Abstract
- 오픈 도메인 질의응답은 답변을 위해 참고할 문서를 검색하는 것이 중요
- 지금까지의 문서 검색은 보통 TF-IDF, BM25와 같은 sparse vector 모델로 이루어짐
- 해당 논문은 2개의 인코더를 학습해서 소수의 질문과 문장을 dense로 표현하여 기존의 BM25기반 검색 정확도를 넘어서는 새로운 retrieval를 제시
1 Introduction
- Open-domain question answering(이하 ODQA)는 엄청나게 많은 정보들을 포함하고 있는 대량의 문서(예: 위키피디아)들로부터 주어진 질문에 대한 답변을 찾는 문제
- 주어진 질문이 어떤 도메인에 해당되는 질문인지, 어떤 키워드인지에 대한 힌트는 전혀 주어지지 않는다.
보통 답변을 위해서,
(1) context retrieval가 질문에 대한 답이 포함된 몇 가지 문서를 선택
(2) machine reader가 1에서 검색된 문맥을 검사하여 정답 도출
2-stage로 이루어짐
- dense 기반 인코딩은 sparse표현을 보완하는 역할을 하는 데, 예를 들어
"Who is the bad guy in lord of the rings?"
라는 질문에
“Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy.”
라는 문맥이 필요하다고 가정해보자
기존의 단어 기반 시스템은 bad guy와 villain의 유사성을 찾기 어렵지만, dense retriaval는 두 단어를 더 잘 매칭할 수 있음
- 이 논문은 인코더의 추가 학습 없이, BERT와 dual-encoder 아키텍처를 활용하여 질문 벡터와 질문과 관련된 문서 벡터의 내적을 최대화 하는 방향으로 인코더를 학습
2 Background
- ODQA task는 “Who first voiced Meg on Family Guy?”, “Where was the 8th Dalai Lama born?"와 같은 사실을 묻는 질문에 다양한 주제가 있는 large copus의 span으로 답변하는 task
- 컬렉션에 D개의 문서 가 있고,
- 각 문서를 동일 길이의 passage로 나누어 검색의 기본 단위로 사용하여 코퍼스에서 M개의 passage를 얻음
- 여기서 각 passage 는 와 같은 토큰 시퀀스로 이루어져 있음
- 질문 q가 들어오면, passage의 토큰에서 질문에 대한 답변을 찾을 수 있음
- 정리하면, 검색기 R : (q, C) → CF는 질문 q와 코퍼스 C를 입력으로 받아들이고, 질문과 관련된 상위-k개의 코퍼스를 추려서 코퍼스에 질문에 답변할 수 있는 span이 포함되어 있는지의 여부로 정확도를 파악
3 Dense Passage Retriever (DPR)
- Dense Passage Retriever(이하 DPR)의 목표는 모든 문장을 저차원 연속 공간에 인덱싱하여, 입력된 질문에 대해 관련된 상위 k개의 문장을 효율적으로 검색하는 것
3.1 Overview
- DPR은 dense encoder를 사용해서 d차원의 벡터로 모든 문장을 매핑해서 검색에 사용할 모든 구절 M에 대한 인덱스를 구축
- 또 다른 인코더는 d차원의 벡터로 입력 질문을 매핑하여 구절 벡터와 질문 벡터를 내적해서 문제와 구절의 유사도를 구함
- 인코더는 768차원의 [CLS]토큰을 output으로 배출하는 BERT를 사용
- FAISS 라이브러리를 사용해서 질문 벡터와 가까운 top k개의 문장 벡터를 검색
3.2 Training
-
학습의 목표는 질문과 관련된 문서가 그렇지 않은 문서보다 높은 유사도를 가지는 Vector space를 만드는 것
-
