Abstract
- 질의 응답, 기계 번역, 독해, 요약 등의 NLP Task는 Task별로 특화된 데이터셋과 지도 학습이 필요함
- 하지만, 본 논문에서는 별도의 지도 학습 없이 수백만 개의 웹 페이지에서 수집한 데이터셋으로 학습하여 광범위한 NLP Task를 수행할 수 있는 언어 모델을 제시함
- 이렇게 별도의 학습 없이 특정 Task를 수행하는 것을 zero-shot으로 칭하며, 언어 모델의 크기를 키울 수록 그 성능은 더욱 개선 됨
- GPT-2는 1.5B 파라미터를 가진 Transformer Decoder 모델로 zero-shot환경에서 수행된 7개의 작업에서 SOTA를 달성

- 모델 크기(117M, 345M, 762M, 1542M)에 따라 제로샷 성능이 점진적으로 개선
1. Introduction
- 기존의 기계 학습 시스템은 단일 도메인과 단일 Task를 위한 시스템이기 때문에 다른 Task에는 적합하지 못하기 때문에 여러 Task에 적용할 수 있는 학습 방법인 zero-shot학습이 중요
- GPT-1에서는 방대한 양의 Corpus로 비지도 사전 학습을 진행한 뒤, 각 Task에 맞는 지도 학습 데이터셋을 이용해서 파인튜닝을 했으나, 본 논문은 어떠한 파라미터나 아키텍처 수정 없이 zero-shot으로 다양한 작업을 수행하는 언어 모델을 제시
2. Approach
- 언어 모델링은 역시 GPT-1의 사전 훈련 방법과 동일하게 주어진 토큰으로 다음 토큰이 나올 조건부 확률을 계산하는 방식으로 이루어짐
- 인터넷에 있는 방대한 양의 정보를 학습하면, 여러 Task를 추론하고 수행하는 방법을 모델이 자연스럽게 학습할 것이라는 가설을 제시
2.1. Training Dataset
- Web Text를 통해 매우 다양하고 엄청난 양의 Corpus를 얻을 수 있지만, 대부분 사용하기 어려워 데이터 품질 문제를 해결해야 함
- 본 논문에서는 Reddit에서 최소 3개 이상의 카르마를 받은 모든 링크를 수집하여 4,500만 개 링크의 텍스트를 모을 수 있었음.
- 여기서 카르마는 커뮤니티에서 사용자가 이 글을 얼마나 신뢰하는지 간접적으로 보여주는 휴리스틱한 지표임.
- 휴리스틱 기반 데이터 클렌징, 데이터 중복 제거를 마친 약 800만 개의 문서가 포함된 40GB의 텍스트를 구성.
- WebText에서 Wikipedia 문서를 모두 제거했는데, Wikipedia는 다른 데이터셋에서도 흔히 사용되는 데이터로 테스트 평가 작업과 훈련 데이터 간의 중복으로 인해 분석이 복잡해질 가능성을 줄이기 위함.
2.2. Input Representation
- 언어 모델은 어떤 문자열 입력에도 대응하여 확률 계산과 계산된 문자열을 생성할 수 있어야 하기 때문에 tokenization, 소문자 변환, out of vocabulary 토큰과 같은 전처리 단계가 포함됨.
- GPT-2는 자주 사용되는 문자열은 단어 수준 입력으로, 잘 사용되지 않는 문자열은 기호 수준 입력으로 조율하는 Byte Pair Encoding을 적용하여 바이트 수준의 BPE을 통한 토크나이징 수행.
- 단, dog?, dog!과 같이 같은 의미를 가진 단어를 여러 토큰으로 사용하는 BPE의 비효율성을 개선하기 위해 알파벳, 숫자, 특수문자의 범주를 정의한 다음 다른 범주끼리는 병합하여 토큰으로 사용하지 못하도록 규칙을 적용.
