Abstract
-
BERT와 RoBERTa는 두 문장의 의미론적 유사성을 추론하는 STS와 같은 task에서 높은 성능을 보임
-
하지만, 두 문장을 전부 모델에 입력값으로 넣어야하기 때문에 엄청난 overhead 발생
-
가령, 10,000개의 문장에서 가장 유사한 문장 쌍을 찾으려할 때 무려 5000만 번 이상의 연산(65시간)을 거쳐야 함
-
그러므로 BERT구조는 문장의 유사도 검색이나, 클러스터링과 같은 비지도task에 적합한 구조가 아님
-
따라서 우리는 Siamese와 triplet network구조를 사용한 사전학습된 BERT구조를 수정한 Sentence-BERT(SBERT)를 제안함
-
이 SBERT는 문장의 의미를 임베딩 된 문장에 반영되게 하는 것이 목적으로 코사인 유사도를 활용하여 두 문장 간의 의미가 얼마나 유사한지 비교 가능
-
SBERT는 65시간이 걸리던 소요 시간을 5초로 획기적으로 줄이면서도 BERT에서의 정확도는 그대로 유지함
-
SBERT와 SRoBERTa는 STS task와 전이학습 task에서 다른 SOTA 문장 임베딩 방법론과 비교해서 우수한 성능을 보임
Related Work
- 문장 쌍 회귀 task를 위한 BERT의 입력으로는 [SEP]토큰으로 분리된 2개의 문장이 들어가고, Multi-head attention layer를 통과한 후, 간단한 회귀 함수를 거쳐 최종적인 label 출력을 내뱉음
- BERT 구조의 가장 큰 단점은 각각의 문장 임베딩을 독립젹으로 계산할 수 없기 때문에 BERT에서는 문장 임베딩을 구하기가 어려움
- 그래서 단일 문장을 BERT에 통과시켜 출력의 평균을 구하거나, 최대 풀링을 이용한 BiLSTM을 훈련시키는 등 여러 시도를 해봤지만, 유의미한 성과는 없었음
Model
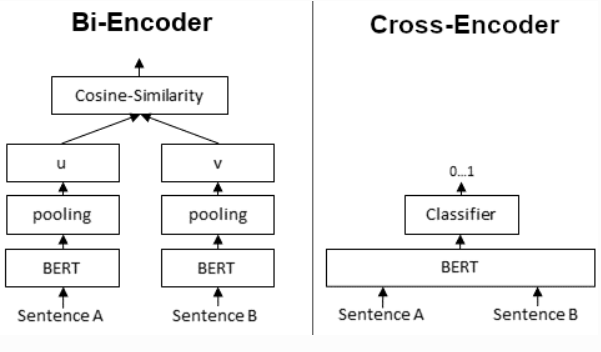
- SBERT의 핵심은 BERT/RoBERTa의 출력에 풀링 연산을 추가하여 고정된 사이즈의 각 문장의 임베딩을 생성함
- 풀링 연산은 3가지 전략이 있는데, 기본은 2번 째 전략을 사용
- CLS 토큰의 출력을 사용하기
- 모든 출력 벡터의 평균을 계산하기
- 출력 벡터의 최대값을 계산하기
- BERT/RoBERTa를 파인튜닝하기 위해서 샴, triplet network를 만들어서 가중치를 업데이트 함
- 목적 함수는 3가지에 대해서 실험함
-
Classification Objective Function
문장 임베딩 u, v, u - v에 절대값 3개를 concatenate하고, 가중치를 곱한 값을 softmax취한 것 -
Regerssion Objective Function
두 문장 임베딩 u, v사이의 코사인 유사도를 계산한 값에 대해서 MSE를 사용 -
Triplet Objective Function
anchor 문장 a, 긍정 문장 p, 부정 문장 n이 주어졌을 때 긍정 문장과의 거리 - 부정 문장과의 거리가 최대화 될 수록 anchor문장과 긍정 문장의 거리는 가깝게, 부정 문장과의 거리는 멀어지는 손실함수
유클리드 거리, 앱실론은 1을 사용(긍정이 적어도 1만큼은 가까워야 함)
Training Details
- 멀티 장르 NLI, SNLI 데이터 셋을 SBERT학습에 사용
- SNLI는 contradiction, eintailment, neural 3가지로 문장 쌍의 관계를 라벨링한 57만 개의 데이터
- 멀티NLI는 여러 장르의 대화와 문서 텍스트로 구성된 43만 개의 문장 쌍 데이터
- SBERT는 1에폭마다 3가지 Softmax 분류 목적 함수로 파인튜닝 됨
- 배치사이즈 16, Adam, 학습률 2e-5, 훈련 데이터의 10%는 선형적으로 학습률을 증가시킴, 평균 풀링 전략
4 Evaluation - Semantic Textual Similarity
- STS task에서 여러 SOTA모델은 복잡한 회귀 함수를 통해 문장 임베딩에 대한 유사도 점수를 학습시키는데, 이러한 회귀 함수는 문장 크기의 확장 가능성과 문장이 쌍 단위로 학습된다는 측면에서 한계가 있음
- 따라서, 항상 두 문장 임베딩을 비교하기 위한 코사인 유사도를 사용