훈련 데이터 D는 m개의 인스턴스로 구성되어 있고, 하나의 질문 , 하나의 긍정 문서 , 여러 개의 부정 문서 로 이루어짐
-
loss function은 negative log likelihood를 사용
-
관련된 문서에 대해 높은 유사도, 관련 없는 문서에는 낮은 유사도가 산출되는 방향으로 학습
-
긍정 데이터셋은 선정하는 것이 쉽지만 부정 데이터셋은 그 수가 매우 방대하기 때문에
Random: 랜덤으로 선정하거나,
BM25: 답변을 포함하지 않으면서 BM25에서 질문과 유사하다고 판단된 문서를 선정하거나,
Gold: 다른 데이터의 긍정 문서를 사용하는 3가지를 고려하여 데이터셋 구축
-
in-batch negative: n개의 질문과 긍정 문서의 임베딩 값 Q, P에 대해서 를 수행하면 유사도 행렬이 생기는 데, (Qi,Pj) 쌍이 i = j로 같으면 긍정 예제로 구분하고 그렇지 않으면 부정 예제로 구분해서 효율적인 학습
4 Experimental Setup
-
위키피디아 데이터를 전처리하여 위키피디아 문서의 제목과 [SEP]토큰을 추가해서 100단어 단위의 문서로 passage를 만듬
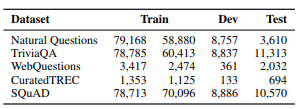
-TREC, WebQuestions, TriviaQA 데이터셋은 질문, 답변 쌍만 제공되기 때문에 BM25의 상위 문서를 긍정 문서로 사용하고, 답변이 포함된 문서가 없는 경우 폐기
(그럼 BM25와 같은 방향으로 학습되는게 아닌가?) -
실험 결과 정확도가 1% 낮은 정도로 큰 차이가 나지 않음
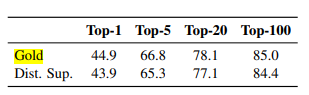
-
SQuAD와 Natural Questions의 경우 데이터셋의 패시지와 해당하는 위키피디아 전처리 문서를 매칭해서 교체
5 Experiments: Passage Retrieval
- 배치 사이즈 128 / in batch Negative / 하나의 BM25 부정 문서
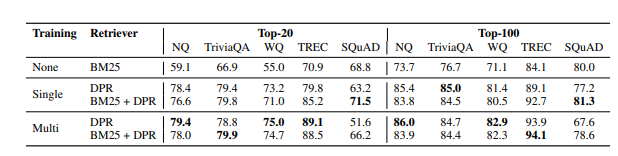
- BM25+DPR의 경우 DPR에 10%의 가중치를 부여하여 랭킹 계산
- SQuAD의 성능이 낮은 이유는 데이터셋을 구축할 때 문서를 보고 질문 데이터를 구축했기 때문에 어휘적으로 데이터셋과 문서간 단어 중복이되어 BM25에 유리
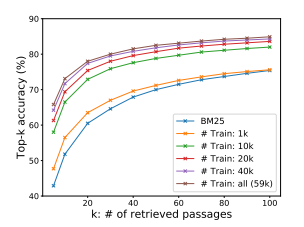
- 1000개 데이터를 학습하는 것만으로도 BM25의 성능보다 높음
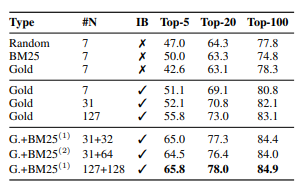
- Top Block : k=20 이상인 경우에는 부정 문서의 종류는 상관이 없음
- Middle Block : in-batch training은 효과적이며 배치 크기가 클 수록 성능이 높아짐
- Bottom Block : 데이터셋을 구축할 때 각 데이터마다 하나의 최상위 부정 문서를 추가하는 것만으로도 성능 향상
6 Experiments: Question Answering
6.1 End-to-end QA System
- 질의응답 시스템을 구축하기 위한 대략적인 메커니즘은
- Retriever가 top k 문서(최대 100개)를 검색
- Reader는 검색된 문서에서 가장 점수가 높은 문서를 선택하고, 해당 문서에서 가장 점수가 높은 토큰을 추출해서 정답으로 채택
- 문서 선택 점수는 해당 문단이 답변을 포함할 확률
- 토큰 선택 점수는 문서 내의 n번 째 토큰이 답변일 확률로 구함
6.2 Results
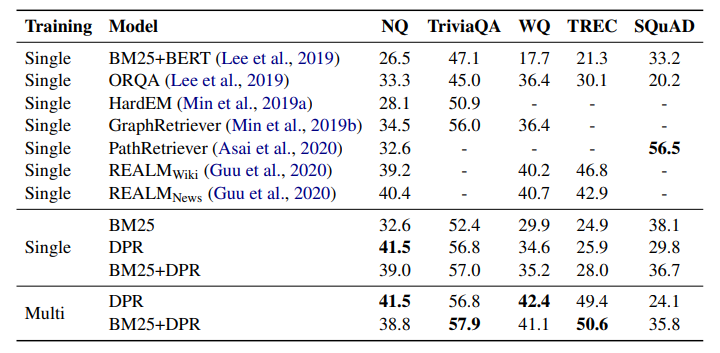
- SQuAD를 제외한 모든 데이터셋에 대해서 SOTA달성