2.3. Model
- GPT-1과 동일하게 Transformer Decoder 아키텍처를 기반으로 몇 가지 수정사항이 적용
- Layer Normalization : Self-Attention Block 뒤에 정규화 layer 추가, 각 서브 블록에서 연산 수행 전 정규화 layer 삽입(기존 모델은 연산 후 정규화 layer)
- ResNet의 연산 누적 효과를 고려하여 초기 가중치를 로 조정합니다. 여기서 N은 잔여 레이어(residual layer)의 수
- 어휘 크기 확장(50,257개), context_length 확장(512 -> 1024), batch_size 확장(512)
3. Experiments
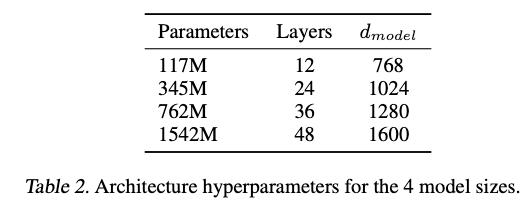
- GPT-2는 4가지 언어 모델을 훈련하였는데, 첫 번째 모델은 GPT-1과 동일한 크기로, 두 번째 모델은 BERT와 동일한 크기임
- 각 모델의 학습률은 WebText에 대한 과소적합을 방지하기 위해 5% 소수 샘플에서 낮은 perplexity를 보이는 값을 기준으로 조정하였음
(여기서 perplexity의 개념이 잘 이해가 안됐는데, 한국어로는 "혼란도"라고 불리며 모델이 다음 토큰을 얼마나 확신 있게 예측하는지를 수치화한 개념인 것 같다.
수식도 각 단어의 조건부 확률을 계산하고, 로그를 취한 값의 확률 평균을 구한 뒤 지수화를 하는 복잡한 방식이었다.
쉽게 정리하면, 혼란도는 "다음 단어를 예측할 때 평균적으로 몇 개의 선택지 중 하나를 골라야 하는지"를 의미한다고 보면 될 것 같다.)
- 모델 평가에 사용되는 데이터는 언어 모델 학습 데이터인 WebText와 다르기 때문에 평가 데이터를 자연스러운 형태로 변환하는 de-tokenizer를 사용하여 모델의 입력으로 제공
- 모든 Task에서 SOTA를 달성하지는 못했지만, 모델 크기에 따라서 성능이 증가하고, zero-shot으로도 유의미한 답변을 출력함
4. Generalization vs Memorization
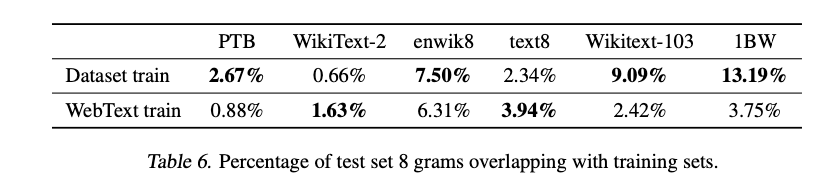
- 학습에 사용된 데이터셋이 워낙 방대하기에 학습 데이터와 테스트 데이터의 중복으로 성능이 과대평가될 수 있어 이 부분에 대해서도 실험을 진행
- 테스트 데이터에서 연속된 8개의 단어로 이루어진 문자열 100만 개를 생성해서 WebText와 비교한 결과 기존 언어 모델의 중복률과 큰 차이를 보이지는 않음
7. Conclusion
- 다양한 분야의 대규모 데이터 셋으로 거대 언어 모델을 훈련하면 여러 Task에서 우수한 성능을 발휘할 수 있음
- 거대 언어 모델이 충분히 다양한 텍스트를 잘 훈련시킬 때, 지도 학습 없이도 여러 작업을 수행할 수 있는 방법을 자연스럽게 학습 가능하다는 결론
소감
GPT-2 이전까지의 AI는 어떤 Task을 수행하기 위한 데이터 셋과 해당 데이터 셋의 의미가 담긴 라벨이 꼭 필요했다.
하지만, GPT-2는 따로 추가적인 학습을 진행할 필요 없이 단순히 엄청난 양의 다양한 고품질의 데이터를 엄청난 크기의 모델에 때려박아서 학습시키는 것만으로 충분하다는 방향성을 제시한 기념비적인 논문이라고 할 수 있겠다.

한 걸음씩 꾸준하게