- 유클리드 거리, 멘헤튼 거리로 유사도를 측정했을 때도 결과는 크게 달라지지 않음
4.1 Unsupervised STS
- SBERT 성능 평가를 위해 STS 관련 훈련 데이터를 사용하지 않았음
- 데이터 셋은 문장 쌍의 의미론적 관계를 0~5점으로 라벨링한 데이터임
- 문장 임베딩과의 코사인 유사도와 라벨 사이의 상관관계를 측정할 때는 피어슨 상관계수 대신 스피어만 상관계수를 사용하여 계산
- SICK-R 데이터셋을 제외한 모든 부문에서 SBERT의 성능이 우수했음. SICK-R의 경우에도 universal sentence encoder가 다양한 데이터 셋을 학습했기 때문에 더 성능이 높게 나온 것이지, SBERT는 위키백과와 NLI 데이터에 대해서만 사전학습 했는데도 거의 비슷한 성능을 보임
4.2 Supervised STS
- STS 벤치마크는 지도 STS system을 평가하는데 있어서 가장 많이 쓰이는 데이터셋으로 캡션, 뉴스, 포럼 카테고리의 8,628개의 train, val, test문장 쌍이 있음
- STSb를 미세조정하는 방식, NLI데이터를 사전학습하고 STSb를 미세조정하는 2가지 방법을 사용하여 후자가 2점 정도 높은 성능 달성
- 하지만, 후자 방법으로 튜닝한 BERT의 크로스 인코더 성능이 제일 높음
4.3 Argument Facet Similarity
- AFS코퍼스는 총기 규제, 동성 결혼, 사형이라는 대조적인 주제에 대해 소셜 미디어 대화에서 6000개의 문장 쌍과 0~5점 사이의 주제가 같은지 다른지를 척도로 라벨링하여 SBERT평가
- 본래 STS데이터는 설명하는 문장인 반면, AFS데이터는 대화 데이터라는 점에서 추론까지 필요함
- 2가지 주제를 훈련하고, 평가는 훈련하지 않은 1가지 주제에 대해서 진행함. 3번을 반복하고, 결과 점수에 대해 평균을 구함
- SBERT는 회귀 목적함수를 사용하여 파인튜닝하고 코사인 유사도를 구함.
- 피어슨 상관계수 사용
- BERT는 attention을 사용하여 두 문장을 직접 비교할 수 있지만, SBERT는 개별 문장이 어떤 주제인지 알 수 없는 상태로 문장을 벡터화 시켜야하기 때문에 비슷한 주장과 비슷한 이유를 가진 문장 간의 거리가 가까워짐
- 결국 AFS에서 SBERT는 BERT보다 낮은 성능을 보임
- 따라서, BERT와 동등한 성능을 내려면 두 주제 이상의 학습이 필요
4.4 Wikipedia Sections Distinction
- 위키피디아의 여러 섹션의 기사 데이터를 사용하여 앵커 문장과 긍정적인 문장은 같은 섹션을, 부정 문장에는 다른 섹션 문장으로 구성
- 긍정 문장이 부정 문장보다 앵커 문장과의 거리가 가까우면 정답, 아니면 오답으로 정확도를 평가 지표로 사용
- 역시 Cross-Topic Evaluation의 경우 SBERT의 뚜렷한 성능 저하 나타남
5 Evaluation - SentEval
- SBERT는 원래 파인 튜닝으로 분류, 예측 사용 용도는 아니지만, 여러 downstream task에서도 뛰어난 성능 달성
6 Ablation Study
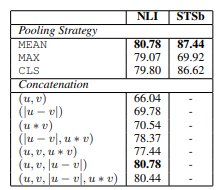
- 여러 풀링 전략, 다양한 concatenate 방법을 사용하여 SBERT를 훈련하고 성능을 평균화
- 분류 목적함수는 SNLI와 multiNLI 데이터셋을 학습하고, 회귀 목적함수는 STS벤치마크의 훈련 데이터를 학습함
- 코사인 유사도와 스피어만 상관계수를 사용하여 STSb의 데이터를 평가함
- concatenate 전략의 경우 평균 풀링 전략만을 사용
- 가장 중요한 요소는 이고, concatenate는 소프트맥스 분류 훈련에만 관련되어있음
- 따라서, STS벤치마크 데이터셋의 유사도를 예측할 때는 코사인 유사도만 이용
7 Computational Efficiency
- 문장 임베딩 계산 속도를 향상시키기위해 스마트 배치 전략을 사용
- 이 전략은 비슷한 길이를 가진 문장을 함께 그룹화하고, 미니배치에서 가장 긴 요소만을 패딩하여 패딩 토큰으로 인한 오버헤드를 크게 감소시킴

