 목표로 사전학습을 진행
-
이후에는 다음 문장이 문맥 상 이어지는 문장인지 예측하는 학습까지 이어서 진행하여 문장 쌍 표현을 함께 사전학습
3. BERT
-
비지도 학습으로 방대한 문서를 양방향 사전 학습한 사전 학습 단계, 사전 학습된 BERT를 각 task에 최적화 하기위해 라벨링된 데이터를 사용하여 지도 학습으로 파인 튜닝하는 단계 2-Stage로 이루어짐
-
BERT의 Input은 우리가 생각하는 일반적인 완성된 형태의 문장 이외에도 여러 개의 문장, 문법적으로 불완전한 문장, 짫은 텍스트 등 모든 형태가 포함
-
모든 I/O에서 첫 번째 토큰은 [CLS] 토큰이며, 분류 task일 경우 [CLS] 출력 벡터를 Downstream task에서 입력으로 활용
-
[SEP] 토큰은 문장 쌍을 구분하며, 각 토큰이 첫 문장인지 두 번째 문장인지 나타내는 추가적인 정보가 포함
3.1 Pre-training BERT
Task #1: Masked LM
-
각 시퀀스에서 15%의 토큰을 랜덤으로 마스킹 후 마스킹된 토큰에 해당하는 임베딩을 전체 어휘에 대해서 softmax를 사용하여 제일 확률이 높은 토큰을 예측하고, Cross-entropy로 실제 정답과 예측 토큰과의 loss를 학습
-
하지만, 실제 파인 튜닝을 할 때는 [MASK] 토큰을 사용하지 않기 때문에사전 학습과정에서의 학습 패턴과 파인 튜닝의 실제 Input과의 차이가 발생
-
모델이 [MASK]에 의존하지 않도록 선택된 토큰에서 80%는 [MASK] 토큰으로 대체, 10%는 무작위 토큰으로 대체, 10%는 변경하지 않고 그대로 유지하여 다양한 입력 패턴에 대응할 수 있도록 함
Task #2: Next Sentence Prediction (NSP)
-
QA, NLI와 같은 중요한 task에서 두 문장 간의 관계를 이해하는 것이 중요함
-
따라서, 사전 학습에 다음 문장을 예측하는 작업을 추가
-
50%의 데이터는 B가 A다음에 실제로 나오는 문장으로, 나머지 50%의 데이터는 A다음에 나오는 문장을 무작위로 설정
Pre-training data
-
BooksCorpus (800백만 토큰, Zhu et al., 2015)
-
Wikipedia (2500백만 토큰). Wikipedia에서는 텍스트 본문만 추출하며, 목록, 표, 제목은 제외
-
문장 수준 데이터가 아닌 문서 수준 말뭉치를 사용하는 것이 중요했음
3.2 Fine-tuning BERT
- sequence tagging, QA와 같은 토큰 task는 라벨로 모든 token을 입력으로, 감정 분석과 문장 분류와 같은 분류 task는 [CLS] 토큰을 입력으로 downstream task에서 사용
4 Experiments
- 11개 NLP task에서의 파인튜닝 된 BERT의 성능은 아래와 같음
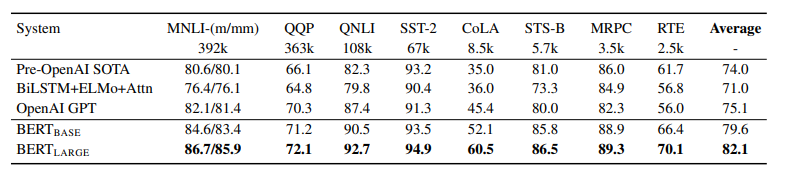
4.1 GLUE
-
문장이 질문에 대한 답을 포함하고 있는지, 두 문장의 유사도 차이, 감성 분석, 문장의 동의어 여부, 질문의 중복 여부 등에 대한 분류 문제를 Accuracy, F1 score, Pearson correlation metric으로 측정
-
[CLS] 토큰의 벡터 와 classification layer의 (K는 label 수) 가중치를 를 통해 loss계산
-
batch size : 32, epoch : 3, learning rate : 5e-5 ~ 2e-5
-
작은 데이터셋에서의 불안정한 파인튜닝 방지를 위해 초기 가중치와 데이터를 랜덤으로 설정해 여러 번 수행해서 그중 가장 좋은 성능을 보인 모델 선택
4.2 SQuAD v1.1
-
질문과 위키백과 문단을 제공하면, 문단에서 답변의 텍스트 범위를 예측하는 task
-
입력으로 질문과 문단을 같이 제공하며 질문은 A 임베딩, 문단은 B 임베딩을 사용
-
fine tuning과정에서 시작 벡터 와 종료 벡터 도입
-
각 단어 가 정답 문장의 시작, 정답 문장의 마지막일 확률을 각각 내적한 후 softmax를 통해 loss 계산
-
batch size : 32, epoch : 3, learning rate : 5e-5
-
조건에서 가 최대인 범위를 예측
4.3 SQuAD v2.0
-
답변이 없는 질문은 [CLS]토큰 위치를 예측하도록 학습
-
따라서, 답변이 없는 경우에는 [CLS] 토큰에 대한 점수를 계산
-
으로 답변 유무 판단 ( = threshold)
-
batch size : 48, epoch : 2, learning rate : 5e-5
4.4 SWAG
-
주어진 문장(문장 A) 뒤에 이어질 가장 그럴듯한 문장(문장 B)을 네 가지 선택지 중에서 고르는 task
-
입력으로 각 선택지의 [CLS] 토큰 임베딩을 추출
-
임베딩 차원 크기의 벡터와 내적한 값을 softmax를 통해 loss 계산
-
batch size : 16, epoch : 3, learning rate : 2e-5
5.2 Effect of Model Size
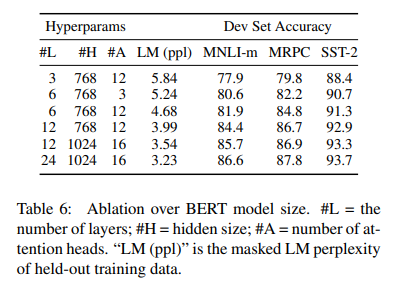
- MPRC는 데이터셋이 3600개로 소규모에 사전 학습과 관련이 별로 없는 task임에도 불구하고, 모델 크기를 늘리는 것만으로도 성능이 개선됨 => 아주 작은 데이터셋에서도 모델 크기를 증가시키는 것이 큰 성능 향상으로 이어짐
Conclusion
-
방대한 비지도 학습 사전 훈련은 곧 모델의 언어 이해 능력 향상으로 이어지고, 이는 다양한 NLP task에서의 높은 성과로 나타남
-
다양한 NLP task를 하나의 공통된 아키텍처 사용으로 수행할 수 있고, low-resource로도 높은 성능을 발휘
소감
BERT는 GPT와 다르게 Transformer의 Encoder 아키텍처만을 취한 모델로 입력 시퀀스의 토큰을 무작위로 마스킹 처리한 뒤 마스킹 된 토큰을 예측하는 방식으로 문맥과 단어의 의미를 효과적으로 학습한다. 하지만, BERT가 가장 빛났던 부분은 단순히 MLM을 넘어서 일부 MASK는 랜덤한 토큰으로 바꾸거나, NSP 학습을 추가적으로 진행하여 다양한 NLP task에서의 일반화된 높은 성능을 담보하도록 여러 detail을 더해줬다는 게 아닌가 싶다.
